天池学习赛--淘宝用户购物行为数据可视化分析
学习赛内容
2014年是阿里巴巴集团移动电商业务快速发展的一年,例如2014双11大促中移动端成交占比达到42.6%,超过240亿元。相比PC时代,移动端网络的访问是随时随地的,具有更丰富的场景数据,比如用户的位置信息、用户访问的时间规律等。
本次可视化分析的目的是针对脱敏过的用户行为数据(包括浏览、收藏、加购和购买4类数据)进行分析,使用Python、Numpy、Pandas和Matplotlib工具完成可视化分析,帮助选手更好的理解数据,并作出商业洞察。
官网地址
数据集分析

数据中有5个维度的字段,其分别表示用户id、商品id、用户行为类型、商品类别以及时间信息。充分理解这些字段的含义是数据分析的基础,这里我们列出这些字段的主要信息:
字段 字段说明 提取说明
user_id 用户标识 抽样和字段脱敏
item_id 商品标识 字段脱敏
behavior_type 用户对商品的行为类型 包括浏览、收藏、加购物车、购买,对应取值分别是1、2、3、4
item_category 商品分类标识 字段脱敏
time 行为时间 精确到小时级别
由于官网并没有给出商品分类标识的含义,所以说商品标识和商品分类标识暂时用不到。
1.导入数据集
使用类包:pandas
官网介绍:pandas is a fast, powerful, flexible and easy to use open source data analysis and manipulation tool,
built on top of the Python programming language.
# 加载数据
def getData(url='user_action.csv'):
"""
根据路径加载数据
:param url: 文件名称
:return:
"""
data_user = pd.read_csv(url)
# data_head = data_user.head(50)
# print(data_head)
#
# # 查看数据集量级
# print('整体数据的大小为', len(data_user))
#
# print('数据集中用户数量是:', len(set(data_user['user_id'])))
# print('数据集中商品数量是:', len(set(data_user['item_id'])))
# print('数据集中商品类别数量是:', len(set(data_user['item_category'])))
# 查看数据缺失情况
# print(data_user.isnull().sum())
# 分割天(date)和小时(hour)
data_user['date'] = data_user['time'].map(lambda x: x.split(' ')[0])
data_user['hour'] = data_user['time'].map(lambda x: x.split(' ')[1])
# data_head2 = data_user.head(20)
# print(data_head2)
user_ids = data_user['user_id'].unique()
return user_ids, data_user
将数据集中时间进行了天和小时的分割,同时返回了数据集中包含用户的id。
2.流量分析:PV/UV是多少,通过分析PV/UV能发现什么规律?
def compute_uv_daily(data_user):
# 访问量(PV):全名为Page View, 基于用户每次对淘宝页面的刷新次数,用户每刷新一次页面或者打开新的页面就记录就算一次访问。
pv_daily = data_user.groupby('date')['user_id'].count()
pv_daily = pv_daily.reset_index()
pv_daily = pv_daily.rename(columns={'user_id': 'pv_daily'})
# print("每日pv:")
# print(pv_daily.head())
# 独立访问量(UV):全名为Unique Visitor,一个用户若多次访问淘宝只记录一次,熟悉SQL的小伙伴会知道,本质上是unique操作。
uv_daily = data_user.groupby('date')['user_id'].apply(lambda x: len(x.unique()))
uv_daily = uv_daily.reset_index()
uv_daily = uv_daily.rename(columns={'user_id': 'uv_daily'})
# print("每日uv:")
# print(uv_daily.head())
uv_pv_daily = uv_daily.rename(columns={'uv_daily': 'pv/uv_daily'})
uv_pv_daily["pv/uv_daily"] = pv_daily["pv_daily"] / uv_daily["uv_daily"]
print("每日用户平均访问页面pv/uv=")
print(uv_pv_daily)
# 可视化
fig, axes = plt.subplots(3, 1, sharex=True)
# pv_daily: pandas 对象
# Matplotlib, Pandas , histplot: 柱状图
pv_daily.plot(x='date', y='pv_daily', ax=axes[0], colormap='cividis')
uv_daily.plot(x='date', y='uv_daily', ax=axes[1], colormap='RdGy')
uv_pv_daily.plot(x='date', y='pv/uv_daily', ax=axes[2], colormap='RdGy')
