数据库查询平台
一、前言
工作中,会经常需要进行数据库增删改查等操作,但是,目前公司的很多数据库在本机使用Navicat软件链接是没有权限的,只能通过另一个终端登录公司堡垒机后,再使用堡垒机的Navicat软件链接数据库查询。
二、当前环境/工具的不足
1、堡垒机的windows机器有个明显的缺点,多人使用的时候,会比较卡,而且还会被挤下线,或者登录不了,因为window的多人操作使用是有数量限制的。
2、数据库在堡垒机上面查询,属于共享资源,你离开一会,你之前写的sql语句,就已经被另外的同事改掉,或者查询窗口已经关了。
3、实际使用中,经常要在本机和堡垒机上面来回切回,而本机的一些复制,在堡垒机不能快速粘贴。
4、如果只是用本机的Navicat软件操作数据库,有些数据库在本机是没有权限链接的。
三、数据库查询平台解决方案
1、数据库查询平台部署在公司的Linux机器,支持多人使用,基本不会存在卡的问题(如果并发数高,那又另外的问题了)。
2、数据库平台的数据以列表形式展示,一个数据库链接可以多个人创建,并保存sql语句,写上备注,别人就不会随意修改。
3、在本机打开一个浏览器,输入链接就能使用数据库查询平台,来回无缝切换。
5、数据库查询平台部署在公司堡垒机里面的Linux机器,堡垒机Windows能链接的,数据库查询平台都能链接,不存在没有权限的问题。
总结:数据库查询平台解决了,本机Navicat软件链接数据库没有权限的问题,同时解决了堡垒机使用体验差的问题,补全两者的短板。
四、数据库查询平台使用介绍:
1、链接:后续部署阿里云服务器后更新
2、数据库查询平台后端用的是python3语言开发、web框架-Django,前端以Html5、js、jquery、bootstrap实现,数据库为djano自带的数据库。
3、页面信息展示:
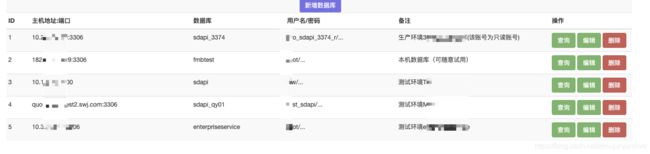
4、新增数据库
填写完数据库信息,支持测试链接是否连接成功,点击“确定”,保存到页面。

5、删除、编辑
删除,就是删除该条数据库链接。编辑,修改保存时候的信息,比如想修改备注信息,可以在编辑里面修改
6、查询
查询,其实不只是查询,支持增删改查,所以这个文案,需要想想改成什么更合适。
页面展示当前弹框操作的数据库主机地址/数据库,右上角:执行-运行sql语句,clear-清空输入框sql语句,保存-保存输入框的sql语句,取消-不保存输入框的内容。
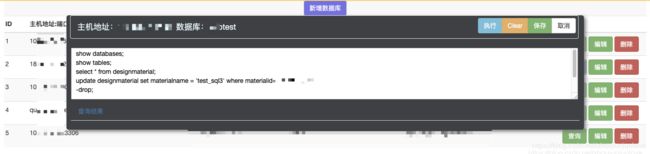
重点说一下,这里的输入框写法逻辑:
前端逻辑:
(1)输入框直接输入sql语句就可以,但是,如果需要执行该条语句,需要在语句前面没有空格加上横杆 - ,而且语句结尾需要加上分号。每条不同的sql语句,需要换行写。
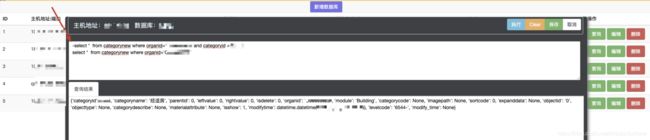
(2)update/delete 语句如果没有填写where,前端做了限制,会弹框提示需要填写where条件,避免操作全表。drop语句是不支持的,前端会提示不支持drop语句,避免误操作(这个就是定制的好处了,下载市场上的软件是没有这点的)。
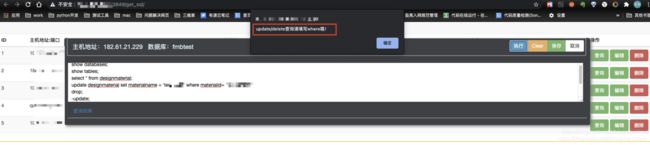

