Day11学习记录
#c语言知识
函数
1.定义:
返回值类型 函数名(参数列表)
{
代码体
return;
}
在定义函数时指定的形参,可有可无,根据需求来设计,如果没有,圆括号为空,或者写一个void关键字。

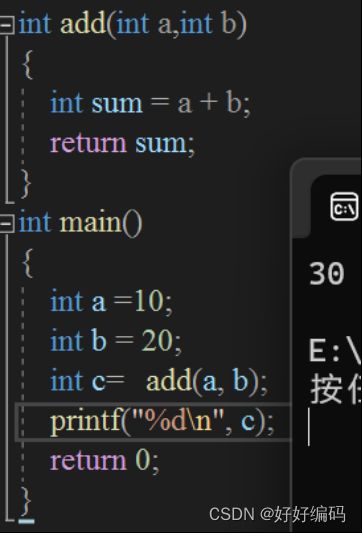
2.函数调用
(1)在不同函数中,函数的变量可以重名,因为作用域不同。
(2)函数调用过程中传递的参数称为实参(实际参数),有具体的值。
(3)函数定义中的参数成为形参(形式参数)。
(4)在函数调用过程中,将实参传递给形参。
(5)函数调用结束后,函数会在内存中销毁(在栈区自动销毁),无需维护。
3.返回值
return后面可以是一个表达式。(尽量保证表达式的值和函数返回值类型是同一类型;如果不一致,则以函数返回类型为准,即函数返回类型决定返回值的类型。对数值型数据,可以自动进行类型转换。)
4.形参与实参
(1)形参出现在函数定义中,在整个函数体内都可以使用,离开该函数则不能。
(2)实参出现在主调函数中,进入被调函数后,实参也不能被使用。
(3)实参变量对形参变量的数据传递是“值传递”,即单向传递,只由实参传给形参,而不能由形参传回来给实参。(通过寄存器传过去之后就被销毁了,传不回来了)
(4)实参单元与形参单元是不同的单元。在调用函数时,编译系统临时给形参分配存储单元。调用结束后,形参单元被释放,函数调用结束返回主调函数后,则不能再使用该形参变量。实参单元保留并维持原值。因此,在执行一个被调用函数时,形参的值如果发生改变,不会改变主调函数中实参的值。
5.字符串比较

6.无参函数调用
圆括号不能省略
7.有参函数调用
(1)如果实参多,各参数间用逗号分隔开。
(2)实参与形参的个数应相等,类型应相匹配(相同或赋值兼容)。实参与形参按顺序对应,一对一地传递数据。
(3)实参可以是常量、变量或表达式。无论实参是何种类型的量,在进行函数调用时,它们都必须具有确定的值,以便把这些值传送给形参。所以这里的变量是在()外定义好、赋好值的变量。
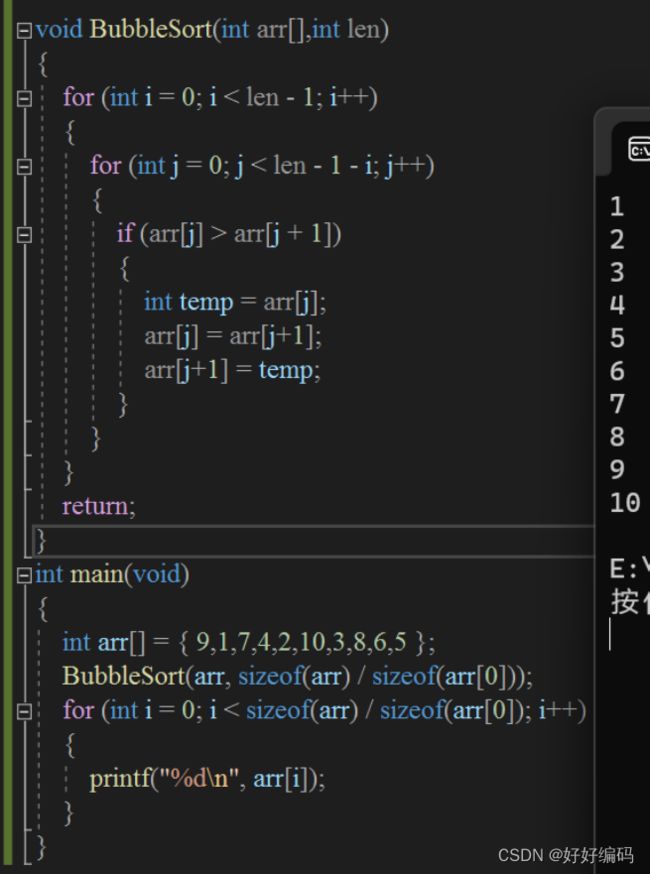
*冒泡排序(函数版)
*void 空类型
不可以直接定义数据,可以作为数据的返回值类型。
void main(void) 无参无返函数
8.函数的声明
*声明——定义——调用
(定义的函数放在主函数之前,可以不用声明;放在主函数之后需要先声明。)
*可多次调用、多次声明,但只能一次定义。