axes[0].set_title('pv_daily')
axes[1].set_title('uv_daily')
axes[2].set_title('pv/uv_daily')
plt.show()
def compute_uv_hourly(data_user):
pv_hour = data_user.groupby('hour')['user_id'].count()
pv_hour = pv_hour.reset_index()
pv_hour = pv_hour.rename(columns={'user_id': 'pv_hour'})
uv_hour = data_user.groupby('hour')['user_id'].apply(lambda x: len(x.unique()))
uv_hour = uv_hour.reset_index()
uv_hour = uv_hour.rename(columns={'user_id': 'uv_hour'})
uv_pv_hour = uv_hour.rename(columns={'uv_hour': 'pv/uv_hour'})
uv_pv_hour["pv/uv_hour"] = pv_hour["pv_hour"] / uv_hour["uv_hour"]
# 可视化
fig, axes = plt.subplots(3, 1, sharex=True)
# pv_daily: pandas 对象
# Matplotlib, Pandas , histplot: 柱状图
pv_hour.plot(x='hour', y='pv_hour', ax=axes[0], colormap='cividis')
uv_hour.plot(x='hour', y='uv_hour', ax=axes[1], colormap='RdGy')
uv_pv_hour.plot(x='hour', y='pv/uv_hour', ax=axes[2], colormap='RdGy')
axes[0].set_title('pv_hour')
axes[1].set_title('uv_hour')
axes[2].set_title('pv/uv_hour')
plt.show()
每日的流量分析

可以看出在12.12日左右,流量出现一个显著的上升。这说明商家退出的促销活动确实能提高用户的流量。
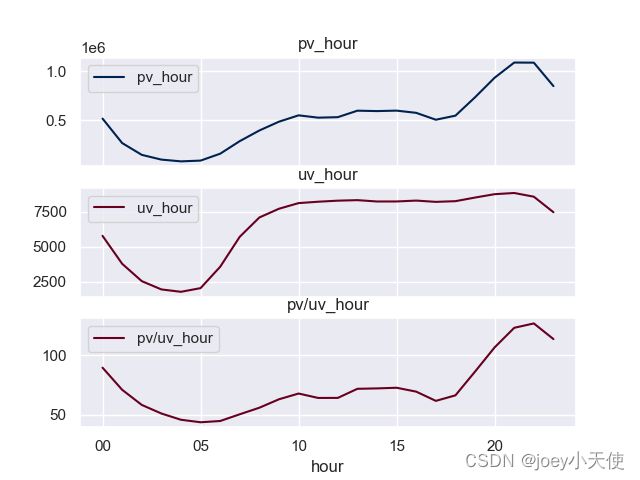
观察每日的流量分布,可以看出流量在18点左右开始出现显著的上升,说明工薪阶层是流量的主力,下班后有更多的时间来浏览商品。
在凌晨5点左右的流量最小,说明可以在此时进行服务器维护或者版本升级。
3. 漏斗分析:用户“浏览-收藏-加购-购买”的转化率是怎样的?哪一步的折损比例最大?
先总的来看所有用户的转化率
def getBehavior(data_user):
behavior_type = data_user.groupby(['behavior_type'])['user_id'].count()
print(behavior_type)
click_num, fav_num, add_num, pay_num = behavior_type[1], behavior_type[2], behavior_type[3], behavior_type[4]
# 发现人们直接从浏览到购买的转换率是最低的,而从加购或者是收藏转换到购买概率是非常大,这和我们的购物日常相似,但是也存在差异每个用户的购物习惯是不同的,接下来对单独的用户进行分析
showDates(click_num, fav_num, add_num, pay_num)
def showDates(click_num, fav_num, add_num, pay_num):
print('浏览--收藏转化率:{:.2}%'.format(100 * fav_num / click_num))
print('浏览--加购转化率:{:.2}%'.format(100 * add_num / click_num))
print('点击 到 购买转化率: {:.2}%'.format(100 * pay_num / click_num))
if fav_num != 0:
print('收藏 到 购买转化率: {}%'.format(100 * pay_num / fav_num))
if add_num != 0:
print('加购 到 购买转化率: {}%'.format(100 * pay_num / add_num))
运行结果
behavior_type
1 11550581
2 242556
3 343564
4 120205
Name: user_id, dtype: int64
浏览--收藏转化率:2.1%
浏览--加购转化率:3.0%
点击 到 购买转化率: 1.0%
收藏 到 购买转化率: 49.557627929220466%
加购 到 购买转化率: 34.98765877682179%
程序的运行时间是: 0:00:09.034494
可以看出用户从点击到购买的损失率是最高的,而从收藏到购买的转化率是最高的,可以采用一些手段鼓励用户收藏产品或者加入购物车。
接下来看一下个体用户的转化率:
def getBehaviorOne(user_ids, data_user):
# 对单独的个体进行分析
behavior_type_userOne = data_user.groupby(['user_id', 'behavior_type'])['item_id'].count()
behavior_type_userOne = behavior_type_userOne.reset_index()
behavior_type_userOne = behavior_type_userOne.rename(columns={'item_id': 'amount'})
