【论文阅读|2024 WACV 多目标跟踪Deep-EloU】

论文阅读|2024 WACV 多目标跟踪Deep-EloU
- 摘要
- 1 引言(Introduction)
- 2 相关工作(Related Work)
-
- 2.1 基于卡尔曼滤波器的多目标跟踪算法(Multi-Object Tracking using Kalman Filter)
- 2.2 基于定位的多目标跟踪算法(Location-based Multi-Object Tracking)
- 2.3 基于外观的多目标跟踪(Appearance-based Multi-Object Tracking)
- 2.4 体育运动中的多目标跟踪(Multi-Object Tracking in Sports)
- 3 提出的方法(Proposed Methods)
-
- 3.1 基于外观的关联(Appearance-based Association)
- 3.2 与 ExpansionIoU 关联(Association with ExpansionIoU)
- 3.3 置信度分数感知匹配(Confidence Score Aware Matching)
- 3.4 迭代扩展ExpansionIoU(Iterative Scale-Up ExpansionIoU)
- 4 实验和结果(Experiments and Results)
-
- 4.1 数据集(Dataset)
- 4.2 检测器(Detector)
- 4.3 ReID模型(ReID模型)
- 4.4 跟踪设置(Tracking Setting)
- 4.5 评估指标(Evaluation Metrics)
- 4.6 性能(Performance)
- 4.7 Deep-EIoU消融实验研究(Ablation Studies on Deep-EIoU)
- 4.8 初始扩展尺度的鲁棒性(Robustness to initial expansion scale)
- 4.9 基于卡尔曼滤波器的跟踪器上的ExpansionIoU(ExpansionIoU on Kalman filter-based tracker)
- 4.10 局限性(Limitation)
- 5 总结
论文题目: Iterative Scale-Up ExpansionIoU and Deep Features Association for Multi-Object Tracking in Sports
论文特点: 作者提出了一种迭代扩展的 ExpansionIoU 和深度特征关联方法Deep-EIoU,用于体育场景中的多目标跟踪,旨在解决非线性、不规则运动、相似外观的在线短时多目标跟踪问题,实验表明,提出的方法对于提高跟踪鲁棒性是有效的,缺点就是该方法目前仅适用于短时跟踪,可能无法解决目标短暂消失入镜重识别问题,实时性较差。
论文下载链接: 下载途径1. 在附件资源中; 下载途径2. https://arxiv.org/abs/2306.13074。
代码和模型: https://github.com/hsiangwei0903/Deep-EIoU 。
纯中文版链接: https://blog.csdn.net/dally2/article/details/135777792
摘要
Deep learning-based object detectors have driven notable progress in multi-object tracking algorithms. Yet, current tracking methods mainly focus on simple, regular motion patterns in pedestrians or vehicles. This leaves a gap in tracking algorithms for targets with nonlinear, irregular motion, like athletes. Additionally, relying on the Kalman filter in recent tracking algorithms falls short when object motion defies its linear assumption. To overcome these issues, Huang et al. propose a novel online and robust multi-object tracking approach named deep ExpansionIoU (Deep-EIoU), which focuses on multi-object tracking for sports scenarios. Unlike conventional methods, they abandon the use of the Kalman filter and leverage the iterative scale-up ExpansionIoU and deep features for robust tracking in sports scenarios. This approach achieves superior tracking performance without adopting a more robust detector, all while keeping the tracking process in an online fashion. They proposed method demonstrates remarkable effectiveness in tracking irregular motion objects, achieving a score of 77.2% HOTA on the SportsMOT dataset and 85.4% HOTA on the SoccerNet-Tracking dataset. It outperforms all previous state-of-the-art trackers on various large-scale multi-object tracking benchmarks, covering various kinds of sports scenarios. The code and models are available at https://github.com/hsiangwei0903/Deep-EIoU.
基于深度学习的目标跟踪算法推动了多目标跟踪算法的显著进步。然而,目前的跟踪方法主要关注行人或车辆这类简单、规则的运动模式。这就为运动员等非线性、不规则运动目标的跟踪算法留下了空白。此外,当物体运动违反卡尔曼滤波器的线性假设时,在最近的跟踪算法中依赖卡尔曼滤波器就会出现问题。为了克服这些问题,Huang等人提出了一种新颖的在线鲁棒多目标跟踪方法,名为ExpansionIoU (Deep-EIoU),主要用于运动场景的多目标跟踪。与传统方法不同的是,放弃了卡尔曼滤波器的使用,而是利用迭代扩展 ExpansionIoU 和深度特征来实现运动场景中的鲁棒跟踪。这种方法无需采用更强大的检测器就能实现卓越的跟踪性能,同时还能保持在线跟踪过程。提出的方法在跟踪不规则运动物体方面效果显著,在 SportsMOT 数据集上获得了 77.2% 的 HOTA 分数,在 SoccerNet-Tracking 数据集上获得了 85.4% 的 HOTA 分数。在涵盖各种运动场景的各种大规模多目标跟踪基准测试中,该方法的表现优于之前所有最先进的跟踪器。
1 引言(Introduction)
Multi-Object Tracking (MOT) is a fundamental computer vision task that aims to track multiple objects in a video and localize them in each frame. Most recent tracking algorithms [33, 1, 28, 4], which mainly focus on pedestrians or vehicle tracking, have achieved tremendous progress on public benchmarks [19, 8, 11]. However, these state-of-the-art algorithms fail to perform well on datasets with higher difficulties, especially those datasets with sports scenarios [7, 6, 36]. Given the growing demand for sports analytic for applications like automatic tactical analysis and athletes’ movement statistics including running distance, and moving speed, the field of multi-object tracking for sports requires more attention.
