大模型日报-20240125
文章目录
-
- 大模型推理速度飙升3.6倍,「美杜莎」论文来了,贾扬清:最优雅加速推理方案之一
- 买个机器人端茶倒水有希望了?Meta、纽约大学造了一个OK-Robot
- 画个框、输入文字,面包即刻出现:AI开始在3D场景「无中生有」了
- 首个通用双向Adapter多模态目标追踪方法BAT,入选AAAI 2024
- 药物-靶标亲和力预测,上科大团队开发了一种Transformer编码器和指纹图谱相结合的方法
- Anthropic 及 OpenAI 等头部 AI 初创公司毛利率不及云软件公司,现有合作模式或难以支撑未来增速与估值
- 从 Altman 对 GPT-5 的剧透中,我们应该如何迎接 AGI 的下一阶段?
- 《幻兽帕鲁》爆火,大厂坐不住了:这游戏是AI设计的?
- Pika北大斯坦福开源新框架,利用LLM提升理解力
- Dify 发布 AI Agent 能力:基于不同的大型语言模型构建 GPTs 和 Assistants
- Jim Fan提出基础AI代理应该在三个轴上进行扩展:技能、表现形式、现实
- Jason Wei谈人工智能研究领域中的员工和GPU/TPU
- Elvis分享优秀机器学习Youtube课程集合
- Killian:我们正在构建一个开源的Rabbit R1
- 大型语言模型课程
- RAGxplorer
- 详解专家混合:MoE模型
- 顶会最新速递@ ICLR2024,强化学习领域约301篇Accept论文汇总整理
- 大模型的高效训练和部署技术卷出新高度!
- Mistral AI:探索LLM推理的吞吐、时延及成本空间
- 通过4个任务比较LangChain和LlamaIndex
大模型推理速度飙升3.6倍,「美杜莎」论文来了,贾扬清:最优雅加速推理方案之一
链接:https://news.miracleplus.com/share_link/16622
在本文中,来自普林斯顿大学、Together.AI、伊利诺伊大学厄巴纳 - 香槟分校等机构的研究者没有使用单独的草稿模型来顺序生成候选输出,而是重新审视并完善了在主干模型之上使用多个解码头加速推理的概念。他们发现,如果该技术得到有效应用,可以克服推测解码的挑战,从而无缝地集成到现有 LLM 系统中。具体来讲, 研究者提出了 MEDUSA,一种通过集成额外解码头(能够同时预测多个 tokens)来增强 LLM 推理的方法。这些头以参数高效的方式进行微调,并可以添加到任何现有模型中。至此,不需要任何新模型,MEDUSA 就可以轻松地集成地当前的 LLM 系统中(包括分布式环境),以确保友好用户体验。值得关注的是,该论文作者之一 Tri Dao 是近来非常火爆的 Transformer 替代架构 Mamba 的两位作者之一。他是 Together.AI 首席科学家,并即将成为普林斯顿大学计算机科学助理教授。
买个机器人端茶倒水有希望了?Meta、纽约大学造了一个OK-Robot

链接:https://news.miracleplus.com/share_link/16623
最近,纽约大学、Meta 研发出的一款机器人学会了这个技能。你只需要对它说,「把桌子上的玉米片拿到床头柜上」,它就能自己找到玉米片,并规划出路线和相应的动作,顺利完成任务。此外,它还能帮你整理东西或扔垃圾。这个机器人名叫 OK-Robot,由来自纽约大学、Meta 的研究者共同构建。他们将视觉语言模型(用于物体检测)、导航和抓取的基础模块整合到一个开放知识型框架中,为机器人的高效拾放操作提供了解决方案。
画个框、输入文字,面包即刻出现:AI开始在3D场景「无中生有」了

链接:https://news.miracleplus.com/share_link/16624
