图像处理深度学习python代码改写成c++推理
目录
前言
一、模型导出与导入
导出模型
加载模型
一、代码改写
ONNX模型
总结
前言
深度学习的代码一般采用python编写,因为python有很多开源的库可以直接引用,但是如果对推理速度有更高的要求,可以采用c++编写推理代码。相比python,c++运行速度更加快,但是需要编译环境,而且第三方的库没有python完善。所以,究竟要使用哪一种语言,可以根据自己的应用场景和使用目的来选择。
如果我们需要用c++来推理,而源代码又只有python版本,那么就需要我们来改写。首先我们需要在python代码中将模型训练好,或者使用预训练模型。接下来我将从两个方面讲述移植的过程。
一、模型导出与导入
python训练出来的模型是没有办法直接在c++上使用的,所以我们需要对模型做一定的处理。对于pytorch框架的模型,c++有libtorch。libtorch是pytorch的C++版本,支持CPU端和GPU端的部署和训练。由于python和c++的语言特性,因此用pytorch做模型训练,libtorch做模型部署。首先我们需要在python代码中将模型用litorch导出,然后在c++代码中加载运行。
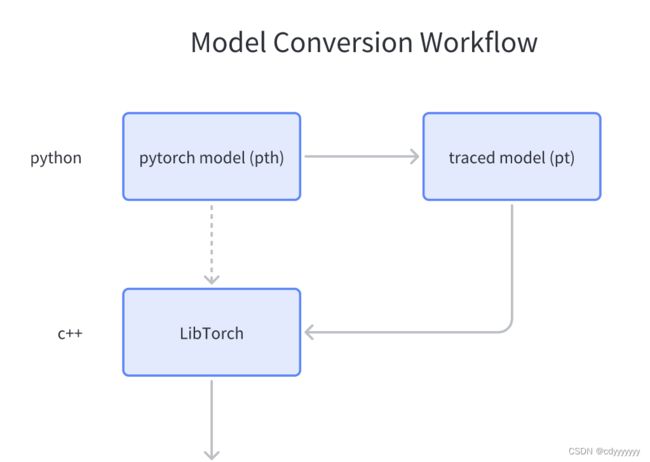
导出模型
导出模型的代码一定要在加载模型权重之后,不然导出的模型是没有权重参数的。导出代码如下:
## 导出模型
model_ = torch.jit.trace(model.eval(), torch.randn(1, 3, 256, 256))
torch.jit.save(model_,'model.pt')torch.jit.trace函数的第一个参数是需要导出的模型(torch.nn.Model),第二个参数是模型的输入(torch.Tensor)。导出的原理是跟踪模型输入,记录所有执行到图形中的操作。输入张量的内容可以是随机的,但是尺寸必须符合模型规定的输入大小。
torch.jit.save函数的第一个参数是torch.jit.trace函数的输出,第二个参数是保存模型的路径及名字。
运行成功后,将会在指定路径下生成一个pt文件,这就是我们需要的模型。
加载模型
在c++代码中,我们将导出的模型加载推理。加载代码如下:
// 加载模型
model = torch::jit::load("model_.pt");
model.to(torch::kCUDA); //加载到gpu运行可以指定加载的模型在cpu还是gpu运行,如果模型加载到gpu上,那么之后输入模型的数据也需放在gpu上。
二、代码改写
对于图像的处理,python代码中可能会使用opencv、numpy、PIL、skimage等库,但是在c++中我们没有那么多开源的库可以使用,而且配置这些库也比较麻烦。其实对于图像的操作,我们基本上可以用opencv来实现,我们需要做的就是,看懂python代码对图像或者张量的处理,然后用opencv将其实现。所以我们的c++代码运行环境必须配备opencv。
opencv表示图像的数据类型是cv::Mat,而模型输入需要的数据类型是torch::Tensor,所以我们最后需要转化数据类型。整体的数据流如下图所示:
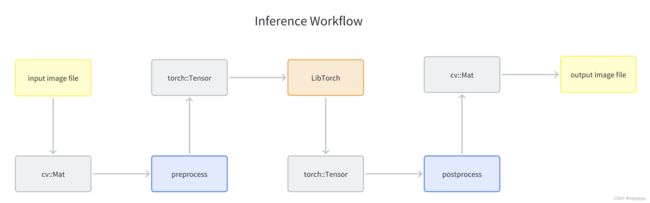
根据不同代码的图片预处理和后处理,我们需要写出对应的opencv代码。下面我举例几个图像或者张量的操作。
cv:Mat image,input,output;
// 读图片
image = cv::imread("1.jpg");
// 8U 转 32F
input.convertTo(output, CV_32FC3, 1.0 / 255.);
// 32F 转 8U
input.convertTo(output, CV_8UC3,255);
// 调整图片大小
cv::resize(input, output, cv::Size(H, W));
// 图片颜色描述空间转换
cv::cvtColor(input, output, cv::COLOR_BGR2Lab); //opencv一开始读进来的图片是BGR格式的
cv::cvtColor(input, output, cv::COLOR_BGR2RGB);
cv::cvtColor(input, output, cv::COLOR_BGR2GRAY);
// 截取某一个通道
cv::extractChannel(input, output, 0);
cv::extractChannel(input, output, 1);
cv::extractChannel(input, output, 2);
// 拆分通道
std::vector Channels(3) ;
cv::split(input, Channels);
// 合并通道
std::vector Channels;
Channels.push_back(通道0);
Channels.push_back(通道1);
Channels.push_back(通道2);
cv::merge(Channels,output);
// 保存图片
cv::imwrite("1.jpg", image); 另外,还涉及到cv::Mat和torch::Tensor互相转换的问题,这里我提供两个转换函数仅供参考。