多目标跟踪(MOT)是一项基本的计算机视觉任务,旨在跟踪视频中的多个物体,并在每一帧中对其进行定位。最近的大多数跟踪算法 [33, 1, 28, 4],主要侧重于行人或车辆跟踪,在公共基准测试中取得了巨大进步 [19, 8, 11]。然而,这些最先进的算法在难度较高的数据集上,尤其是那些包含体育场景的数据集上表现不佳[7, 6, 36]。鉴于自动战术分析和运动员运动统计(包括跑步距离和移动速度)等应用对体育分析的需求日益增长,体育多目标跟踪领域需要更多关注。
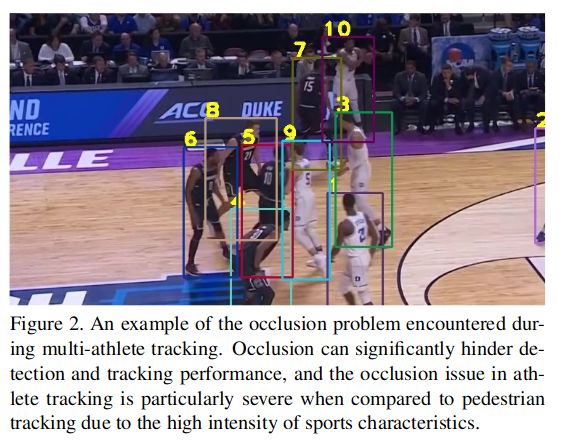
Different from multi-object tracking for pedestrians or vehicles, MOT in sports scenarios poses higher difficulties due to several reasons, including severe occlusion caused by the high intensity in sports scenes as illustrated in Figure 2, similar appearance between players in the same team due to the same color jersey like examples in Figure 3, and also unpredictable motion due to some sport movement like a crossover in basketball, sliding tackle in football or spike in volleyball. Due to the above reasons, the previous trackers, which utilize appearance-motion fusion [34, 28] or simply motion-based [33, 5, 4] methods struggle to conduct robust tracking on several major MOT benchmarks in sports scenarios [6, 7].
与行人或车辆的多目标跟踪不同,运动场景中的 MOT 具有更高的难度,由于多种原因,包括如图 2 所示的运动场景中高强度运动造成的严重遮挡、如图 3 所示的同队球员之间因球衣颜色相同而产生的相似外观,以及一些运动动作(如篮球中的交叉步、足球中的滑铲或排球中的扣球)造成的不可预测运动。由于上述原因,以往利用外观-运动融合[34, 28]或单纯基于运动[33, 5, 4]方法的跟踪器在体育场景中的几个主要 MOT 基准[6, 7]上难以进行稳健跟踪。

To address these issues, in this paper, they propose a novel and robust online multi-object tracking algorithm specifically designed for objects with irregular and unpredictable motion. Their experimental results demonstrate that their algorithm effectively handles the irregular and unpredictable motion of athletes during the tracking process. It outperforms all tracking algorithms on two large-scale public benchmarks [7] without introducing extra computational cost while maintaining the algorithm online. Therefore, in this paper, they assert three main contributions:
•They present a novel association method to specifically address the challenges in sports tracking, named ExpansionIoU, which is a simple yet effective method for tracking objects with irregular movement and similar appearances.
• Their proposed iterative scale-up ExpansionIoU further leverages with deep features association for robust multi-object tracking for sports scenarios.
• The proposed method achieves 77.2 HOTA on the SportsMOT [7] dataset, and 85.4 HOTA on the SoccerNet-Tracking dataset [6], outperforming all the other previous tracking algorithms by a large margin.
为了解决这些问题,在本文中提出了一种新颖、稳健的在线多目标跟踪算法,专门针对具有不规则和不可预测运动的物体而设计。实验结果表明,该算法能在跟踪过程中有效处理运动员的不规则和不可预测运动。在两个大型公共基准测试[7]中,该算法的性能优于所有跟踪算法,而且在保持算法在线的同时,没有引入额外的计算损失。因此,在本文中提出了三个主要贡献:
-
提出了一种简单而有效名为 ExpansionIoU 的新型关联方法,以专门应对体育跟踪中的挑战,可用于跟踪具有不规则运动和相似外观的物体。
-
提出的迭代扩展 ExpansionIoU 进一步利用了深度特征关联,可用于体育场景中稳健的多目标跟踪。
-
所提出的方法在 SportsMOT [7] 数据集上实现了 77.2 HOTA,在 SoccerNet-Tracking 数据集 [6] 上实现了 85.4 HOTA,大大优于之前所有的跟踪算法。
2 相关工作(Related Work)
2.1 基于卡尔曼滤波器的多目标跟踪算法(Multi-Object Tracking using Kalman Filter)
Most of the existing tracking algorithms [33, 4, 5, 28, 35, 30, 14, 12, 13, 29] incorporate Kalman filter [15] as a method for object motion modeling. Kalman filter can formulate object motion as a linear dynamic system and can be used to predict its next frame location according to the object’s motion from the previous frames. Kalman filter has shown effectiveness in multi-object tracking across several public benchmarks [19, 8, 23]. However, due to the Kalman filter’s linear motion and Gaussian noise assumption, the Kalman filter might fail to track an object with nonlinear motion. Due to this reason, OC-SORT [5] proposes several methods including observation-centric re-update to modify the Kalman filter’s parameters during the tracking process and prevent error accumulations when an object is not tracked. The performance has shown effectiveness for tracking objects with irregular motion on several public datasets [23, 7].
现有的大多数跟踪算法 [33, 4, 5, 28, 35, 30, 14, 12, 13, 29] 都采用卡尔曼滤波 [15] 作为物体运动建模的方法。卡尔曼滤波器可将物体运动视为一个线性动态系统,并可根据物体在前几帧的运动情况预测其下一帧的位置。卡尔曼滤波器在多个公共基准测试中展示出了多目标跟踪的有效性 [19, 8, 23]。然而,由于卡尔曼滤波器的线性运动和高斯噪声假设,卡尔曼滤波器可能无法跟踪非线性运动的物体。基于这个原因,OC-SORT [5] 提出了几种方法,包括以观测为中心的重新更新,在跟踪过程中修改卡尔曼滤波器的参数,防止在未跟踪物体时误差累积。该方法在多个公共数据集上展示出跟踪不规则运动物体的有效性[23, 7]。
2.2 基于定位的多目标跟踪算法(Location-based Multi-Object Tracking)
Tracking can also be conducted based on the position information, given a high frame rate input video sequence, the object’s position shift between frames is relatively small due to the high frame rates, thus making the position information a reliable clue for association between frames. Several methods [22, 14] utilizes the bounding boxes’ distance as the cost for bounding box association, while some recent work [31] utilize different IoU calculation methods including GIoU [20], DIoU [38], and BIoU [31], to conduct bounding box association between frames, which also demonstrate effectiveness in multi-object tracking.
在高帧率输入视频序列中,由于帧率较高,物体在帧间的位置偏移相对较小,因此位置信息成为帧间关联的可靠线索。有几种方法[22, 14]利用边界框距离作为边界框关联的损失,而最近的一些工作[31]则利用不同的 IoU 计算方法,包括 GIoU [20]、DIoU [38] 和 BIoU [31],来进行帧间边界框关联,这些方法在多目标跟踪中也展示出了有效性。
2.3 基于外观的多目标跟踪(Appearance-based Multi-Object Tracking)
With the recent development and improvement of object ReID model [39] and training tricks [17], many tracking algorithms incorporate ReID into the association process. Some methods use the joint detection and embedding architecture [35, 27] to produce detection and object embedding at the same time to achieve real-time tracking. While the other methods [28, 1] apply other stand-alone ReID model to extract detection’s embedding features for association. The appearance-based tracking methods improve the tracking robustness with an extra appearance clue, while sometimes the appearance can be unreliable due to several reasons including occlusions, similar appearance among tracked objects, appearance variation caused by the object’s rotation, or the lighting condition.