来自苏黎世联邦理工学院和谷歌,在论文《InseRF: Text-Driven Generative Object Insertion in Neural 3D Scenes》中,他们提出了一种名为 InseRF 的 3D 场景重建方法。InseRF 能基于用户提供的文本描述和参考视点中的 2D 边界框,在 3D 场景中生成新对象。
首个通用双向Adapter多模态目标追踪方法BAT,入选AAAI 2024

链接:https://news.miracleplus.com/share_link/16625
来自天津大学的研究人员设计出了一种双向 adapter 用于多模态跟踪 (BAT)。与在主导模态中添加辅助模态信息作为提示以增强基础模型在下游任务中的表示能力的方法 (通常使用 RGB 作为主要模态) 不同,该方法没有预设固定的主导模态 - 辅助模态,而是在辅助模态向主导模态变化的过程中动态提取有效信息。BAT 由两个共享参数的特定于模态分支的基础模型编码器和一个通用的双向 adapter 组成。在训练过程中,BAT 没有对基础模型进行完全的微调,每个特定的模态分支由具有固定参数的基础模型初始化,仅训练新增的双向 adapter。每个模态分支从其他模态中学习提示信息,与当前模态的特征信息相结合,增强表征能力。两个特定模态的分支通过通用双向 adapter 执行交互,在多模态非固定关联范式中动态地相互融合主导辅助信息。
药物-靶标亲和力预测,上科大团队开发了一种Transformer编码器和指纹图谱相结合的方法
链接:https://news.miracleplus.com/share_link/16626
药物与靶标之间的结合亲和力的预测对于药物发现至关重要。然而,现有方法的准确性仍需提高。另一方面,大多数深度学习方法只关注非共价(非键合)结合分子系统的预测,而忽略了在药物开发领域越来越受到关注的共价结合的情况。上海科技大学的研究团队提出了一种新的基于注意力的模型,称为 TEFDTA (Transformer Encoder and Fingerprint combined Prediction method for Drug-Target Affinity),来预测键合和非键合药物-靶标相互作用的结合亲和力。
Anthropic 及 OpenAI 等头部 AI 初创公司毛利率不及云软件公司,现有合作模式或难以支撑未来增速与估值

链接:https://news.miracleplus.com/share_link/16627
根据 Information 最新报道,在过去的一年中,Anthropic 通过其快速的收入增长和对未来销售的大规模预测,筹集了数十亿美元,估值超过 150 亿美元。然而,随着 Anthropic 和许多竞争对手的成熟,他们需要优先考虑利润率和现金流,以期建立一个可持续的业务,并有望在未来某一天上市。最新数据显示,AI 初创公司的利润率可能会低于现有企业软件公司。根据两位了解相关数据的人士透露,经过支付客户支持和用于支持其 AI 的服务器成本后,Anthropic 的毛利率,即毛利润占收入的百分比——在去年 12 月份介于 50%~55%,这远低于 Meritech Capital 报道的云软件股票平均毛利率的 77%。
从 Altman 对 GPT-5 的剧透中,我们应该如何迎接 AGI 的下一阶段?
链接:https://news.miracleplus.com/share_link/16628
前几天的 2024 达沃斯世界经济论坛上,Sam Altman 谈到了 GPT 发展的一些新的方向及可能性,对于当下大模型的一些现状的分析。
《幻兽帕鲁》爆火,大厂坐不住了:这游戏是AI设计的?

