Linux系统编程(二)文件IO/系统调用IO
一、IO 简介
I/O 是一切实现的基础:
- 标准 IO(stdio);
- 系统调用 IO(sysio,文件IO);
不同系统上的系统调用 IO 的使用方式可能不一样,为了隐藏不同系统上的细节,提出了标准 IO 给程序员调用,标准 IO 的实现是依赖于系统调用 IO 的,但是标准 IO 的可移植性更好。
文件 IO 都是不带缓冲的 IO,而标准 IO 是带缓冲的 IO。
二、系统调用 IO
部分系统调用 IO 如下(文件描述符 fd 贯穿始终):
- open()、close()
- read()、write()
- lseek()
- dup()、dup2()
- sync()、fsync()、fdatasync()
- fcntl()
- ioctl()
2.1 文件描述符 fd
fd 是一个整形数,实际上为一个数组的下标,数组的内容指向一个结构体,结构体中包含了当前打开文件的信息(如文件位置指针 pos),该信息包含指向文件的 inode 节点的指针,每使用 open() 系统调用就会创建一个该结构体,多次对一个文件使用 open() 系统调用会创建多个结构体,这些结构体都指向同一个 inode 节点,如下图所示:

其中,文件描述符 0 与进程的标准输入(stdin)关联,文件描述符 1 与进程的标准输出(stdout)关联,文件描述符 2 与进程的标准错误(stderr)关联。
2.2 open()、close()
以 flag 指定的模式打开文件,返回文件描述符 fd。
#include
#include
#include
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode); 参数 flags 必须包含下面三种模式之一:
- O_RDONLY:以只读打开文件;
- O_WRONLY:以只写打开文件;
- O_RDWR:以可读可写打开文件;
另外,flags 还可以包含如下创建选项(creation flags)和状态选项(status flags):
- O_CREAT:若文件不存在则创建它;
- O_EXCL:该文件必须是新文件,否则报错,一般和 O_CREAT 一起用;
- O_APPEND:写内容追加到文件末尾;
- O_ASYNC:使能信号驱动 IO(signal-driven I/O);
- O_DIRECT:最小化 cache 的影响(cache 一般理解为读的缓冲区,即读加速;buffer 一般理解为写的缓冲区,即加速写);
- O_NONBLOCK:非阻塞,打开文件和后续的操作不会等待,直接返回(比如请求的锁正在被使用),而阻塞模式则会等待请求的资源,不加此选项则默认为阻塞模式;
- O_TRUNC:若文件存在,而且以只写或读-写打开,则将文件长度截断为 0;
重载:函数名相同,参数的类型和个数不相同。但上述两个 open 函数不是使用重载实现的,而是使用变参函数实现的。
另外,还有一种系统调用 openat() 能够使用相对路径名打开目录中的文件。
2.3 read()、write()
read() 系统调用会从文件描述符 fd 中读取 count 个字节的数据到 buf 中,返回读到的字节个数。
#include
ssize_t read(int fd, void *buf, size_t count); write() 系统调用将 buf 中的 count 个字节数据写入文件描述符 fd 中,返回写入的字节数。
#include
ssize_t write(int fd, const void *buf, size_t count); 下面使用 read 和 write 实现 mycopy,注意在 write 的时候要判断是否写入对应字节的数据,若没有写完,可以报错或者使用 while 循环写完。
#include
#include
#include
#include
#include
#include
#define BUFSIZE 1024
int main(int argc, char *argv[])
{
if (argc < 3) {
fprintf(stderr, "Usage:...\n");
exit(1);
}
int fd1, fd2;
if ((fd1 = open(argv[1], O_RDONLY)) < 0) {
perror("fopen:");
exit(1);
}
if ((fd2 = open(argv[2], O_CREAT | O_WRONLY | O_TRUNC, 0600)) < 0) {
close(fd1);
perror("fopen:");
exit(1);
}
char buf[BUFSIZE];
int n;
while ((n = read(fd1, buf, BUFSIZE)) > 0) {
if (write(fd2, buf, n) != n) {
perror("write:");
break;
}
}
close(fd1);
close(fd2);
exit(0);
} 2.4 lseek()
将文件的位置指针设置为相对于 whence 偏移 offset 的位置,并且返回当前文件位置(相当于 fseek 和 ftell 的结合体)。
#include
#include
off_t lseek(int fd, off_t offset, int whence); 其中 whence 有如下几种:
- SEEK_SET:代表将文件位置指针设置为 offset 处;
- SEEK_CUR:将文件位置指针设置为当前位置加上 offset 处;
- SEEK_END:将文件位置指针设置为文件末尾加上 offset 处;
lseek 只修改文件表项(中间那层结构体)中的当前文件偏移量(pos),不进行任何 IO 操作(可以参考下面的删除文件中任意行的代码)。
2.5 dup()、dup2()
dup() 系统调用可以复制一个文件描述符,新的文件描述符会使用当前可用的最小的文件描述符(新和旧的文件描述符指向的内容是一样的,)。
dup2() 系统调用的功能和 dup() 一样,区别就是 dup2() 会指定新的文件描述符,当新文件描述符已经被打开,则先关闭新的文件描述符,再执行拷贝操作。如果 oldfd 和 newfd 相同,则什么都不做,直接返回,并且 dup2() 是一个原子操作。
#include
int dup(int oldfd);
int dup2(int oldfd, int newfd); 以开头那张图为例,其中 fd1为使用 open() 系统调用打开文件得到的文件描述符,fd2 为对 fd1 使用 dup() 系统调用得到的文件描述符,fd3 则是对与 fd1 同一个文件使用 open() 系统调用得到的文件描述符:
上述操作转换成代码如下:
char *filepath = ""
int fd1 = open(filepath, O_RDONLY);
int fd2 = dup(fd1);
int fd3 = open(filepath, O_RDONLY);
使用 dup() 系统调用可用实现很多功能,比如将标准输出重定向到文件,实现方式为,打开一个文件得到 fd,然后使用 close(1) 关闭标准输出,再使用 dup(fd) 拷贝 fd 到标准输出,之后在代码中对标准输出的写操作将会被重定向到文件中(现象就是命令窗口不会打印 hello,而文件 /tmp/out 中会出现 hello)。
上述的做法有一点问题就是,在多线程并发执行的情况下,关闭和拷贝不是原子的,这使得当一个进程关闭了标准输出后,另外一个进程可能会执行拷贝,这样就违背了最开始的目的。可用使用 dup2() 系统调用来解决这个问题:
#include
#include
#include
#include
#include
#include
/* The dup() system call creates a copy of the file descriptor oldfd, using
* the lowest-numbered unused file descriptor for the new descriptor.
*/
#define FILE_NAME "/tmp/out"
int main()
{
int fd = open(FILE_NAME, O_CREAT|O_WRONLY|O_TRUNC, 0600);
if (fd < 0) {
perror("open");
exit(1);
}
// wrong!! it is not Atomic, we should use dup2()!
//close(1);
dup2(fd, 1);
// 为了避免 fd = 1 导致把自己关闭了
if (fd != 1)
close(fd);
puts("hello!");
exit(0);
}
编译执行上述代码后,查看 /tmp/out 文件即可发现文件的内容出现 hello!

