C++ 内存管理 - malloc/free - 侯捷
VC6与VC10的malloc比较
malloc/free是C层面的函数
上面图从下往上看,在程序调用(第8步)main之前,可以看到有很多操作,以及调用Main之后的操作;
在这些操作中,有一个黄色标亮的_heap_alloc_base(),size小于等于__sbh_thredshold==(1016)就执行__sbh_alloc_block(size),否则就执行window操作系统的一个函数HeapAlloc;
VC10的如下,打叉是不存在的:

新的VC10没有加判断,就是没有再最小块内存作特殊管理,都交给HeapAlloc函数处理;
VC6的特殊处理,只是包装在一起到HeapAlloc函数里了;
_heap_init()

用以申请一块自己用的空间,调用HeapCreate函数,
然后执行__sbh_heap_init()中调用HeapAlloc来,其中参数_crtheap就是指向刚刚申请的内存的指针,
拿出16个HEADER大小的空间给这个指针,初始化就是将16个HEADER准备好;
具体HEADER就是下面展开样子,根据下方框的数据结构
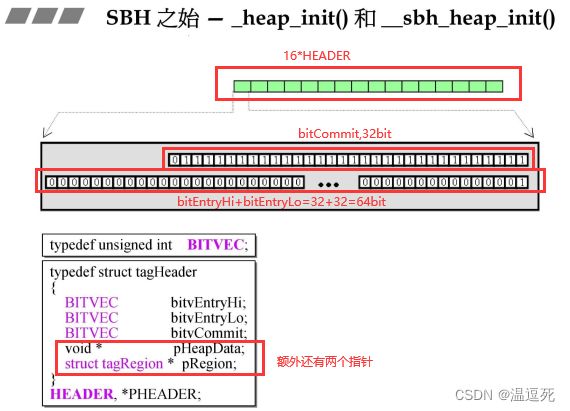
BITVEC==unsigned int,3*32bit,其中有两个组合起来,一个是Hi,一个是Lo,将其组合起来其实是64个bit;
SBH真正的面貌如下,为了进行内存管理而创建一个结构;是内存管理的消耗;

VC6内存分配

开始看第二步执行函数,黄色标注部分,其中源码有一部分如右框所示;
此处是第一次调用malloc,可看到右侧,申请的内存大小是32*8=256字节,十六进制就是100h,sizeof(ioinfo) 的大小如右侧红色框所示,是8个字节,4+1+1=6->8;

红色框内函数,表示都是_ioinit()函数,
黄色标注函数,_heap_alloc_dbg()中传入的参数是nsize=256,就是上一页中的256个字节;另外加上了前后sizeof(_CrtMemBlockHeader)+nNoMansLandSize=4;这是在DEBUG模式下准备申请到那块内存;
将目前申请的三部分组成的blockSize画成示意图如右图所示,DEBUG专用的;对于右侧3和4,就是两个指针,
分别指向debug文件和具体行数,这里是ioinit.c和第81行;
第5个DataSize记录真正的nSize的大小,就是100h;7是流水号,8是以字符形成的array;
深绿色可以作为真正大小nSize的两个“篱笆”;
从malloc_dbg()第一次调用malloc到调用_-heap_alloc _dbg()大小在这里变大了,另加了两个部分,但是这里都还没有分配内存;
接着便调用了_heap_alloc_base(blockSize)函数;这个参数已经是被调整过的blockSize大小;
命名中,dbg一直在调整大小,block是调整好的大小;
在进入_heap_alloc_base(blockSize)函数之前,还有一部分如下:

上图表示,每次malloc内存,虽然内存分配出去了,但是malloc过的每个内存,malloc都用链表串接起来了进行记录;
这就是为什么可以debug的原因;
因为在debug模式下,多了深灰色(实际申请内存之外)的东西;
上图中最后下方源代码,memset是预先填写一些特定的数值,在方框中的常量大小;
接下来是下一张图中的_heap_alloc_baset()之前提到的函数

