k8s-pod 控制器
文章目录
- 一、Pod 控制器
-
- 1、pod 控制器简介
- 2、pod控制器的状态
- 2、pod控制器有多种类型
-
- 1.ReplicaSet
- 2.Deployment
- 3.DaemonSet
- 4.StatefulSet:
- 5.Job
- 6.Cronjob
- 3 、Pod与控制器之间的关系
- 二、Deployment(无状态)
-
- 1、Deployment的资源清单文件
- 三、ReplicaSet(RS)
-
- 1、ReplicaSet的资源清单文件
- 2、创建ReplicaSet
- 四、SatefulSet(有状态)
- 五、DaemonSet(守护进程集)
- 六、Job
- 七、CronJob
一、Pod 控制器
1、pod 控制器简介
Pod控制器,又称之为工作负载(workload),是用于实现管理pod的中间层,确保pod资源符合预期的状态,pod的资源出现故障时,会尝试进行重启,当根据重启策略无效,则会重新新建pod的资源
在kubernetes中,按照pod的创建安方式可以将其分为两类:
- **自主式pod:**kubernetes直接创建出来的pod,这种pod删除后就没有了,也不会重建
- **控制器创建的pod:**通过控制器创建的pod,这种pod删除了之后还会自动重建
2、pod控制器的状态
有状态:
1.实例之间有差别,每个实例都有自己的独特性,元数据不同,例如etcd,zookeeper
2.实例之间不对等的关系,以及依靠外部存储的应用
无状态:
1.deployment认为所有的pod都是一样的
2.不用考虑顺序的要求
3.不用考虑在哪个node节点上运行
4.可以随意扩容和缩容
常规service和无头服务的区别:
**service:**一组pod访问策略,提供cluster-ip集群之间通讯,还提供负载均衡和服务发现
**Headless service:**无头服务,不需要cluster-ip,直接绑定具体的pod的IP
2、pod控制器有多种类型
1.ReplicaSet
代用户创建指定数量的pod副本数量,确保pod副本数量符合预期状态,并且支持滚动式自动扩容和缩容功能。
ReplicaSet主要三个组件组成:
(1)用户期望的pod副本数量
(2)标签选择器,判断哪个pod归自己管理
(3)当现存的pod数量不足,会根据pod资源模板进行新建
帮助用户管理无状态的pod资源,精确反应用户定义的目标数量,但是ReplicaSet不是直接使用的控制器,而是使用Deployment
2.Deployment
工作在ReplicaSet之上,用于管理无状态应用,目前来说最好的控制器。支持滚动更新和回滚功能,还提供声明式配置
ReplicaSet 与Deployment 这两个资源对象逐步替换之前RC的作用
3.DaemonSet
用于确保集群中的每一个节点只运行特定的pod副本,通常用于实现系统升级后台任务。比如ELK服务
- 特性:服务是无状态的
- 服务必须是守护进程
4.StatefulSet:
管理有状态应用(是有序的创建pod,删除时是倒叙删除,它们都是串行执行的)
5.Job
只要完成就立即退出,不需要重启或重建
6.Cronjob
周期性任务控制,不需要持续后台运行
3 、Pod与控制器之间的关系
- controllers:在集群上管理和运行容器的 pod 对象,pod通过label-selector 相关联
- Pod通过控制器实现应用的运维,如伸缩,升级等
二、Deployment(无状态)
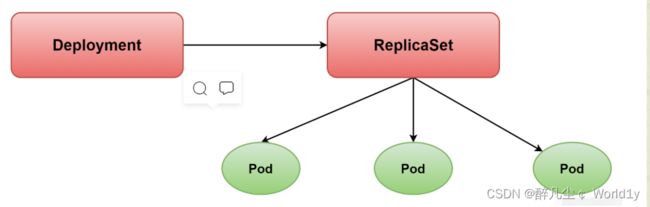
为了更好的解决服务编排的问题,kubernetes在v1.2版本开始,引入了Deployment控制。值得一提的是,这种控制器并不直接管理pod,而是通过管理 ReplicaSet 来间接管理Pod,即:Deployment管理ReplicaSet,ReplicaSet管理Pod。所以Deployment比ReplicaSet功能更加强大
Deployment主要功能有下面几个:
支持ReplicaSet的所有功能
支持发布的停止、继续
支持版本滚动升级和版本回退
特点:
部署无状态应用,只关心数量,不论角色等,称无状态
管理Pod和ReplicaSet
具有上线部署、副本设定、滚动升级、回滚等功能
提供声明式更新,例如只更新一个新的image
应用场景:应用场景: Nginx, 微服务,jar
1、Deployment的资源清单文件
apiVersion: apps/v1 # 版本号
