Tensorflow高阶内容(五)- Deep Learning
高阶内容
-
- 5.1 Classification分类学习
- 5.2 什么是过拟合(Overfitting)
- 5.3 Dropout 解决 Overfitting
- 5.4 什么是卷积神经网络CNN(Convolutional Neural Network)
- 5.5 CNN卷积神经网络 1
- 5.6 CNN卷积神经网络 2
- 5.7 CNN卷积神经网络 3
- 5.8 Saver保存读取
- 5.9 什么是循环神经网络 RNN (Recurrent Neural Network)
- 5.10 什么是LSTM循环神经网络
- 5.11 RNN循环神经网络
- 5.12 RNN LSTM 循环神经网络(分类例子)
- 5.13 RNN LSTM(回归例子)
- 5.14 RNN LSTM(回归例子可视化)
- 5.15 什么是自编码(Autoencoder)
- 5.16 自编码Autoencoder(非监督学习)
- 5.17 scope命名方法
- 5.18 什么是批标准化(Batch Normalization)
- 5.19 Batch Normalization 批标准化
- 5.20 Tensorflow 2017更新
- 5.21 用Tensorflow可视化梯度下降
- 5.22 什么是迁移学习 Transfer Learning
- 5.23 迁移学习 Transfer Learning
5.1 Classification分类学习
- MINST 数据
- 搭建网络
- Cross Entropy Loss
- 训练
这次我们会介绍如何使用TensorFlow解决Classification(分类)问题。 之前的视频讲解的是Regression (回归)问题。 分类和回归的区别在于输出变量的类型上。 通俗理解定量输出是回归,或者说是连续变量预测; 定性输出是分类,或者说是离散变量预测。如预测房价这是一个回归任务; 把东西分成几类, 比如猫狗猪牛,就是一个分类任务。
相关代码:
# View more python learning tutorial on my Youtube and Youku channel!!!
# Youtube video tutorial: https://www.youtube.com/channel/UCdyjiB5H8Pu7aDTNVXTTpcg
# Youku video tutorial: http://i.youku.com/pythontutorial
"""
Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly.
"""
from __future__ import print_function
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# number 1 to 10 data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
def add_layer(inputs, in_size, out_size, activation_function=None,):
# add one more layer and return the output of this layer
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1,)
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b,)
return outputs
def compute_accuracy(v_xs, v_ys):
global prediction
y_pre = sess.run(prediction, feed_dict={xs: v_xs})
correct_prediction = tf.equal(tf.argmax(y_pre,1), tf.argmax(v_ys,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys})
return result
# define placeholder for inputs to network
xs = tf.placeholder(tf.float32, [None, 784]) # 28x28
ys = tf.placeholder(tf.float32, [None, 10])
# add output layer
prediction = add_layer(xs, 784, 10, activation_function=tf.nn.softmax)
# the error between prediction and real data
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1])) # loss
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
sess = tf.Session()
# important step
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys})
if i % 50 == 0:
print(compute_accuracy(
mnist.test.images, mnist.test.labels))
(1)MNIST 数据
首先准备数据(MNIST库)
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
MNIST库是手写体数字库,差不多是这样子的:

数据中包含55000张训练图片,每张图片的分辨率是28×28,所以我们的训练网络输入应该是28×28=784个像素数据。
(2)搭建网络
xs = tf.placeholder(tf.float32, [None, 784]) # 28x28
每张图片都表示一个数字,所以我们的输出是数字0到9,共10类。
ys = tf.placeholder(tf.float32, [None, 10])
调用add_layer函数搭建一个最简单的训练网络结构,只有输入层和输出层。
prediction = add_layer(xs, 784, 10, activation_function=tf.nn.softmax)
其中输入数据是784个特征,输出数据是10个特征,激励采用softmax函数,网络结构图是这样子的

(3)Cross Entropy Loss
loss函数(即最优化目标函数)选用交叉熵函数。交叉熵用来衡量预测值和真实值的相似程度,如果完全相同,它们的交叉熵等于零。
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1])) # loss
train方法(最优化算法)采用梯度下降法。
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
sess = tf.Session()
# tf.initialize_all_variables() 这种写法马上就要被废弃
# 替换成下面的写法:
sess.run(tf.global_variables_initializer())
(4)训练
现在开始train,每次只取100张图片,免得数据太多训练太慢。
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys})
每训练50次输出一下预测精度:
if i % 50 == 0:
print(compute_accuracy(
mnist.test.images, mnist.test.labels))
输出结果如下:

有没有很惊讶啊,如此简单的神经网络结构竟然可以达到这样的图像识别精度,其实稍作改动后,识别的精度将大幅提高。 请关注后续课程哦。
5.2 什么是过拟合(Overfitting)
- 过于自负
- 回归分类的过拟合
- 解决方法
(1)过于自负

在细说之前, 我们先用实际生活中的一个例子来比喻一下过拟合现象. 说白了, 就是机器学习模型于自信. 已经到了自负的阶段了. 那自负的坏处, 大家也知道, 就是在自己的小圈子里表现非凡, 不过在现实的大圈子里却往往处处碰壁. 所以在这个简介里, 我们把自负和过拟合画上等号.
(2)回归分类的过拟合

机器学习模型的自负又表现在哪些方面呢. 这里是一些数据. 如果要你画一条线来描述这些数据, 大多数人都会这么画. 对, 这条线也是我们希望机器也能学出来的一条用来总结这些数据的线. 这时蓝线与数据的总误差可能是10. 可是有时候, 机器过于纠结这误差值, 他想把误差减到更小, 来完成他对这一批数据的学习使命. 所以, 他学到的可能会变成这样 . 它几乎经过了每一个数据点, 这样, 误差值会更小 . 可是误差越小就真的好吗? 看来我们的模型还是太天真了. 当我拿这个模型运用在现实中的时候, 他的自负就体现出来. 小二, 来一打现实数据 . 这时, 之前误差大的蓝线误差基本保持不变 .误差小的 红线误差值突然飙高 , 自负的红线再也骄傲不起来, 因为他不能成功的表达除了训练数据以外的其他数据. 这就叫做过拟合. Overfitting。

那么在分类问题当中. 过拟合的分割线可能是这样, 小二, 再上一打数据 . 我们明显看出, 有两个黄色的数据并没有被很好的分隔开来. 这也是过拟合在作怪.好了, 既然我们时不时会遇到过拟合问题, 那解决的方法有那些呢.
(3)解决方法

方法一: 增加数据量, 大部分过拟合产生的原因是因为数据量太少了. 如果我们有成千上万的数据, 红线也会慢慢被拉直, 变得没那么扭曲 . 方法二:

运用正规化. L1, l2 regularization等等, 这些方法适用于大多数的机器学习, 包括神经网络. 他们的做法大同小异, 我们简化机器学习的关键公式为 y=Wx . W为机器需要学习到的各种参数. 在过拟合中, W 的值往往变化得特别大或特别小. 为了不让W变化太大, 我们在计算误差上做些手脚. 原始的 cost 误差是这样计算, cost = 预测值-真实值的平方. 如果 W 变得太大, 我们就让 cost 也跟着变大, 变成一种惩罚机制. 所以我们把 W 自己考虑进来. 这里 abs 是绝对值. 这一种形式的 正规化, 叫做 l1 正规化. L2 正规化和 l1 类似, 只是绝对值换成了平方. 其他的l3, l4 也都是换成了立方和4次方等等. 形式类似. 用这些方法,我们就能保证让学出来的线条不会过于扭曲.

还有一种专门用在神经网络的正规化的方法, 叫作 dropout. 在训练的时候, 我们随机忽略掉一些神经元和神经联结 , 是这个神经网络变得”不完整”. 用一个不完整的神经网络训练一次.
到第二次再随机忽略另一些, 变成另一个不完整的神经网络. 有了这些随机 drop 掉的规则, 我们可以想象其实每次训练的时候, 我们都让每一次预测结果都不会依赖于其中某部分特定的神经元. 像l1, l2正规化一样, 过度依赖的 W , 也就是训练参数的数值会很大, l1, l2会惩罚这些大的 参数. Dropout 的做法是从根本上让神经网络没机会过度依赖.
5.3 Dropout 解决 Overfitting
- 要点
- 建立Dropout 层
- 训练
- 可视化结果
- 可能会遇到的问题
相关代码:
# View more python learning tutorial on my Youtube and Youku channel!!!
# Youtube video tutorial: https://www.youtube.com/channel/UCdyjiB5H8Pu7aDTNVXTTpcg
# Youku video tutorial: http://i.youku.com/pythontutorial
"""
Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly.
"""
from __future__ import print_function
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
# load data
digits = load_digits()
X = digits.data
y = digits.target
y = LabelBinarizer().fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3)
def add_layer(inputs, in_size, out_size, layer_name, activation_function=None, ):
# add one more layer and return the output of this layer
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, )
Wx_plus_b = tf.matmul(inputs, Weights) + biases
# here to dropout
Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob)
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b, )
tf.summary.histogram(layer_name + '/outputs', outputs)
return outputs
# define placeholder for inputs to network
keep_prob = tf.placeholder(tf.float32)
xs = tf.placeholder(tf.float32, [None, 64]) # 8x8
ys = tf.placeholder(tf.float32, [None, 10])
# add output layer
l1 = add_layer(xs, 64, 50, 'l1', activation_function=tf.nn.tanh)
prediction = add_layer(l1, 50, 10, 'l2', activation_function=tf.nn.softmax)
# the loss between prediction and real data
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1])) # loss
tf.summary.scalar('loss', cross_entropy)
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
sess = tf.Session()
merged = tf.summary.merge_all()
# summary writer goes in here
train_writer = tf.summary.FileWriter("logs/train", sess.graph)
test_writer = tf.summary.FileWriter("logs/test", sess.graph)
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
for i in range(500):
# here to determine the keeping probability
sess.run(train_step, feed_dict={xs: X_train, ys: y_train, keep_prob: 0.5})
if i % 50 == 0:
# record loss
train_result = sess.run(merged, feed_dict={xs: X_train, ys: y_train, keep_prob: 1})
test_result = sess.run(merged, feed_dict={xs: X_test, ys: y_test, keep_prob: 1})
train_writer.add_summary(train_result, i)
test_writer.add_summary(test_result, i)
(1)要点
Overfitting 也被称为过度学习,过度拟合。 它是机器学习中常见的问题。 举个Classification(分类)的例子。

图中黑色曲线是正常模型,绿色曲线就是overfitting模型。尽管绿色曲线很精确的区分了所有的训练数据,但是并没有描述数据的整体特征,对新测试数据的适应性较差。
举个Regression (回归)的例子:

第三条曲线存在overfitting问题,尽管它经过了所有的训练点,但是不能很好的反应数据的趋势,预测能力严重不足。 TensorFlow提供了强大的dropout方法来解决overfitting问题。
(2)建立dropout层
本次内容需要使用一下 sklearn 数据库当中的数据, 没有安装 sklearn 的同学可以参考一下这个教程 安装一下. 然后 import 以下模块.
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import LabelBinarizer
keep_prob = tf.placeholder(tf.float32)
...
...
Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob)
这里的keep_prob是保留概率,即我们要保留的结果所占比例,它作为一个placeholder,在run时传入, 当keep_prob=1的时候,相当于100%保留,也就是dropout没有起作用。 下面我们分析一下程序结构,首先准备数据,
digits = load_digits()
X = digits.data
y = digits.target
y = LabelBinarizer().fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3)
其中X_train是训练数据, X_test是测试数据。 然后添加隐含层和输出层,
# add output layer
l1 = add_layer(xs, 64, 50, 'l1', activation_function=tf.nn.tanh)
prediction = add_layer(l1, 50, 10, 'l2', activation_function=tf.nn.softmax)
loss函数(即最优化目标函数)选用交叉熵函数。交叉熵用来衡量预测值和真实值的相似程度,如果完全相同,交叉熵就等于零。
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1])) # loss
train方法(最优化算法)采用梯度下降法。
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
(3)训练
最后开始train,总共训练500次。
sess.run(train_step, feed_dict={xs: X_train, ys: y_train, keep_prob: 0.5})
#sess.run(train_step, feed_dict={xs: X_train, ys: y_train, keep_prob: 1})
(4)可视化结果
训练中keep_prob=1时,就可以暴露出overfitting问题。keep_prob=0.5时,dropout就发挥了作用。 我们可以两种参数分别运行程序,对比一下结果。
当keep_prob=1时,模型对训练数据的适应性优于测试数据,存在overfitting,输出如下: 红线是 train 的误差, 蓝线是 test 的误差.
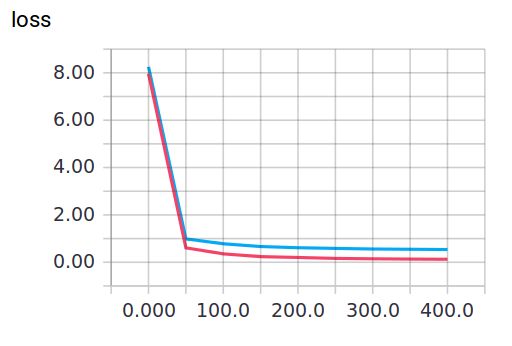
当keep_prob=0.5时效果好了很多,输出如下:

程序中用到了Tensorboard输出结果。
(5)可能会遇到的问题
由于评论区中讨论了很多这份代码的问题, 我在此说明一下. 因为 Tensorflow 升级改版了, 执行的代码可能会遇到一些问题。
5.4 什么是卷积神经网络CNN(Convolutional Neural Network)
- 卷积和神经网络
- 池化(Pooling)
- 流行的CNN结构

卷积神经网络是近些年逐步兴起的一种人工神经网络结构, 因为利用卷积神经网络在图像和语音识别方面能够给出更优预测结果, 这一种技术也被广泛的传播和应用. 卷积神经网络最常被应用的方面是计算机的图像识别, 不过因为不断地创新, 它也被应用在视频分析, 自然语言处理, 药物发现, 等等. 近期最火的 Alpha Go, 让计算机看懂围棋, 同样也是有运用到这门技术.
(1)卷积和神经网络

我们来具体说说卷积神经网络是如何运作的吧, 举一个识别图片的例子, 我们知道神经网络是由一连串的神经层组成,每一层神经层里面存在有很多的神经元. 这些神经元就是神经网络识别事物的关键. 每一种神经网络都会有输入输出值, 当输入值是图片的时候, 实际上输入神经网络的并不是那些色彩缤纷的图案,而是一堆堆的数字. 就比如说这个. 当神经网络需要处理这么多输入信息的时候, 也就是卷积神经网络就可以发挥它的优势的时候了. 那什么是卷积神经网络呢?

我们先把卷积神经网络这个词拆开来看. “卷积” 和 “神经网络”. 卷积也就是说神经网络不再是对每个像素的输入信息做处理了,而是图片上每一小块像素区域进行处理, 这种做法加强了图片信息的连续性. 使得神经网络能看到图形, 而非一个点. 这种做法同时也加深了神经网络对图片的理解. 具体来说, 卷积神经网络有一个批量过滤器, 持续不断的在图片上滚动收集图片里的信息,每一次收集的时候都只是收集一小块像素区域, 然后把收集来的信息进行整理, 这时候整理出来的信息有了一些实际上的呈现, 比如这时的神经网络能看到一些边缘的图片信息, 然后在以同样的步骤, 用类似的批量过滤器扫过产生的这些边缘信息, 神经网络从这些边缘信息里面总结出更高层的信息结构,比如说总结的边缘能够画出眼睛,鼻子等等. 再经过一次过滤, 脸部的信息也从这些眼睛鼻子的信息中被总结出来. 最后我们再把这些信息套入几层普通的全连接神经层进行分类, 这样就能得到输入的图片能被分为哪一类的结果了.

我们截取一段 google 介绍卷积神经网络的视频, 具体说说图片是如何被卷积的. 下面是一张猫的图片, 图片有长, 宽, 高 三个参数. 对! 图片是有高度的! 这里的高指的是计算机用于产生颜色使用的信息. 如果是黑白照片的话, 高的单位就只有1, 如果是彩色照片, 就可能有红绿蓝三种颜色的信息, 这时的高度为3. 我们以彩色照片为例子. 过滤器就是影像中不断移动的东西, 他不断在图片收集小批小批的像素块, 收集完所有信息后, 输出的值, 我们可以理解成是一个高度更高,长和宽更小的”图片”. 这个图片里就能包含一些边缘信息. 然后以同样的步骤再进行多次卷积, 将图片的长宽再压缩, 高度再增加, 就有了对输入图片更深的理解. 将压缩,增高的信息嵌套在普通的分类神经层上,我们就能对这种图片进行分类了.
(2)池化(Pooling)
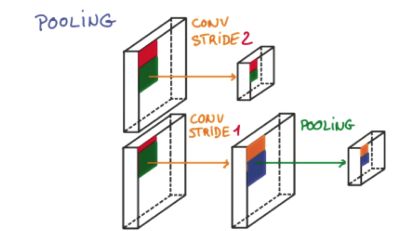
研究发现, 在每一次卷积的时候, 神经层可能会无意地丢失一些信息. 这时, 池化 (pooling) 就可以很好地解决这一问题. 而且池化是一个筛选过滤的过程, 能将 layer 中有用的信息筛选出来, 给下一个层分析. 同时也减轻了神经网络的计算负担 (具体细节参考). 也就是说在卷集的时候, 我们不压缩长宽, 尽量地保留更多信息, 压缩的工作就交给池化了,这样的一项附加工作能够很有效的提高准确性. 有了这些技术,我们就可以搭建一个属于我们自己的卷积神经网络啦.
(3)流行的CNN结构