随着近年来物体 ReID 模型[39]和训练技巧[17]的发展和改进,许多跟踪算法都将 ReID 纳入了关联过程。有些方法使用联合检测和嵌入架构 [35, 27],同时进行检测和物体嵌入,以实现实时跟踪。而其他方法[28, 1]则应用其他独立的 ReID 模型来提取检测的嵌入特征进行关联。基于外观的跟踪方法通过额外的外观线索来提高跟踪的鲁棒性,但有时外观线索可能会因为一些原因而不可靠,这些原因包括遮挡、被跟踪物体之间的外观相似、物体旋转或光照条件导致的外观变化等。
2.4 体育运动中的多目标跟踪(Multi-Object Tracking in Sports)
Numerous studies have been conducted to monitor players’ movements in team sports during games. This monitoring serves not only to automate the recording of game statistics but also enables sports analysts to obtain comprehensive information from a video scene understanding perspective. Different from MOT of pedestrian [19], MOT in sports scenarios is much more challenging due to several reasons including targets’ faster and irregular motions, similar appearance among players in the same team, and more severe occlusion problem due to the sport’s intense characteristic. The majority of recent methods for MOT for sports utilize the tracking-by-detection paradigm and integrate a re-identification network to generate an embedding feature for association.
在团队运动中,人们对球员在比赛中的动作进行了大量监控研究。这种监测不仅能自动记录比赛统计数据,还能让体育分析人员从视频场景理解的角度获得全面信息。与行人的 MOT 不同[19],体育场景中的 MOT 具有更高的挑战性,原因包括目标的运动速度更快、不规则,同队球员的外观相似,以及体育运动的激烈特点导致的更严重的遮挡问题。最近的大多数体育运动中的移动定位方法都采用了通过检测进行跟踪的模式,并整合了一个重新识别网络来生成用于关联的嵌入特征。
Vats et al. [25] combine team classification and player identification approaches to improve the tracking performance in hockey. Similarly, Yang et al. [32] and Maglo et al. [18] demonstrate that by localizing the field and players, the tracking results in football can be more accurate. Additionally, Sang ̈ uesa et al. [21] utilize the human pose information and actions as the embedding features to enhance basketball player tracking. While Huang et al. [14] combine OC-SORT [5] and appearance-based post-processing to conduct tracking on multiple sports scenarios including basketball, volleyball, and football [7].
Vats 等人[25] 结合球队分类和球员识别方法,提高了曲棍球的跟踪性能。同样,Yang 等人[32] 和 Maglo 等人[18] 的研究表明,通过定位场地和球员,足球的跟踪结果可以更加准确。此外,Sang ̈ uesa 等人[21] 利用人体姿势信息和动作作为嵌入特征来增强篮球运动员的跟踪。Huang 等人[14] 则结合 OC-SORT [5] 和基于外观的后处理技术,对篮球、排球和足球等多种运动场景进行跟踪[7]。
3 提出的方法(Proposed Methods)

Their proposed method follows the classic tracking-by-detection paradigm, which also enables online tracking without using future information. They first apply the object detector YOLOX on each input frame, and then they conduct association based on several clues including the similarity between extracted appearance features and the ExpansionIoU between the tracklets and detections. After the association cost is obtained, the Hungarian algorithm is conducted to get the best matching between tracklets and detections.
提出的方法遵循经典的 "跟踪-检测 "范式,无需使用未来信息也能实现在线跟踪。首先在每个输入帧上应用目标检测器 YOLOX,然后根据提取的外观特征之间的相似性以及小轨迹和检测之间的 ExpansionIoU 等几条线索进行关联。在得到关联损失后,采用匈牙利算法来获得小轨迹和检测之间的最佳匹配。
3.1 基于外观的关联(Appearance-based Association)
The appearance similarity is a strong clue for object association between frames, the similarity can be calculated by the cosine similarity between the appearance features, and it can also be used to filter out some impossible associations. The cost for appearance association Cost_A can be directly obtained from the cosine similarity with the following formula:
C o s t A = 1 − C o s i n e S i m i l a r i t y = 1 − a ⋅ b ∥ a ∥ ∥ b ∥ Cost_A = 1 - Cosine Similarity = 1 - \frac{a \cdot b}{\left \| a \right \| \left \| b\right \| } CostA=1−CosineSimilarity=1−∥a∥∥b∥a⋅b
Here, a and b are the tracklet’s appearance feature and the detection’s appearance feature, respectively. A higher cosine similarity denotes a higher similarity in appearance, while a lower cosine similarity means the tracklet’s appearance and the detection’s appearance are different.
