22-09-04 西安 谷粒商城(01)MySQL主从复制、MyCat读写分离、MyCat分库分表
人人尽说江南好,游人只合江南老。春水碧于天,画船听雨眠。

MySQL主从复制
1、主从复制原理
mysql主从复制:分摊读写压力(cpu计算压力)
写交给主库,读由主从分摊处理(原因是写操作较少,读操作较多),以满足在安全性与高可用性上的需求
主从复制的目的就是:读写分离
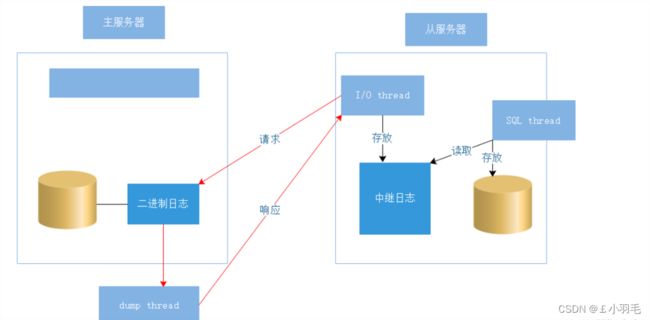
主从复制原理
核心:两个日志,三个线程
两个日志:二进制日志、中继日志
三个线程:I/O、dump、sql
中继日志通常会位于OS缓存中,所以中继日志的开销很小。复制过程有一个很重要的限制,即复制在slave上是串行化的,也就是说Master上的并行更新操作不能在slave上并行操作。
主要原理:
- 主MySQL服务器做的增删改操作,都会写入自己的二进制日志(Binary log)
- 然后从MySQL从服务器打开自己的I/O线程连接主服务器,进行读取主服务器的二进制日志
- I/O去监听二进制日志,一旦有新的数据,会发起请求连接
- 这时候会触发dump线程,dump thread响应请求,传送数据给I/O(dump线程要么处于等待,要么处于睡眠)
- I/O接收到数据之后存放在中继日志
- SQL thread线程会读取中继日志里的数据,存放到自己的服务器中
主从同步四种方式对比
| 同步方式 | 概念 |
| 异步复制(Async Replication) | 主库将更新写入Binlog日志文件后,不需要等待数据更新是否已经复制到从库中,就可以继续处理更多的请求。Master将事件写入binlog, 但并不知道Slave是否或何时已经接收且已处理。在异步复制的机制的情况下,如果Master宕机,事务在Master上已提交,但很可能这些事务没有传到任何的Slave上。 假设有Master->Salve故障转移的机制,此时Slave也可能会丢失事务。MySQL复制默认是异步复制,异步复制提供了最佳性能。 |
| 同步复制(sync Replication) | 主库将更新写入Binlog日志文件后,需要等待数据更新已经复制到从库中,并且已经在从库执行成功,然后才能返回继续处理其它的请求。 同步复制提供了最佳安全性,保证数据安全,数据不会丢失,但对性能有一定的影响。 |
| 半同步复制(Async Replication) | 主库提交更新写入二进制日志文件后,等待数据更新写入了从服务器中继日志中,然后才能再继续处理其它请求。 该功能确保至少有1个从库接收完主库传递过来的binlog内容已经写入到自己的relay log里面了,才会通知主库上面的等待线程,该操作完毕。 半同步复制,是最佳安全性与最佳性能之间的一个折中。 MySQL 5.5版本之后引入了半同步复制功能,主从服务器必须安装半同步复制插件,才能开启该复制功能。 如果等待超时,超过rpl_semi_sync_master_timeout参数设置时间(默认值为10000,表示10秒),则关闭半同步复制,并自动转换为异步复制模式。 当master dump线程发送完一个事务的所有事件之后,如果在rpl_semi_sync_master_timeout内,收到了从库的响应,则主从又重新恢复为增强半同步复制。 ACK (Acknowledge character)即是确认字符。 |