kind: Deployment # 类型
metadata: # 元数据
name: # rs名称
namespace: # 所属命名空间
labels: #标签
controller: deploy
spec: # 详情描述
replicas: 3 # 副本数量
revisionHistoryLimit: 3 # 保留历史版本,默认是10,用于版本回退时使用
paused: false # 暂停部署,默认是false,即deployment创建好后是否立即开始部署和创建pod
progressDeadlineSeconds: 600 # 部署超时时间(s),默认是600
strategy: # 策略
type: RollingUpdate # 滚动更新策略
rollingUpdate: # 滚动更新
maxSurge: 30% # 最大额外可以存在的副本数,可以为百分比,也可以为整数
maxUnavailable: 30% # 最大不可用状态的 Pod 的最大值,可以为百分比,也可以为整数
selector: # 选择器,通过它指定该控制器管理哪些pod
matchLabels: # Labels匹配规则
app: nginx-pod
matchExpressions: # Expressions匹配规则
- {key: app, operator: In, values: [nginx-pod]}
template: # 模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
#上述资源清单可以分为三部分,spec以上是deployment信息;spec的replicas到selector是副本数量、镜像更新策略、标签选择器(会和下面的Pod做关联)等;template及以下是Pod配置信息
----------------------------------------------------------------------------------------------------------
#示例:创建deployment
vim nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.15.4
ports:
- containerPort: 80
#创建资源
kubectl create -f nginx-deployment.yaml
#查看创建的pod资源、控制器和副本
kubectl get pods,deploy,rs
查看控制器配置
kubectl edit deployment/nginx-deployment
查看历史版本
kubectl rollout history deployment/nginx-deployment
三、ReplicaSet(RS)
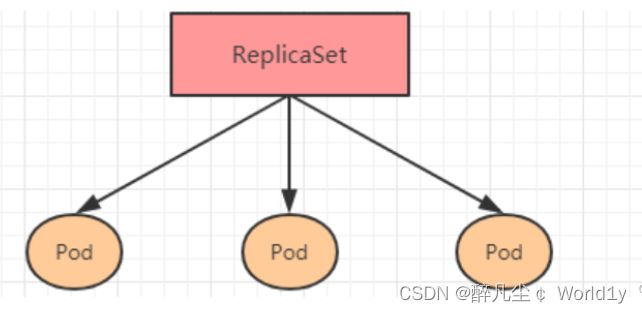
ReplicaSet的主要作用是保证一定数量的pod正常运行,它会持续监听这些Pod的运行状态,一旦Pod发生故障,就会重启或重建。同时它还支持对pod数量的扩缩容和镜像版本的升降级
1、ReplicaSet的资源清单文件
apiVersion: apps/v1 # 版本号
kind: ReplicaSet # 类型
metadata: # 元数据
name: # rs名称
namespace: # 所属命名空间
labels: #标签
controller: rs
spec: # 详情描述
replicas: 3 # 副本数量
selector: # 选择器,通过它指定该控制器管理哪些pod
matchLabels: # Labels匹配规则
app: nginx-pod
matchExpressions: # Expressions匹配规则
- {key: app, operator: In, values: [nginx-pod]}
template: # 模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
在这里面,需要新了解的配置项就是spec下面几个选项:
- **replicas:**指定副本数量,其实就是当前rs创建出来的pod的数量,默认为1
- **selector:**选择器,它的作用是建立pod控制器和pod之间的关联关系,采用的Label Selector机制。在pod模板上定义label,在控制器上定义选择器,就可以表明当前控制器能管理哪些pod了
- **template:**模板,就是当前控制器创建pod所使用的模板板,里面其实就是前一章学过的pod的定义