外观相似度是帧间物体关联的有力线索,相似度可以通过外观特征之间的余弦相似度来计算,也可以用来过滤掉一些不可能的关联。根据余弦相似度可以直接得到外观关联的损失Cost_A,计算公式如下:
C o s t A = 1 − C o s i n e S i m i l a r i t y = 1 − a ⋅ b ∥ a ∥ ∥ b ∥ Cost_A = 1 - Cosine Similarity = 1 - \frac{a \cdot b}{ \left \| a \right \| \left \| b\right \| } CostA=1−CosineSimilarity=1−∥a∥∥b∥a⋅b
这里,a 和 b 分别是小轨迹的外观特征和检测的外观特征。余弦相似度越高,表示外观相似度越高,余弦相似度越低,表示小轨迹的外观和检测的外观不同。
3.2 与 ExpansionIoU 关联(Association with ExpansionIoU)
Insipired by previous work [31], which utilizes expanding bounding boxes for association, to deal with the fast and irregular movement of sports player, they proposed ExpansionIoU (EIoU), a robust association method for tracking under large and nonlinear motion. Different from the previous work [31], they found out that expanding the bounding box even more during association can lead to a significantly better performance in athlete tracking. Traditional IoU has been a cornerstone in location-based tracking method, but it often lacks the flexibility to account for object’s large movement, when tracklet and detection bounding boxes share small or no IoU between adjacent frames. EIoU addresses this limitation by modifying the dimensions of bounding boxes, expanding their width and height and considers a wider range of object relationships, thus recover the association for those objects with large movement in sports scenarios. The expansion of bounding box is controlled by expansion scale E, given an original bounding box with height h and width w, they can calculate the expansion length h⋆ and w⋆ following:
h ∗ = ( 2 E + 1 ) h w ∗ = ( 2 E + 1 ) w \begin{matrix} &\\ h^* = (2E + 1)h & \\ w^* = (2E + 1)w \end{matrix} h∗=(2E+1)hw∗=(2E+1)w
受之前利用扩展边界框进行关联来处理运动员的快速和不规则运动的工作[31]的启发,提出了一种在大运动量和非线性运动下进行跟踪的鲁棒关联方法ExpansionIoU(EIoU)。与之前的工作 [31]不同,发现在关联过程中进一步扩大边界框可以显著降低在运动员跟踪中获得更好的性能。传统的 IoU 一直是基于位置的跟踪方法的基石,但它往往缺乏灵活性,当跟踪器和检测边界框在相邻帧之间共享较小的 IoU 或没有 IoU 时,无法顾及物体的大运动量。EIoU 通过修改边界框的尺寸、扩大其宽度和高度以及考虑更广泛的物体关系来解决这一局限性,从而恢复体育场景中运动量大的物体的关联性。边界框的扩展由扩展尺度 E 控制,给定一个高度为 h、宽度为 w 的原始边界框,可以计算出扩展长度 h⋆和 w⋆,如下所示:
h ∗ = ( 2 E + 1 ) h w ∗ = ( 2 E + 1 ) w h^* = (2E + 1)h \\\ w^* = (2E + 1)w h∗=(2E+1)h w∗=(2E+1)w
The original bounding box is expand based on the expansion length. Denote the original bounding box top-left and bottom-right coordinate as (t, l),(b, r), they can derive the expanded bounding box’s coordinate as (t − h⋆ 2 , l − w⋆ 2) and (b + h⋆ 2 , r + w⋆ 2 ).
原始边界框根据扩展长度进行扩展。将原始边界框的左上角和右下角坐标分别表示为 (t, l),(b, r),可以得出扩展边界框的坐标为 :
( t − h ∗ 2 , l − w ∗ 2 ) ( b + h ∗ 2 , r + w ∗ 2 ) \ (t- \frac{h^*}{2}, l - \frac{w^*}{2}) \\\ (b+\frac{h^*}{2}, r+\frac{w^*}{2}) (t−2h∗,l−2w∗) (b+2h∗,r+2w∗)
The expanded bounding box is further used for IoU calculation between tracklets and detections pairs, note that the expansion is applied both on tracklets’ last frame detections and the new coming detections from detector, the calculated EIoU is used for Hungarian association between adjacent frames. The operation of expanding the bounding box does not change several important objects’ information like the bounding box center, aspect ratio, or appearance features. By simply expanding the search space, they can associate those tracklets and detections with small or no IoU, which is considered a common situation when the target’s movement is fast, especially in sports games.
扩展后的边界框进一步用于计算小轨迹和检测对之间的 IoU,注意扩展同时应用于小轨迹的最后一帧检测和检测器的新检测,计算出的 EIoU 用于相邻帧之间的匈牙利关联。扩展边界框的操作不会改变几个重要的对象信息,如边界框中心、长宽比或外观特征。通过简单地扩展搜索空间,可以关联常见的目标快速移动时,尤其是在体育比赛中那些IoU 较小或没有 IoU 的小轨迹和检测结果。
3.3 置信度分数感知匹配(Confidence Score Aware Matching)
Following ByteTrack [33], they give the high confidence score detections higher weighting during the matching process. The high score detections usually imply less occlusion, hence a higher chance to preserve more reliable appearance features. Due to this reason, the first stage matching with high score detections is based on the association cost of both appearance and ExpansionIoU, denoted as Cstage1. The first stage of matching is built upon several rounds of iterative associations with a gradually scale-up expansion scale, addressed in Section 3.4. In the second round of matching with low score detections, only ExpansionIoU is used, the cost is denoted as Cstage2.
In their first matching stage, they abandon the IoU-ReID weighted cost method used in several previous works [34, 28], where the cost is a weighted sum of the appearance cost CA and IoU cost CIoU :
C = λ C A + ( 1 − λ ) C I o U C = \lambda C_A + (1-\lambda)C_{IoU} C=λCA+(1−λ)CIoU
根据 ByteTrack [33],在匹配过程中会给高置信度分数的检测赋予更高的权重。高分检测通常意味着较少的遮挡,因此更有可能保留更可靠的外观特征。因此,第一阶段的高分检测匹配基于外观和 ExpansionIoU 的关联损失,记为 Cstage1。第一阶段的匹配建立在几轮迭代关联的基础上,并逐步扩大扩展规模,这将在第 3.4 节中讨论。在低分检测的第二轮匹配中,只使用 ExpansionIoU,损失记为 Cstage2。
在第一匹配阶段,放弃了之前几项研究中使用的 IoU-ReID 加权损失法 [34,28],其中损失是外观损失 CA 和 IoU 损失 CIoU 的加权和:
C = λ C A + ( 1 − λ ) C I o U C = \lambda C_A + (1-\lambda)C_{IoU} C=λCA+(1−λ)CIoU
Instead, they adopt strategy similar to that of BoT-SORT [1] for appearance-based association. More specifically, they first filter out some impossible associations by setting cost thresholds for both appearance and ExpansionIoU (EIoU). The adjusted appearance cost C ˆ A is set to 1 if either cost is bigger than its corresponding threshold, otherwise C ˆ A is set as half of its appearance cost CA. Finally, the first stage’s final association cost Cstage1 is set as the minimum of the appearance cost C ˆ A and EIoU cost CEIoU . With τA and τEIoU denotes the threshold for the cost filter, they can write the appearance cost C ˆ A as:
C = { 1 , i f C A > τ A o r C E I o U > τ E I o U 0.5 C A , o t h e r w i s e C = \left\{\begin{matrix} 1 , & if \quad C_A>\tau_A \quad or \quad C_{EIoU} >\tau_{EIoU} \\ 0.5 C_A,& otherwise \end{matrix}\right. C={1,0.5CA,ifCA>τAorCEIoU>τEIoUotherwise
The final cost in the first stage of matching Cstage1 will be the minimum between adjusted appearance cost C ˆ A and EIoU cost CEIoU .
C s t a g e 1 = m i n ( C A ^ , C E I o U ) C_{stage1}=min(C_{\hat{A}}, C_{EIoU}) Cstage1=min(CA^,CEIoU)
While the association cost in the second matching stage Cstage2 will be only using the EIoU cost CEIoU .
