14、Kafka ------ kafka 核心API 之 流API(就是把一个主题的消息 导流 到另一个主题里面去)
目录
- kafka 核心API 之 流API
-
- Kafka流API的作用:
- 流API的核心API:
- 使用流API编程的大致步骤如下:
- 代码演示 流API 用法
-
- MessageStream 流API 代码
- 演示消息从 test1主题 导流到 test2主题
- 演示使用匿名内部类对消息进行处理
- Topology 拓扑结构 讲解
- 代码:
-
- MessageProducer 消息生产者
- Consumer01 消费者01
- Consumer02 消费者02
- MessageStream 流API 功能演示类
- pom 依赖
kafka 核心API 之 流API
Kafka流API的作用:
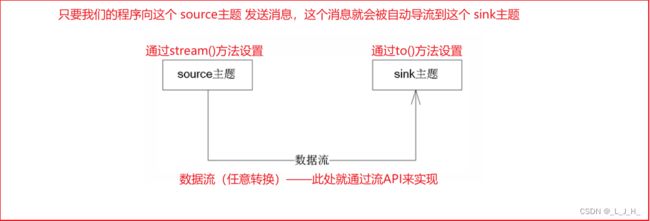
流API 的作用 是创建多个主题之间的消息流,从而允许将消息从一个主题“导流”到另一个主题,在消息“导流”的过程中,客户端程序可对消息进行任意自定义的转换(转换也就是对消息进行业务操作)。
这个 sink主题并不是指具体的一个叫sink的主题,只是类似于 源和目标 中的目标一样。
我把某个主题的方法导流到另一个主题上面去而已。这个sink主题也可以是a主题,也可以是b主题。
流API的核心API:
流API 的核心API包括如下几个:
StreamsBuilder: 从名称就知道,它的作用是创建Stream。但它不是直接创建KafkaStream,而是创建KStream。
KStream: KStream 代表key-value数据流,它的主要功能就是定义流的拓扑(Topology)结构。通俗来说,就是设置source主题,设置sink主题等。
Topology: 代表流的拓扑(Topology)结构,它也提供了大量重载的 addSource()、addSink()方法来添加 source主题 和 sink主题。
KafkaStreams: 代表程序要用到的数据流,调用它的 start()方法开始导流,调用它的 close()方法可关闭导流。
使用流API编程的大致步骤如下:
1、使用StreamsBuilder创建KStream,创建KStream时已经指定了source主题。
2、通过KStream设置sink主题、要流所做到转换处理。
KStream提供了大量重载的flatMap()、map()、filter()……等方法对流进行转换, 调用这些处理方法时,通常都需要传入自定义的处理器,常使用Lambda表达式来定义这些处理器。
3、调用StreamsBuilder的build()方法创建代表流关系的Topology对,该对象已经封装了通过KSteam所设置的source主题、sink主题等信息。
如果还需要对流关系进行修改,也可调用Topology对象的addSource()、addSink()方法来添加source主题和sink主题。
4、以Topology为参数,创建KafkaStreams对象,创建该对象时,还需要传入一个Properties对象对该流进行配置。
5、调用KafkaStreams对象的start()方法开始导流;导流结束后调用 close()方式关闭流。
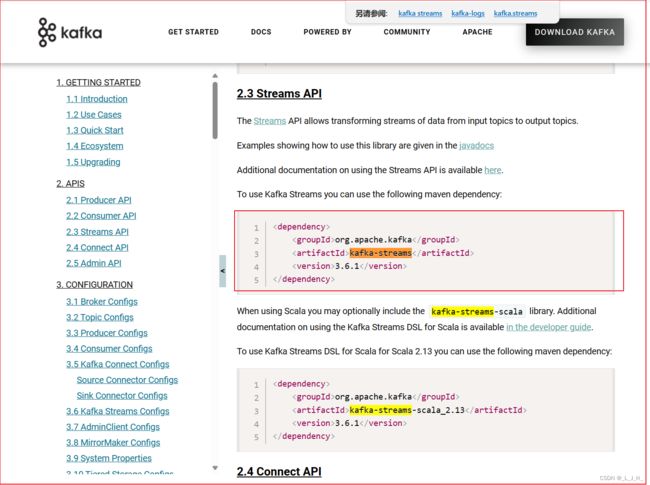
流API要使用自己的依赖库:
org.apache.kafka
kafka-streams
3.6.1
依赖
代码演示 流API 用法
KafkaStreams 官方API 示例

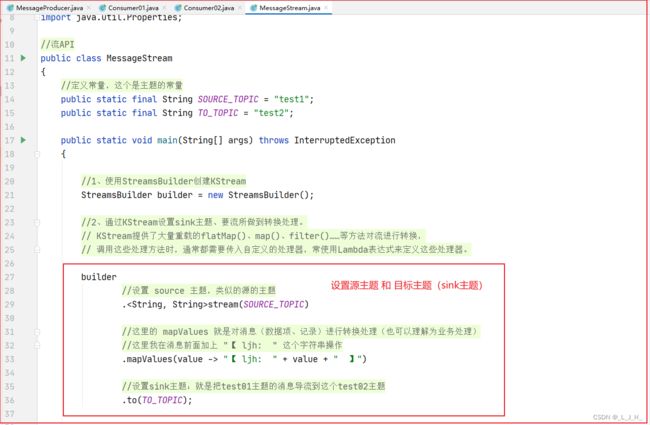
MessageStream 流API 代码
这个导流的类,功能就是把test1主题的消息自动导流到test2主题里面,导流的时候还对消息做了业务处理,就是在消息前面加上 "【 ljh: " 这个字符串操作

启动 流API 这个类,开始导流

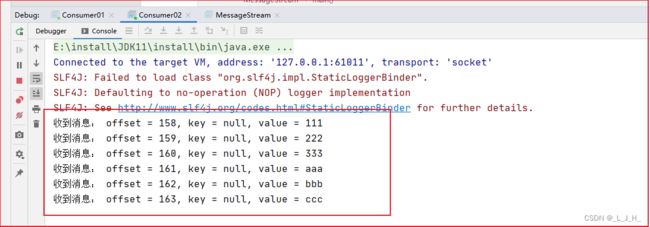
演示消息从 test1主题 导流到 test2主题
前景提要,消费者01和消费者02都是在监听test2这个主题的消息的。
两个消费者在不同的消费者组,所以都可以监听到test2主题的所有消息。类似发布/订阅模式。
打开一个小黑窗,往test1主题发送消息
C:\Users\JH> kafka-console-producer --bootstrap-server localhost:9092 ^
More? --topic test1

导流成功:
如图:我往 test1主题 发送的消息,因为成功导流到 test2 主题,所以也被消费者01 和 消费者02 监听到了。
而且消息也做了处理,在消息前面加了–> 【 ljh:

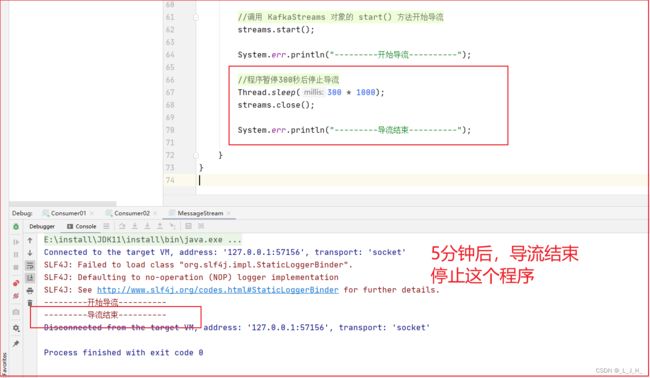
5分钟后,导流结束,关闭这个导流功能的线程。
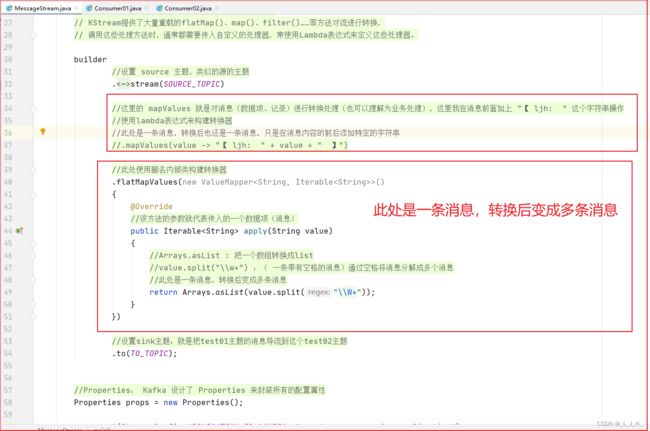
演示使用匿名内部类对消息进行处理
通过代码处理,以空格为分割点,将带有空格的消息分割成多个消息
此处是一条消息,转换后变成多条消息
如图:发送的这一条消息,带有多个空格
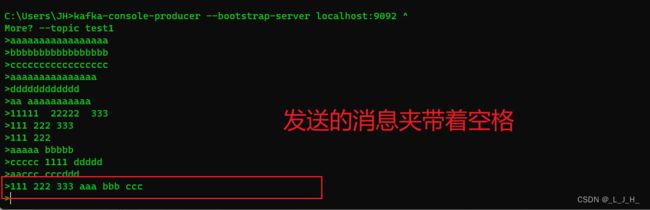
通过业务处理后,一条消息通过空格,分割成6条消息
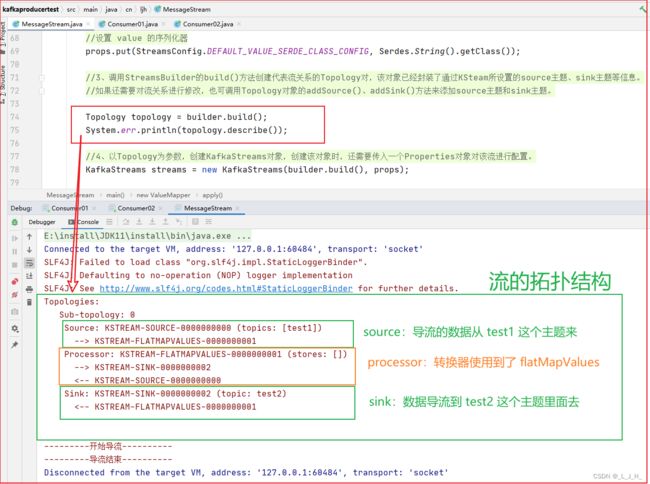
Topology 拓扑结构 讲解
调用StreamsBuilder的build()方法创建代表流关系的Topology对像,该对象已经封装了通过KSteam所设置的 source主题、sink主题等信息。如果还需要对流关系进行修改,也可调用Topology对象的addSource()、addSink()方法来添加source主题和sink主题。
通过打印这个拓扑结构,看下我们设置的 source主题、sink主题等信息。
如图:我们设置的 source主题 就是 test1 主题,设置的 sink主题 就是test2 主题
代码:
MessageProducer 消息生产者
这个在演示中用不到,不过为了方便后期研究,也贴上来
package cn.ljh;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
//生产者
import java.util.Properties;
/**
* Properties: Kafka 设计了 Properties 来封装所有的配置属性
*
* KafkaProducer:用来创建消息生产者,是 生产者API 的核心类,
* 它提供了一个 send()方法 来发送消息,该方法需要传入一个 ProducerRecord对象
*
* ProducerRecord:代表了一条消息,Kafka 的消息是包含了key、value、timestamp
*/
public class MessageProducer
{
//主题常量
public static final String TEST_TOPIC = "test2";
public static void main(String[] args)
{
//Properties 中所设置的key,有效的value,可以通过Kafka官方文档来查询生产者API支持哪些配置属性
Properties props = new Properties();
//指定连接Kafka的地址,多个地址之间用逗号隔开
props.put("bootstrap.servers", "localhost:9092,localhost:9093,localhost:9094");
//指定Kafka的消息确认机制
//0:不等待消息确认;1:只等待领导者分区的消息写入之后确认;all:等待所有分区的消息都写入之后才确认
props.put("acks", "all");
//指定消息发送失败的重试多少次
props.put("retries", 0);
//控制生产者在发送消息之前等待的时间
//props.put("linger.ms", 3);
//设置序列化器
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//1、创建 KafkaProducer 时,需要传入 Properties 对象来配置消息生产者
Producer<String, String> producer = new KafkaProducer<>(props);
//2、发送消息
for (int i = 0; i < 20; i++)
{
var msg = "这是第【 " + (i + 1) + " 】条消息!";
if (i < 10)
{
//发送带 key 的消息
producer.send(new ProducerRecord<String, String>(TEST_TOPIC, "ljh", msg));
} else
{
//发送不带 key 的消息
producer.send(new ProducerRecord<String, String>(TEST_TOPIC, msg));
}
}
System.out.println("消息发送成功!");
//3、关闭资源
producer.close();
}
}
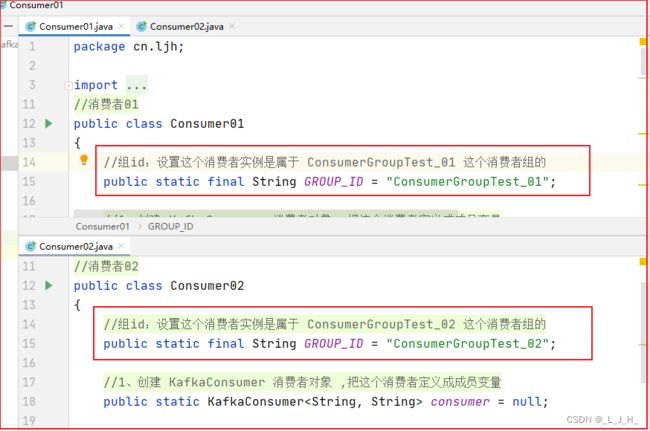
Consumer01 消费者01
package cn.ljh;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
import java.util.Scanner;