| 增强半同步复制(lossless Semi-Sync Replication)、无损复制 | 增强半同步是在MySQL 5.7引入,其实半同步可以看成是一个过渡功能,因为默认的配置就是增强半同步,所以,大家一般说的半同步复制其实就是增强的半同步复制,也就是无损复制。 增强半同步和半同步不同的是,等待ACK时间不同 rpl_semi_sync_master_wait_point = AFTER_SYNC(默认) 半同步的问题是因为等待ACK的点是Commit之后,此时Master已经完成数据变更,用户已经可以看到最新数据,当Binlog还未同步到Slave时,发生主从切换,那么此时从库是没有这个最新数据的, 用户看到的是老数据。 增强半同步将等待ACK的点放在提交Commit之前,此时数据还未被提交,外界看不到数据变更,此时如果发送主从切换,新库依然还是老数据,不存在数据不一致的问题。 |
2、搭建主库mysql_master
1.主库准备工作
1.拉取mysql5.7镜像
docker pull mysql:5.72.准备主库配置
# 创建主需要的配置目录 mkdir -p /etc/mysql/master mkdir -p /etc/mysql/master/conf mkdir -p /etc/mysql/master/data # 给文件夹设置所有权限!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! chmod -R 777 /etc/mysql# 创建主需要的配置文件my.cnf vim /etc/mysql/master/conf/my.cnfmy.cnf内容如下:
[mysqld] # 集群环境该节点的唯一的id值 server-id=1 # 主从复制:主有写操作时 主会记录写日志到该日志文件中 log-bin=master-bin # 设置不要复制的数据库 binlog-ignore-db=mysql binlog-ignore-db=mydb # 设置需要复制的数据库 主会将该库的写操作记录到log-bin日志文件中 binlog-do-db=guli_oms # 字符编码 character_set_server=utf8 datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid default-time_zone='+8:00' # logbin日志文件的格式:statement->记录写sql(批量操作主从效率高,@@hostname之类系统变量获取主从执行时不一致) ,row->记录写后的数据(和前面相反) binlog_format=STATEMENT3.创建mysql_master容器
docker run -d -p 3316:3306 \ --name mysql_master \ --privileged=true \ --restart=always \ -v /etc/mysql/master/data:/var/lib/mysql:rw \ -v /etc/mysql/master/conf/my.cnf:/etc/mysql/my.cnf:rw \ -e MYSQL_ROOT_PASSWORD=123456 \ mysql:5.74.远程连接主机
使用sqlyog分别连接docker启动的mysql主库:注意修改端口号,Master对外映射的端口号是3316
2.binlog日志三种格式
1.statement
statement->记录写sql(批量操作主从效率高,@@hostname之类系统变量获取主从执行时不一致)2.row
row->记录写后的数据3.mixed
可以根据有没有函数自动切换前俩种格式,但是它也识别不了系统变量,主机名字不一样就会造成主从不一致
-- "@@"首先标记会话系统变量,如果会话变量不存在,则标记全局系统变量 SELECT @@hostname;
系统变量 规范:以“@@”开头
启动MySQL服务,生成MySQL实例期间,MySQL将为MySQL服务器内存中的系统变量赋值。 这些系统变量定义了当前MySQL服务实例的属性、特征。