相反,作者采用与 BoT-SORT [1] 类似的策略来处理基于外观的关联。更具体地说,首先通过设置外观和ExpansionIoU(EIoU)的损失阈值来过滤掉一些不可能的关联。如果其中一个损失大于相应的阈值,则调整后的外观损失 C ˆ A 设为 1,否则 C ˆ A 设为其外观损失CA 的一半。最后,第一阶段的最终关联损失 Cstage1 设为外观损失 C ˆ A 和 EIoU 损失 CEIoU 的最小值。 τA 和 τEIoU 表示损失过滤器的阈值,可以将外观成本 C ˆ A 写成:
C = { 1 , i f C A > τ A o r C E I o U > τ E I o U 0.5 C A , o t h e r w i s e C = \left\{\begin{matrix} 1 , & if \quad C_A>\tau_A \quad or \quad C_{EIoU} >\tau_{EIoU} \\ 0.5 C_A,& otherwise \end{matrix}\right. C={1,0.5CA,ifCA>τAorCEIoU>τEIoUotherwise
第一阶段匹配的最终损失 Cstage1 将是调整后的外观损失 C ˆ A 与 EIoU 损失 CEIoU 之间的最小值。
C s t a g e 1 = m i n ( C A ^ , C E I o U ) C_{stage1}=min(C_{\hat{A}}, C_{EIoU}) Cstage1=min(CA^,CEIoU)
而第二匹配阶段 Cstage2 的关联损失将只使用 EIoU 损失 CEIoU。
3.4 迭代扩展ExpansionIoU(Iterative Scale-Up ExpansionIoU)
As illustrated by the previous work using expansion bounding box for association [31], the amount of the bounding box expansion is a crucial and sensitive hyperparameter in the tracking process and the performance of the tracker can be largely affected by the choice of the hyperparameter. In the real-world scenario, several factors might limit us from tuning the expansion scale and improving the tracking performance, including 1) the online tracking requirements. One common requirement for an athlete tracking system is the system needs to operate in an online matter, tuning the expansion scale with experiments and tweaking the performance is not possible in such cases. 2) No access to the testing data. For real-world scenarios, the testing data’s ground truth is often not available, which makes finding the perfect expansion scale for association impossible. Due to the above reasons, they proposed a novel iterative scale-up ExpansionIoU association stage for robust tracking, the experiment results show that without any parameter tuning, their algorithms can always maintain SOTA performance on public benchmark. Instead of doing hyperparameter tuning for the best expansion scale E, they choose to iteratively conduct EIoU association based on a gradually increasing Et during the tracking process. In each scale-up iteration, the expansion scale of the current iteration Et can be derived from the following formula:
E t = E i n i t i a l + λ t , E_t=E_{initial}+\lambda t, Et=Einitial+λt,
正如之前使用扩展边界框进行关联的工作[31]所示,边界框的扩展量是跟踪过程中一个关键而敏感的超参数,跟踪器的性能在很大程度上会受到超参数选择的影响。在现实世界中,有几个因素可能会限制我们调整扩展尺度并提高跟踪性能,其中包括:1)在线跟踪要求。运动员跟踪系统的一个常见要求是系统需要在线运行,在这种情况下,通过实验调整扩展尺度和调整性能是不可能的。2) 无法获取测试数据。在现实世界中,往往无法获得测试数据的真实值,这就不可能找到完美的关联扩展尺度。基于上述原因,作者提出了一种新颖的迭代扩展 ExpansionIoU 关联阶段来实现鲁棒跟踪,实验结果表明,在不进行任何参数调整的情况下,该算法可以在公共基准上始终保持 SOTA 性能。在跟踪过程中,作者选择基于逐渐增大的 Et 来迭代进行 EIoU 关联,而不是对最佳扩展尺度 E 进行超参数调整。在每次扩展迭代中,当前迭代的扩展尺度 Et 可由以下公式得出:
E t = E i n i t i a l + λ t , E_t=E_{initial}+\lambda t, Et=Einitial+λt, {$}
where E_initial is the initial expansion scale, λ denotes the step size for the iterative scale-up process, t stands for the iteration count, which starts from 0. By using this approach, they can first perform association to those trajectory and detection pairs with higher ExpansionIoU, and gradually search for those pairs with lower overlapping area, which enhances the robustness of their association process. Note that the iterative scale-up process is only applied for high score detections association, once the iteration count reaches the total number of iteration t_total, the association for high score detections stops and the tracker moves on to the low score detections association stage.
其中,E_initial是初始扩展尺度,λ 表示迭代扩展过程的步长,t 代表迭代次数,从 0 开始。 通过这种方法,可以先对扩展尺度较高的轨迹和探测对进行关联,然后逐步搜索重叠面积较小的轨迹和探测对,从而增强关联过程的鲁棒性。需要注意的是,迭代扩展过程只适用于高分检测关联,一旦迭代次数达到总迭代次数 t_total,高分检测关联就会停止,跟踪器将进入低分检测关联阶段。
4 实验和结果(Experiments and Results)
4.1 数据集(Dataset)
They evaluate their tracking algorithm on two large-scale multi-sports player tracking datasets, i.e., SportsMOT [7] and SoccerNet-Tracking [6].
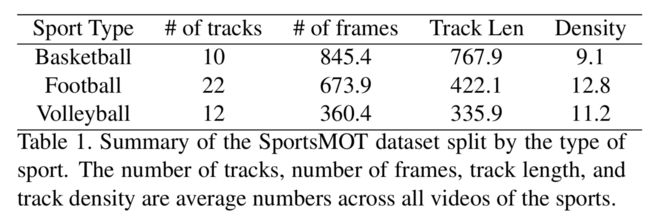
SportsMOT consists of 240 video sequences with over 150K frames and over 1.6M bounding boxes collected from 3 different sports, including basketball, football, and volleyball. Different from the MOT dataset [19, 8], SportsMOT possesses higher difficulties including: 1) targets’ fast and irregular motions, 2) larger camera movements, and 3) similar appearance among players in the same team.
SoccerNet-Tracking is a large-scale dataset for multiple object tracking composed of 201 soccer game sequences. Each sequence is 30 seconds long. The dataset consists of 225,375 frames, 3,645,661 annotated bounding boxes, and 5,009 trajectories. Unlike SportsMOT, which only focuses on the tracking of sports players on the court, the tracking targets of SoccerNet contains multiple object classes including normal players, goalkeepers, referees, and soccer ball.