链接:https://news.miracleplus.com/share_link/16629
最近,很多社交网络平台都被一款开放世界生存游戏刷了屏。《幻兽帕鲁》(Palworld)是当下最热门的话题之一,它在 1 月 19 日于 Steam 上线抢先体验版本,24 小时之内销量就超过了 200 万份,几天之内就突破了 600 万。在 1 月 23 日,幻兽帕鲁的 Steam 历史在线峰值就达到了 185 万人,超越了《CS 2》,成为了 Steam 历史在线玩家峰值第二的游戏。除了出乎预料的火爆,另一个让人难以想象的就是,幻兽帕鲁出自一个「小作坊」,项目开工的时候全公司只有 10 个人。在幻兽帕鲁游戏中,作者设计出了一个内容丰富、生机勃勃(也充满既视感)的世界。
Pika北大斯坦福开源新框架,利用LLM提升理解力
链接:https://news.miracleplus.com/share_link/16630
北大和斯坦福大学联合Pika AI共同开发了一个新的文本-图像生成/编辑框架RPG(Recaption, Plan and Generate),旨在提升扩散模型对复杂提示词的理解能力。该框架通过多模态重新描述、思维链规划和互补区域扩散策略,无需额外训练即可生成更自然、细节更丰富的图片。RPG框架兼容多种多模态大模型和扩散模型主干网络,能够实现图像生成和编辑的闭环,效果超越了当前的图像生成模型如Dall·E 3和SDXL。研究团队包括北大计算机学院的崔斌教授和Pika的联合创始人兼CTO Chenlin Meng等。相关论文和代码已开源。
Dify 发布 AI Agent 能力:基于不同的大型语言模型构建 GPTs 和 Assistants
链接:https://news.miracleplus.com/share_link/16631
Dify.AI发布了新版本v0.5.0,引入了AI Agent能力,允许开发者基于不同的大型语言模型(LLMs)构建GPTs和智能助手(Assistants)。这个开源平台支持所有流行的LLMs,包括OpenAI、ChatGLM、Tongyi等,提供了Function Calling和ReAct两种推理模式。Dify还提供了11个内置工具,如Google搜索、DALL·E绘画、Vectorizer.AI等,以及支持自定义API工具的接入。这些工具可以帮助LLM解决多步骤复杂问题,实现更高级的AI Agent功能。Dify的更新还包括对产品功能入口的调整,以更好地传达其设计理念。
Jim Fan提出基础AI代理应该在三个轴上进行扩展:技能、表现形式、现实
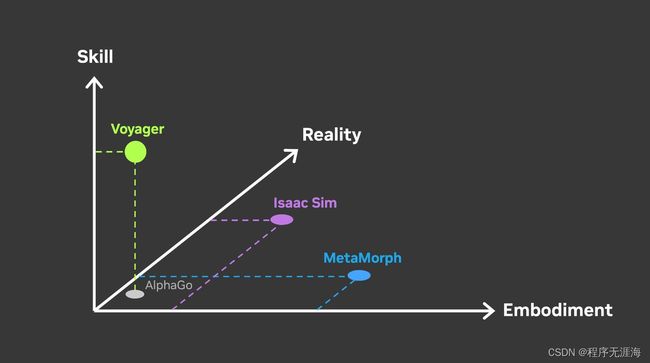