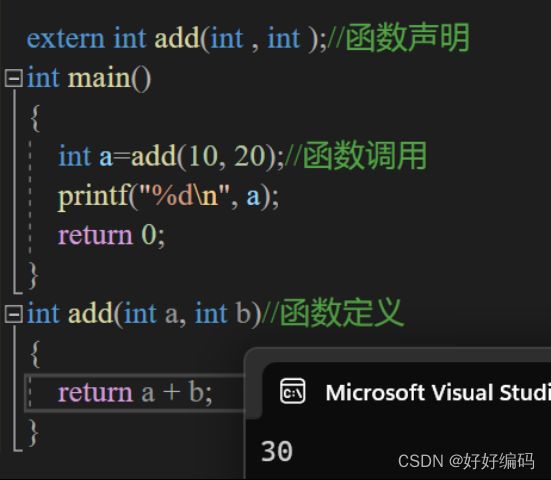
**声明和定义的区别:
声明不需要建立存储空间,如:extern int a;
定义需要建立存储空间,如:int b;
(声明中包含着定义,即定义是声明的一个特例,所以并非所有声明都是定义。)
***exit() 结束当前进程/当前程序/,在整个程序中,只要调用 exit ,就结束。
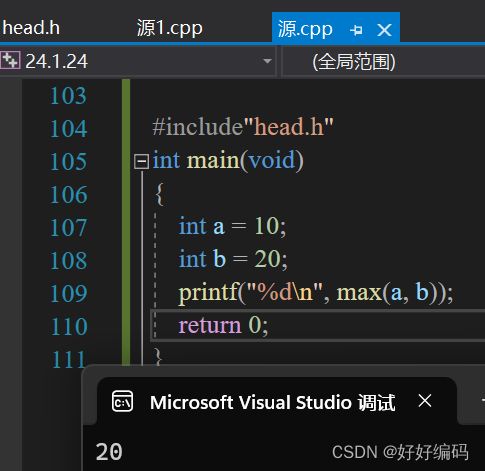
9.多文件编程


指针
1.
(1)存储器:用来存储程序和数据,辅助CPU进行运算处理的重要部分。
(2)内存:内部存储器,暂存程序/数据——掉电丢失SRAM、DRAM、DDR、DDR2、DDR3。
(3)外存:外部存储器,长时间保存程序/数据——掉电不丢失ROM、ERRROM、FLASH(NAND、NOR)、硬盘、光盘。
*内存时沟通CPU与硬盘的桥梁
暂存CPU中的运算数据;暂存与硬盘等外部存储器交换的数据。
2.物理存储器和存储地址空间
(1)物理存储器:实际存在的具体存储器芯片。
*主板上装插的内存条
*显示卡上的显示RAM芯片
*各种适配卡上的RAM芯片和ROM芯片
(2)存储地址空间:对存储器编码的范围(常说的内存)
*编码:对每个物理存储单元(一个字节)分配一个号码
*寻址:可以根据分配的号码找到相应的存储单元,完成数据的读写。
3.内存地址
(1)将内存抽象成一个很大的一维字符数组。
(2)编码就是对内存的每一个字节分配一个32位或64位的编号(与32位或64位处理器相关)。这个内存编号我们称之为内存地址。
(3)内存中每一个数据都会分配相应的地址:
char:占一个字节,分配一个地址。
int:占四个字节,分配四个地址。
float、struct、函数、数组等。
4.指针大小
(1)可通过指针p间接修改变量的值
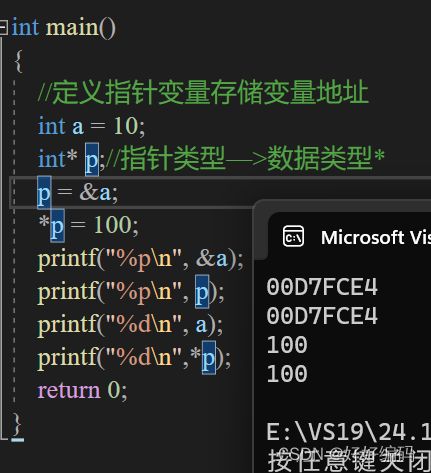
(2)所有的指针类型存储的都是内存地址。
所有的地址都是一个无符号十六进制整型数。
(3)使用sizeof()测量指针的大小,得到的总是4/8。
sizeof()测的是指针变量指向存储地址的大小。
在32位操作系统下,所有指针(地址)都是4字节大小;
在64位操作系统下,所有指针(地址)都是8字节大小。
#行业信息
1.网络爬虫
一种可以从网页上抓取数据信息并保存的自动化程序。它的原理就是模拟浏览器发送网络请求,接受请求响应,然后按照一定的规则自动抓取互联网数据。