在两个大型多体育项目球员跟踪数据集(即 SportsMOT [7] 和 SoccerNet-Tracking [6])上对跟踪算法进行了评估。
SportsMOT 包含 240 个视频序列,超过 150K 个帧和 160 多万个边界框,收集自篮球、足球和排球等 3 种不同的运动项目。与 MOT 数据集 [19, 8]不同,SportsMOT 具有更高的难度,包括1) 目标的快速和不规则运动;2) 更大的摄像机运动;3) 同一球队球员的相似外观。
SoccerNet-Tracking 是一个大规模的多目标跟踪数据集,由 201 个足球比赛序列组成。每个序列长度为 30 秒。该数据集包含 225,375 个帧,3,645,661 个注释边界框和 5,009 个轨迹。与 仅关注体育运动员在球场上的跟踪情况的SportsMOT 不同,SoccerNet 的跟踪目标包含多个对象类别,包括普通球员、守门员、裁判和足球。
4.2 检测器(Detector)
They choose YOLOX [10] as their object detector to achieve real-time and high accuracy detection performance. Several existing trackers [33, 5, 1, 31] also incorporate YOLOX as detector, this also leads to a more fair comparison between these trackers with theirs. They use the COCO pretrained YOLOX-X model provided by the official GitHub repositories of YOLOX [10] and further fine-tune the model with SportsMOT training and validation set for 80 epochs, the input image size is 1440 × 800, with data augmentation including Mosaic and Mixup. They use SGD optimizer with weight decay of 5 × 10−4 and momentum of 0.9. The initial learning rate is 10−3 with 1 epoch warmup and cosine annealing schedule, which follows the same training procedure of ByteTrack’s [33]. As for the SoccerNet-Tracking dataset, since oracle detections are provided in the dataset, to make a fair comparison and focus on tracking, they directly use the oracle detections provided by the dataset for the evaluation of all trackers.
作者选择 YOLOX [10] 作为目标检测器,以实现实时和高精度的检测性能。现有的几个跟踪器 [33, 5, 1, 31] 也采用了 YOLOX 作为检测器,这也使得这些跟踪器与作者的跟踪器之间的比较更加公平。作者使用 YOLOX 官方 GitHub 仓库提供的 COCO 预训练 YOLOX-X 模型[10],并使用 SportsMOT 训练集和验证集对该模型进一步微调。 epochs设置为80,输入图像大小为 1440 × 800,数据增强包括 Mosaic 和 Mixup。使用权重衰减为 5 × 10-4 和动量为 0.9 的 SGD 优化器。带有1 epoch的加热和余弦退火计划的初始学习率为 10-3,这与 ByteTrack [33] 的训练步骤相同。至于SoccerNet-Tracking 数据集,由于该数据集提供了oracle detections,为了进行公平比较并侧重于跟踪,直接使用该数据集提供的oracle detetions对所有跟踪器进行评估。
4.3 ReID模型(ReID模型)
For player re-identification (ReID), they use the omniscale feature learning proposed in OSNet [39]. The unified aggregation gate fuses the features from different scales and enhances the ability of human ReID.
SportsMOT The ReID training data for experiments on SportsMOT dataset is constructed based on the original SportsMOT dataset where they crop out each player according to its ground truth annotation of the bounding boxes. The sampled dataset includes 31,279 training images, 133 query images, and 1,025 gallery images.
SoccerNet-Tracking They sample the ReID training data from the SoccerNet-Tracking training set, they randomly select 100 ground truth bounding boxes for each player from randomly sampled videos, with 65 used as training images, 10 used as query images, and 25 used as gallery images. The sampled ReID data contains 7,085 training images, 1,090 query images, and 2,725 gallery images, with a total of 109 randomly selected identities.
Training Details They use the pre-trained model from the Market-1501 dataset [37] and further fine-tune the model based on each of the above mentioned sampled sports ReID datasets, resulting in two ReID models for these two datasets. Each model is trained for 60 epochs, using Adam optimizer with cross entropy loss and the initial learning rate is 3 × 10−4. All the experiments are conducted on single Nvidia RTX 4080 GPU.
对于运动员再识别(ReID),作者使用 OSNet [39] 中提出的全尺度特征学习。统一的聚合门融合了不同尺度的特征,增强了人员ReID 的能力。
SportsMOT 用于 SportsMOT 数据集实验的 ReID 训练数据是基于原始的 SportsMOT 数据集构建的,作者根据每个球员的边界框的标注真实值对其进行裁剪。采样数据集包括 31279 张训练图像、133 张查询图像和 1025 张图库图像。
SoccerNet-Tracking 作者从 SoccerNet-Tracking 训练集中抽取 ReID 训练数据,从随机抽样的视频中为每个球员随机选取 100 个真实值边界框,其中 65 个用作训练图像,10 个用作查询图像,25 个用作图库图像。采样的 ReID 数据包含 7,085 张训练图像、1,090 张查询图像和 2,725 张图库图像,共随机选择了 109 个身份。
训练细节 作者使用 Market-1501 数据集[37]中的预训练模型,并根据上述每个抽样体育 ReID 数据集进一步微调模型,最终为这两个数据集建立两个 ReID 模型。每个模型训练 60 个epochs,使用带有交叉熵损失的Adam优化器,初始学习率为 3 × 10-4。所有实验均在单个 Nvidia RTX 4080 GPU 上进行。
4.4 跟踪设置(Tracking Setting)
The threshold for detection to be treated as high score detection is 0.6, while detections with confidence score between 0.6 and 0.1 will be treated as low score detections, the rest detections with confidence score lower than 0.1 will be filtered. The cost filter threshold τA and τEIoU are set to 0.25 and 0.5, respectively. They also remove the constraint of aspect ratio in the detection bounding box, since sports scenarios might have the condition when a player is lying on the ground, which is different from the MOT datasets where most of the pedestrians are standing and walking. For the high score detections association, the initial value of expansion scale E_initial is set to 0.7 with a step size λ of 0.1, and the total number of iteration t_total is 2. The expansion scale E for low score detections association is 0.7, while for unmatched detections is 0.5. The max frames for keeping lost tracks is 60. After tracking is finished, linear interpolation is applied to boost the final tracking performance.
高分检测的阈值为 0.6,而置信度在 0.6 和 0.1 之间的检测将被视为低分检测,其余置信度低于 0.1 的检测将被过滤。损失过滤阈值 τA 和 τEIoU 分别设为 0.25 和 0.5。作者还取消了检测边界框中的长宽比限制,因为体育场景中可能会出现球员躺在地上的情况,这与 MOT 数据集中大多数行人站立和行走的情况不同。对于高分检测关联,将扩展尺度 E_initial 的初始值设为 0.7,步长 λ 为 0.1,迭代总次数t_total为2。低分检测关联的扩展尺度 E 为 0.7,未匹配检测的扩展尺度 E 为 0.5。保留丢失轨迹的最大帧数为 60 帧。跟踪结束后,应用线性插值来提高最终跟踪性能。
4.5 评估指标(Evaluation Metrics)
MOTA [2] is often used as an evaluation metric for multiobject tracking task, however, MOTA mainly focuses on the detection performance instead of association accuracy. Recently, in order to balance between the detection and association performance, more and more public benchmarks start to use HOTA [16] as the main evaluation metric. For evaluation on the SportsMOT dataset, they adopt HOTA, MOTA, IDF1, and other associated metrics [3] for comparison. While for SoccerNet, they adopt HOTA metrics, with associated DetA, and AssA metrics, since only these metrics are provided by the evaluation server.
