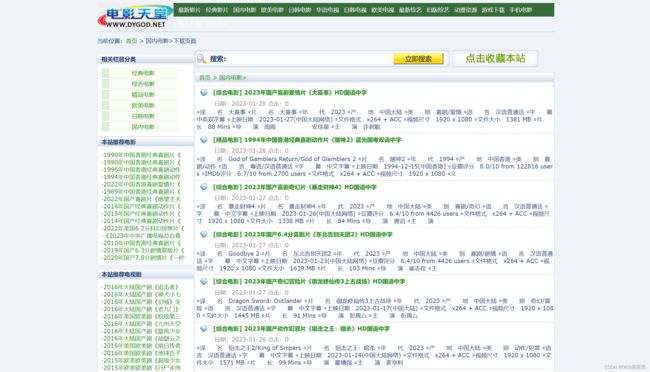
一、爬取目标网站数据,关键项不能少于5项。
首先需导入requests、BeautifulSoup、xlwt、re第三方库
代码如下:
import requests
import re
import xlwt
from bs4 import BeautifulSoup
url = 'https://www.dygod.net/html/gndy/china/'
hd = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.188'
}
def getmanget(linkurl):
res = requests.get(linkurl, headers=hd)
res.encoding = 'GBK'
soup = BeautifulSoup(res.text, 'html.parser')
ret = soup.find_all('a')
for n in ret:
if 'magnet' in str(n.string):
return n.string
return None
def saveExcel(worksheet, count, lst):
for i in range(6):
worksheet.write(count, i, lst[i])
count = 0
workbook = xlwt.Workbook(encoding='utf-8')
worksheet = workbook.add_sheet('sheet1')
for i in range(2, 3):
url = 'https://www.dygod.net/html/gndy/china/index_' + str(i) + '.html'
res = requests.get(url, headers=hd)
res.encoding = 'GBK'
soup = BeautifulSoup(res.text, 'html.parser')
ret = soup.find_all(class_='tbspan', style='margin-top:6px')
for x in ret:
info = []
a_tags = x.find_all("a")
info.append(a_tags[1].string)
pat = re.compile(r'◎译 名(.*)\n')
ret = re.findall(pat, str(x))
for n in ret:
n = n.replace(u'\u3000', u'')
info.append(str(n).split('/')[0])
pat = re.compile(r'◎年 代(.*)\n')
ret = re.findall(pat, str(x))
for n in ret:
n = n.replace(u'\u3000', u'')
info.append(str(n))
pat = re.compile(r'◎产 地(.*)\n')
ret = re.findall(pat, str(x))
for n in ret:
n = n.replace(u'\u3000', u'')
info.append(str(n).split('/')[0])
pat = re.compile(r'◎类 别(.*)\n')
ret = re.findall(pat, str(x))
for n in ret:
n = n.replace(u'\u3000', u'')
info.append(str(n).split('/')[0])
linkurl = 'https://www.dygod.net/' + a_tags[1].get("href")
manget = getmanget(linkurl)
if manget:
info.append(str(manget))
saveExcel(worksheet, count, info)
count += 1
workbook.save('movie.xls')
print(f"共爬取了 {count} 部电影")
运行结果:


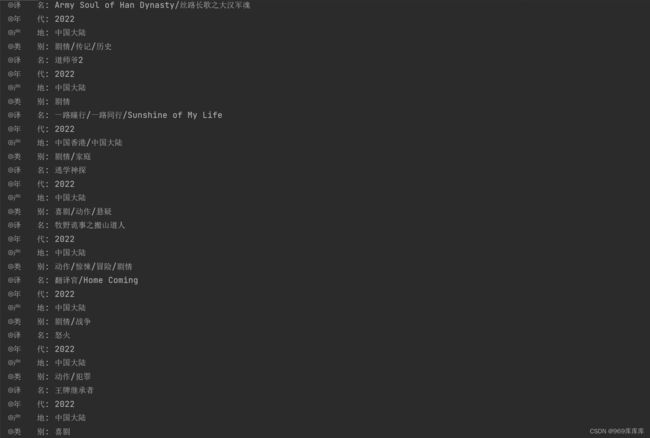
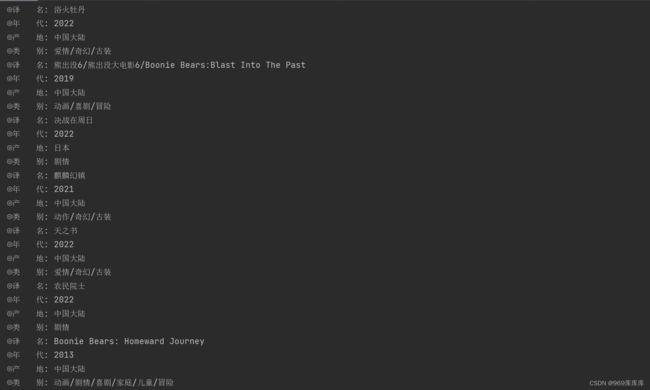
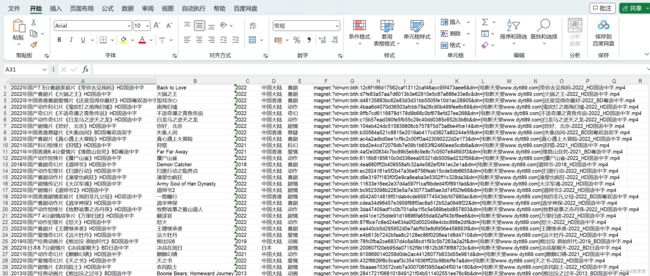
 将爬取的电影存储在excel中:
将爬取的电影存储在excel中:
二、将以上代码存储在SQLite数据库中并可以进行增、删、改操作:
上述代码不变,只需增加以下代码
代码如下:
# 添加函数:从数据库中查询所有电影信息
def query_movies(conn):
cursor = conn.cursor()
cursor.execute("SELECT * FROM movies")
return cursor.fetchall()
# 添加函数:根据电影名称查询电影信息
def query_movie_by_name(conn, movie_name):
cursor = conn.cursor()
cursor.execute("SELECT * FROM movies WHERE name LIKE ?", ('%' + movie_name + '%',))
return cursor.fetchall()
# 添加函数:根据电影ID删除电影信息
def delete_movie_by_id(conn, movie_id):
cursor = conn.cursor()
cursor.execute("DELETE FROM movies WHERE id = ?", (movie_id,))
conn.commit()
# 添加函数:根据电影ID更新电影信息
def update_movie_info(conn, movie_id, new_info):
cursor = conn.cursor()
cursor.execute("UPDATE movies SET name=?, translation=?, year=?, area=?, category=?, magnet=? WHERE id=?", new_info + (movie_id,))
conn.commit()
# 示例:查询所有电影信息并打印
conn = sqlite3.connect('movie_database.db')
all_movies = query_movies(conn)
print("所有电影信息:")
for movie in all_movies:
print(movie)
# 示例:根据电影名称查询电影信息并打印
search_name = "复仇"
movies_by_name = query_movie_by_name(conn, search_name)
print(f"电影名称中包含'{search_name}'的电影信息:")
for movie in movies_by_name:
print(movie)
# 示例:删除电影信息并更新
delete_movie_id = 1 # 需要根据实际情况指定要删除的电影ID
delete_movie_by_id(conn, delete_movie_id)
print(f"删除电影ID为{delete_movie_id}的电影信息")
update_movie_id = 2 # 需要根据实际情况指定要更新的电影ID
new_movie_info = ("小龙女", "小龙女", "2022", "中国大陆", "爱情/奇幻/古装", "magent=新下载地址") # 需要根据实际情况指定新的电影信息
update_movie_info(conn, update_movie_id, new_movie_info)
print(f"更新电影ID为{update_movie_id}的电影信息为:{new_movie_info}")
# 关闭数据库连接
conn.close()
运行结果如下:


扩展:将数据可视化展示
需导入pandas、matplotlib第三方库
代码如下:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 读取Excel文件并创建DataFrame
df = pd.read_excel('movie.xls')
# 设置中文字体
font = FontProperties(fname=r"C:\Windows\Fonts\simsun.ttc", size=14)
# 统计产地信息
area_counts = df[df.columns[2]].value_counts()
# 创建条形统计图
plt.figure(figsize=(10, 6))
area_counts.plot(kind='bar', color='skyblue', edgecolor='black')
# 设置图表标题和轴标签
plt.title('电影年代统计', fontproperties=font)
plt.xlabel('年代', fontproperties=font)
plt.ylabel('数量', fontproperties=font)
# 设置x轴刻度旋转
plt.xticks(rotation=45, fontproperties=font)
# 显示图表
plt.show()
运行结果如下:

至此,项目结束