为什么是1016呢,但是加上cookie=8字节,就是1024;
目前都是_ioinit()中第一次调用malloc申请1024字节大小空间;

_sbh_alloc_block()将其得到的大小intSize做进一步处理,+2*sizeof(int)=2 * 4=8字节,就是图中上下粉红色的两块,然后+的部分是ROUNDUP,调整到16的倍数;
第一次申请的nsize就是100h,(256,16进制),然后加上了上下两部分,(8*4+4=36,就是ox24,16进制),最后+4 * 2(上下cookie),=0x12C,上调至16的倍数,0x130;
上下cookie应该记录的是130,目前是131,因为最后4个Bit都是0,借用最后一个Bit来标记是在自己手上还是已经分配出去;
到目前,都还在调整大小,没有分配内存;
前面都是计算大小,目前是第一块内存分配出去了,_sbh_alloc_new_region
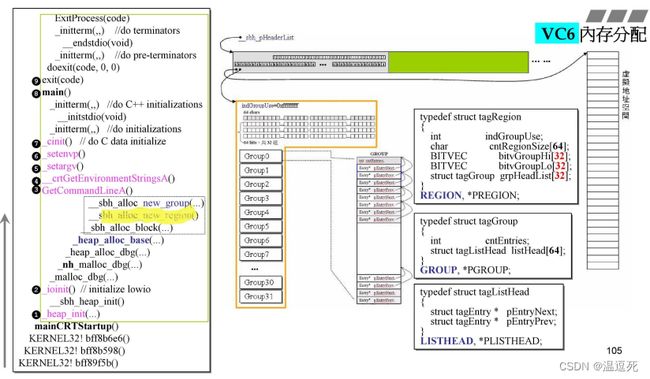
1个HEADER负责管理1M的内存;用下图所示的数据结构进行管理;其中一个指针指向真正的内存,另一个指针指向管理中心;
1M=1024KB,1KB=1024字节;
在黄色线框中,分别对应右侧数据结构,
一个int,一行char,
32行64bit的bitGroup,由高低位组成(作用:管理block区块是否存在的小细节);
下面就是32个Group0-Group31;
一个Group展开,就是右侧GROUP,对应右侧的tagGroup数据结构:
一个int,+64个listHead(类型是tagListHead),就是64对指针,128个指针;每两个指针指向一个双向链表;
为了管理1M内存,这些数据结构大小为16K;
进入_sbh_alloc_new_group,从1M中切出一块出来