MOTA [2] 通常被用作多目标跟踪任务的评估指标,但 MOTA 主要关注的是检测性能而非关联精度。最近,为了在检测性能和关联性能之间取得平衡,越来越多的公共基准开始使用 HOTA [16] 作为主要评估指标。在对 SportsMOT 数据集进行评估时,作者采用了 HOTA、MOTA、IDF1 和其他相关指标 [3] 进行比较。而对于 SoccerNet,采用 HOTA 指标以及相关的 DetA 和 AssA 指标,因为只有这些指标是由评估服务器提供的。
4.6 性能(Performance)
They compare their tracking algorithm with previous existing trackers on two large-scale multi-object tracking datasets in sports scenarios, the SportsMOT and SoccerNetTracking datasets. All the experiments are run on one Nvidia RTX 4080 GPU, and the tracking results are evaluated on the datasets’ official evaluation server.
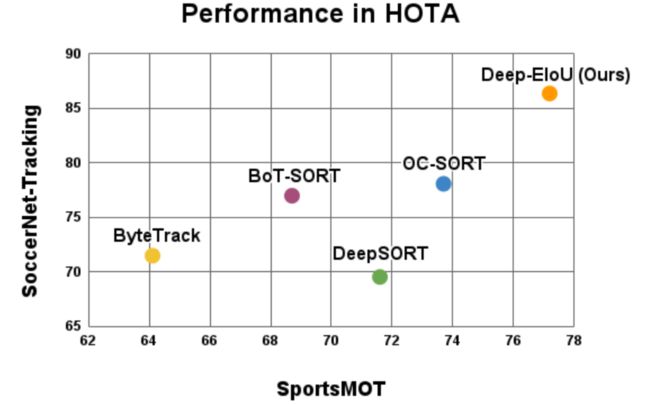
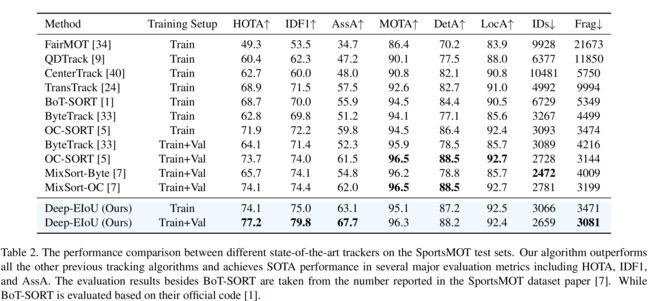
SportsMOT As shown in table 2, the performance of their proposed Deep-EIoU achieves 77.2 in HOTA, 79.8 in IDF1, 67.7 in AssA. The performance of their method achieves state-of-the-art results and outperforms all the other previous trackers while also keeping the tracking process in an online fashion, showing the effectiveness of their algorithm in multi-object tracking in sports scenarios.
SoccerNet To focus on the tracking performance and make a fair comparison, all the evaluated methods are using oracle detections provided by the SoccerNet-Tracking dataset [6]. The performance of their proposed method is reported in table 3. Their method achieves 85.443 in HOTA, 73.567 in AssA, 99.236 in DetA, which outperforms several state-of-the-art online tracking algorithms by a large margin. The performance of DeepSORT and ByteTrack are reported from the original SoccerNet-Tracking paper [6]. The competitive performance of Deep-EIoU in various large-scale sports player tracking datasets demonstrates the effectiveness of their algorithm in multi-object tracking in sports.
作者在两个大型体育场景多目标跟踪数据集SportsMOT 和 SoccerNetTracking 数据集上将他们的跟踪算法与之前已有的跟踪器进行了比较。所有实验均在一个 Nvidia RTX 4080 GPU 上运行,跟踪结果在数据集的官方评估服务器上进行评估。
SportsMOT 如表 2 所示,提出的 Deep-EIoU 在 HOTA 中达到 77.2,在 IDF1 中达到 79.8,在 AssA 中达到 67.7。性能达到了最先进的水平,优于之前所有的跟踪器,同时还保持了在线跟踪过程,展示了算法在体育场景中多目标跟踪的有效性。
SoccerNet 为了关注跟踪性能并进行公平比较,所有评估方法都使用了由 SoccerNet-Tracking 数据集 [6] 提供的 oracle 检测。作者提出的方法的性能见表 3。方法在 HOTA、AssA 和 DetA 中的性能分别达到了 85.443、73.567 和 99.236,远远超过了几种最先进的在线跟踪算法。DeepSORT 和 ByteTrack 的性能报告来自最初的 SoccerNet-Tracking 论文[6]。Deep-EIoU 在各种大规模体育运动员跟踪数据集中的优异表现证明了作者的算法在体育多目标跟踪中的有效性。

4.7 Deep-EIoU消融实验研究(Ablation Studies on Deep-EIoU)
In their experiments, Deep-EIoU is evaluated with different settings on the SportsMOT test set, including whether to incorporate appearance (ReID) during tracking, using iterative scale-up bounding box expansion, and using linear interpolation as post-processing. As shown in Table 4, after incorporating ReID model based on appearance association, the HOTA of Deep-EIoU is boosted by 3.8, showing that although sharing similar appearance between athletes, it is still important to use appearance as a clue for tracking in sport scenarios. With the iterative scale-up process (ISU), the gradually scale-up bounding box can first establish association with those tracklets and detections with higher EIoU, thus also increase the tracking performance, note that the iterative scale-up process is incorporate with a larger tracking buffer, unlike the default setting of 30 for pedestrian tracking, they use 60 due to the stronger occlusion characteristics of the sports scenarios. And finally, following most of the online tracking algorithm [33, 5], they also include linear interpolation (LI) as a strategy to boost the final tracking performance.