3.查看主mysql的状态
这个时候,要是你也能出的来效果就最好了,出不来也没事。。因为我们很多人都出不来,拷别人虚拟机的。。。
-- 查看主mysql的状态 SHOW MASTER STATUS
接入点:从机从接入点开始复制。之前主机发生的任何事情跟我从机无关,我只从接入这个点开始复制

3、搭建从库mysql_slave
搭建从库准备工作
1.准备从库配置
# 创建从需要的配置目录 mkdir -p /etc/mysql/slave/conf mkdir -p /etc/mysql/slave/data # 给文件夹设置所有权限!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! chmod -R 777 /etc/mysql这里要再重写设置权限,不然sqlyog登录不上去。
# 创建从需要的配置文件my.cnf vim /etc/mysql/slave/conf/my.cnfmy.cnf内容如下:
[mysqld] server-id=2 relay-log=relay-bin character_set_server=utf8 datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid default-time_zone='+8:00'2.创建mysql_slave容器
docker run -d -p 3326:3306 \ --name mysql_slave \ --restart=always \ -v /etc/mysql/slave/data:/var/lib/mysql:rw \ -v /etc/mysql/slave/conf/my.cnf:/etc/mysql/my.cnf:rw \ -e MYSQL_ROOT_PASSWORD=123456 \ mysql:5.73.远程连接主机
Slave对外映射的端口号是3326
4、建立主从关系
mysql用户可以分为普通用户和root用户,root用户是超级管理员,拥有所有权限。包括创建用户、删除用户、修改用户密码等管理权限;普通用户只拥有被授予的各种权限
1.主库创建slave账户
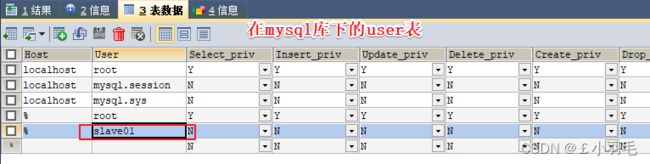
# 创建slave用户 CREATE USER 'slave01'@'%'; # 设置密码 ALTER USER 'slave01'@'%' IDENTIFIED BY '123456'; # 授权 GRANT REPLICATION SLAVE ON *.* TO 'slave01'@'%'; flush privileges;在user表中
----------------------------------------------
2.从库配置主从关系
如果从机中搭建过主从,要重新设置主从
stop slave;
reset master
从库中执行sql
CHANGE MASTER TO MASTER_HOST = '192.168.2.108', MASTER_PORT = 3316, MASTER_USER = 'slave01', MASTER_PASSWORD = '123456', MASTER_LOG_FILE = 'master-bin.000004', MASTER_LOG_POS = 13988;master_port:主库的ip地址
master_port:主库的端口
master_user:用户名
master_password:密码
master_log_file:主库查询的file项对应的值
master_log_pos:主库查询的的值
-- 查看主mysql的状态 SHOW MASTER STATUS
---------------------
3.开启主从复制
#启动slave同步
START SLAVE;
#查看同步状态
SHOW SLAVE STATUS;主从搭建成功,如下:
 ------------------
------------------
4.测试主从
主库中创建guli_oms,从库也会自动的跟着创建该数据库。创建别的库,从库不会跟的,因为主库的my.conf配置过。。SHOW MASTER STATUS也看到过

在主库中的guli_oms中创建表,从库也会跟着。达到主从复制的目的
MyCat读写分离
通过MyCat和MySQL的主从复制配合搭建数据库的读写分离,实现MySQL的高可用性。
java项目连接数据库连接mycat,sql交给mycat接收,由它根据配置好的参数,判断读写应该交给哪个数据库来处理。
大体就是下面这个样子,后面会详细说
1、安装MyCat
把压缩包ftp上传到/opt目录下并解压(压缩包我也是老师的资料中给的。。。)
tar -zxvf /opt/Mycat-server-1.6.7.6-release-20220524173810-linux.tar.gz

解压后的mycat/conf目录下存放的是它的配置文件:
其中核心的配置有3个:
server.xml:配置MyCat作为虚拟数据库的信息(地址、数据库名、用户名、密码等信息)mycat启动时初始化的配置schemal.xml:mycat代理的真实数据库的信息,实现读写分离
mycat通过逻辑库 将真实数据库表加载到该逻辑库中 展示给连接mycat的用户rule.xml:分库分表规则配置