(3)点击“执行”,接口响应没有完成,“执行”按钮会置灰不可点击,等到接口响应完成,才可点击。

附上部分前端js代码:
后端逻辑:
后端会在查询接口添加一个判断函数是否超时的装饰器,如果查询的数据量太大,超过了5s,会直接终止执行的接口,并返回超时信息给前端(同样是定制的功能,市场上的软件是没有的),因为后端写了一个for 循环会比较耗性能,而且python语言本身的运行效率不是很出色,所以写sql的语句,最好带上多个条件,就可以秒出结果了。

附上部分后端sql语句执行代码:
def query_sql(request):
query_sql_id = request.GET['query_sql_id']
db_sql = request.GET['query_sql']
query_sql_data = db_data.objects.filter(id=query_sql_id).values()[0]
db_host = query_sql_data["db_host"]
db_count = query_sql_data["db_count"]
db_paswd = query_sql_data["db_paswd"]
db_port = query_sql_data["db_port"]
db_database = query_sql_data["db_database"]
db_method = query_sql_data["db_method"]
db_bz = query_sql_data["db_bz"]
def connect_db():
try:
db = pymysql.connect(db_host, db_count, db_paswd, db_database, port=int(db_port), charset='utf8')
cursor = db.cursor()
return db, cursor
except Exception as e:
return HttpResponse(str(e))
def get_index_dict():
"""
获取数据库对应表中的字段名
"""
index_dict = dict()
index = 0
for desc in cursor.description:
index_dict[desc[0]] = index
index = index + 1
return index_dict
def get_dict_data_sql(sql):
"""
运行sql语句,获取结果,并根据表中字段名,转化成dict格式(默认是tuple格式)
"""
cursor.execute(sql)
data = cursor.fetchall()
index_dict = get_index_dict()
res = []
for datai in data:
resi = dict()
for indexi in index_dict:
resi[indexi] = datai[index_dict[indexi]]
res.append(resi)
# print(res)
return res
@timeout_decorator.timeout(5,use_signals=False,exception_message="查询时间已超过5s,请输入更精确的查询条件哦!")
def selcect_db(sql):
ret = get_dict_data_sql(sql)
print(ret)
return (ret)
def update_db(sql):
print(sql)
try:
# 执行sql语句
cursor.execute(sql)
# 获取结果
result = cursor.fetchone()
# print(result)
db.commit()
result = '执行成功!'
except Exception as e:
# 如果发生错误则回滚
result = '执行失败!ERROE:' + str(e)
db.rollback()
return result
try:
db, cursor = connect_db()
if 'update' in db_sql or 'delete' in db_sql or 'create' in db_sql or 'insert' in db_sql:
ret = update_db(db_sql)
db.close()
return HttpResponse(ret)
else:
ret = selcect_db(db_sql)
db.close()
return HttpResponse(ret)
except Exception as e:
return HttpResponse(e)
五、后言
数据库查询平台的功能,相对于来说是比较简单的。但是几乎可以代替使用公司堡垒机查询数据库了(目的也是如此),如果是数据库深入使用的就另外说了。
功能虽然简单,但是从构思需求——架构——后端开发——前端开发——部署——调优,对于一个人来说,还是有不少工作量的。每行代码都是手打出来,除了功能参考Navicat软件,其他的定制都是个人在日常工作中遇到的疼点进行定制开发的。加班、放假的时间做出来的东西,前后花了差不多一个月时间 ==
如果习惯了堡垒机的使用,觉得没必要再增加成本去用一个新的东西,也是可以理解。但是,如果遇到像我一样的问题的时候,可以来试下这个平台,可能会有不一样的体验。平台是刚刚完成,我也没有使用过很长的时间,欢迎来提bug或者需求,如果我能做的。