# print(behavior_type_userOne)
behavior_type_userOne_list = behavior_type_userOne.values.tolist()
print(behavior_type_userOne_list[1])
temp_index = behavior_type_userOne_list[0][0] # 初始用户
click_num, fav_num, add_num, pay_num = 0, 0, 0, 0
for i in range(len(behavior_type_userOne_list)):
user_index = behavior_type_userOne_list[i][0]
if user_index != temp_index:
# 输出上一个用户的全部具体数据
print("用户{}的数据为".format(temp_index))
# showDates(click_num, fav_num, add_num, pay_num)
if pay_num / click_num > 0.01:
print("用户{}是个疯狂购物者".format(temp_index))
if pay_num / click_num < 0.0001:
print("用户{}只是看看,很少购买".format(temp_index))
print("-------------------------------------------------------------------------")
temp_index = user_index
click_num, fav_num, add_num, pay_num = 0, 0, 0, 0
type_index = behavior_type_userOne_list[i][1]
amount_index = behavior_type_userOne_list[i][2]
if type_index == 1:
click_num = amount_index
if type_index == 2:
fav_num = amount_index
if type_index == 3:
add_num = amount_index
if type_index == 4:
pay_num = amount_index
这样有利对每个用户进行单独的分析。
如果用户点击10000个商品都不购买一个我们称它为“白嫖怪”。

计算复购用户的比例:
def repurchase(data_user):
# 计算用户购买频次
data_user_pay = data_user[data_user.behavior_type == 4]
# 基于date去重,得到的结果即为购物分布的天数:
data_user_pay = data_user_pay.groupby('user_id')['date'].apply(lambda x: len(x.unique()))
repeat_buy_ratio = data_user_pay[data_user_pay > 1].count() / data_user_pay.count()
return repeat_buy_ratio
达到了惊人的0.8717083051991897说明用户一旦在某个app上购买东西,他就很容易重复购买。所以app应该给与新用户极大的优惠券来诱使新用户购物。
单独一个用户的复购次数
4.用户价值分析:对电商平台什么样的用户是有价值的?如果你作为商家,要重点关注哪部分用户?
def latestBut(data_user):
buyTimesUser = data_user.groupby(['user_id', 'time', 'behavior_type'])
temp_index = 4913
temp_time = '2000-01-01 00'
i = 1
for label, values in buyTimesUser:
if label[0] != temp_index:
if temp_time == '2000-01-01 00':
print("该用户真的是白嫖党啊,只看不买")
temp_index = label[0]
# print(i)
# i = i + 1
else:
print("用户{}最近的购买时间是".format(temp_index))
print(temp_time)
temp_index = label[0]
temp_time = '2000-01-01 00'
if label[0] == temp_index:
if label[2] == 4:
if timeCompareMy(temp_time, label[1]):
temp_time = label[1]
统计用户的最近购买时间。
2014-12-14 15
用户142368840最近的购买时间是
2014-12-16 12
用户142376113最近的购买时间是
2014-12-08 16
用户142412247最近的购买时间是
2014-12-15 10
用户142430177最近的购买时间是
2014-12-18 10
用户142450275最近的购买时间是
2014-12-13 12
最近购买时间越远的用户越需要挖掘!!!
统计用户购买次数
def buyTimes(data_user):
## 浏览 >> 加购/收藏 >> 购买(4)
data_user_buy = data_user[data_user.behavior_type == 4].groupby('user_id')['behavior_type'].count()
data_user_buy.plot(x='user_id', y='buy_count')
plt.show()

用户购买的次数越少越要挖掘