此时已经有1M内存;进入函数_sbh_alloc_new_group,希望用32个GROUP对应右侧的1M,每一块(32K)由一个GROUP管理,每一个GROUP有64个链表;
最右侧一个粉红块大小为32K,每一个32K再分为page1-page8.每一个page大小为4K,
16的倍数就是一段paragraph,这里4K就是1page;
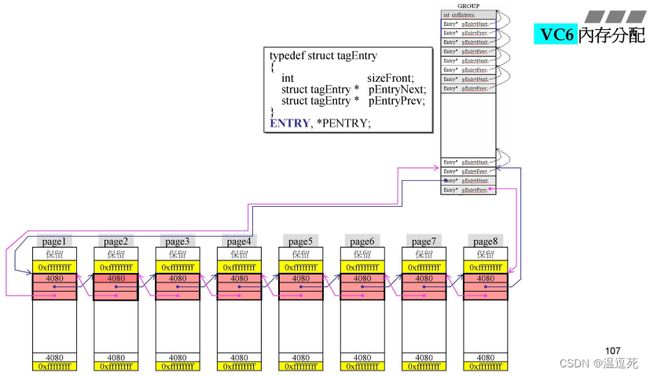
4080就是一块中两个黄色框之间的大小;本来是(4K)4096-8(两个黄色部分)= 4088;但是要为16的倍数,缩小大小部分保留(8bit),真正可用的就是4080字节;
黄色上下都有cookie,就自己的大小为4080;
切第一刀
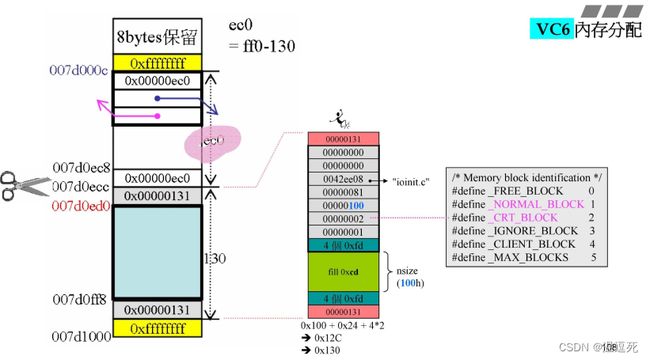
右侧就是切出去的第一个小内存,nsize=100h,
对应剩下了ec0h=ff0(4080)-130h;本来是130,因为是分配出去了,变成131;
切割动作,就是调整cookie+指针指出;
因为是debug模式,因此在真正要的nsie=100h中加上了上下信息调整大小到0x130;
注意,002代表_CRT_BLOCK,之后进入main函数后,就是001代表_NORMAL_BLOCK;
切割后,剩余地址空间计算大小,指针挂载到相应地方。
SBH行为分析:分配+释放之连续工作图解
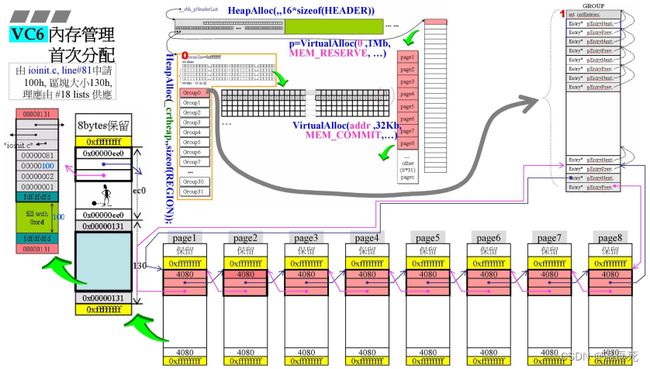
首次发出需求,就是在ioinit.c的第81行开始,申请100h(256)大小内存空间,经过调整为区块大小130h,如最左侧图所示;本来应该由64个链表中的#18进行操作,(130H/16-1,10进制);
最下面一行的8个page形成的链表,头尾指针指向最右侧的最后一格,最右侧的64个双向链表,比如,第一个负责16个字节,第二个负责32个字节,等等,但是最后这个就比较特殊,专门处理大于1K=1024字节的情况,
现在64个中,只有目前还有第63个为内存块;中间小格就是为了记录这些信息;
第二次开始分配内存;

