阅读记录:RNNLOGIC: LEARNING LOGIC RULES FOR REASON-ING ON KNOWLEDGE GRAPHS
一、介绍
本文研究知识图谱推理的学习逻辑规则。
逻辑规则在用于预测时提供可解释的解释,并且能够推广到其他任务。现有方法要么面临在大搜索空间中搜索的问题(例如神经逻辑编程),要么由于奖励稀疏而导致优化无效(例如基于强化学习的技术)。为了解决这些限制,本文提出了一种称为 RNNLogic 的概率模型。 RNNLogic 将逻辑规则视为潜在变量,同时用逻辑规则训练规则生成器和推理预测器。
本文开发了一种基于 EM 的优化算法。在每次迭代中,首先更新推理预测器以探索一些生成的推理逻辑规则。然后在E步骤中,通过后验推理从规则生成器和推理预测器生成的所有规则中选择一组高质量规则;在M步骤中,规则生成器根据E步骤中选择的规则进行更新。
本文研究知识图谱推理的学习逻辑规则。例如,可以提取一条规则∀X, Y, Z hobby(X, Y)←friend(X, Z) ∧ hobby(Z, Y),这意味着如果Z是X的朋友并且Z有爱好Y,那么Y也可能是X的爱好。然后可以应用该规则来推断人们的新爱好。这样的逻辑规则能够提高推理的可解释性和精确度。
RNNLogic由规则生成器和具有逻辑规则的推理预测器组成,它们同时经过训练以相互增强。规则生成器提供逻辑规则供推理预测器进行推理,而推理预测器提供有效的奖励来训练规则生成器,这有助于显着减少搜索空间。具体来说,对于每个查询-答案对,例如 q = (h, r, ?) 和 a = t,对以查询和现有知识图谱 G 为条件的答案概率进行建模,即 p(a|G, q ),其中一组逻辑规则 z 被视为隐变量。规则生成器为每个查询定义逻辑规则的先验分布,即 p(z|q),它由循环神经网络参数化。推理预测器计算以逻辑规则和现有知识图 G 为条件的答案的可能性,即 p(a|G, q, z)。在每次训练迭代中,首先从规则生成器中采样一些逻辑规则,并进一步更新推理预测器以尝试这些规则进行预测。然后使用 EM 算法来优化规则生成器。在E步中,根据后验概率从所有生成的规则中选择一组高质量的逻辑规则。在M步骤中,规则生成器被更新以模仿E步骤中选择的高质量规则。
二、方法
大多数传统方法将查询实体和答案实体之间的关系路径枚举为候选逻辑规则,并进一步学习每个规则的标量权重来评估质量,然而同时学习逻辑规则及其权重并不利于优化。
另一种规则学习方法是基于强化学习的。总体思路是训练寻路代理,在知识图谱中搜索推理路径来回答问题,然后从推理路径中提取逻辑规则。然而,训练有效的寻路代理非常具有挑战性,因为奖励信号(即路径是否以正确答案结束)可能非常稀疏。
给定 G 和查询 q,目标是预测正确答案 a。更正式地说,目标是对概率分布 p(a|G, q) 进行建模。在 RNNLogic 中,将一组逻辑规则视为必须推断的潜在变量,这些规则可以将查询解释为潜在变量。为此,引入了规则生成器和使用逻辑规则的推理预测器。
给定一个查询,规则生成器使用循环神经网络生成一组逻辑规则,并将其提供给推理预测器进行预测。使用基于 EM 的算法优化 RNNLogic。在每次迭代中,从更新推理预测器开始,尝试规则生成器生成的一些逻辑规则。然后在 E 步骤中,通过后验推理、来自规则生成器的先验和来自推理预测器的似然,从所有生成的规则中识别出一组高质量规则。最后,在 M 步骤中,使用已识别的高质量规则更新规则生成器。
2.1 概率形式化
首先以概率的方式形式化知识图谱推理,其中一组逻辑规则 z 被视为隐变量。目标分布 p(a|G, q) 由规则生成器和推理预测器联合建模。
规则生成器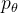 定义了以查询 q 为条件的一组潜在规则 z 的先验。
定义了以查询 q 为条件的一组潜在规则 z 的先验。
推理预测器![]() 给出了以潜在规则 z、查询 q 和知识图 G 为条件的答案 a 的可能性(后验概率)。
给出了以潜在规则 z、查询 q 和知识图 G 为条件的答案 a 的可能性(后验概率)。
因此 ![]() (目标分布)可以计算如下:
(目标分布)可以计算如下:
![]()
目标是联合训练规则生成器和推理预测器,以最大化训练数据的可能性。形式上,目标函数如下所示:

2.2 规则生成器
规则生成器定义分布 pθ(z|q)。对于查询 q,规则生成器旨在生成一组潜在逻辑规则 z 用于回答查询。给定一个查询 q = (h, r, ?),通过仅考虑查询关系 r 而不考虑查询实体 h 来生成组合逻辑规则,这使得生成的规则可以跨实体泛化。对于缩写形式 r ← r1 ∧···∧rl 中的每个组合规则,可以将其视为关系序列 [r, r1, r2 ··· rl, rEND],其中 r 是查询关系或规则head、![]() 是规则的主体,rEND 是表示关系序列结束的特殊关系。
是规则的主体,rEND 是表示关系序列结束的特殊关系。
这种关系序列可以通过RNN进行建模。引入 ![]() 来参数化规则生成器。给定一个查询关系 r,
来参数化规则生成器。给定一个查询关系 r,![]() 顺序生成规则主体中的每个关系,直到到达结束关系 rEND。在此过程中,同时计算生成规则的概率。有了这样的规则概率,将一组规则 z 上的分布定义为多项分布:
顺序生成规则主体中的每个关系,直到到达结束关系 rEND。在此过程中,同时计算生成规则的概率。有了这样的规则概率,将一组规则 z 上的分布定义为多项分布:
多项分布是二项分布的推广,二项分布的实验结果有两个,多项分布的结果多于两个,如果有三个结果就是三项分布,如果有六个结果就是六项分布。
![]()
Mu 代表多项分布,N 是集合 z 大小的超参数,![]() 定义规则头为 r 的组合规则上的分布。规则集 z 的生成过程非常直观,只需用
定义规则头为 r 的组合规则上的分布。规则集 z 的生成过程非常直观,只需用![]() 生成 N 条规则即可形成 z。
生成 N 条规则即可形成 z。
2.3 推理预测器
推理预测器定义为 ![]() 。对于查询 q,预测器使用一组规则 z 在知识图 G 上进行推理并预测答案 a。
。对于查询 q,预测器使用一组规则 z 在知识图 G 上进行推理并预测答案 a。
遵循随机逻辑编程这一原则性推理框架,文章使用对数线性模型进行推理。对于每个查询 q = (h, r, ?),组合规则能够在图 G 上找到不同的基础路径,从而得出不同的候选答案。
例如,给定查询(Alice,爱好,?),规则爱好←朋友∧爱好可以有两个基础,爱好(Alice,Sing)←朋友(Alice,Bob)∧爱好(Bob,Sing)和 爱好(Alice, Ski)←朋友(Alice, Charlie)∧ 爱好(Charlie,Ski),产生两个候选答案 Sing 和 Ski。
设A是可以通过集合z中的任何逻辑规则发现的候选答案的集合。对于每个候选答案 e ∈ A,计算该候选的以下标量 ![]() :
:

直观来看,每个候选答案e的得分是每个规则贡献的得分之和,也就是 ![]() ,通过对G中的基路径求和得到。
,通过对G中的基路径求和得到。
![]() 是一组基础路径,从h开始到e结束。例如:
是一组基础路径,从h开始到e结束。例如:![]() 。
。
![]() 是每条规则的标量权重,是一个可学习的变量。
是每条规则的标量权重,是一个可学习的变量。
![]() 是路径的标量权重,是特定路径的得分。文章提出了两种参数化的方法。一种方法总是设置为1。但是,该方法无法区分不同的关系路径。另一种方法,遵循嵌入算法 RotatE为每个实体引入嵌入,并将每个关系建模为实体嵌入的旋转运算符。
是路径的标量权重,是特定路径的得分。文章提出了两种参数化的方法。一种方法总是设置为1。但是,该方法无法区分不同的关系路径。另一种方法,遵循嵌入算法 RotatE为每个实体引入嵌入,并将每个关系建模为实体嵌入的旋转运算符。
对于从 h 到 e 的规则的每个基础路径,如果根据规则的主体关系定义的旋转运算符来旋转 h 的嵌入,应该是期望获得接近 e 的嵌入的嵌入。因此,计算导出的嵌入与 e 的嵌入之间的相似度为 ![]() ,被视为每条路径的健全性和一致性的度量。
,被视为每条路径的健全性和一致性的度量。
例如,给定一条路径
,使用朋友和爱好定义的运算符来旋转 Alice 的嵌入。然后计算导出的嵌入和 Sing 嵌入的相似度为
。
这种方法允许计算每条路径的特定 ![]() ,这进一步导致不同候选答案的更精确的分数。一旦获得了每个候选答案的分数,就可以使用 softmax 函数进一步定义查询 q 的答案 a 是实体 e 的概率,如下所示:
,这进一步导致不同候选答案的更精确的分数。一旦获得了每个候选答案的分数,就可以使用 softmax 函数进一步定义查询 q 的答案 a 是实体 e 的概率,如下所示:

2.4 优化
在每次训练迭代中,根据规则生成器生成的规则更新推理预测器pw,然后使用 EM 算法更新规则生成器 pθ。

如2.1所示,从最大化![]() 开始。每个训练实例 (G, q, a) 都有一个关于 pθ(z|q) 的期望操作。通过为查询 q 绘制样本
开始。每个训练实例 (G, q, a) 都有一个关于 pθ(z|q) 的期望操作。通过为查询 q 绘制样本 ![]() ,我们可以在每个训练实例 (G, q, a) 处近似 w 的目标函数:
,我们可以在每个训练实例 (G, q, a) 处近似 w 的目标函数:
![]()
从规则生成器中采样一组规则 并将反馈到推理预测器中。然后更新推理预测器的参数w以最大化答案a的对数似然。使用更新的推理预测器,更新规则生成器 pθ 以最大化目标 O(θ, w)。
并将反馈到推理预测器中。然后更新推理预测器的参数w以最大化答案a的对数似然。使用更新的推理预测器,更新规则生成器 pθ 以最大化目标 O(θ, w)。
2.4.1 E-step
通过后验推理从所有生成的规则中识别出一组高质量规则,其中规则生成器作为先验,推理预测器作为似然。
优化推理预测器时,为每个数据实例(G,q,a)绘制一组规则,并让推理预测器使用来预测 a。对于每个数据实例,E-step 的目标是从所有生成的规则中识别一组 K 个高质量规则![]() ,即
,即![]() 。
。
形式上,这是通过考虑逻辑规则 ![]() 每个子集的后验概率来实现的。
每个子集的后验概率来实现的。
即 ![]() ,其中
,其中 ![]() 的先验来自规则生成器 pθ,似然来自推理预测器 pw。
的先验来自规则生成器 pθ,似然来自推理预测器 pw。
后验结合了来自规则生成器和推理预测器的知识,因此可以通过后验采样来获得可能的高质量规则集。然而,由于其难以处理的配分函数,从后验样本中采样并不简单,因此可使用更容易处理的形式来近似后验样本,其命题如下:
考虑一个数据实例 (G, q, a),其中 q = (h, r, ?) 且 a = t。对于由规则生成器 pθ 生成的一组规则 ,可以为每个rule ∈ 计算以下分数 H:

A 是由 中的规则发现的所有候选答案e的集合,![]() 是每个规则对实体 e 贡献的分数。
是每个规则对实体 e 贡献的分数。![]() 是生成器计算的规则的先验概率。
是生成器计算的规则的先验概率。
假设 ![]() . 然后对于规则子集
. 然后对于规则子集 ![]() ,对数概率
,对数概率![]() 可以近似如下:
可以近似如下:

其中 const 是与 ![]() 无关的常数项
无关的常数项
![]() K 是
K 是![]() 集合的给定大小,
集合的给定大小,![]() 是每个规则在
是每个规则在![]() 中出现的次数。
中出现的次数。
上述命题允许利用![]() 来近似对数后验
来近似对数后验![]() ,产生分布
,产生分布 ![]() 作为后验的良好近似。
作为后验的良好近似。
经证明,导出的![]() 是多项式分布,因此从
是多项式分布,因此从![]() 中采样更容易处理。具体来说,来自
中采样更容易处理。具体来说,来自![]() 的样本
的样本![]() 可以由从独立采样的 K 个逻辑规则组成,其中采样每个规则的概率计算为:
可以由从独立采样的 K 个逻辑规则组成,其中采样每个规则的概率计算为:
![]()
将每条规则的H(rule)视为对规则质量的评估,它考虑了两个因素。第一个因素基于推理预测器 pw,计算方法为规则对正确答案 t 贡献的分数减去该规则对其他候选答案贡献的平均分数。如果一条规则对真实答案给出较高分数,对其他候选答案给出较低分数,则该规则很可能更重要。第二个因素基于规则生成器 pθ,计算每个规则的先验概率并使用该概率进行正则化。
由经验可得,选择具有最高 H(rule) 的 K 个规则来形成![]() 比从后验采样效果更好。
比从后验采样效果更好。
2.4.2 M-step
在 E 步骤中为每个数据实例 (G, q, a) 获得一组高质量的逻辑规则![]() ,进一步利用这些规则来更新 M 步骤中规则生成器(Rule Generator)的参数 θ。以与 E 步骤中选择的高质量规则一致。
,进一步利用这些规则来更新 M 步骤中规则生成器(Rule Generator)的参数 θ。以与 E 步骤中选择的高质量规则一致。
对于每个数据实例 (G, q, a),将相应的规则集![]() 视为训练数据的一部分,并通过最大化
视为训练数据的一部分,并通过最大化![]() 的对数似然来更新规则生成器:
的对数似然来更新规则生成器:

推理预测器的反馈可以有效地提炼到规则生成器中。通过这种方式,规则生成器将学会只生成高质量的规则供推理预测器探索,从而减少搜索空间并产生更好的经验结果。
2.5 RNNLogic+
在 RNNLogic 中,目标是联合训练规则生成器和简单推理预测器。虽然这个框架允许生成高质量的逻辑规则,但知识图谱推理的性能受到推理预测器能力低的限制。
为了进一步改进结果,一个自然的想法是只关注推理预测器,并使用 RNNLogic 生成的高质量规则作为输入来开发更强大的预测器。文章提出一个这样的预测器。形式上,令![]() 为生成的高质量逻辑规则的集合。给定一个查询 q = (h, r, ?),令 A 为可由
为生成的高质量逻辑规则的集合。给定一个查询 q = (h, r, ?),令 A 为可由![]() 中的任何规则发现的候选答案的集合。对于每个候选答案 e ∈ A,再次计算该候选答案的标量分数 Scorew(e),如下所示:
中的任何规则发现的候选答案的集合。对于每个候选答案 e ∈ A,再次计算该候选答案的标量分数 Scorew(e),如下所示:
![]()
![]() 是每个规则的嵌入向量,并且|P(h,rule,e)|是规则发现的从 h 到 e 的接地路径的数量。 AGG是一个聚合器,其目的是通过处理|P(h,rule,e)|来聚合所有规则嵌入
是每个规则的嵌入向量,并且|P(h,rule,e)|是规则发现的从 h 到 e 的接地路径的数量。 AGG是一个聚合器,其目的是通过处理|P(h,rule,e)|来聚合所有规则嵌入![]() 作为聚合权重。
作为聚合权重。
本文使用 PNA 聚合器。一旦获得聚合嵌入,MLP 就会进一步将嵌入投影到候选 e 的标量分数。
可以通过知识图谱嵌入进一步提高上述分数。对于每个查询 q = (h, r, ?) 和候选答案 e,知识图谱嵌入的方法能够推断出合理性分数 KGE(h, r, e),测量 (h, r, e) 有效的可能三元组。
基于此,可以通过结合逻辑规则的得分和知识图嵌入的得分来获得更强大的得分函数。例如,可以将它们线性组合如下:
![]()
其中 η 控制知识图谱嵌入分数的权重。
一旦获得了每个候选 e 的分数 Scorew(e),就可以再次对分数应用 softmax 函数,如等式5所示。 计算 e 为答案的概率,即 pw(a = e|G, q, z)。然后可以通过最大化每个实例(G,q,a)的可能性来优化该预测器。
三、实验
3.1 数据集
选择四个数据集进行评估,包括 FB15k-237、WN18RR 、Kinship 和 UMLS
3.2 评估指标
平均排名 (MR)、平均倒数排名 (MRR) 和 Hit@k (H@k)

对于RNNLogic考虑两种模型变体:第一个变体为推理预测器中的不同接地路径分配恒定分数,即等式中的 φw(path) = 1,表示为 w/o emb.。第二个变体利用实体嵌入和关系嵌入来计算路径得分 φw(path),表示为 with emb..。
对于 RNNLogic+,同样考虑了两种模型变体:第一个变体仅使用 RNNLogic 学到的逻辑规则来训练推理预测器,如等式 10 所示,表示为w/o emb.。第二个变体使用学习的逻辑规则和知识图嵌入来训练推理预测器,如等式(11)所示。表示为 with emb..。

3.3 参数设置
对于 RNNLogic 的规则生成器,生成规则的最大长度设置为 FB15k-237 为 4,WN18RR 为 5,其余为 3。RNNLogic 训练完成后,利用规则生成器生成一些高质量的逻辑规则,这些规则将进一步用于训练 RNNLogic+。
生成规则的最大长度设置为3。为FB15k-237中的每个关系生成100条规则,为WN18RR中的每个关系生成200条规则。 RNNLogic+ 中逻辑规则嵌入的维度在所有数据集上均设置为 32。方程中的超参数 η。在 FB15k-237 数据集上设置为 2,在 WN18RR 数据集上设置为 0.5。
在 RNNLogic+ with emb. 中,使用 RotatE作为知识图嵌入模型,这与 RNNLogic with emb. 相同。对于这两个模型,实体和关系嵌入都是预先训练的。嵌入尺寸在 FB15k-237 上设置为 500,在 WN18RR 上设置为 200。
四、总结
本文研究了知识图推理的学习逻辑规则,提出了一种称为 RNNLogic 的方法。 RNNLogic 将一组逻辑规则视为潜在变量,并共同学习规则生成器和具有逻辑规则的推理预测器,利用EM算法不断优化。