链接:https://news.miracleplus.com/share_link/16632
基础AI代理应该在三个轴上进行扩展:
-
技能:它能解决的任务数量;
-
表现形式:它能控制的身体形态的多样性;
-
现实:该代理能够掌握的世界数量,无论是虚拟的还是物理的。这包括游戏、模拟和现实世界场景,这些场景具有不同的机制和规则。
为什么我们想要一个单一的基金会代理,而不是许多较小的模型?我想引用我的朋友教授 @yukez 在 CoRL 主题演讲中的想法。如果我们追溯每个人工智能领域的发展,我们会发现这样的模式:
专家 -> 通才 -> 专业化的通才
而“专业化的通才”通常比最初的专家强大得多。就像 LlaMA 的蒸馏版本比五年前定制的自然语言处理系统要好得多。
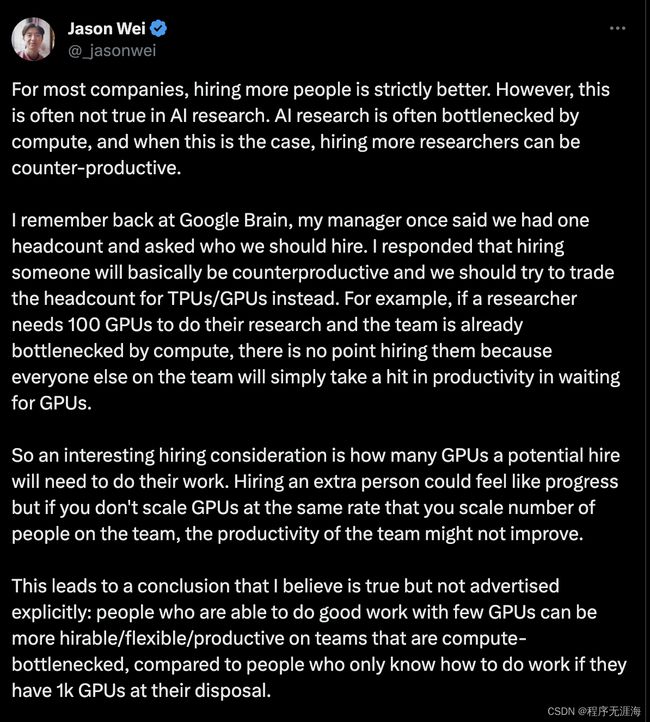
Jason Wei谈人工智能研究领域中的员工和GPU/TPU

链接:https://news.miracleplus.com/share_link/16633
对于大多数公司来说,增加员工通常是更好的选择。然而,在人工智能研究领域,这通常不是真的。人工智能研究经常受限于计算能力,当出现这种情况时,增加研究人员可能适得其反。
我记得在谷歌大脑时,我的经理曾经说我们只有一个名额,问我们应该雇谁。我回答说,雇佣某人基本上会适得其反,我们应该尝试将这个名额换成 TPU/GPU。例如,如果一个研究员需要 100 个 GPU 来进行他们的研究,并且团队已经受限于计算能力,那么雇佣他们是没有意义的,因为团队中的其他人将在等待 GPU 时损失生产力。
因此,一个有趣的招聘考虑因素是,潜在雇员需要多少 GPU 来完成他们的工作。增加一个额外的人可能感觉像是进步,但是如果你不以与团队人数相同的速度扩展 GPU,那么团队的生产力可能不会提高。
这导致了我相信是正确的但没有明确宣传的结论:在计算能力受限的团队中,能够使用较少的 GPU 做出良好工作的人可能比只有在他们有 1000 个 GPU 可用时才知道如何工作的人更有招聘价值/灵活性/生产力。
(不过有一个注意点——如果你雇佣的新人比当前团队更高效地使用 GPU,那么这可能是可以接受的,因为尽管每人的生产力下降,但团队的总体生产力将增加。相反,如果你雇佣的新人需要使用许多 GPU 并且使用效率不高,那么团队的总体生产力和每人的生产力都将下降。)
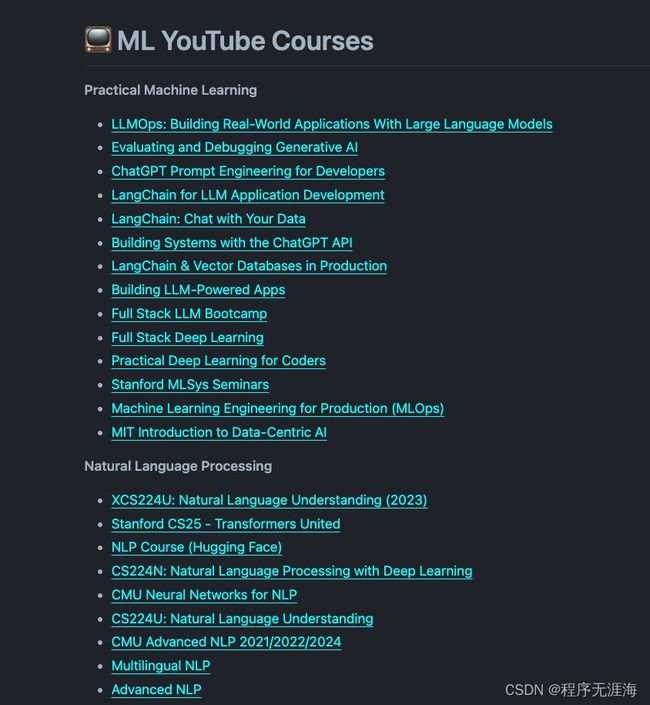
Elvis分享优秀机器学习Youtube课程集合
链接:https://news.miracleplus.com/share_link/16636
ML YouTube 课程(约 12K⭐️)