2.6 sync()、fsync()、fdatasync()
在操作系统中,大多数磁盘 IO 都通过缓冲区进行,内核会先把数据写入到缓冲区中,然后晚些时候再一起写入磁盘,这种方式被称为延迟写(delayed write)。
为了保证磁盘上实际文件系统与缓冲区的内容的一致性,操作系统提供了 sync、fsync、fdatasync 三个函数:
- sync 将所有修改过的缓冲区排入写队列,然后返回,不等待实际的写磁盘操作结束;
- fsync 只对由文件描述符 fd 指定的一个文件起作用,并且等待写磁盘操作结束才返回;
- fdatasync 类似于 fsync,它只影响文件的数据部分,但不同步更新文件的属性(文件的修改时间等等);
#include
void sync(void);
int fsync(int fd);
int fdatasync(int fd); 2.7 fcntl()
该系统调用对文件描述符执行对应的操作 cmd,cmd 后面跟着操作需要的参数。
#include
#include
int fcntl(int fd, int cmd, ... /* arg */ ); 该函数功能十分强大,比如 cmd 为 F_DUPFD 时可用实现 dup() 系统调用的功能(fcntl(fd, F_DUPFD, 0)),即复制一个文件描述符。不同的 cmd 可以实现不同的功能,后面跟着需要传入的参数。
fcntl 函数有如下 5 种功能:
- 复制一个已有的文件描述符(cmd=F_DUPFD 或 F_DUPFD_CLOEXEC);
- 获取/设置文件描述符标志(cmd=F_GETFD 或 F_SETFD);
- 获取/设置文件状态标志(cmd=F_GETFL 或 F_SETFL);
- 获取/设置异步 IO 所有权(cmd=F_GETOWN 或 F_SETOWN);
- 获取/设置记录锁(cmd=F_GETLK、F_SETLK 或 F_SETLKW);
2.8 ioctl()
设备相关的内容,可用于控制设备。每个设备驱动程序都可以定义它自己专用的一组 ioctl 命令。
#include
int ioctl(int fd, unsigned long request, ...); /dev/fd/ 目录(ubuntu 下链接至 /proc/self/fd/):虚目录,显示当前进程的文件描述符信息。比如我用 ls 进程查看 /dev/fd 目录的内容,则其中的文件描述符则为 ls 进程的文件描述符信息。