cv::Mat tensor2mat(torch::Tensor tensor, bool show = false)
{
torch::Tensor ten=tensor.to(torch::kCPU);
int H, W;
H = ten.size(2);
W = ten.size(3);
int channel = ten.size(1);
int index = 0;
float *rst_data = ten.data_ptr<float>();
cv::Mat ret = cv::Mat::zeros(H, W, CV_32FC3); //三通道
// 不同tensor的排列方式不同,请根据实际排列方式修改下面代码
// ============================================================
for (int h = 0; h < H; h++)
{
for (int w = 0; w < W; w++)
{
for (int c = 0; c < channel; c++)
{
float val = rst_data[index];
ret.at(h, w)[c] = val;
index++;
}
}
}
// ==============================================================
if (show) // 打印结果
{
cout << endl
<< "===================== Tensor ============================="
<< endl;
cout << endl << ten;
cout << endl
<< "===================== Mat ============================="
<< endl;
cout << ret << endl;
}
return ret;
}
torch::Tensor mat2tensor(cv::Mat mat, bool show = false)
{
torch::Tensor ret;
ret = torch::from_blob(mat.data,
{1, mat.rows, mat.cols, mat.channels()},
torch::TensorOptions().dtype(torch::kFloat32));
ret = ret.permute({0, 3, 1, 2}).to(torch::kCUDA);
if (show) // 打印结果
{
cout << endl
<< "===================== Mat ============================="
<< endl;
cout << endl << mat;
cout << endl
<< "======================Tensor ============================"
<< endl;
cout << ret << endl;
}
return ret;
}c++模型推理代码:
// 推理
std::vector input_tensor = {输入的tensor};
torch::Tensor output = model.forward(input_tensor).toTensor(); ONNX模型
以上主要针对于pytorch框架的移植,如果使用的是其他框架,则可以使用ONNX模型。无论你使用什么样的训练框架来训练模型(比如TensorFlow/Pytorch/OneFlow/Paddle),你都可以在训练后将这些框架的模型统一转为ONNX存储。 ONNX文件不仅存储了神经网络模型的权重,还存储了模型的结构信息、网络中各层的输入输出等一些信息。 然后将转换后的ONNX模型,转换成我们需要使用不同框架部署的类型,通俗来说ONNX 相当于一个翻译。
如果使用ONNX模型,则需修改模型导出代码。ONNX模型可以使用opencv加载运行,需要注意的是,用opencv加载模型后,模型的输入输出就不再是Tensor,而是Mat了。这里的Mat需要使用cv::dnn::blobFromImage()函数进行转化。
opencv加载ONNX模型相关函数具体详见:函数详解
其他相关教程详见:ONNX相关教程
举例将pytorch模型导出为ONNX格式的代码:
# 导出onnx模型
torch.onnx.export(model,
torch.randn(1, 3, 256, 256), # 模型输入
"siggraph17.onnx", # 模型名字
export_params=True, # 导出模型参数
input_names=['input'],
output_names=['output'],
dynamic_axes={'input':{0:'N', 2:'H', 3:'W'},'output':{0:'N', 2:'H',3:'W'}}, # 设置动态的维度
opset_version=11)
c++模型推理代码:
model.setInput(input);
cv::Mat output = model.forward();总结
以上就是我在python->c++中的经验和总结,如有问题望指正,欢迎找我探讨。