130h是第一次分配出去的内存,第二次就是上面的240h;
240h转化为十进制后,/16就可以得到应该对应的链表编号;(计算应该是#35号);
只有最后一个链表是1,就从最后一个链表中,开始分配;
最左侧:ec0-240=c80h;
注意,在最右侧的最上面,有一个int cntEntrys,每次分配都会+1;如果是0,就说明分配内存都已经回收完毕,就可以还给操作系统了;
注意,在画面中间的0,代表目前正在使用的是GROUP0;
第3次分配内存
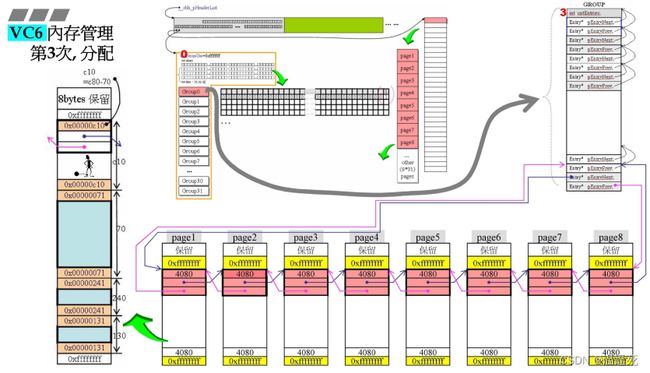
步骤
1、根据70h,转化为10进制/16,计算应该对应的链表编号,;
2、根据链表编号查询中间表达,发现为0,那么从最后一个1(链表)开始;
3、来到page1,开始切割;(这里用的是嵌入式指针);
假设在第15次释放,调用了free函数(前面都是malloc)
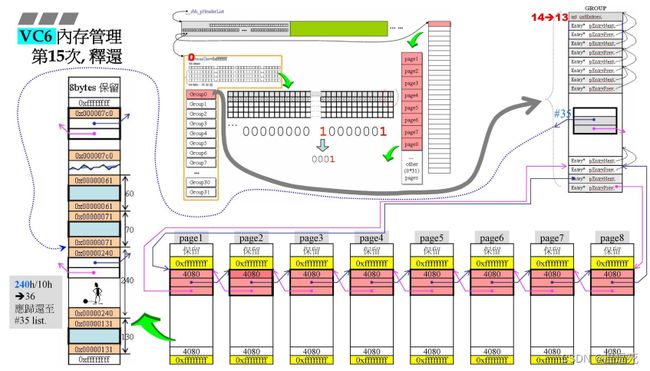
释放,因此右侧14-1=13;
目前释放第二次申请的240h空间;是将之前的cookie=241改为240,说明回收,利用嵌入式指针,(240h=576/16=36-1=35)将其挂在第#35号链表回收,那么中间bit第#35号bit置1,说明#35号链表也有区块;
第16次分配
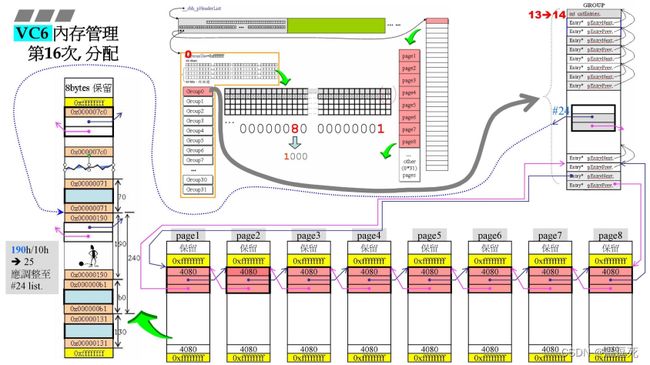
这次是bh大小,(b0h=176/16=11-1=10)第#10号链表bit=0,那么就从10号往后找,那么从35号链表240h-b0h=190h需要重新安排这个剩余块,190h/16=25-1=24,应该挂在#24号链表之上;
第n次开始分配,这里GROUP1被分配完成,

中间链表为02000014,表示有3处链表挂载有区块,
本次申请内存大小为230,因为前面的都不满足,因此重开一个链表,重新开始切割;
分割后,开始内存合并

白色是应该要合并的部分,cookie的最后一个Bit是0,说明是已经回收的;300h应该都落在同一个链表上,
目前已经有两块了,归还的内存是灰色部分,首先检测到灰色下方的cookie最后一位是0,那么就先与下方那个合并,继续往上看4个字节,就到了上一块的下cookie,就继续向上调整;
因此,下cookie很有必要;
VC6-free