令人印象深刻的是,有这么多高质量的免费人工智能课程。
为了使它们易于查找,我维护了这个集合,包括了我最喜欢的一些课程,涵盖了自然语言处理、深度学习、LLMOps、机器学习数学等主题。
这对全世界的成千上万的学生、研究人员甚至开发人员都很有用。
Killian:我们正在构建一个开源的Rabbit R1

链接:https://news.miracleplus.com/share_link/16637
哇。在我时间线上看到这个,就在那个泄露的Rabbit R1的TikTok下面,它有20秒的延迟。
Vikhyatk 在01核心团队中。我们正在构建一个开源的Rabbit R1。
在5周内,像这样的模型将在你手中本地运行
大型语言模型课程
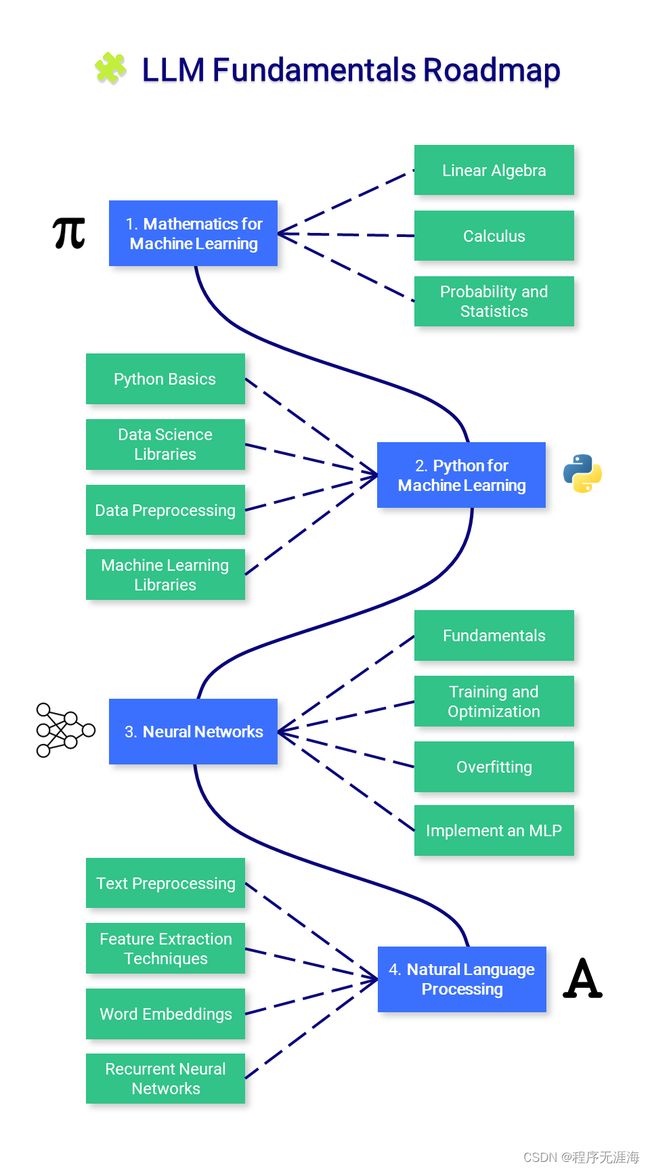
链接:https://news.miracleplus.com/share_link/12188
该课程分为三个部分:
1.LLM 基础知识涵盖有关数学、Python 和神经网络的基本知识。
2.相关科学家借助大模型技术构建的产品。
3.相关工程师创建基于大模型技术的应用程序并部署。
RAGxplorer
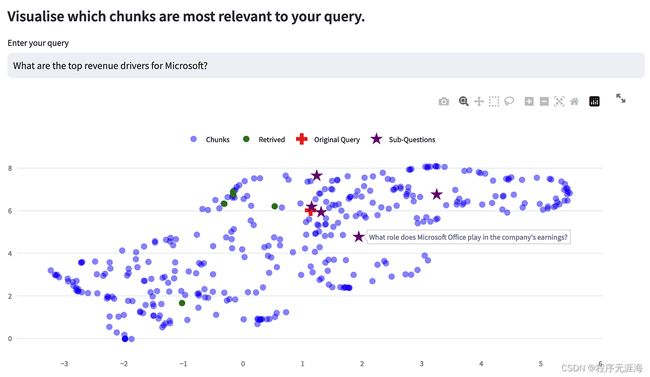
链接:https://news.miracleplus.com/share_link/16644
RAGxplorer 是一个交互式的 Streamlit 工具,希望可以通过可视化文档块和嵌入空间中的查询来支持检索增强生成(RAG)应用程序的构建。
详解专家混合:MoE模型
链接:https://news.miracleplus.com/share_link/16646
该文章深入探讨了混合专家模型(MoE),特别是新推出的Mixtral 8x7B。MoE是一种将多个专家神经网络整合在一起的Transformer技术,通过门控网络进行token路由,优化了预训练速度和推理效率。由于只在推理时使用部分专家参数,MoE可以在保有大量参数的同时提高推理速度。文章还讨论了MoE在自然语言处理(NLP)领域的应用和面临的挑战,如通信成本高和训练不稳定等,以及研究者为提升模型稳定性和效率所做的最新进展。
顶会最新速递@ ICLR2024,强化学习领域约301篇Accept论文汇总整理
链接:https://news.miracleplus.com/share_link/16647
ICLR2024会议上,强化学习领域的论文接受情况被整理汇总,共有约301篇论文被接受,包括11篇口头报告(Oral)、59篇亮点论文(Spotlight)和231篇海报论文(Poster)。这些论文涵盖了多个子领域,如深度强化学习、多智能体系统、语言模型与强化学习的结合、世界模型、规划、长期记忆任务、逆强化学习、因果世界模型学习等。文章还提供了论文的原始PDF链接和交流群信息,以便读者进一步了解和讨论这些研究成果。