//消费者01
public class Consumer01
{
//组id:设置这个消费者实例是属于 ConsumerGroupTest_01 这个消费者组的
public static final String GROUP_ID = "ConsumerGroupTest_01";
//1、创建 KafkaConsumer 消费者对象 ,把这个消费者定义成成员变量
public static KafkaConsumer<String, String> consumer = null;
public static void main(String[] args)
{
//Properties 中所设置的key,有效的value,可以通过Kafka官方文档来查询生产者API支持哪些配置属性
Properties props = new Properties();
//指定连接Kafka的地址,多个地址之间用逗号隔开
props.put("bootstrap.servers", "localhost:9092,localhost:9093,localhost:9094");
//设置这个消费者实例属于哪个消费者组
props.setProperty("group.id", GROUP_ID);
//自动提交offset,就是类似之前的自动消息确认
props.setProperty("enable.auto.commit", "true");
//多个消息之间,自动提交消息的时间间隔
props.setProperty("auto.commit.interval.ms", "1000");
//设置session的超时时长,默认是10秒,这里设置15秒
props.setProperty("session.timeout.ms", "15000");
//设置每次都从最新的消息开始读取
props.setProperty("auto.offset.reset","latest");
//设置序列化器
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//1、创建 KafkaConsumer 消费者对象
consumer = new KafkaConsumer<>(props);
//2、订阅主题,订阅kafka集群中的test2主题
consumer.subscribe(Arrays.asList(MessageProducer.TEST_TOPIC));
//因为获取消息的循环是一个死循环,没法退出,所以我在这里再加一个线程来关闭这个消费者
//启动一个线程来关闭这个 KafkaConsumer
new Thread(() ->
{
//创建一个Scanner 类来读取控制台数据
Scanner sc = new Scanner(System.in);
//如果有下一行,就读取下一行
while (sc.hasNextLine())
{
//获取控制台下一行的内容
var str = sc.nextLine();
//就是这个线程一直监听控制台,如果我们在控制台输出” :exit “,则关闭这个这个 KafkaConsumer
if (str.equals(":exit"))
{
//取消订阅
consumer.unsubscribe();
//关闭消费者对象
consumer.close();
}
}
}).start();
//这是一个死循环,一直在获取主题中的消息
while (true)
{
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records)
System.out.printf("收到消息: offset = %d, key = %s, value = %s%n",
record.offset(), record.key(), record.value());
}
}
}
Consumer02 消费者02
package cn.ljh;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
import java.util.Scanner;
//消费者02
public class Consumer02
{
//组id:设置这个消费者实例是属于 ConsumerGroupTest_02 这个消费者组的
public static final String GROUP_ID = "ConsumerGroupTest_02";
//1、创建 KafkaConsumer 消费者对象 ,把这个消费者定义成成员变量
public static KafkaConsumer<String, String> consumer = null;
public static void main(String[] args)
{
