【程序】给C++的cout和fstream添加Unicode支持,使其能向屏幕或文件输入/输出wchar_t字符串
【程序】
#include
#include
#include
#define RDBUF_LEN 200
using namespace std;
ostream &operator << (ostream &os, const wchar_t *wstr)
{
if (os == cout)
WriteConsoleW(GetStdHandle(STD_OUTPUT_HANDLE), wstr, wcslen(wstr), NULL, NULL); // 输出到屏幕上
else
{
// 此时wstr是UTF-16编码
// 将其转换为UTF-8编码后写入文件
int n = WideCharToMultiByte(CP_UTF8, NULL, wstr, -1, NULL, NULL, NULL, NULL);
char *p = new char[n];
WideCharToMultiByte(CP_UTF8, NULL, wstr, -1, p, n, NULL, NULL);
os.write(p, n - 1);
delete[] p;
}
return os;
}
ostream &operator << (ostream &os, wstring &ws)
{
os << ws.c_str();
return os;
}
istream &operator >> (istream &is, wstring &ws)
{
int n = 0;
wchar_t *wp;
if (is == cin)
{
/* 从控制台中输入一行字符串 */
bool complete = false;
DWORD dwRead; // 实际读到的字符个数
HANDLE hInput = GetStdHandle(STD_INPUT_HANDLE);
wp = NULL;
do
{
/* 分次循环读取, 直到遇到换行符 */
wp = (wchar_t *)realloc(wp, (n + RDBUF_LEN + 2) * sizeof(wchar_t)); // 分配内存时始终为\r\n预留空间
ReadConsoleW(hInput, wp + n, RDBUF_LEN + 2, &dwRead, NULL);
if (wp[n + dwRead - 2] == '\r')
{
wp[n + dwRead - 2] = '\0'; // 把\r换成\0, 并结束读取
complete = true;
// 注意: 当本次只读到\n一个字符时, wp[n + dwRead - 2]指向上一次读到的那一段的最后一个字符, 且一定是\r
// 例如: [abc][de\r][\n ], 此时RDBUF_LEN=1, 第二次读的时候n=3, dwRead=3, wp[3+3-2]=wp[4]是e而不是\r, 所以继续
// 第三次读的时候n=6, dwRead=1, wp[6+1-2]=wp[5]恰好是\r, 因此将\r替换成\0并退出循环
}
else
n += dwRead;
} while (!complete);
ws = wp;
free(wp);
}
else
{
/* 从文件中读取一行字符串 */
streampos start_pos = is.tellg(); // 记录开始读取的位置
char ch;
while (ch = is.get(), !is.eof() && ch != '\r' && ch != '\n')
n++; // 寻找换行符或文件结束符出现的位置
is.seekg(start_pos); // 回到开始位置
// 读取这一部分内容
char *p = new char[n + 1];
is.read(p, n);
p[n] = '\0';
// 使文件位置指针跳过换行符
while (ch = is.get(), !is.eof() && (ch == '\r' || ch == '\n'));
if (!is.eof())
is.seekg(-1, ios::cur);
// 转换成UTF-16编码
n = MultiByteToWideChar(CP_UTF8, NULL, p, -1, NULL, NULL);
wp = new wchar_t[n];
MultiByteToWideChar(CP_UTF8, NULL, p, -1, wp, n);
delete[] p;
ws = wp;
delete[] wp;
}
return is;
}
int main(void)
{
// 从控制台中输入Unicode字符串
wstring wstr;
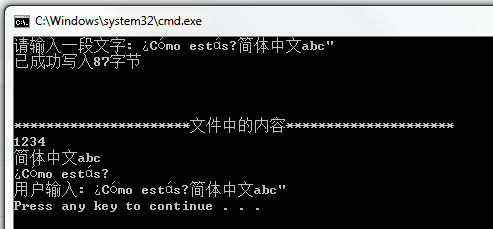
cout << L"请输入一段文字: ";
cin >> wstr;
// 打开文件并写入Unicode字符串
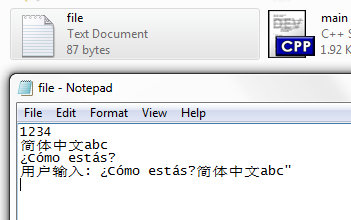
ofstream file("file.txt");
if (!file.is_open())
{
cout << L"文件打开失败" << endl;
return 0;
}
file << L"1234" << endl;
file << L"简体中文abc" << endl;
file << L"¿Cómo estás?" << endl;
file << L"用户输入: " << wstr << endl;
cout << L"已成功写入" << file.tellp() << L"字节" << endl;
file.close();
// 打开文件并从文件中读取Unicode字符串
ifstream ifile("file.txt");
cout << endl << endl << endl << L"**********************文件中的内容*********************" << endl;
while (!ifile.eof())
{
ifile >> wstr;
cout << wstr << endl; // 显示
}
ifile.close();
return 0;
} 【运行结果】
【输出的文件】
【背景知识】
char字符数组能存放任意编码的字符串
wchar_t在Windows系统下一般用来存放UTF-16编码的字符串,Linux下一般是UTF-32字符串
在C/C++中,"xxx"型的字符串的编码与源文件的编码格式一致,而L"xxx"则统一为UTF-16(Windows) / UTF-32(Linux)编码。
在Visual Studio中默认创建的源文件的编码格式是ANSI编码,所以char xxx[] = "xxx"的编码一般都是ANSI。
ANSI的编码格式并不固定,它只是一个编码映射。在简体中文Windows操作系统下,ANSI指向的是GB2312编码。由于英文版系统下ANSI并不指向GB2312编码,所以打开相关的文本文件就会显示为乱码,而打开UTF-8编码的文本文件就不会乱码。
Windows API函数都分为ANSI和Unicode版本。例如SetWindowTextA接受的是char字符数组,因为char字符数组一般都是ANSI编码,而SetWindowTextW接受的是wchar_t字符数组(默认UTF-16编码)
UTF-8、UTF-16和UTF-32是Unicode的三种实现方式。Unicode负责给每个字符编号,而这三种实现方式则按不同的方式存储其编号。
C/C++中自带的printf, cout等库函数都不能正确输出Unicode的字符串,因为它们在输出前都会将Unicode转换成ANSI,导致字符信息丢失,并且这个过程无法阻止。要想输出Unicode字符串只有调用Windows的API函数:WriteConsoleW。对于Unicode字符串的输入也有同样的问题。
本文就是把这个功能封装到了C++的cout里面。