2、创建ReplicaSet
vim pc-replicaset.yam
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: pc-replicaset
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
创建rs
# 创建rs
[root@master ~]# kubectl create -f pc-replicaset.yaml
replicaset.apps/pc-replicaset created
--------------------------------------------------------
# 查看rs
# DESIRED:期望副本数量
# CURRENT:当前副本数量
# READY:已经准备好提供服务的副本数量
--------------------------------------------------------
[root@master ~]# kubectl get rs pc-replicaset -n dev -o wide
NAME DESIRED CORRENT READY AGE CONTAINERS IMAGES SELECTOR
pc-replicaset 3 3 3 22s nginx nginx:1.17.1 app=nginx-pod
---------------------------------------------------------------------
# 查看当前控制器创建出来的pod
# 这里发现控制器创建出来的pod的名称是在控制器名称后面拼接了-xxxx随机码
---------------------------------------------------------------------
[root@master ~]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
pc-replicaset-6vmvt 1/1 Running 0 54s
pc-replicaset-fm8f 1/1 Running 0 54s
pc-replicaset-snrk 1/1 Running 0 54s
四、SatefulSet(有状态)
稳定的持久化存储,即 Pod 重新调度后还是能访问到相同的持久化数据,基于 PVC 来实现
稳定的网络标志,即 pod 重新调度后其 PodName 和 HostName 不变,基于 Headless Service(即没有 Cluster IP 的 Service)来实现有序部署,有序扩展,即 Pod 是有顺序的,在部署或者扩展的时候要依据定义的顺序依次进行(即从 0 到 N-1,在下一个 Pod 运行之前所有之前的 Pod 必须都是 Running 和 Ready 状态),基于 initcontainers(初始化容器) 来实现,也可有序收缩,有序删除(即从N-1到0)
简单描述:
- 1.部署有状态应用
- 2.解决Pod独立生命周期,保持Pod启动顺序和唯一性
- 3.稳定,唯一的网络标识符,持久存储(例如:etcd配置文件,节点地址发生变化,将无法使用)
- 4.有序,优雅的部署和扩展、删除和终止(例如:mysql主从关系,先启动主,再启动从)
- 5.有序,滚动更新
应用场景:数据库,Mysql主从,zookeeper集群,etcd集群
无论是Kube-dns还是CoreDNS,基本原理都是利用监听 Kubernetes 的 Service 和Pod,生成 DNS 记录,然后通过重新配置 Kubelet 的 DNS 选项让新启动的 Pod 使用 Kube-dns 或 CoreDNS 提供的
上面也写过,那就再重复一边是重点
1.有状态与无状态的区别
*无状态*
- deployment认为所有的pod都是一样的
- 不用考虑顺序的要求
- 不用考虑在哪个node节点上运行
- 可以随意扩容和缩容
*有状态*
- 实例之间有差别,每个实例都有自己的独特性,元数据不同,例如etcd,zookeeper
- 实例之间不对等的关系,以及依靠外部存储的应用
2.常规service和无头服务区别
- service:一组Pod访问策略,提供cluster-IP群集之间通讯,还提供负载均衡和服务发现。
- Headless service :无头服务,不需要cluster-IP,直接绑定具体的Pod的IP,也可用于为Pod资源标识符生成可解析的DNS记录
为什么要有headless?