//Properties 中所设置的key,有效的value,可以通过Kafka官方文档来查询生产者API支持哪些配置属性
Properties props = new Properties();
//指定连接Kafka的地址,多个地址之间用逗号隔开
props.put("bootstrap.servers", "localhost:9092,localhost:9093,localhost:9094");
//设置这个消费者实例属于哪个消费者组
props.setProperty("group.id", GROUP_ID);
//自动提交offset,就是类似之前的自动消息确认
props.setProperty("enable.auto.commit", "true");
//多个消息之间,自动提交消息的时间间隔
props.setProperty("auto.commit.interval.ms", "1000");
//设置session的超时时长,默认是10秒,这里设置15秒
props.setProperty("session.timeout.ms", "15000");
//设置每次都从最新的消息开始读取
props.setProperty("auto.offset.reset","latest");
//设置序列化器
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//1、创建 KafkaConsumer 消费者对象
consumer = new KafkaConsumer<>(props);
//2、订阅主题,订阅kafka集群中的test2主题
consumer.subscribe(Arrays.asList(MessageProducer.TEST_TOPIC));
//因为获取消息的循环是一个死循环,没法退出,所以我在这里再加一个线程来关闭这个消费者
//启动一个线程来关闭这个 KafkaConsumer
new Thread(() ->
{
//创建一个Scanner 类来读取控制台数据
Scanner sc = new Scanner(System.in);
//如果有下一行,就读取下一行
while (sc.hasNextLine())
{
//获取控制台下一行的内容
var str = sc.nextLine();
//就是这个线程一直监听控制台,如果我们在控制台输出” :exit “,则关闭这个这个 KafkaConsumer
if (str.equals(":exit"))
{
//取消订阅
consumer.unsubscribe();
//关闭消费者对象
consumer.close();
}
}
}).start();
//这是一个死循环,一直在获取主题中的消息
while (true)
{
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records)
System.out.printf("收到消息: offset = %d, key = %s, value = %s%n",
record.offset(), record.key(), record.value());
}
}
}
MessageStream 流API 功能演示类
package cn.ljh;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.ValueMapper;
import java.util.Arrays;
import java.util.Properties;
//流API
public class MessageStream
{
//定义常量,这个是主题的常量
public static final String SOURCE_TOPIC = "test1";
public static final String TO_TOPIC = "test2";
public static void main(String[] args) throws InterruptedException
{
//1、使用StreamsBuilder创建KStream
StreamsBuilder builder = new StreamsBuilder();
//2、通过KStream设置sink主题、要流所做到转换处理。
// KStream提供了大量重载的flatMap()、map()、filter()……等方法对流进行转换,
// 调用这些处理方法时,通常都需要传入自定义的处理器,常使用Lambda表达式来定义这些处理器。
builder
//设置 source 主题,类似的源的主题
.<String, String>stream(SOURCE_TOPIC)
//这里的 mapValues 就是对消息(数据项、记录)进行转换处理(也可以理解为业务处理),这里我在消息前面加上 "【 ljh: " 这个字符串操作