(1)获取网页
获取网页可以简单理解为向网页的服务器发送网络请求,然后服务器返回给我们网页的源代码,其中通信的底层原理较为复杂,而Python给我们封装好了urllib库和requests库等,这些库可以让我们非常简单的发送各种形式的请求。
(2)提取信息
获取到的网页源码内包含了很多信息,想要进提取到我们需要的信息,则需要对源码还要做进一步筛选。可以选用python中的re库即通过正则匹配的形式去提取信息,也可以采用BeautifulSoup库(bs4)等解析源代码,除了有自动编码的优势之外,bs4库还可以结构化输出源代码信息,更易于理解与使用。
(3)保存数据
提取到我们需要的有用信息后,需要在Python中把它们保存下来。可以使用通过内置函数open保存为文本数据,也可以用第三方库保存为其它形式的数据,例如可以通过pandas库保存为常见的xlsx数据,如果有图片等非结构化数据还可以通过pymongo库保存至非结构化数据库中。
(4)让爬虫自动运行
从获取网页,到提取信息,然后保存数据之后,我们就可以把这些爬虫代码整合成一个有效的爬虫自动程序,当我们需要类似的数据时,随时可以获取。
2.几种常见的人工智能模型
决策树(Decision Trees)、支持向量机(Support Vector Machines, SVM)、朴素贝叶斯(Naive Bayes)、线性回归(Linear Regression)、逻辑回归(Logistic Regression)和神经网络(Neural Networks)等。
贝叶斯公式:
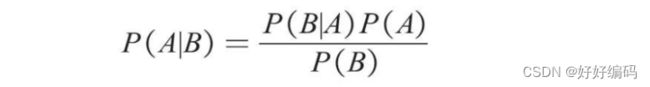
在2个特征变量的基础上将贝叶斯公式推广至n个特征变量X1,X2,…,Xn,公式如下。
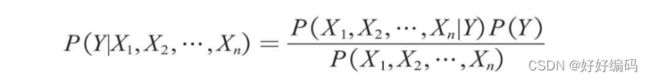
朴素贝叶斯模型属于分类模型,所以也可以利用ROC曲线来评估其预测效果。( ROC曲线:对学习器的泛化性能评估,针对某种具体任务(样本)评估模型性能)
朴素贝叶斯模型是一种非常经典的机器学习模型,它主要基于贝叶斯公式,在应用过程中会把数据集中的特征看成是相互独立的,而不需考虑特征间的关联关系,因此运算速度较快。相比于其他经典的机器学习模型,朴素贝叶斯模型的泛化能力稍弱,不过当样本及特征的数量增加时,其预测效果也是不错的。(在机器学习方法中,泛化能力通俗来讲就是指学习到的模型对未知数据的预测能力。)