数据采集与预处理02 :网络爬虫实战
数据采集与预处理02 :网络爬虫实战
爬虫基本知识
1 HTTP的理解
URL uniform resource locator. 是统一资源定位符,URI identifier是统一资源标识符。几乎所有的URI都是URL。
URL前部一般可以看到是HTTP还是HTTPS, 这是访问资源需要的协议类型。HTTP hyper text transfer protocol 是客户端和服务器端请求和应答的标准,是互联网中应用最为广泛的一种协议。
HTTPS是以安全为目标的HTTP通道,加入了SSL层。
2 网页基础知识
网页的组成分为三大部分,HTML、CSS(Cascading Style sheets)层叠样式表、javascript。
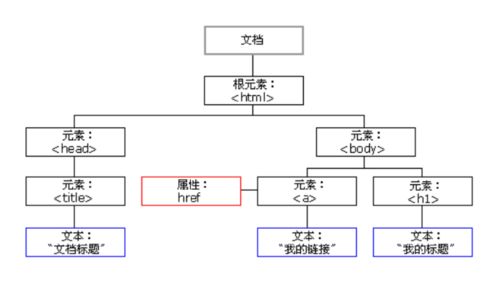
在网页中,组织页面的对象被渲染成一个树形结构,用来标识文档中对象的准确模型,称为文档对象模型 Document Object Model DOM。
3 爬虫基本原理
网络爬虫本质上就是获取网页并提取和保存信息的自动化程序。
爬虫的首要工作就是获取网页源代码,再从中提取想要的数据。urllib requests等库都能够实现HTTP请求的操作。
获取网页源代码后,接下来的工作就是分析网页源代码,最通用的方式是使用正则表达式。在python中,使用BeautifulSoup PyQuery LXML等库,可以更高效的从源代码中提取网页信息。
提取信息之后,可以将数据保存到本地,以便后续使用。

4. 基本库的使用
以下基于python3.8
4.1 urllib
urllib库是python中一个功能强大,用于操作URL并在制作爬虫过程中经常用到的库。
发送请求:
import urllib.request
r=urllib.request.urlopen("HTTP://www.python.org/")
print(r)
读取响应内容
import urllib.request
url="HTTP://www.python.org/"
with urllib.request.urlopen(url) as r:
r.read()
r.read() 将相应内容读到内存。
传递URL参数
import urllib.request
import urllib.parse
params=urllib.parse.urlencode({'q':'urllib','check_keywords':'yes','area':'default'})
url="HTTPS://docs.python.org/3/search.html?{}".format(params)
r=urllib.request.urlopen(url)
传递中文参数
import urllib.request
searchword=urllib.request.quote(input("请输入要查询的关键字:"))
url="HTTPS://cn.bing.com/images/async?q={}&first=0&mmasync=1".format(searchword)
r=urllib.request.urlopen(url)
print(r)
定制请求头
import urllib.request
url="链接"
headers={
'User-Agent':……
'Referer':……
req=urllib.request.Request(url,headers=headers)
r=urllib.request.urlopen(req)
}
传递POST请求
import urllib.request
import urllib.parse
url="链接"
post={
'username':'xxx'
'password':'xxxxx'
}
postdata=urllib.parse.urlencode(post).encode('utf-8')
req=urllib.request.Request(url,postdata)
r=urllib.request.urlopen(req)
下载远程数据到本地
urllib.request.urlretrieve(url,"python-logo.png)
另外患有设置代理、异常处理和Cookie的使用,不再赘述。
4.2 BeautifulSoup
BeautifulSoup提供一些简单的,python方式的函数处理导航、搜索、修改分析树等功能。
创建BeautifulSoup对象
from bs4 import BeautifulSoup
soup=BeautifulSoup(html)
print soup.prettify()
四大对象类
BeautifulSoup将复杂的HTML文档转换称为一个复杂的树形结构,归纳为4种:Tag , NavigableString, BeautifulSoup, Comment.
Tag就是一个个标签。
print soup.title
print soup.head
print soup.a
print soup.p
NavigalbeString
不仅可以得到标签内容,还可以通过“.string”获取标签内部的文字。
print soup.p.string
BeautifulSoup
BeautifulSoup对象表示一个文档的全部内容。
print type(soupp.name)
comment
comment对象是一个特殊类型的NavigableString对象,其输出内容不包括注释符号。
遍历
Tag的contents属性可以使Tag的子节点以列表方式输出。
print soup.head.contents
print soup.head.contents[0]
Tag的children返回的不是一个list,而是list生成器对象,可以用来遍历获取所有子节点。
descendants可以对所有子孙结点进行递归循环。
如果Tag只有一个NavigableString类型的子节点,那么Tag可以使用string得到子节点。
使用.stripped_strings可以去除多余空白内容。
使用元素的.parent属性可以获取父节点。
搜索
使用 find_all()搜索
- name参数 用来查找所有名称为name的tag。
#传字符串
soup.find_all('b')
# 传正则表达式
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
#传列表
soup.find_all(["a","b"])
#传True
for tag in soup.find_all(True):
print(tag.name)
- attrs参数
data_soup.find_all(data-foo="value")
data_soup.find_all(attrs={"data-foo":"value"})
- recursive参数
soup.html.find_all("title",recursive=False)
# recursive=True意味着直接检索子节点
- text参数
通过text参数可以搜索文档中的字符串内容。
soup.find_all(text="test1")
- limit参数
soup.find_all("a",limit=2)
#限制返回数量
select()
使用soup.select()方法从css中筛选,返回类型是list。
print soup.select('title')
print soup.select("a")
print soup.select(#id值)
print ("head>title")