//使用lambda表达式来构建转换器
//此处是一条消息,转换后也还是一条消息,只是在消息内容的前后添加特定的字符串
//.mapValues(value -> "【 ljh: " + value + " 】")
//此处使用匿名内部类构建转换器
.flatMapValues(new ValueMapper<String, Iterable<String>>()
{
@Override
//该方法的参数就代表传入的一个数据项(消息)
public Iterable<String> apply(String value)
{
//Arrays.asList : 把一个数组转换成list
//value.split("\\w+") :( 一条带有空格的消息)通过空格将消息分解成多个消息
//此处是一条消息,转换后变成多条消息
return Arrays.asList(value.split("\\W+"));
}
})
//设置sink主题:就是把test01主题的消息导流到这个test02主题
.to(TO_TOPIC);
//Properties: Kafka 设计了 Properties 来封装所有的配置属性
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "my-stream-processing-application");
//指定连接Kafka的地址,多个地址之间用逗号隔开
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093,localhost:9094");
//设置 key 的序列化器
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
//设置 value 的序列化器
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
//3、调用StreamsBuilder的build()方法创建代表流关系的Topology对像,该对象已经封装了通过KSteam所设置的source主题、sink主题等信息。
//如果还需要对流关系进行修改,也可调用Topology对象的addSource()、addSink()方法来添加source主题和sink主题。
Topology topology = builder.build();
System.err.println(topology.describe());
//4、以Topology为参数,创建KafkaStreams对象,创建该对象时,还需要传入一个Properties对象对该流进行配置。
KafkaStreams streams = new KafkaStreams(builder.build(), props);
//5、调用KafkaStreams对象的start()方法开始导流;导流结束后调用 close()方式关闭流。
//调用 KafkaStreams 对象的 start() 方法开始导流
streams.start();
System.err.println("---------开始导流----------");
//程序暂停300秒后停止导流
Thread.sleep(300 * 1000);
streams.close();
System.err.println("---------导流结束----------");
}
}
pom 依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.ljh</groupId>
<artifactId>kafkaproducertest</artifactId>
<version>1.0.0</version>
<!-- 项目名,和 artifactId 保持一致 -->
<name>kafkaproducertest</name>
<properties>
<!-- 在这里指定编译器的版本 -->
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<java.version>11</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- 导入 Kafka 客户端API的JAR包 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.6.1</version>
</dependency>
<!-- 导入Kafka 流API 的JAR包 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>3.6.1</version>
</dependency>
</dependencies>
</project>