2、MyCat是什么
重要:mycat本身不存储数据,只是在中间做一些业务逻辑
1、mycat是我们的程序与mysql数据库之间的桥梁,我们的请求不再直接到达数据库,而是到达mycat(解耦)
2、mycat中需要配置好主库从库关系,mycat根据配置决定读和写的去向。我们的Jdbc连接是连接mycat,程序代码没有任何变化。
3、mycat基本原理就是拦截转发
它拦截用户发送过来的SQL语句,对SQL做了一些特定的分析后,将此SQL发送到真实的数据库。
3、MyCat常用命令
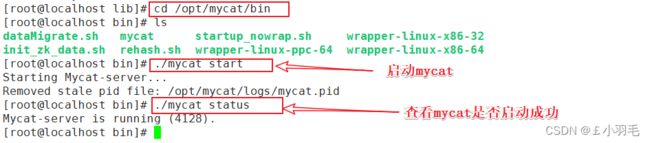
进入 mycat/bin目录:cd /opt/mycat/bin
启动: ./mycat start
控制台启动: ./mycat console
停止: ./mycat stop
重启: ./mycat restart
状态: ./mycat status
日志文件:mycat/logs/wrapper.log
4、schema.xml 配置读写分离
select user()
writeHost和readHost分别指定写和读,balance=0的话 代表不使用读写分离

启动mycat
启动失败的话,查看
tail -30 /opt/mycat/logs/wrapper.log

测试mycat读写分离
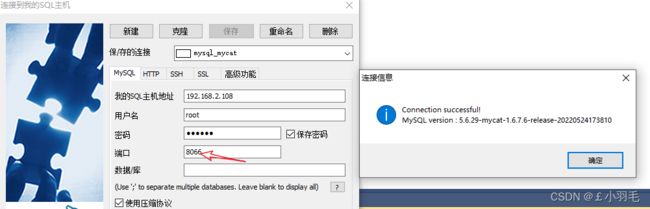
1.sqlyog连接mycat
2.插入SQL,再读取
INSERT INTO oms_order_operate_history VALUES('2' , '10011' , '9528' , NOW() ,0 , @@hostname); SELECT * FROM oms_order_operate_history;balance=2的情况下,很不幸我他喵的都是从主库中读的
修改一下schema.xml 中balance=4。重启mycat
很遗憾,还是没有读写分离。。。


分库分表
ali开发手册:什么时候才需要分库分表

1、分库分表准备工作
1.在mysql_mycat库中删除上面的测试数据。
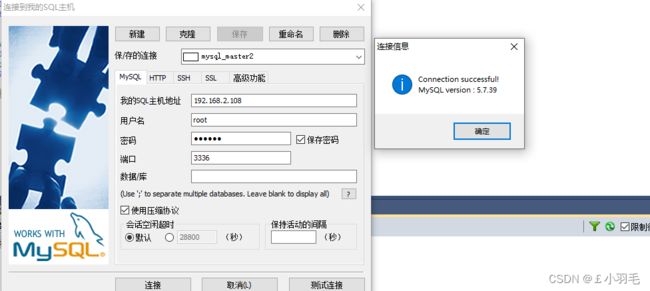
DELETE FROM oms_order_operate_history;2.创建新的容器mysql_master2
# 创建主2需要的配置目录 mkdir /etc/mysql/master2 mkdir /etc/mysql/master2/conf mkdir /etc/mysql/master2/data # 设置权限 chmod -R 777 /etc/mysql/ # 创建主需要的配置文件my.cnf vim /etc/mysql/master2/conf/my.cnfmy.cnf内容如下:
[mysqld] server-id=3 log-bin=master-bin # 设置不要复制的数据库 binlog-ignore-db=mysql # 设置需要复制的数据库 binlog-do-db=guli_oms character_set_server=utf8 datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid default-time_zone='+8:00' binlog_format=STATEMENT创建容器mysql_master2启动:
docker run -d -p 3336:3306 \ --name mysql_master2 \ --privileged=true \ --restart=always \ -v /etc/mysql/master2/data:/var/lib/mysql:rw \ -v /etc/mysql/master2/conf/my.cnf:/etc/mysql/my.cnf:rw \ -e MYSQL_ROOT_PASSWORD=123456 \ mysql:5.7sqlyog连接
在该数据库中导入guli_oms整个库
注意:3316/3326/3336 三个mysql的guli_oms库中的表都必须是空的