根据p来寻找,哪一个HEADER,pointer再确定是哪一段(一共32段,对应32GROUP)
(16个)HEADER确定:有头尾指针,限定范围,一个一个找;
(32个)GROUP就使用pointer-头指针/一段的长度(32K);
链表可以一直连接,为什么要分成32段?
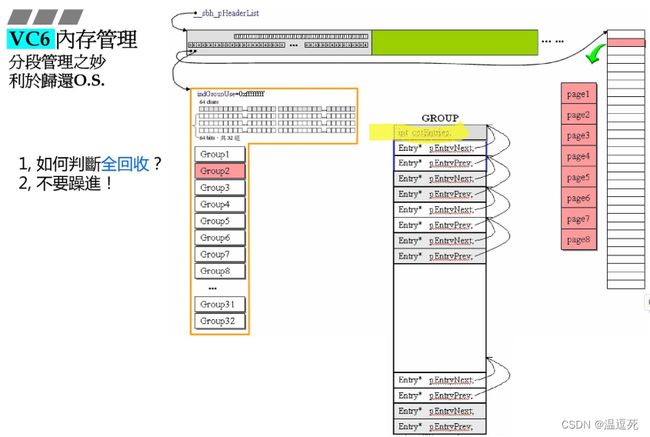
以一段(GROUP,32K)为更小单位,全部回收成功的机会更大;
根据每个GROUP最上面的cntEntries来确定是否真的全回收了,==0就完全回收;
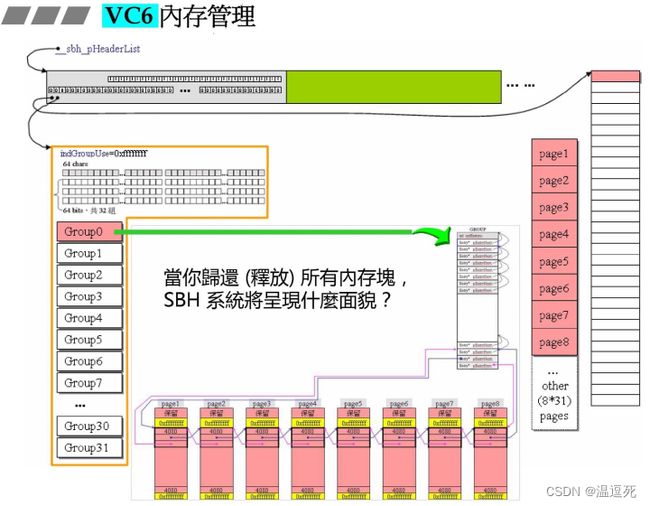
完全回收时,就回到初始状态如下:

都回到最后一个链表的8个page,
之前分割出去挂在64个不同链表的内存都回收到初始状态;
这8个page不可以再重新组成一个完整的32K,因为有黄色部分0xfffff阻挡;
不着急还,有两个全回收才会归回;

在右侧函数中,有一个全局变量指针__sbh_pHeaderDefer=NULL,
指向一个全回收group所属的HEADER,此时延缓释放,
等待第二个出现,才会释放当前HEADER,
手上始终保留一个全回收HEADER;
当没有全回收,设为NULL;
当释放所有内存,SBH系统将会呈现的面貌;
VC malloc+ GCC allocator
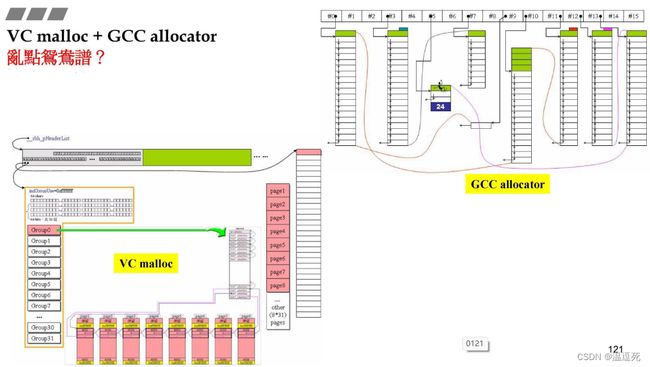
第二讲是GCC allocator;第三讲是VC malloc;但是都是相似的;
分配器要的都是从malloc申请内存的,分配器链表最高管理128字节,
使用allocator目的不是在于减少时间,而是为了减少调用malloc,从而减少cookie的内存消耗;

1、allocator减少cookie,缺点是没有free;
2、malloc调用OS也有类似自由链表的设计的内存管理;
3、叠床架屋有浪费!但是优点是CRT(malloc/free)是C语言跨平台的,不依赖于操作系统,不预设/依赖下层是否内存管理;
4、VC10就没有malloc/free设计,依赖于操作系统win,自己家产品了解;