比较流行的一种搭建结构是这样, 从下到上的顺序, 首先是输入的图片(image), 经过一层卷积层 (convolution), 然后在用池化(pooling)方式处理卷积的信息, 这里使用的是 max pooling 的方式. 然后在经过一次同样的处理, 把得到的第二次处理的信息传入两层全连接的神经层 (fully connected),这也是一般的两层神经网络层,最后在接上一个分类器(classifier)进行分类预测. 这仅仅是对卷积神经网络在图片处理上一次简单的介绍。
5.5 CNN卷积神经网络 1
- CNN简短介绍
(1)卷CNN简短介绍
我们的一般的神经网络在理解图片信息的时候还是有不足之处, 这时卷积神经网络就是计算机处理图片的助推器. Convolutional Neural Networks (CNN) 是神经网络处理图片信息的一大利器. 有了它, 我们给计算机看图片,计算机理解起来就更准确. 强烈推荐观看我制作的短小精炼的 机器学习-简介系列 什么是 CNN
计算机视觉处理的飞跃提升,在图像和语音识别方面表现出了强大的优势,学习卷积神经网络之前,我们已经假设你对神经网络已经有了初步的了解,如果没有的话,可以去看看tensorflow第一篇视频教程哦~
卷积神经网络包含输入层、隐藏层和输出层,隐藏层又包含卷积层和pooling层,图像输入到卷积神经网络后通过卷积来不断的提取特征,每提取一个特征就会增加一个feature map,所以会看到视频教程中的立方体不断的增加厚度,那么为什么厚度增加了但是却越来越瘦了呢,哈哈这就是pooling层的作用喽,pooling层也就是下采样,通常采用的是最大值pooling和平均值pooling,因为参数太多喽,所以通过pooling来稀疏参数,使我们的网络不至于太复杂。
好啦,既然你对卷积神经网络已经有了大概的了解,下次课我们将通过代码来实现一个基于MNIST数据集的简单卷积神经网络。
5.6 CNN卷积神经网络 2
- 定义卷积层的 wight bias
- 定义Pooling
这一次我们会说道 CNN 代码中怎么定义 Convolutional 的层和怎样进行 pooling.
基于上一次卷积神经网络的介绍,我们在代码中实现一个基于MNIST数据集的例子
相关代码:
# View more python tutorial on my Youtube and Youku channel!!!
# Youtube video tutorial: https://www.youtube.com/channel/UCdyjiB5H8Pu7aDTNVXTTpcg
# Youku video tutorial: http://i.youku.com/pythontutorial
"""
Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly.
"""
from __future__ import print_function
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# number 1 to 10 data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
def compute_accuracy(v_xs, v_ys):
global prediction
y_pre = sess.run(prediction, feed_dict={xs: v_xs, keep_prob: 1})
correct_prediction = tf.equal(tf.argmax(y_pre,1), tf.argmax(v_ys,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys, keep_prob: 1})
return result
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
# stride [1, x_movement, y_movement, 1]
# Must have strides[0] = strides[3] = 1
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
# stride [1, x_movement, y_movement, 1]
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
# define placeholder for inputs to network
xs = tf.placeholder(tf.float32, [None, 784]) # 28x28
ys = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32)
## conv1 layer ##
## conv2 layer ##
## func1 layer ##
## func2 layer ##
# the error between prediction and real data
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1])) # loss
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
sess = tf.Session()
# important step
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys, keep_prob: 0.5})
if i % 50 == 0:
print(compute_accuracy(
mnist.test.images[:1000], mnist.test.labels[:1000]))
(1)定义卷积层的 wight bias
首先我们导入:
import tensorflow as tf
采用的数据集依然是tensorflow里面的mnist数据集,我们需要先导入它,
python from tensorflow.examples.tutorials.mnist import input_data
本次课程代码用到的数据集就是来自于它,
mnist=input_data.read_data_sets('MNIST_data',one_hot=true)
接着呢,我们定义Weight变量,输入shape,返回变量的参数。其中我们使用tf.truncted_normal产生随机变量来进行初始化:
def weight_variable(shape):
inital=tf.truncted_normal(shape,stddev=0.1)
return tf.Variable(initial)
同样的定义biase变量,输入shape ,返回变量的一些参数。其中我们使用tf.constant常量函数来进行初始化:
def bias_variable(shape):
initial=tf.constant(0.1,shape=shape)
return tf.Variable(initial)
定义卷积,tf.nn.conv2d函数是tensoflow里面的二维的卷积函数,x是图片的所有参数,W是此卷积层的权重,然后定义步长strides=[1,1,1,1]值,strides[0]和strides[3]的两个1是默认值,中间两个1代表padding时在x方向运动一步,y方向运动一步,padding采用的方式是SAME。
def conv2d(x,W):
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')
(2)定义Pooling
接着定义池化pooling,为了得到更多的图片信息,padding时我们选的是一次一步,也就是strides[1]=strides[2]=1,这样得到的图片尺寸没有变化,而我们希望压缩一下图片也就是参数能少一些从而减小系统的复杂度,因此我们采用pooling来稀疏化参数,也就是卷积神经网络中所谓的下采样层。pooling有两种,一种是最大值池化,一种是平均值池化,本例采用的是最大值池化tf.max_pool()。池化的核函数大小为2x2,因此ksize=[1,2,2,1],步长为2,因此strides=[1,2,2,1]:
def max_poo_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1])
5.7 CNN卷积神经网络 3
- 图片处理
- 建立卷积层
- 建立全连接层
- 选优化方法
这一次我们一层层的加上了不同的 layer. 分别是:
convolutional layer1 + max pooling;
convolutional layer2 + max pooling;
fully connected layer1 + dropout;
fully connected layer2 to prediction.
相关代码:
# View more python tutorial on my Youtube and Youku channel!!!
# Youtube video tutorial: https://www.youtube.com/channel/UCdyjiB5H8Pu7aDTNVXTTpcg
# Youku video tutorial: http://i.youku.com/pythontutorial
"""
Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly.
"""
from __future__ import print_function
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# number 1 to 10 data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
def compute_accuracy(v_xs, v_ys):
global prediction
y_pre = sess.run(prediction, feed_dict={xs: v_xs, keep_prob: 1})
correct_prediction = tf.equal(tf.argmax(y_pre,1), tf.argmax(v_ys,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys, keep_prob: 1})
return result
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
# stride [1, x_movement, y_movement, 1]
# Must have strides[0] = strides[3] = 1
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
# stride [1, x_movement, y_movement, 1]
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
# define placeholder for inputs to network
xs = tf.placeholder(tf.float32, [None, 784])/255. # 28x28
ys = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32)
x_image = tf.reshape(xs, [-1, 28, 28, 1])
# print(x_image.shape) # [n_samples, 28,28,1]
## conv1 layer ##
W_conv1 = weight_variable([5,5, 1,32]) # patch 5x5, in size 1, out size 32
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # output size 28x28x32
h_pool1 = max_pool_2x2(h_conv1) # output size 14x14x32
## conv2 layer ##
W_conv2 = weight_variable([5,5, 32, 64]) # patch 5x5, in size 32, out size 64
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) # output size 14x14x64
h_pool2 = max_pool_2x2(h_conv2) # output size 7x7x64
## fc1 layer ##
W_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
# [n_samples, 7, 7, 64] ->> [n_samples, 7*7*64]
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
## fc2 layer ##
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
prediction = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
# the error between prediction and real data
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1])) # loss
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
sess = tf.Session()
# important step
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys, keep_prob: 0.5})
if i % 50 == 0:
print(compute_accuracy(
mnist.test.images[:1000], mnist.test.labels[:1000]))
(1)图片处理
首先呢,我们定义一下输入的placeholder,
xs=tf.placeholder(tf.float32,[None,784])
ys=tf.placeholder(tf.float32,[None,10])
我们还定义了dropout的placeholder,它是解决过拟合的有效手段
keep_prob=tf.placeholder(tf.float32)
接着呢,我们需要处理我们的xs,把xs的形状变成[-1,28,28,1],-1代表先不考虑输入的图片例子多少这个维度,后面的1是channel的数量,因为我们输入的图片是黑白的,因此channel是1,例如如果是RGB图像,那么channel就是3。
x_image=tf.reshape(xs,[-1,28,28,1])
(2)建立卷积层
接着我们定义第一层卷积,先定义本层的Weight,本层我们的卷积核patch的大小是5x5,因为黑白图片channel是1所以输入是1,输出是32个featuremap,
W_conv1=weight_variable([5,5,1,32])
接着定义bias,它的大小是32个长度,因此我们传入它的shape为[32]
b_conv1=bias_variable([32])
定义好了Weight和bias,我们就可以定义卷积神经网络的第一个卷积层h_conv1=conv2d(x_image,W_conv1)+b_conv1,同时我们对h_conv1进行非线性处理,也就是激活函数来处理喽,这里我们用的是tf.nn.relu(修正线性单元)来处理,要注意的是,因为采用了SAME的padding方式,输出图片的大小没有变化依然是28x28,只是厚度变厚了,因此现在的输出大小就变成了28x28x32
h_conv1=tf.nn.relu(conv2d(x_image,W_conv1)+b_conv1)
最后我们再进行pooling的处理就ok啦,经过pooling的处理,输出大小就变为了14x14x32
h_pool=max_pool_2x2(h_conv1)
接着呢,同样的形式我们定义第二层卷积,本层我们的输入就是上一层的输出,本层我们的卷积核patch的大小是5x5,有32个featuremap所以输入就是32,输出呢我们定为64
W_conv2=weight_variable([5,5,32,64])
b_conv2=bias_variable([64])
接着我们就可以定义卷积神经网络的第二个卷积层,这时的输出的大小就是14x14x64
h_conv2=tf.nn.relu(conv2d(h_pool1,W_conv2)+b_conv2)
最后也是一个pooling处理,输出大小为7x7x64
h_pool2=max_pool_2x2(h_conv2)
(3)建立全连接层
好的,接下来我们定义我们的 fully connected layer,
进入全连接层时, 我们通过tf.reshape()将h_pool2的输出值从一个三维的变为一维的数据, -1表示先不考虑输入图片例子维度, 将上一个输出结果展平.
#[n_samples,7,7,64]->>[n_samples,7*7*64]
h_pool2_flat=tf.reshape(h_pool2,[-1,7*7*64])
此时weight_variable的shape输入就是第二个卷积层展平了的输出大小: 7x7x64, 后面的输出size我们继续扩大,定为1024
W_fc1=weight_variable([7*7*64,1024])
b_fc1=bias_variable([1024])
然后将展平后的h_pool2_flat与本层的W_fc1相乘(注意这个时候不是卷积了)
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1)
如果我们考虑过拟合问题,可以加一个dropout的处理
h_fc1_drop=tf.nn.dropout(h_fc1,keep_drop)
接下来我们就可以进行最后一层的构建了,好激动啊, 输入是1024,最后的输出是10个 (因为mnist数据集就是[0-9]十个类),prediction就是我们最后的预测值
W_fc2=weight_variable([1024,10]) b_fc2=bias_variable([10])
然后呢我们用softmax分类器(多分类,输出是各个类的概率),对我们的输出进行分类
prediction=tf.nn.softmax(tf.matmul(h_fc1_dropt,W_fc2),b_fc2)
(4)选优化方法
接着呢我们利用交叉熵损失函数来定义我们的cost function,
cross_entropy=tf.reduce_mean(
-tf.reduce_sum(ys*tf.log(prediction),
reduction_indices=[1]))
我们用tf.train.AdamOptimizer()作为我们的优化器进行优化,使我们的cross_entropy最小
train_step=tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
接着呢就是和之前视频讲的一样喽 定义Session
sess=tf.Session()
初始化变量
# tf.initialize_all_variables() 这种写法马上就要被废弃
# 替换成下面的写法:
sess.run(tf.global_variables_initializer())
好啦接着就是训练数据啦,我们假定训练1000步,每50步输出一下准确率, 注意sess.run()时记得要用feed_dict给我们的众多 placeholder 喂数据哦.
5.8 Saver保存读取
- 保存
- 提取
我们搭建好了一个神经网络, 训练好了, 肯定也想保存起来, 用于再次加载. 那今天我们就来说说怎样用 Tensorflow 中的 saver 保存和加载吧.
相关代码:
# View more python tutorials on my Youtube and Youku channel!!!
# Youtube video tutorial: https://www.youtube.com/channel/UCdyjiB5H8Pu7aDTNVXTTpcg
# Youku video tutorial: http://i.youku.com/pythontutorial
"""
Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly.
"""
from __future__ import print_function
import tensorflow as tf
import numpy as np
# Save to file
# remember to define the same dtype and shape when restore
# W = tf.Variable([[1,2,3],[3,4,5]], dtype=tf.float32, name='weights')
# b = tf.Variable([[1,2,3]], dtype=tf.float32, name='biases')
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
# if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
# init = tf.initialize_all_variables()
# else:
# init = tf.global_variables_initializer()
#
# saver = tf.train.Saver()
#
# with tf.Session() as sess:
# sess.run(init)
# save_path = saver.save(sess, "my_net/save_net.ckpt")
# print("Save to path: ", save_path)
################################################
# restore variables
# redefine the same shape and same type for your variables
W = tf.Variable(np.arange(6).reshape((2, 3)), dtype=tf.float32, name="weights")
b = tf.Variable(np.arange(3).reshape((1, 3)), dtype=tf.float32, name="biases")
# not need init step
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, "my_net/save_net.ckpt")
print("weights:", sess.run(W))
print("biases:", sess.run(b))
(1)保存
import所需的模块, 然后建立神经网络当中的 W 和 b, 并初始化变量.
import tensorflow as tf
import numpy as np
<h2 class="tut-h2-pad" id="Save to file">Save to file
<a href="https://mofanpy.com/tutorials/machine-learning/tensorflow/save#Save to file" class="headerlink" title="Permalink to this headline">¶</a>
</h2>
# remember to define the same dtype and shape when restore
W = tf.Variable([[1,2,3],[3,4,5]], dtype=tf.float32, name='weights')
b = tf.Variable([[1,2,3]], dtype=tf.float32, name='biases')
# init= tf.initialize_all_variables() # tf 马上就要废弃这种写法
# 替换成下面的写法:
init = tf.global_variables_initializer()
保存时, 首先要建立一个 tf.train.Saver() 用来保存, 提取变量. 再创建一个名为my_net的文件夹, 用这个 saver 来保存变量到这个目录 “my_net/save_net.ckpt”.
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
save_path = saver.save(sess, "my_net/save_net.ckpt")
print("Save to path: ", save_path)
"""
Save to path: my_net/save_net.ckpt
"""
(2)提取
提取时, 先建立零时的W 和 b容器. 找到文件目录, 并用saver.restore()我们放在这个目录的变量.
# 先建立 W, b 的容器
W = tf.Variable(np.arange(6).reshape((2, 3)), dtype=tf.float32, name="weights")
b = tf.Variable(np.arange(3).reshape((1, 3)), dtype=tf.float32, name="biases")
# 这里不需要初始化步骤 init= tf.initialize_all_variables()
saver = tf.train.Saver()
with tf.Session() as sess:
# 提取变量
saver.restore(sess, "my_net/save_net.ckpt")
print("weights:", sess.run(W))
print("biases:", sess.run(b))
"""
weights: [[ 1. 2. 3.]
[ 3. 4. 5.]]
biases: [[ 1. 2. 3.]]
5.9 什么是循环神经网络 RNN (Recurrent Neural Network)
- RNN用途
- 序列数据
- 处理序列数据的神经网络
- RNN的应用
今天我们会来聊聊在语言分析, 序列化数据中穿梭自如的循环神经网络 RNN. RNN 是用来干什么的 ? 它和普通的神经网络有什么不同 ? 我会将会一一探讨.
(1)RNN用途

