【本科生机器学习】【北京航空航天大学】课题报告:支持向量机(Support Vector Machine, SVM)初步研究【上、原理部分】
说明:
(1)、仅供个人学习使用;
(2)、本科生学术水平有限,故不能保证全无科学性错误,本文仅作为该领域的学习参考。
一、课程总结
1、机器学习(Machine Learning, ML)的定义
机器学习是人工智能的一个分支。人工智能的研究历史有着一条从以“推理”为重点,到以“知识”为重点,再到以“学习”为重点的自然、清晰的脉络。显然,机器学习是实现人工智能的一个途径,即以机器学习为手段解决人工智能中的问题。机器学习在近30多年已发展为一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、计算复杂性理论等多门学科。
机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。因为学习算法中涉及了大量的统计学理论,机器学习与推断统计学联系尤为密切,也被称为统计学习理论。算法设计方面,机器学习理论关注可以实现的,行之有效的学习算法。很多推论问题属于无程序可循难度,所以部分的机器学习研究是开发容易处理的近似算法。
机器学习已广泛应用于数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人等领域。
统计学习是关于计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析的一门学科。统计学习也称为统计机器学习。
统计学习的主要特点是:
(1)、统计学习以计算机及网络为平台,是建立在计算机及网络上的;
(2)、统计学习以数据为研究对象,是数据驱动的学科;
(3)、统计学习的目的是对数据进行预测与分析;
(4)、统计学习以方法为中心,统计学习方法构建模型并应用模型进行预测与分析;
(5)、统计学习是概率论、统计学、信息论、计算理论、最优化理论及计算机科学等多个领域的交叉学科,并且在发展中逐步形成独自的理论体系与方法论。
2、本课程主要内容
略。(参见下文中的算法描述部分。)
二、问题介绍
1、问题描述:
(1)、 使用逻辑回归分类器和支持向量机,根据鸢尾花的特征,在鸢尾花数据集上进行分类任务;
(2)、 使用多项式特征的SVM分类器,对卫星形(Moon-shaped)数据集进行分类。
(3)、 使用SVM回归模型,对随机线性数据拟合最优直线。
2、原始数据:
(1)、 鸢尾植物数据集。这个数据集中共有150朵鸢尾花的图片,分别来自三个不同品种(山鸢尾(Iris Setosa)、变色鸢尾(Iris Versicolor)和维吉尼亚鸢尾(Iris Virginica)),数据条目里包含花的萼片以及花瓣的长度和宽度(见图1)。

图1.三种不同品种的鸢尾花
鸢尾植物数据集的键(keys)分别为:
['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename']
![]()
其中 ‘target’ 字段指示鸢尾花的品种,取值为0,1,2. 若target = 0, 说明为山鸢尾(Iris Setosa);若target = 1, 说明为变色鸢尾(Iris Versicolor);若target = 2, 说明为维吉尼亚鸢尾(Iris Virginica)。
(2)、 卫星数据集。卫星数据集(Moon-shaped Dataset)是一种用于二元分类的小型数据集,其中数据点所组成的形状为两个相互交织的半圆型。Python中的 make_moons() 函数用来生成该数据集,便于在数据集上进行分类测试。make_moons() 函数生成的数据集如下图所示:

图2. make_moons()函数生成的数据集举例
(3)、 为了训练线性SVM回归模型,使用随机生成的线性数据集作为训练集。该数据集由100个样本点所构成,具有单一特征x1,并且添加了高斯白噪声。拟合成的直线方程为y=3x+4. 此数据集的形状如下图所示:

图3. 线性数据集
3、算法描述:
(1)、 逻辑斯谛回归(Logistic Regression):
逻辑斯谛回归是统计学习中的一种经典分类方法。
二项逻辑斯谛回归模型是一种分类模型,由条件概率分布 P(Y|X) 表示,形式为参数化的逻辑斯谛分布。这里,随机变量X的取值范围为全体实数,随机变量Y取值范围为1或0.通过监督学习(Supervised Learning)的方法来估计模型参数。对于给定的输入实例x,按照公式:
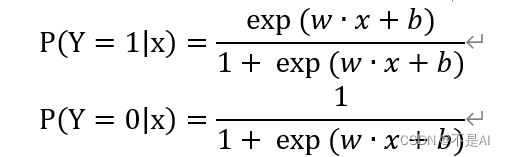
可以求得P(Y=1│x)和P(Y=0│x)。逻辑斯谛回归比较两个条件概率值的大小,将实例x分到概率值较大的那一类。
一个事件的对数几率表示为
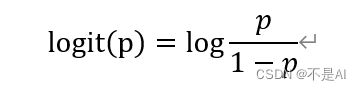
代入上式,得

即,在逻辑斯谛回归模型中,输出Y=1的对数几率是输入x的线性函数。或者说,输出Y=1的对数几率是由输入x的线性函数表示的模型,即为逻辑斯谛回归模型。
(2)、 支持向量机(support vector machines, SVM):
支持向量机是一种二类分类模型,如图4所示。它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;支持向量机还包括核技巧,这使它成为实质上的非线性分类器。支持向量机的学习策略就是间隔最大化,可形式化为一个求解凸二次规划(convex quadratic programming)的问题,也等价于正则化的合页损失函数(hinge函数)的最小化问题。支持向量机的学习算法是求解凸二次规划的最优化方法。

图4.支持向量机(SVM)原理图示
线性可分支持向量机的定义如下:
给定一个线性可分的训练数据集,通过间隔最大化或者等价地求解相应的凸二次规划问题学习得到的分离超平面方程为
w * ∙x+ b * =0
以及相应的分类决策函数
f(x)=sign(w^ * ∙x+ b^ * )(其中sign()函数为符号函数)
称为线性可分支持向量机。
在如下图所示的二类分类问题中,训练数据集线性可分,这时有许多直线能将两类数据正确划分。线性可分支持向量机对应着将两类数据正确划分并且间隔最大的直线,如下图所示。
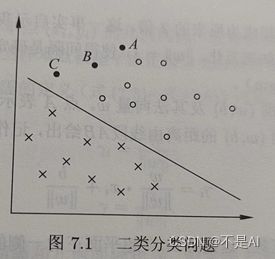
图5.二类分类问题
4、选择该算法的原因:
(1)、 一些回归算法也可以用于分类(反之亦然)。逻辑斯谛回归(Logistic回归,也称为Logit回归)算法被广泛使用于估算一个实例属于某个特定类别的概率。即,如果预估概率超过50%,则模型预测该实例属于该类别(称为正类,标记为“1”);反之,则预测不属于(称为负类,标记为“0”)。这样,逻辑斯谛回归算法实际上构成了一个二元分类器。
(2)、 支持向量机(Support Vector Machine,SVM)是一个功能强大并且全面的机器学习模型,它能够执行线性或非线性分类、回归,甚至是异常值检测等任务。它是机器学习领域中最受欢迎的模型之一。此外,SVM特别适用于中小型复杂数据集的分类,本课题中的数据集满足此要求。
(原理部分到此结束)