在deployment中,每一个pod是没有名称,是随机字符串,是无序的。而statefulset中是要求有序的,每一个pod的名称必须是固定的。当节点挂了,重建之后的标识符是不变的,每一个节点的节点名称是不能改变的。pod名称是作为pod识别的唯一标识符,必须保证其标识符的稳定并且唯一,为了实现标识符的稳定,这时候就需要一个headless service 解析直达到pod,还需要给pod配置一个唯一的名称
服务发现的概念:就是应用服务之间相互定位的过程
应用场景:
动态性强:Pod会飘到别的node节点
**更新发布频繁:**互联网思维小步快跑,先实现再优化,老板永远是先上线再慢慢优化,先把idea变成产品挣到钱然后再慢慢一点一点优化
支持自动伸缩:一来大促,肯定是要扩容多个副本K8S里服务发现的方式—DNS,使K8S集群能够自动关联Service资源的“名称”和“CLUSTER-IP”,从而达到服务被集群自动发现的目的
实现K8S里DNS功能的插件:
**skyDNS:**Kubernetes 1.3之前的版本
**kubeDNS:**Kubernetes 1.3至Kubernetes 1.11
**CoreDNS:**Kubernetes 1.11开始至今
3.Service类型
- Cluster_IP
- NodePort:使用Pod所在节点的IP和其端口范围
- Headless
- HostPort(ingress、kubesphere)
- LoadBalance负载均衡(F5硬件负载均衡器)
PS:k8s暴露方式主要就3种:ingress loadbalance(SLB/ALB K8S集群外的负载均衡器、Ng、harproxy、KONG、traefik等等) service
4.示例
vim nginx-service.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
labels:
app: nginx
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
selector:
app: nginx
kubectl create -f nginx-service.yaml
kubectl get svc
#在node节点操作,查看集群间通讯
curl podip地址
5.headless方式
因为Pod动态IP地址,所以常用于绑定DNS访问—来尽可能固定Pod的位置
vim headless.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
kubectl apply -f headless.yaml
kubectl get svc
#再定义一个pod
vim dns-test.yaml
apiVersion: v1
kind: Pod
metadata:
name: dns-test
spec:
containers:
- name: busybox
image: busybox:1.28.4
args:
- /bin/sh
- -c
- sleep 36000
restartPolicy: Never
#验证dns解析
kubectl create -f dns-test.yaml
kubectl get svc
#解析kubernetes和nginx-svc名称
kubectl exec -it dns-test sh
#创建StatefulSet.yaml文件
vim statefulSet.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: nginx-statefulset
namespace: default
spec:
serviceName: nginx
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
# 清理所有pod
kubectl delete -f --all
kubectl create -f statefulSet.yaml
kubectl get pods,svc
#解析pod的唯一域名和自身的ip
kubectl apply -f dns-test.yaml
kubectl exec -it dns-test sh
nslookup nginx-statefulset-0.nginx
nslookup nginx-statefulset-1.nginx
nslookup nginx-statefulset-2.nginx
总结
StatefulSet与Deployment区别
无状态服务对象-Deployment: 用于部署无状态的服务,一般用于管理维护企业内部无状态的微服务,比如configserver、zuul、springboot。其可以管理多个副本的Pod实现无缝迁移、自动扩容缩容、自动灾难恢复、一键回滚等功能。其服务部署结构模型是Deployment->ReplicaSet->Pod;Deployment工作在ReplicaSet之上,用于管理无状态应用,通过“控制器模式”,来操作 ReplicaSet 的个数和属性,进而实现“水平扩展 / 收缩”和“滚动更新”这两个编排动作,也就是说,Deployment 控制器实际操纵的是ReplicaSet 对象,而不是 Pod 对象