在实验中,Deep-EIoU 在 SportsMOT 测试集上以不同的设置进行了评估,包括是否在跟踪过程中加入外观(ReID)、使用迭代扩展边界框扩展以及使用线性插值作为后处理。如表 4 所示,在加入基于外观关联的 ReID 模型后,Deep-EIoU 的 HOTA 提升了 3.8,这表明虽然运动员之间具有相似的外观,但在运动场景中以外观为线索进行追踪仍然非常重要。通过迭代扩展过程(ISU),逐步扩展的边界框可以首先与 EIoU 较高的小轨迹和检测建立关联,从而也提高了跟踪性能,需要注意的是,迭代扩展过程结合了更大的跟踪缓冲区,与行人跟踪的默认设置 30 不同,由于体育场景的遮挡特性更强,使用了 60。最后,按照大多数在线跟踪算法[33, 5],还加入了线性插值(LI)作为提高最终跟踪性能的策略。

4.8 初始扩展尺度的鲁棒性(Robustness to initial expansion scale)
To prove the effectiveness and robustness of their approach, they conduct experiments based on different initial expansion scales in the iterative scale-up process. They change the initial expansion scale from 0.2 to 0.8. The experiment results in Figure 5 show that they can still achieve SOTA performance with different initial expansion scales because the iterative scale-up process can enhance the robustness and does not require any parameter tuning to achieve SOTA performance. This proves their method’s effectiveness in the real-world scenario, when ground truth is often not available and the tracking parameter can not be tuned.
为了证明方法的有效性和鲁棒性,作者在迭代扩展过程中根据不同的初始扩展尺度进行了实验。将初始扩展尺度从 0.2 改为 0.8。图 5 中的实验结果表明,由于迭代扩展过程可以增强鲁棒性,并且无需调整任何参数即可实现 SOTA 性能,因此仍然可以在不同的初始扩展尺度下实现 SOTA 性能。这证明了方法在现实世界中的有效性,因为现实世界中往往没有真实值,跟踪参数也无法调整。

4.9 基于卡尔曼滤波器的跟踪器上的ExpansionIoU(ExpansionIoU on Kalman filter-based tracker)
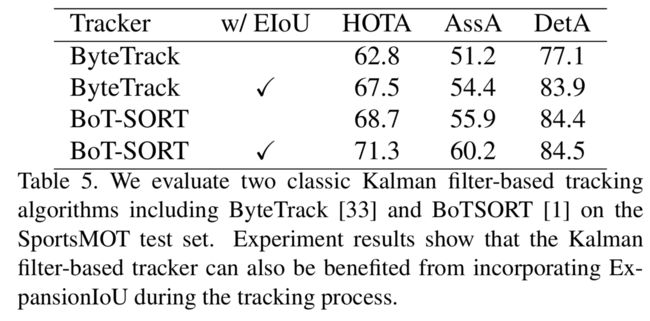
To test the effect of ExpansionIoU on the Kalman filter-based tracker, they also implement several versions of their method by directly incorporating the Kalman filter and ExpansionIoU. In their implementation, the Kalman filter’s prediction and detection will be expanded in the tracking process following the ExpansionIoU. The experiment results in Table 5 demonstrate that after directly replacing IoU with EIoU, these two classic Kalman filter-based trackers increase their performance by a large margin in HOTA, AssA, and DetA. This demonstrates that ExpansionIoU can also be applied as a plug-and-play trick for Kalman filter-based tracker to boost the tracking performance.
为了测试 ExpansionIoU 对基于卡尔曼滤波器的跟踪器的影响,作者还通过直接集成卡尔曼滤波器和 ExpansionIoU 实现了几个版本的方法。在实施过程中,在ExpansionIoU 之后的跟踪过程中,将对卡尔曼滤波器的预测和检测结果进行扩展。表 5 中的实验结果表明,将 IoU 直接替换为 EIoU 后,这两种基于卡尔曼滤波器的经典跟踪器在 HOTA、AssA 和 DetA 中的性能都有很大程度的提高。这表明,ExpansionIoU 也可以作为基于卡尔曼滤波器的跟踪器的即插即用技巧来提高跟踪性能。
4.10 局限性(Limitation)
While their algorithm provides a robust and practical solution for online multi-object tracking in sports scenarios, it does have its limitations, including the absence of an offline post-processing trajectories refinement method. Such methods could involve a post-processing approach [14] or a strong memory buffer [26], which would be valuable in handling edge cases where sports players temporarily exit and re-enter the camera’s field of view. It is worth noting that exploring and integrating offline refinement techniques in the future could potentially enhance the overall performance and extend the applicability of their approach beyond short-term tracking scenarios.
虽然作者的算法为体育场景中的在线多目标跟踪提供了一个强大而实用的解决方案,但它也有其局限性,包括缺乏离线后处理轨迹细化方法。这种方法可能涉及后处理方法[14]或强内存缓冲区[26],这对于处理体育运动员临时退出和重新进入摄像机视野的边缘情况非常有价值。值得注意的是,未来探索和整合离线细化技术有可能提高整体性能,并将方法的适用范围扩展到短期跟踪场景之外。
Another concern of Deep-EIoU is its relatively slower running speed when compared with motion-based trackers. Despite delivering significantly enhanced performance, the integration of the appearance-based tracking-by-detection framework, which involves a detector and a ReID model, introduces additional computational cost. The current DeepEIoU pipeline achieves around 14.6 FPS on a single Nvidia RTX 4080 GPU, which is slower compared to motion-based method. It’s worth noting that transitioning to a more lightweight detector and ReID model has the potential to significantly boost operational speed.
Deep-EIoU 的另一个问题是,与基于运动的跟踪器相比,它的运行速度相对较慢。尽管性能大幅提升,但基于外观的逐个检测跟踪框架(涉及检测器和 ReID 模型)的集成带来了额外的计算成本。目前的 DeepEIoU 管道在单个 Nvidia RTX 4080 GPU 上可达到约 14.6 FPS,与基于运动的跟踪器相比速度较慢。值得注意的是,过渡到更轻便的探测器和 ReID 模式有可能大大提高运行速度。
5 总结
In this paper, they proposed Deep-EIoU, an iterative scale-up ExpansionIoU and deep features association method for multi-object tracking in sports scenarios, which achieves competitive performance on two large-scale multiobject sports player tracking datasets including SportsMOT and SoccerNet-Tracking. Their method successfully tackles the challenges of irregular movement during multi-object tracking in sports scenarios and outperforms the previous tracking algorithms by a large margin.
在本文中,提出了 Deep-EIoU,一种迭代扩展的 ExpansionIoU 和深度特征关联方法,用于体育场景中的多目标跟踪。在包括 SportsMOT 和 SoccerNet-Tracking 在内的两个大规模多目标运动选手跟踪数据集上取得了极具竞争力的性能。该方法成功地解决了体育场景中多目标跟踪过程中不规则运动的难题,并在很大程度上优于之前的跟踪算法。