现在请你看着这个名字. 不出意外, 你应该可以脱口而出. 因为你很可能就用了他们家的一款产品 . 那么现在, 请抛开这个产品, 只想着斯蒂芬乔布斯这个名字 , 请你再把他逆序念出来. 斯布乔(*#&, 有点难吧. 这就说明, 对于预测, 顺序排列是多么重要. 我们可以预测下一个按照一定顺序排列的字, 但是打乱顺序, 我们就没办法分析自己到底在说什么了.
(2)序列数据

我们想象现在有一组序列数据 data 0,1,2,3. 在当预测 result0 的时候,我们基于的是 data0, 同样在预测其他数据的时候, 我们也都只单单基于单个的数据. 每次使用的神经网络都是同一个 NN. 不过这些数据是有关联 顺序的 , 就像在厨房做菜, 酱料 A要比酱料 B 早放, 不然就串味了. 所以普通的神经网络结构并不能让 NN 了解这些数据之间的关联.
(3)处理序列数据的神经网络
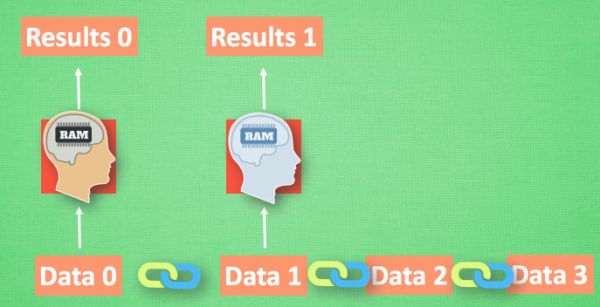
那我们如何让数据间的关联也被 NN 加以分析呢? 想想我们人类是怎么分析各种事物的关联吧, 最基本的方式,就是记住之前发生的事情. 那我们让神经网络也具备这种记住之前发生的事的能力. 再分析 Data0 的时候, 我们把分析结果存入记忆. 然后当分析 data1的时候, NN会产生新的记忆, 但是新记忆和老记忆是没有联系的. 我们就简单的把老记忆调用过来, 一起分析. 如果继续分析更多的有序数据 , RNN就会把之前的记忆都累积起来, 一起分析.

我们再重复一遍刚才的流程, 不过这次是以加入一些数学方面的东西. 每次 RNN 运算完之后都会产生一个对于当前状态的描述 , state. 我们用简写 S( t) 代替, 然后这个 RNN开始分析 x(t+1) , 他会根据 x(t+1)产生s(t+1), 不过此时 y(t+1) 是由 s(t) 和 s(t+1) 共同创造的. 所以我们通常看到的 RNN 也可以表达成这种样子.
(4)RNN的应用
RNN 的形式不单单这有这样一种, 他的结构形式很自由. 如果用于分类问题, 比如说一个人说了一句话, 这句话带的感情色彩是积极的还是消极的. 那我们就可以用只有最后一个时间点输出判断结果的RNN.
又或者这是图片描述 RNN, 我们只需要一个 X 来代替输入的图片, 然后生成对图片描述的一段话.
或者是语言翻译的 RNN, 给出一段英文, 然后再翻译成中文.
有了这些不同形式的 RNN, RNN 就变得强大了. 有很多有趣的 RNN 应用. 比如之前提到的, 让 RNN 描述照片. 让 RNN 写学术论文, 让 RNN 写程序脚本, 让 RNN 作曲. 我们一般人甚至都不能分辨这到底是不是机器写出来的.
5.10 什么是LSTM循环神经网络
- RNN的弊端
- LSTM
今天我们会来聊聊在普通RNN的弊端和为了解决这个弊端而提出的 LSTM 技术. LSTM 是 long-short term memory 的简称, 中文叫做 长短期记忆. 是当下最流行的 RNN 形式之一.
(1)RNN的弊端

之前我们说过, RNN 是在有顺序的数据上进行学习的. 为了记住这些数据, RNN 会像人一样产生对先前发生事件的记忆. 不过一般形式的 RNN 就像一个老爷爷, 有时候比较健忘. 为什么会这样呢?

想像现在有这样一个 RNN, 他的输入值是一句话: ‘我今天要做红烧排骨, 首先要准备排骨, 然后…., 最后美味的一道菜就出锅了’, shua ~ 说着说着就流口水了. 现在请 RNN 来分析, 我今天做的到底是什么菜呢. RNN可能会给出“辣子鸡”这个答案. 由于判断失误, RNN就要开始学习 这个长序列 X 和 ‘红烧排骨’ 的关系 , 而RNN需要的关键信息 ”红烧排骨”却出现在句子开头,


再来看看 RNN是怎样学习的吧. 红烧排骨这个信息原的记忆要进过长途跋涉才能抵达最后一个时间点. 然后我们得到误差, 而且在 反向传递 得到的误差的时候, 他在每一步都会 乘以一个自己的参数 W. 如果这个 W 是一个小于1 的数, 比如0.9. 这个0.9 不断乘以误差, 误差传到初始时间点也会是一个接近于零的数, 所以对于初始时刻, 误差相当于就消失了. 我们把这个问题叫做梯度消失或者梯度弥散 Gradient vanishing. 反之如果 W 是一个大于1 的数, 比如1.1 不断累乘, 则到最后变成了无穷大的数, RNN被这无穷大的数撑死了, 这种情况我们叫做剃度爆炸, Gradient exploding. 这就是普通 RNN 没有办法回忆起久远记忆的原因.
(2)LSTM