大模型的高效训练和部署技术卷出新高度!
链接:https://news.miracleplus.com/share_link/16648
文章深入探讨了大模型训练的挑战,特别是随着模型参数量的指数级增长,如何实现高效的分布式训练。Colossal-AI作为一个解决方案,提供了高效的内存管理、N维并行系统和低延迟推理系统,以支持在不同硬件上进行大规模AI模型的训练。文章详细分析了数据并行、流水线并行和张量并行的优化策略,以及如何通过这些策略提高训练效率和降低成本。特别提到了Colossal-AI在处理长序列模型时的Ring Self-Attention方法,该方法通过减少通信操作来提高训练效率,文章还讨论了Colossal-AI在实际应用中的性能表现,如在Stable Diffusion模型上的加速效果,以及与DeepSpeed等其他框架的比较。
Mistral AI:探索LLM推理的吞吐、时延及成本空间
链接:https://news.miracleplus.com/share_link/16649
Mistral AI首席技术官Timothée Lacroix在演讲中探讨了大型语言模型(LLM)推理的吞吐量、时延和成本。他强调了选择合适的推理栈对于部署语言大模型的重要性,并讨论了影响这些指标的因素,包括硬件和软件层面。Lacroix分享了一些优化技巧,如分组查询注意力、量化、分页注意力和滑动窗口注意力,以及如何通过代码优化来提高性能。他还提到了Mistral AI发布的开源MoE大模型Mixtral-8x7B,并讨论了在不同硬件上部署模型的成本效益。最后,他回答了听众关于处理器选择、Python开销减少和多语言模型训练的问题。
通过4个任务比较LangChain和LlamaIndex
链接:https://news.miracleplus.com/share_link/16650
本文通过四个任务对比了LangChain和LlamaIndex两个框架在构建大型语言模型(LLM)应用方面的优劣。LangChain是一个通用框架,适用于多种LLM应用,而LlamaIndex专注于构建检索增强型生成(RAG)系统。在创建聊天机器人、构建RAG系统、整合RAG和聊天机器人以及实现代理功能的任务中,LlamaIndex提供了更简洁的代码和更直接的RAG管道封装。LangChain则提供了更广泛的应用支持,但在RAG特定任务上,其代码实现更为复杂。LlamaIndex在RAG用例中表现更佳,而LangChain在非RAG功能上可能更有优势。