有状态服务-statefuleset: 用于管理有状态应用程序的工作负载API对象。比如在生产环境中,可以部署ElasticSearch集群、MongoDB集群或者需要持久化的RabbitMQ集群、Redis集群、Kafka集群和ZooKeeper集群等,其解决了有状态服务使用容器化部署的一个问题,保证pod的hostname重启/重建后不变,通过hostname维护关联数据。其服务部署结构模型是Statefulset->ReplicaSet->Pod;Statefulset也是工作在Replicaset之上,用于管理有状态服务。有状态部署的产品设置通无状态部署
五、DaemonSet(守护进程集)
daemonset确保全部(或者一些)node上运行一个pod副本,当有node加入集群时,也会为他们新增一个pod。当有node从集群移除时,这些pod也会被回收。删除daemonset将会删除它创建的所有的pod
使用 DaemonSet 的一些典型用法:
- 运行集群存储 daemon,例如在每个 Node 上运行 glusterd、ceph(存储)
- 在每个 Node 上运行日志收集 daemon,例如fluentd、logstash
- 在每个 Node 上运行监控 daemon,例如 Prometheus Node Exporter、collectd、Datadog 代理、New Relic 代理,或 Ganglia gmond
应用场景:Agent
应用场景:运行日志收集,监控,集群存储daemon
- 在每一个Node上运行一个Pod
- 新加入的Node也同样会自动运行一个Pod,但会受到污点影响
vim daemonSet.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.15.4
ports:
- containerPort: 80
DaemonSet会在每个node节点都创建一个Pod
kubectl apply -f daemonSet.yaml
kubectl get pods
六、Job
Job分为普通任务(Job)和定时任务(CronJob)
常用于运行那些仅需要执行一次性执行
应用场景:数据库迁移、批处理脚本、kube-bench扫描离线数据处理,视频解码等业务
示例:
用job控制器类型创建资源,执行算圆周率的命令,保持后2000位,创建过程等同于在计算
,重试次数默认是6次,修改为4次,当遇到异常时Never状态会重启,所以要设定次数
vim job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl:5.34.0 #不要用最新版本
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4 #重试次数默认是6次,修改为4次
#参数解释
#.spec.template.spec.restartPolicy该属性拥有三个候选值:OnFailure,Never和Always。默认值为Always。它主要用于描述Pod内容器的重启策略。在Job中只能将此属性设置为OnFailure或Never,否则Job将不间断运行
#.spec.backoffLimit用于设置job失败后进行重试的次数,默认值为6。默认情况下,除非Pod失败或容器异常退出,Job任务将不间断的重试,此时Job遵循 .spec.backoffLimit上述说明。一旦.spec.backoffLimit达到,作业将被标记为失败
在node1节点下载perl镜像,因为镜像比较大所以提前下载好
docker pull perl
在master操作
#创建
kubectl apply -f job.yaml
#查看到完成状态
kubectl get pod
#结果输出到控制台
kubectl logs pi-6tjtp
#清除job资源
kubectl get job
kubectl delete -f job.yaml
七、CronJob
- 周期性任务,像Linux的Crontab一样
- 周期性任务
应用场景:通知,备份
cronjob其它可用参数的配置
spec:
concurrencyPolicy: Allow #要保留的失败的完成作业数(默认为1)
schedule: '*/1 * * * *' #作业时间表。在此示例中,作业将每分钟运行一次
startingDeadlineSeconds: 15 #pod必须在规定时间后的15秒内开始执行,若超过该时间未执行,则任务将不运行,且标记失败
successfulJobsHistoryLimit: 3 #要保留的成功完成的作业数(默认为3)
terminationGracePeriodSeconds: 30 #job存活时间 默认不设置为永久
jobTemplate: #作业模板。这类似于工作示例
示例:
每隔一分钟输出一条信息,打印hello
vim cronjob.yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: lcdb
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: lcdb
image: busybox
args:
- /bin/sh
- -c
- date; echo lcdb from the Kubernetes cluster
restartPolicy: OnFailure
kubectl apply -f cronjob.yaml
kubectl get pod
kubectl get cronjob
#清除cronjob资源
kubectl delete -f cronjob.yaml