LSTM 就是为了解决这个问题而诞生的. LSTM 和普通 RNN 相比, 多出了三个控制器. (输入控制, 输出控制, 忘记控制). 现在, LSTM RNN 内部的情况是这样.
他多了一个 控制全局的记忆, 我们用粗线代替. 为了方便理解, 我们把粗线想象成电影或游戏当中的 主线剧情. 而原本的 RNN 体系就是 分线剧情. 三个控制器都是在原始的 RNN 体系上, 我们先看 输入方面 , 如果此时的分线剧情对于剧终结果十分重要, 输入控制就会将这个分线剧情按重要程度 写入主线剧情 进行分析. 再看 忘记方面, 如果此时的分线剧情更改了我们对之前剧情的想法, 那么忘记控制就会将之前的某些主线剧情忘记, 按比例替换成现在的新剧情. 所以 主线剧情的更新就取决于输入 和忘记 控制. 最后的输出方面, 输出控制会基于目前的主线剧情和分线剧情判断要输出的到底是什么.基于这些控制机制, LSTM 就像延缓记忆衰退的良药, 可以带来更好的结果.
5.11 RNN循环神经网络
- 简介系列
(1)简介系列
RNN recurrent neural networks 在序列化的预测当中是很有优势的. 我们先看看 RNN 是怎么工作的.
5.12 RNN LSTM 循环神经网络(分类例子)
- 设置RNN参数
- 定义RNN的主体结构
- 训练RNN
相关代码:
# View more python learning tutorial on my Youtube and Youku channel!!!
# Youtube video tutorial: https://www.youtube.com/channel/UCdyjiB5H8Pu7aDTNVXTTpcg
# Youku video tutorial: http://i.youku.com/pythontutorial
"""
This code is a modified version of the code from this link:
https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/recurrent_network.py
His code is a very good one for RNN beginners. Feel free to check it out.
"""
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# set random seed for comparing the two result calculations
tf.set_random_seed(1)
# this is data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
# hyperparameters
lr = 0.001
training_iters = 100000
batch_size = 128
n_inputs = 28 # MNIST data input (img shape: 28*28)
n_steps = 28 # time steps
n_hidden_units = 128 # neurons in hidden layer
n_classes = 10 # MNIST classes (0-9 digits)
# tf Graph input
x = tf.placeholder(tf.float32, [None, n_steps, n_inputs])
y = tf.placeholder(tf.float32, [None, n_classes])
# Define weights
weights = {
# (28, 128)
'in': tf.Variable(tf.random_normal([n_inputs, n_hidden_units])),
# (128, 10)
'out': tf.Variable(tf.random_normal([n_hidden_units, n_classes]))
}
biases = {
# (128, )
'in': tf.Variable(tf.constant(0.1, shape=[n_hidden_units, ])),
# (10, )
'out': tf.Variable(tf.constant(0.1, shape=[n_classes, ]))
}
def RNN(X, weights, biases):
# hidden layer for input to cell
########################################
# transpose the inputs shape from
# X ==> (128 batch * 28 steps, 28 inputs)
X = tf.reshape(X, [-1, n_inputs])
# into hidden
# X_in = (128 batch * 28 steps, 128 hidden)
X_in = tf.matmul(X, weights['in']) + biases['in']
# X_in ==> (128 batch, 28 steps, 128 hidden)
X_in = tf.reshape(X_in, [-1, n_steps, n_hidden_units])
# cell
##########################################
# basic LSTM Cell.
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
cell = tf.nn.rnn_cell.BasicLSTMCell(n_hidden_units, forget_bias=1.0, state_is_tuple=True)
else:
cell = tf.contrib.rnn.BasicLSTMCell(n_hidden_units)
# lstm cell is divided into two parts (c_state, h_state)
init_state = cell.zero_state(batch_size, dtype=tf.float32)
# You have 2 options for following step.
# 1: tf.nn.rnn(cell, inputs);
# 2: tf.nn.dynamic_rnn(cell, inputs).
# If use option 1, you have to modified the shape of X_in, go and check out this:
# https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/recurrent_network.py
# In here, we go for option 2.
# dynamic_rnn receive Tensor (batch, steps, inputs) or (steps, batch, inputs) as X_in.
# Make sure the time_major is changed accordingly.
outputs, final_state = tf.nn.dynamic_rnn(cell, X_in, initial_state=init_state, time_major=False)
# hidden layer for output as the final results
#############################################
# results = tf.matmul(final_state[1], weights['out']) + biases['out']
# # or
# unpack to list [(batch, outputs)..] * steps
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
outputs = tf.unpack(tf.transpose(outputs, [1, 0, 2])) # states is the last outputs
else:
outputs = tf.unstack(tf.transpose(outputs, [1,0,2]))
results = tf.matmul(outputs[-1], weights['out']) + biases['out'] # shape = (128, 10)
return results
pred = RNN(x, weights, biases)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y))
train_op = tf.train.AdamOptimizer(lr).minimize(cost)
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
with tf.Session() as sess:
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
step = 0
while step * batch_size < training_iters:
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
batch_xs = batch_xs.reshape([batch_size, n_steps, n_inputs])
sess.run([train_op], feed_dict={
x: batch_xs,
y: batch_ys,
})
if step % 20 == 0:
print(sess.run(accuracy, feed_dict={
x: batch_xs,
y: batch_ys,
}))
step += 1
(1)设置RNN参数
这次我们会使用 RNN 来进行分类的训练 (Classification). 会继续使用到手写数字 MNIST 数据集. 让 RNN 从每张图片的第一行像素读到最后一行, 然后再进行分类判断. 接下来我们导入 MNIST 数据并确定 RNN 的各种参数(hyper-parameters):
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
tf.set_random_seed(1) # set random seed
# 导入数据
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
# hyperparameters
lr = 0.001 # learning rate
training_iters = 100000 # train step 上限
batch_size = 128
n_inputs = 28 # MNIST data input (img shape: 28*28)
n_steps = 28 # time steps
n_hidden_units = 128 # neurons in hidden layer
n_classes = 10 # MNIST classes (0-9 digits)
接着定义 x, y 的 placeholder 和 weights, biases 的初始状况.
# x y placeholder
x = tf.placeholder(tf.float32, [None, n_steps, n_inputs])
y = tf.placeholder(tf.float32, [None, n_classes])
# 对 weights biases 初始值的定义
weights = {
# shape (28, 128)
'in': tf.Variable(tf.random_normal([n_inputs, n_hidden_units])),
# shape (128, 10)
'out': tf.Variable(tf.random_normal([n_hidden_units, n_classes]))
}
biases = {
# shape (128, )
'in': tf.Variable(tf.constant(0.1, shape=[n_hidden_units, ])),
# shape (10, )
'out': tf.Variable(tf.constant(0.1, shape=[n_classes, ]))
}
(2)定于RNN的主体结构
接着开始定义 RNN 主体结构, 这个 RNN 总共有 3 个组成部分 ( input_layer, cell, output_layer). 首先我们先定义 input_layer:
def RNN(X, weights, biases):
# 原始的 X 是 3 维数据, 我们需要把它变成 2 维数据才能使用 weights 的矩阵乘法
# X ==> (128 batches * 28 steps, 28 inputs)
X = tf.reshape(X, [-1, n_inputs])
# X_in = W*X + b
X_in = tf.matmul(X, weights['in']) + biases['in']
# X_in ==> (128 batches, 28 steps, 128 hidden) 换回3维
X_in = tf.reshape(X_in, [-1, n_steps, n_hidden_units])
接着是 cell 中的计算, 有两种途径:
使用 tf.nn.rnn(cell, inputs) (不推荐原因). 但是如果使用这种方法, 可以参考原因;
使用 tf.nn.dynamic_rnn(cell, inputs) (推荐). 这次的练习将使用这种方式.
因 Tensorflow 版本升级原因, state_is_tuple=True 将在之后的版本中变为默认. 对于 lstm 来说, state可被分为(c_state, h_state).
# 使用 basic LSTM Cell.
lstm_cell = tf.contrib.rnn.BasicLSTMCell(n_hidden_units, forget_bias=1.0, state_is_tuple=True)
init_state = lstm_cell.zero_state(batch_size, dtype=tf.float32) # 初始化全零 state
如果使用tf.nn.dynamic_rnn(cell, inputs), 我们要确定 inputs 的格式. tf.nn.dynamic_rnn 中的 time_major 参数会针对不同 inputs 格式有不同的值.
如果 inputs 为 (batches, steps, inputs) ==> time_major=False;
如果 inputs 为 (steps, batches, inputs) ==> time_major=True;
outputs, final_state = tf.nn.dynamic_rnn(lstm_cell, X_in, initial_state=init_state, time_major=False)
最后是 output_layer 和 return 的值. 因为这个例子的特殊性, 有两种方法可以求得 results.
方式一: 直接调用final_state 中的 h_state (final_state[1]) 来进行运算:
results = tf.matmul(final_state[1], weights['out']) + biases['out']
方式二: 调用最后一个 outputs (在这个例子中,和上面的final_state[1]是一样的):
# 把 outputs 变成 列表 [(batch, outputs)..] * steps
outputs = tf.unstack(tf.transpose(outputs, [1,0,2]))
results = tf.matmul(outputs[-1], weights['out']) + biases['out'] #选取最后一个 output
在 def RNN() 的最后输出 result
return results
定义好了 RNN 主体结构后, 我们就可以来计算 cost 和 train_op:
pred = RNN(x, weights, biases)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y))
train_op = tf.train.AdamOptimizer(lr).minimize(cost)
(3)训练RNN
训练时, 不断输出 accuracy, 观看结果:
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# init= tf.initialize_all_variables() # tf 马上就要废弃这种写法
# 替换成下面的写法:
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
step = 0
while step * batch_size < training_iters:
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
batch_xs = batch_xs.reshape([batch_size, n_steps, n_inputs])
sess.run([train_op], feed_dict={
x: batch_xs,
y: batch_ys,
})
if step % 20 == 0:
print(sess.run(accuracy, feed_dict={
x: batch_xs,
y: batch_ys,
}))
step += 1
最终 accuracy 的结果如下:
0.1875
0.65625
0.726562
0.757812
0.820312
0.796875
0.859375
0.921875
0.921875
0.898438
0.828125
0.890625
0.9375
0.921875
0.9375
0.929688
0.953125
....
5.13 RNN LSTM(回归例子)
- 设置RNN参数
- 数据生成
- 定义LSTM RNN 的主体结构
- 训练LSTM RNN
相关代码:
# View more python learning tutorial on my Youtube and Youku channel!!!
# Youtube video tutorial: https://www.youtube.com/channel/UCdyjiB5H8Pu7aDTNVXTTpcg
# Youku video tutorial: http://i.youku.com/pythontutorial
"""
Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly.
Run this script on tensorflow r0.10. Errors appear when using lower versions.
"""
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
BATCH_START = 0
TIME_STEPS = 20
BATCH_SIZE = 50
INPUT_SIZE = 1
OUTPUT_SIZE = 1
CELL_SIZE = 10
LR = 0.006
def get_batch():
global BATCH_START, TIME_STEPS
# xs shape (50batch, 20steps)
xs = np.arange(BATCH_START, BATCH_START+TIME_STEPS*BATCH_SIZE).reshape((BATCH_SIZE, TIME_STEPS)) / (10*np.pi)
seq = np.sin(xs)
res = np.cos(xs)
BATCH_START += TIME_STEPS
# plt.plot(xs[0, :], res[0, :], 'r', xs[0, :], seq[0, :], 'b--')
# plt.show()
# returned seq, res and xs: shape (batch, step, input)
return [seq[:, :, np.newaxis], res[:, :, np.newaxis], xs]
class LSTMRNN(object):
def __init__(self, n_steps, input_size, output_size, cell_size, batch_size):
self.n_steps = n_steps
self.input_size = input_size
self.output_size = output_size
self.cell_size = cell_size
self.batch_size = batch_size
with tf.name_scope('inputs'):
self.xs = tf.placeholder(tf.float32, [None, n_steps, input_size], name='xs')
self.ys = tf.placeholder(tf.float32, [None, n_steps, output_size], name='ys')
with tf.variable_scope('in_hidden'):
self.add_input_layer()
with tf.variable_scope('LSTM_cell'):
self.add_cell()
with tf.variable_scope('out_hidden'):
self.add_output_layer()
with tf.name_scope('cost'):
self.compute_cost()
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(LR).minimize(self.cost)
def add_input_layer(self,):
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='2_2D') # (batch*n_step, in_size)
# Ws (in_size, cell_size)
Ws_in = self._weight_variable([self.input_size, self.cell_size])
# bs (cell_size, )
bs_in = self._bias_variable([self.cell_size,])
# l_in_y = (batch * n_steps, cell_size)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# reshape l_in_y ==> (batch, n_steps, cell_size)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='2_3D')
def add_cell(self):
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
def add_output_layer(self):
# shape = (batch * steps, cell_size)
l_out_x = tf.reshape(self.cell_outputs, [-1, self.cell_size], name='2_2D')
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size, ])
# shape = (batch * steps, output_size)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(l_out_x, Ws_out) + bs_out
def compute_cost(self):
losses = tf.contrib.legacy_seq2seq.sequence_loss_by_example(
[tf.reshape(self.pred, [-1], name='reshape_pred')],
[tf.reshape(self.ys, [-1], name='reshape_target')],
[tf.ones([self.batch_size * self.n_steps], dtype=tf.float32)],
average_across_timesteps=True,
softmax_loss_function=self.ms_error,
name='losses'
)
with tf.name_scope('average_cost'):
self.cost = tf.div(
tf.reduce_sum(losses, name='losses_sum'),
self.batch_size,
name='average_cost')
tf.summary.scalar('cost', self.cost)
@staticmethod
def ms_error(labels, logits):
return tf.square(tf.subtract(labels, logits))
def _weight_variable(self, shape, name='weights'):
initializer = tf.random_normal_initializer(mean=0., stddev=1.,)
return tf.get_variable(shape=shape, initializer=initializer, name=name)
def _bias_variable(self, shape, name='biases'):
initializer = tf.constant_initializer(0.1)
return tf.get_variable(name=name, shape=shape, initializer=initializer)
if __name__ == '__main__':
model = LSTMRNN(TIME_STEPS, INPUT_SIZE, OUTPUT_SIZE, CELL_SIZE, BATCH_SIZE)
sess = tf.Session()
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("logs", sess.graph)
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
# relocate to the local dir and run this line to view it on Chrome (http://0.0.0.0:6006/):
# $ tensorboard --logdir='logs'
plt.ion()
plt.show()
for i in range(200):
seq, res, xs = get_batch()
if i == 0:
feed_dict = {
model.xs: seq,
model.ys: res,
# create initial state
}
else:
feed_dict = {
model.xs: seq,
model.ys: res,
model.cell_init_state: state # use last state as the initial state for this run
}
_, cost, state, pred = sess.run(
[model.train_op, model.cost, model.cell_final_state, model.pred],
feed_dict=feed_dict)
# plotting
plt.plot(xs[0, :], res[0].flatten(), 'r', xs[0, :], pred.flatten()[:TIME_STEPS], 'b--')
plt.ylim((-1.2, 1.2))
plt.draw()
plt.pause(0.3)
if i % 20 == 0:
print('cost: ', round(cost, 4))
result = sess.run(merged, feed_dict)
writer.add_summary(result, i)
(1)设置RNN参数
这次我们会使用 RNN 来进行回归的训练 (Regression). 会继续使用到自己创建的 sin 曲线预测一条 cos 曲线. 接下来我们先确定 RNN 的各种参数(super-parameters):
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
BATCH_START = 0 # 建立 batch data 时候的 index
TIME_STEPS = 20 # backpropagation through time 的 time_steps
BATCH_SIZE = 50
INPUT_SIZE = 1 # sin 数据输入 size
OUTPUT_SIZE = 1 # cos 数据输出 size
CELL_SIZE = 10 # RNN 的 hidden unit size
LR = 0.006 # learning rate
(2)数据生成
定义一个生成数据的 get_batch function:
def get_batch():
global BATCH_START, TIME_STEPS
# xs shape (50batch, 20steps)
xs = np.arange(BATCH_START, BATCH_START+TIME_STEPS*BATCH_SIZE).reshape((BATCH_SIZE, TIME_STEPS)) / (10*np.pi)
seq = np.sin(xs)
res = np.cos(xs)
BATCH_START += TIME_STEPS
# returned seq, res and xs: shape (batch, step, input)
return [seq[:, :, np.newaxis], res[:, :, np.newaxis], xs]