2、数据分片
数据分片是指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面,以达到分散单台设备负载的效果。
数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式:
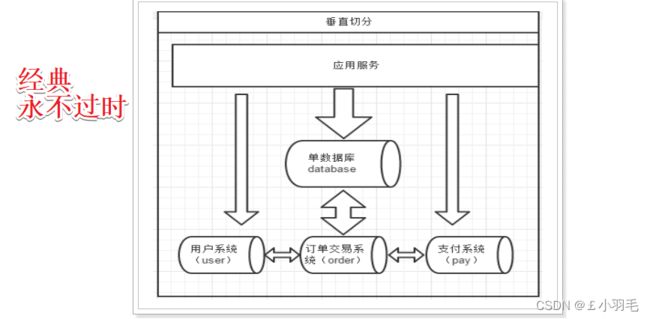
1.垂直(纵向)切分:是按照不同的表来切分到不同的数据库(主机)之上。
将原本一个库中的多张表存到多个不同的数据库(主机),将一个库的读写压力分摊到多个库中
分布式每个微服务只连接自己的数据库,已经实现。
2.水平(横向)切分:是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)的多张表中,这些多张表结构一样,多张表数据组合起来代表所有的数据。
分表可以减少单表数据量,查询时提高速度
逻辑库:在mycat中的数据库,但是真实物理不存在。
将多个库中的表合并到逻辑库中,项目中只要连接mycat就可以操作所有表
逻辑表:逻辑库中包含多个逻辑表,逻辑表可以映射mysql真实存在的物理表,逻辑表和物理表可 以一多一,也可以一对多(数据分片)
将拆分的多张表数据合并到一张逻辑表中,增删改查(指定条件查询)时,mycat可以根据rule规则快速判断到哪张表中操作数据
3、mycat配置分表
1.在rule.xml中配置分表规则
user_id
mod-long
2
2.在schema.xml中新增配置
select user()

重启mycat,测试分库分表
INSERT INTO oms_order(id,user_id,order_sn,create_time,username)
VALUES('1' , '1001' ,'1' , NOW() , 'zhangsan');
INSERT INTO oms_order(id,user_id,order_sn,create_time,username)
VALUES('2' , '1002' ,'2' , NOW() , 'zhaosi');
INSERT INTO oms_order(id,user_id,order_sn,create_time,username)
VALUES('3' , '1003' ,'3' , NOW() , 'wangwu');
INSERT INTO oms_order(id,user_id,order_sn,create_time,username)
VALUES('4' , '1004' ,'4' , NOW() , 'qianliu');
INSERT INTO oms_order_item(id,order_id,spu_name)
VALUES('1' ,'2' , '小米手机1');
INSERT INTO oms_order_item(id,order_id,spu_name)
VALUES('2' ,'4' , '小米手机2');
INSERT INTO oms_order_item(id,order_id,spu_name)
VALUES('3' ,'1' , '小米手机3');
INSERT INTO oms_order_item(id,order_id,spu_name)
VALUES('4' ,'3' , '小米手机4');测试联查
SELECT * FROM oms_order t1 LEFT JOIN oms_order_item t2 ON t1.id = t2.order_id;

4、跨库join问题
两个数据库在同一台主机上可以做关联查询;两张表在不同的主机上是不能做join关联查询的
解决思路:子表的记录与所关联的父表记录存放在同一个数据分片上
在schema.xml这里解决的,设置了ER表,ER表的分片字段就是那个外键“order_id”
ER表:指父子表中的子表,该表依赖于别的另外一张表。比如订单详情表(子表)和订单表 (父表)