三、文件 IO(系统调用 IO)和标准 IO
3.1 区别
举例:传达室老大爷跑邮局。
多个人来找老大爷寄信(多次标准 IO),老大爷累计到一定数量后再一起寄出(一次系统调用),如果出现加急信件(fflush 强制刷新),那么会立刻送出现有的信件。
标准 IO 有缓冲,而系统调用 IO 无缓冲。这样的好处是能将多次标准 IO 整合到一个系统调用 IO(合并系统调用),节省用户态到内核态的切换时间。所以系统调用 IO 的响应速度快,而标准 IO 的吞吐量大。尽量使用标准 IO:可移植性好、吞吐量大。
注意:标准 IO 和文件 IO 不可混用!(文件位置指针不一致,一个在 FILE 中,一个在 fd 指向的结构体中,由于 FILE 标准 IO 有缓冲区的机制,所以写入的内容不一定写到了对应位置,所以实际 pos 和 FILE 中的 pos 可能不一样)
举例,下面代码打印的内容是什么:
#include
#include
int main()
{
putchar('a');
write(1, "b", 1);
putchar('a');
write(1, "b", 1);
putchar('a');
write(1, "b", 1);
exti(0);
}
运行结果是 bbbaaa,标准 IO putchar 函数由于缓冲区的存在,所以没有立刻将数据写入标准输出,而系统调用 IO write 无缓冲区,立刻写入标准输出, 直到程序结束,刷新缓冲区才把标准 IO 的内容输出:
![]()
使用 strace 命令可以跟踪系统调用的执行,可以看到三个标准 IO putchar 被合并为了一个 write 系统调用:
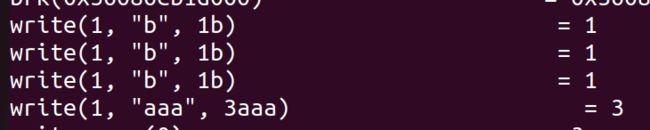
转换:fileno() 能将 FILE 转换成文件描述符 fd;fdopen() 能将文件描述符 fd 转成 FILE。
3.2 性能
其中 user 为用户态执行时间,sys 为内核态执行时间,real 为真实时间,包括调度等待、切换时间。

上述 mycopy 将 buffersize 一直增大会出现的性能拐点?
四、文件共享
面试:删除文件的第 10 行。
可以把文件想象成一个数组,用后面的数据覆盖第 10 行的数据,并且将文件多余的空内容截断。
可以使用多个任务共同操作一个文件,协同完成任务。
一个进程中操作步骤如下,把一个文件使用 open 系统调用打开两次,一个用于读,一个用于写,多进程需要进程间通信:

truncate 系统调用将一个未打开的文件截断到 length 长度,而 ftruncate 将已打开的文件截断。利用这个函数将移动后产生的空洞删除:
#include
#include
int truncate(const char *path, off_t length);
int ftruncate(int fd, off_t length); 实现代码如下:
#include
#include
#include
#include
#include
#include
#define BUFSIZE 1024
char buf[BUFSIZE];
int main(int argc, char *argv[])
{
if(argc < 3){
fprintf(stderr, "Usage: del_line \n");
exit(1);
}
int line = atoi(argv[2]);
char* filepath = argv[1];
int fd1, fd2;
if((fd1 = open(filepath, O_RDONLY)) < 0){
perror("fd1: open");
exit(1);
}
if((fd2 = open(filepath, O_WRONLY)) < 0){
perror("fd2: open");
exit(1);
}
char c;
int i = line - 1;
if(i < 0){
perror("line should not lower than or equal 0");
exit(1);
}
while(i > 0){
if((read(fd1, &c, sizeof(c))) != sizeof(c)){
perror("read");
exit(1);
}
if(c == '\n'){
i--;
}
}
off_t pos1 = lseek(fd1, 0, SEEK_CUR);
while(1){
if((read(fd1, &c, sizeof(c))) != sizeof(c)){
perror("read");
exit(1);
}
if(c == '\n'){
break;
}
}
off_t pos2 = lseek(fd1, 0, SEEK_CUR);
lseek(fd2, pos1, SEEK_SET);
int n;
while((n = read(fd1, &buf, BUFSIZE)) > 0){
if(write(fd2, &buf, n) != n){
perror("write");
exit(1);
}
}
off_t filesize = lseek(fd1, 0, SEEK_END);
ftruncate(fd2, filesize - (pos2 - pos1));
exit(0);
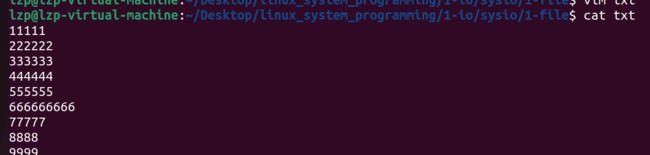
} 假如有一个文件 txt,里面有 9 行内容,现在要删除第六行的内容:
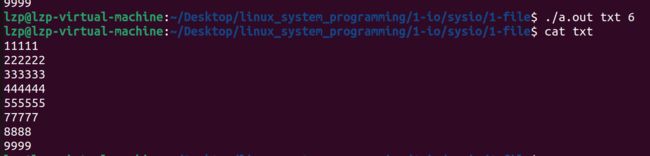
执行程序后可以看到第 6 行内容成功被删除:
4.1 原子操作
原子操作:不可分割的操作。
作用:解决并发环境下的竞争和冲突。