(3)定义LSTM RNN 的主体结构
使用一个 class 来定义这次的 LSTMRNN 会更加方便. 第一步定义 class 中的 init 传入各种参数:
class LSTMRNN(object):
def __init__(self, n_steps, input_size, output_size, cell_size, batch_size):
self.n_steps = n_steps
self.input_size = input_size
self.output_size = output_size
self.cell_size = cell_size
self.batch_size = batch_size
with tf.name_scope('inputs'):
self.xs = tf.placeholder(tf.float32, [None, n_steps, input_size], name='xs')
self.ys = tf.placeholder(tf.float32, [None, n_steps, output_size], name='ys')
with tf.variable_scope('in_hidden'):
self.add_input_layer()
with tf.variable_scope('LSTM_cell'):
self.add_cell()
with tf.variable_scope('out_hidden'):
self.add_output_layer()
with tf.name_scope('cost'):
self.compute_cost()
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(LR).minimize(self.cost)
设置 add_input_layer 功能, 添加 input_layer:
def add_input_layer(self,):
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='2_2D') # (batch*n_step, in_size)
# Ws (in_size, cell_size)
Ws_in = self._weight_variable([self.input_size, self.cell_size])
# bs (cell_size, )
bs_in = self._bias_variable([self.cell_size,])
# l_in_y = (batch * n_steps, cell_size)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# reshape l_in_y ==> (batch, n_steps, cell_size)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='2_3D')
设置 add_cell 功能, 添加 cell, 注意这里的 self.cell_init_state, 因为我们在 training 的时候, 这个地方要特别说明.
def add_cell(self):
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
设置 add_output_layer 功能, 添加 output_layer:
def add_output_layer(self):
# shape = (batch * steps, cell_size)
l_out_x = tf.reshape(self.cell_outputs, [-1, self.cell_size], name='2_2D')
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size, ])
# shape = (batch * steps, output_size)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(l_out_x, Ws_out) + bs_out
添加 RNN 中剩下的部分:
def compute_cost(self):
losses = tf.contrib.legacy_seq2seq.sequence_loss_by_example(
[tf.reshape(self.pred, [-1], name='reshape_pred')],
[tf.reshape(self.ys, [-1], name='reshape_target')],
[tf.ones([self.batch_size * self.n_steps], dtype=tf.float32)],
average_across_timesteps=True,
softmax_loss_function=self.ms_error,
name='losses'
)
with tf.name_scope('average_cost'):
self.cost = tf.div(
tf.reduce_sum(losses, name='losses_sum'),
self.batch_size,
name='average_cost')
tf.summary.scalar('cost', self.cost)
def ms_error(self, y_target, y_pre):
return tf.square(tf.sub(y_target, y_pre))
def _weight_variable(self, shape, name='weights'):
initializer = tf.random_normal_initializer(mean=0., stddev=1.,)
return tf.get_variable(shape=shape, initializer=initializer, name=name)
def _bias_variable(self, shape, name='biases'):
initializer = tf.constant_initializer(0.1)
return tf.get_variable(name=name, shape=shape, initializer=initializer)
(4)训练LSTM RNN
if __name__ == '__main__':
# 搭建 LSTMRNN 模型
model = LSTMRNN(TIME_STEPS, INPUT_SIZE, OUTPUT_SIZE, CELL_SIZE, BATCH_SIZE)
sess = tf.Session()
# sess.run(tf.initialize_all_variables()) # tf 马上就要废弃这种写法
# 替换成下面的写法:
sess.run(tf.global_variables_initializer())
# 训练 200 次
for i in range(200):
seq, res, xs = get_batch() # 提取 batch data
if i == 0:
# 初始化 data
feed_dict = {
model.xs: seq,
model.ys: res,
}
else:
feed_dict = {
model.xs: seq,
model.ys: res,
model.cell_init_state: state # 保持 state 的连续性
}
# 训练
_, cost, state, pred = sess.run(
[model.train_op, model.cost, model.cell_final_state, model.pred],
feed_dict=feed_dict)
# 打印 cost 结果
if i % 20 == 0:
print('cost: ', round(cost, 4))
最后cost结果如下:
cost: 48.4813
cost: 9.9825
cost: 7.9988
cost: 5.8154
cost: 3.9268
cost: 2.4393
cost: 2.9643
cost: 0.4856
cost: 0.5175
cost: 0.7858
5.14 RNN LSTM(回归例子可视化)
- matplotlib可视化
相关代码:
# View more python learning tutorial on my Youtube and Youku channel!!!
# Youtube video tutorial: https://www.youtube.com/channel/UCdyjiB5H8Pu7aDTNVXTTpcg
# Youku video tutorial: http://i.youku.com/pythontutorial
"""
Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly.
Run this script on tensorflow r0.10. Errors appear when using lower versions.
"""
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
BATCH_START = 0
TIME_STEPS = 20
BATCH_SIZE = 50
INPUT_SIZE = 1
OUTPUT_SIZE = 1
CELL_SIZE = 10
LR = 0.006
def get_batch():
global BATCH_START, TIME_STEPS
# xs shape (50batch, 20steps)
xs = np.arange(BATCH_START, BATCH_START+TIME_STEPS*BATCH_SIZE).reshape((BATCH_SIZE, TIME_STEPS)) / (10*np.pi)
seq = np.sin(xs)
res = np.cos(xs)
BATCH_START += TIME_STEPS
# plt.plot(xs[0, :], res[0, :], 'r', xs[0, :], seq[0, :], 'b--')
# plt.show()
# returned seq, res and xs: shape (batch, step, input)
return [seq[:, :, np.newaxis], res[:, :, np.newaxis], xs]
class LSTMRNN(object):
def __init__(self, n_steps, input_size, output_size, cell_size, batch_size):
self.n_steps = n_steps
self.input_size = input_size
self.output_size = output_size
self.cell_size = cell_size
self.batch_size = batch_size
with tf.name_scope('inputs'):
self.xs = tf.placeholder(tf.float32, [None, n_steps, input_size], name='xs')
self.ys = tf.placeholder(tf.float32, [None, n_steps, output_size], name='ys')
with tf.variable_scope('in_hidden'):
self.add_input_layer()
with tf.variable_scope('LSTM_cell'):
self.add_cell()
with tf.variable_scope('out_hidden'):
self.add_output_layer()
with tf.name_scope('cost'):
self.compute_cost()
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(LR).minimize(self.cost)
def add_input_layer(self,):
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='2_2D') # (batch*n_step, in_size)
# Ws (in_size, cell_size)
Ws_in = self._weight_variable([self.input_size, self.cell_size])
# bs (cell_size, )
bs_in = self._bias_variable([self.cell_size,])
# l_in_y = (batch * n_steps, cell_size)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# reshape l_in_y ==> (batch, n_steps, cell_size)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='2_3D')
def add_cell(self):
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
def add_output_layer(self):
# shape = (batch * steps, cell_size)
l_out_x = tf.reshape(self.cell_outputs, [-1, self.cell_size], name='2_2D')
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size, ])
# shape = (batch * steps, output_size)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(l_out_x, Ws_out) + bs_out
def compute_cost(self):
losses = tf.contrib.legacy_seq2seq.sequence_loss_by_example(
[tf.reshape(self.pred, [-1], name='reshape_pred')],
[tf.reshape(self.ys, [-1], name='reshape_target')],
[tf.ones([self.batch_size * self.n_steps], dtype=tf.float32)],
average_across_timesteps=True,
softmax_loss_function=self.ms_error,
name='losses'
)
with tf.name_scope('average_cost'):
self.cost = tf.div(
tf.reduce_sum(losses, name='losses_sum'),
self.batch_size,
name='average_cost')
tf.summary.scalar('cost', self.cost)
@staticmethod
def ms_error(labels, logits):
return tf.square(tf.subtract(labels, logits))
def _weight_variable(self, shape, name='weights'):
initializer = tf.random_normal_initializer(mean=0., stddev=1.,)
return tf.get_variable(shape=shape, initializer=initializer, name=name)
def _bias_variable(self, shape, name='biases'):
initializer = tf.constant_initializer(0.1)
return tf.get_variable(name=name, shape=shape, initializer=initializer)
if __name__ == '__main__':
model = LSTMRNN(TIME_STEPS, INPUT_SIZE, OUTPUT_SIZE, CELL_SIZE, BATCH_SIZE)
sess = tf.Session()
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("logs", sess.graph)
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
# relocate to the local dir and run this line to view it on Chrome (http://0.0.0.0:6006/):
# $ tensorboard --logdir='logs'
plt.ion()
plt.show()
for i in range(200):
seq, res, xs = get_batch()
if i == 0:
feed_dict = {
model.xs: seq,
model.ys: res,
# create initial state
}
else:
feed_dict = {
model.xs: seq,
model.ys: res,
model.cell_init_state: state # use last state as the initial state for this run
}
_, cost, state, pred = sess.run(
[model.train_op, model.cost, model.cell_final_state, model.pred],
feed_dict=feed_dict)
# plotting
plt.plot(xs[0, :], res[0].flatten(), 'r', xs[0, :], pred.flatten()[:TIME_STEPS], 'b--')
plt.ylim((-1.2, 1.2))
plt.draw()
plt.pause(0.3)
if i % 20 == 0:
print('cost: ', round(cost, 4))
result = sess.run(merged, feed_dict)
writer.add_summary(result, i)
(1)matplotlib可视化
使用 Matplotlib 模块来进行可视化过程, 在建立好 model 以后, 设置 plt.ion() 使 plt.show()可以连续显示.
model = LSTMRNN(TIME_STEPS, INPUT_SIZE, OUTPUT_SIZE, CELL_SIZE, BATCH_SIZE)
sess = tf.Session()
# sess.run(tf.initialize_all_variables()) # tf 马上就要废弃这种写法
# 替换成下面的写法:
sess.run(tf.global_variables_initializer())
plt.ion() # 设置连续 plot
plt.show()
然后在 sess.run() 后面加上plt.draw()的步骤.
_, cost, state, pred = sess.run(
[model.train_op, model.cost, model.cell_final_state, model.pred],
feed_dict=feed_dict)
# plotting
plt.plot(xs[0, :], res[0].flatten(), 'r', xs[0, :], pred.flatten()[:TIME_STEPS], 'b--')
plt.ylim((-1.2, 1.2))
plt.draw()
plt.pause(0.3) # 每 0.3 s 刷新一次
最后的结果显示为:

5.15 什么是自编码(Autoencoder)
- 压缩与解压
- 编码器 Encoder
- 解码器 Decoder
今天我们会来聊聊用神经网络如何进行非监督形式的学习. 也就是 autoencoder, 自编码.
自编码 autoencoder 是一种什么码呢. 他是不是 条形码? 二维码? 打码? 其中的一种呢? NONONONO. 和他们统统没有关系. 自编码是一种神经网络的形式.如果你一定要把他们扯上关系, 我想也只能这样解释啦.
(1)压缩与解压

有一个神经网络, 它在做的事情是 接收一张图片, 然后 给它打码, 最后 再从打码后的图片中还原. 太抽象啦? 行, 我们再具体点.

假设刚刚那个神经网络是这样, 对应上刚刚的图片, 可以看出图片其实是经过了压缩,再解压的这一道工序. 当压缩的时候, 原有的图片质量被缩减, 解压时用信息量小却包含了所有关键信息的文件恢复出原本的图片. 为什么要这样做呢?

原来有时神经网络要接受大量的输入信息, 比如输入信息是高清图片时, 输入信息量可能达到上千万, 让神经网络直接从上千万个信息源中学习是一件很吃力的工作. 所以, 何不压缩一下, 提取出原图片中的最具代表性的信息, 缩减输入信息量, 再把缩减过后的信息放进神经网络学习. 这样学习起来就简单轻松了. 所以, 自编码就能在这时发挥作用. 通过将原数据白色的X 压缩, 解压 成黑色的X, 然后通过对比黑白 X ,求出预测误差, 进行反向传递, 逐步提升自编码的准确性. 训练好的自编码中间这一部分就是能总结原数据的精髓. 可以看出, 从头到尾, 我们只用到了输入数据 X, 并没有用到 X 对应的数据标签, 所以也可以说自编码是一种非监督学习. 到了真正使用自编码的时候. 通常只会用到自编码前半部分.
(2)编码器 Encoder

这 部分也叫作 encoder 编码器. 编码器能得到原数据的精髓, 然后我们只需要再创建一个小的神经网络学习这个精髓的数据,不仅减少了神经网络的负担, 而且同样能达到很好的效果.

这是一个通过自编码整理出来的数据, 他能从原数据中总结出每种类型数据的特征, 如果把这些特征类型都放在一张二维的图片上, 每种类型都已经被很好的用原数据的精髓区分开来. 如果你了解 PCA 主成分分析, 再提取主要特征时, 自编码和它一样,甚至超越了 PCA. 换句话说, 自编码 可以像 PCA 一样 给特征属性降维.
(3)解码器 Decoder
至于解码器 Decoder, 我们也能那它来做点事情. 我们知道, 解码器在训练的时候是要将精髓信息解压成原始信息, 那么这就提供了一个解压器的作用, 甚至我们可以认为是一个生成器 (类似于GAN). 那做这件事的一种特殊自编码叫做 variational autoencoders, 你能在这里找到他的具体说明.
有一个例子就是让它能模仿并生成手写数字.

5.16 自编码Autoencoder(非监督学习)
- 要点
- Autoencoder
- Encoder
相关代码:
# View more python learning tutorial on my Youtube and Youku channel!!!
# My tutorial website: https://mofanpy.com/tutorials/
from __future__ import division, print_function, absolute_import
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# Import MNIST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=False)
# Visualize decoder setting
# Parameters
learning_rate = 0.01
training_epochs = 5
batch_size = 256
display_step = 1
examples_to_show = 10
# Network Parameters
n_input = 784 # MNIST data input (img shape: 28*28)
# tf Graph input (only pictures)
X = tf.placeholder("float", [None, n_input])
# hidden layer settings
n_hidden_1 = 256 # 1st layer num features
n_hidden_2 = 128 # 2nd layer num features
weights = {
'encoder_h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_1])),
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_input])),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b2': tf.Variable(tf.random_normal([n_input])),
}
# Building the encoder
def encoder(x):
# Encoder Hidden layer with sigmoid activation #1
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
# Decoder Hidden layer with sigmoid activation #2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
return layer_2
# Building the decoder
def decoder(x):
# Encoder Hidden layer with sigmoid activation #1
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
# Decoder Hidden layer with sigmoid activation #2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
return layer_2
"""
# Visualize encoder setting
# Parameters
learning_rate = 0.01 # 0.01 this learning rate will be better! Tested
training_epochs = 10
batch_size = 256
display_step = 1
# Network Parameters
n_input = 784 # MNIST data input (img shape: 28*28)
# tf Graph input (only pictures)
X = tf.placeholder("float", [None, n_input])
# hidden layer settings
n_hidden_1 = 128
n_hidden_2 = 64
n_hidden_3 = 10
n_hidden_4 = 2
weights = {
'encoder_h1': tf.Variable(tf.truncated_normal([n_input, n_hidden_1],)),
'encoder_h2': tf.Variable(tf.truncated_normal([n_hidden_1, n_hidden_2],)),
'encoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_3],)),
'encoder_h4': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_4],)),
'decoder_h1': tf.Variable(tf.truncated_normal([n_hidden_4, n_hidden_3],)),
'decoder_h2': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_2],)),
'decoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_1],)),
'decoder_h4': tf.Variable(tf.truncated_normal([n_hidden_1, n_input],)),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'encoder_b3': tf.Variable(tf.random_normal([n_hidden_3])),
'encoder_b4': tf.Variable(tf.random_normal([n_hidden_4])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_3])),
'decoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b3': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b4': tf.Variable(tf.random_normal([n_input])),
}
def encoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['encoder_h3']),
biases['encoder_b3']))
layer_4 = tf.add(tf.matmul(layer_3, weights['encoder_h4']),
biases['encoder_b4'])
return layer_4
def decoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['decoder_h3']),
biases['decoder_b3']))
layer_4 = tf.nn.sigmoid(tf.add(tf.matmul(layer_3, weights['decoder_h4']),
biases['decoder_b4']))
return layer_4
"""
# Construct model
encoder_op = encoder(X)
decoder_op = decoder(encoder_op)
# Prediction
y_pred = decoder_op
# Targets (Labels) are the input data.
y_true = X
# Define loss and optimizer, minimize the squared error
cost = tf.reduce_mean(tf.pow(y_true - y_pred, 2))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
# Launch the graph
with tf.Session() as sess:
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
total_batch = int(mnist.train.num_examples/batch_size)
# Training cycle
for epoch in range(training_epochs):
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size) # max(x) = 1, min(x) = 0
# Run optimization op (backprop) and cost op (to get loss value)
_, c = sess.run([optimizer, cost], feed_dict={X: batch_xs})
# Display logs per epoch step
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch+1),
"cost=", "{:.9f}".format(c))
print("Optimization Finished!")
# # Applying encode and decode over test set
encode_decode = sess.run(
y_pred, feed_dict={X: mnist.test.images[:examples_to_show]})
# Compare original images with their reconstructions
f, a = plt.subplots(2, 10, figsize=(10, 2))
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
a[1][i].imshow(np.reshape(encode_decode[i], (28, 28)))
plt.show()
# encoder_result = sess.run(encoder_op, feed_dict={X: mnist.test.images})
# plt.scatter(encoder_result[:, 0], encoder_result[:, 1], c=mnist.test.labels)
# plt.colorbar()
# plt.show()
(1)要点
Autoencoder 简单来说就是将有很多Feature的数据进行压缩,之后再进行解压的过程。 本质上来说,它也是一个对数据的非监督学习,如果大家知道 PCA (Principal component analysis), 与 Autoencoder 相类似,它的主要功能即对数据进行非监督学习,并将压缩之后得到的“特征值”,这一中间结果正类似于PCA的结果。 之后再将压缩过的“特征值”进行解压,得到的最终结果与原始数据进行比较,对此进行非监督学习。如果大家还不是非常了解,请观看机器学习简介系列里的 Autoencoder 那一集; 如果对它已经有了一定的了解,那么便可以进行代码阶段的学习了。大概过程如下图所示:

今天的代码,我们会运用两个类型:
第一,是通过Feature的压缩并解压,并将结果与原始数据进行对比,观察处理过后的数据是不是如预期跟原始数据很相像。(这里会用到MNIST数据)
第二,我们只看 encoder 压缩的过程,使用它将一个数据集压缩到只有两个Feature时,将数据放入一个二维坐标系内,特征压缩的效果如下:

同样颜色的点,代表分到同一类的数据。(Lebel相同)
(2)Autoencoder
# Parameter
learning_rate = 0.01
training_epochs = 5 # 五组训练
batch_size = 256
display_step = 1
examples_to_show = 10
我们的MNIST数据,每张图片大小是 28x28 pix,即 784 Features:
# Network Parameters
n_input = 784 # MNIST data input (img shape: 28*28)
在压缩环节:我们要把这个Features不断压缩,经过第一个隐藏层压缩至256个 Features,再经过第二个隐藏层压缩至128个。
在解压环节:我们将128个Features还原至256个,再经过一步还原至784个。
在对比环节:比较原始数据与还原后的拥有 784 Features 的数据进行 cost 的对比,根据 cost 来提升我的 Autoencoder 的准确率,下图是两个隐藏层的 weights 和 biases 的定义:
# hidden layer settings
n_hidden_1 = 256 # 1st layer num features
n_hidden_2 = 128 # 2nd layer num features
weights = {
'encoder_h1':tf.Variable(tf.random_normal([n_input,n_hidden_1])),
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1,n_hidden_2])),
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_2,n_hidden_1])),
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_input])),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b2': tf.Variable(tf.random_normal([n_input])),
}
下面来定义 Encoder 和 Decoder ,使用的 Activation function 是 sigmoid, 压缩之后的值应该在 [0,1] 这个范围内。在 decoder 过程中,通常使用对应于 encoder 的 Activation function:
# Building the encoder
def encoder(x):
# Encoder Hidden layer with sigmoid activation #1
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
# Decoder Hidden layer with sigmoid activation #2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
return layer_2
# Building the decoder
def decoder(x):
# Encoder Hidden layer with sigmoid activation #1
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
# Decoder Hidden layer with sigmoid activation #2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
return layer_2
来实现 Encoder 和 Decoder 输出的结果:
# Construct model
encoder_op = encoder(X) # 128 Features
decoder_op = decoder(encoder_op) # 784 Features
# Prediction
y_pred = decoder_op # After
# Targets (Labels) are the input data.
y_true = X # Before
再通过我们非监督学习进行对照,即对 “原始的有 784 Features 的数据集” 和 “通过 ‘Prediction’ 得出的有 784 Features 的数据集” 进行最小二乘法的计算,并且使 cost 最小化:
# Define loss and optimizer, minimize the squared error
cost = tf.reduce_mean(tf.pow(y_true - y_pred, 2))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
最后,通过 Matplotlib 的 pyplot 模块将结果显示出来, 注意在输出时MNIST数据集经过压缩之后 x 的最大值是1,而非255:
# Launch the graph
with tf.Session() as sess:
# tf 马上就要废弃tf.initialize_all_variables()这种写法
# 替换成下面:
sess.run(tf.global_variables_initializer())
total_batch = int(mnist.train.num_examples/batch_size)
# Training cycle
for epoch in range(training_epochs):
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size) # max(x) = 1, min(x) = 0
# Run optimization op (backprop) and cost op (to get loss value)
_, c = sess.run([optimizer, cost], feed_dict={X: batch_xs})
# Display logs per epoch step
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch+1),
"cost=", "{:.9f}".format(c))
print("Optimization Finished!")
# # Applying encode and decode over test set
encode_decode = sess.run(
y_pred, feed_dict={X: mnist.test.images[:examples_to_show]})
# Compare original images with their reconstructions
f, a = plt.subplots(2, 10, figsize=(10, 2))
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
a[1][i].imshow(np.reshape(encode_decode[i], (28, 28)))
plt.show()
通过5个 Epoch 的训练,(通常情况下,想要得到好的的效果,我们应进行10 ~ 20个 Epoch 的训练)我们的结果如下:

上面一行是真实数据,下面一行是经过 encoder 和 decoder 之后的数据,如果继续进行训练,效果会更好。
(3)Encoder
在类型二中,我们只显示 encoder 之后的数据, 并画在一个二维直角坐标系内。做法很简单,我们将原有 784 Features 的数据压缩成仅剩 2 Features 的数据:
# Parameters
learning_rate = 0.01 # 0.01 this learning rate will be better! Tested
training_epochs = 10 # 10 Epoch 训练
batch_size = 256
display_step = 1
通过四层 Hidden Layers 实现将 784 Features 压缩至 2 Features:
# hidden layer settings
n_hidden_1 = 128
n_hidden_2 = 64
n_hidden_3 = 10
n_hidden_4 = 2
Weights 和 biases 也要做相应的变化:
weights = {
'encoder_h1': tf.Variable(tf.truncated_normal([n_input, n_hidden_1],)),
'encoder_h2': tf.Variable(tf.truncated_normal([n_hidden_1, n_hidden_2],)),
'encoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_3],)),
'encoder_h4': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_4],)),
'decoder_h1': tf.Variable(tf.truncated_normal([n_hidden_4, n_hidden_3],)),
'decoder_h2': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_2],)),
'decoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_1],)),
'decoder_h4': tf.Variable(tf.truncated_normal([n_hidden_1, n_input],)),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'encoder_b3': tf.Variable(tf.random_normal([n_hidden_3])),
'encoder_b4': tf.Variable(tf.random_normal([n_hidden_4])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_3])),
'decoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b3': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b4': tf.Variable(tf.random_normal([n_input])),
}
与类型一类似,创建四层神经网络。(注意:在第四层时,输出量不再是 [0,1] 范围内的数,而是将数据通过默认的 Linear activation function 调整为 (-∞,∞) :
def encoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['encoder_h3']),
biases['encoder_b3']))
layer_4 = tf.add(tf.matmul(layer_3, weights['encoder_h4']),
biases['encoder_b4'])
return layer_4
def decoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['decoder_h3']),
biases['decoder_b3']))
layer_4 = tf.nn.sigmoid(tf.add(tf.matmul(layer_3, weights['decoder_h4']),
biases['decoder_b4']))
return layer_4
在输出图像时,我们只关心 encoder 压缩之后,即 decoder 解压之前的结果:

5.17 scope命名方法
- tf.name_scope()
- tf.variable_scope()
- RNN应用例子
scope 能让你命名变量的时候轻松很多. 同时也会在 reusing variable 代码中常常见到. 所以今天我们会来讨论下 tensorflow 当中的两种定义 scope 的方式. 最后并附加一个 RNN 运用 reuse variable 的例子.
相关代码:
# visit https://mofanpy.com/tutorials/ for more!
# 22 scope (name_scope/variable_scope)
from __future__ import print_function
import tensorflow as tf
with tf.name_scope("a_name_scope"):
initializer = tf.constant_initializer(value=1)
var1 = tf.get_variable(name='var1', shape=[1], dtype=tf.float32, initializer=initializer)
var2 = tf.Variable(name='var2', initial_value=[2], dtype=tf.float32)
var21 = tf.Variable(name='var2', initial_value=[2.1], dtype=tf.float32)
var22 = tf.Variable(name='var2', initial_value=[2.2], dtype=tf.float32)
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
print(var1.name) # var1:0
print(sess.run(var1)) # [ 1.]
print(var2.name) # a_name_scope/var2:0
print(sess.run(var2)) # [ 2.]
print(var21.name) # a_name_scope/var2_1:0
print(sess.run(var21)) # [ 2.0999999]
print(var22.name) # a_name_scope/var2_2:0
print(sess.run(var22)) # [ 2.20000005]
with tf.variable_scope("a_variable_scope") as scope:
initializer = tf.constant_initializer(value=3)
var3 = tf.get_variable(name='var3', shape=[1], dtype=tf.float32, initializer=initializer)
var4 = tf.Variable(name='var4', initial_value=[4], dtype=tf.float32)
var4_reuse = tf.Variable(name='var4', initial_value=[4], dtype=tf.float32)
scope.reuse_variables()
var3_reuse = tf.get_variable(name='var3',)
with tf.Session() as sess:
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
print(var3.name) # a_variable_scope/var3:0
print(sess.run(var3)) # [ 3.]
print(var4.name) # a_variable_scope/var4:0
print(sess.run(var4)) # [ 4.]
print(var4_reuse.name) # a_variable_scope/var4_1:0
print(sess.run(var4_reuse)) # [ 4.]
print(var3_reuse.name) # a_variable_scope/var3:0
print(sess.run(var3_reuse)) # [ 3.]
(1)tf.name_scope()
在 Tensorflow 当中有两种途径生成变量 variable, 一种是 tf.get_variable(), 另一种是 tf.Variable(). 如果在 tf.name_scope() 的框架下使用这两种方式, 结果会如下.
import tensorflow as tf
with tf.name_scope("a_name_scope"):
initializer = tf.constant_initializer(value=1)
var1 = tf.get_variable(name='var1', shape=[1], dtype=tf.float32, initializer=initializer)
var2 = tf.Variable(name='var2', initial_value=[2], dtype=tf.float32)
var21 = tf.Variable(name='var2', initial_value=[2.1], dtype=tf.float32)
var22 = tf.Variable(name='var2', initial_value=[2.2], dtype=tf.float32)
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
print(var1.name) # var1:0
print(sess.run(var1)) # [ 1.]
print(var2.name) # a_name_scope/var2:0
print(sess.run(var2)) # [ 2.]
print(var21.name) # a_name_scope/var2_1:0
print(sess.run(var21)) # [ 2.0999999]
print(var22.name) # a_name_scope/var2_2:0
print(sess.run(var22)) # [ 2.20000005]
可以看出使用 tf.Variable() 定义的时候, 虽然 name 都一样, 但是为了不重复变量名, Tensorflow 输出的变量名并不是一样的. 所以, 本质上 var2, var21, var22 并不是一样的变量. 而另一方面, 使用tf.get_variable()定义的变量不会被tf.name_scope()当中的名字所影响.
(2)tf.variable_scope()
如果想要达到重复利用变量的效果, 我们就要使用 tf.variable_scope(), 并搭配 tf.get_variable() 这种方式产生和提取变量. 不像 tf.Variable() 每次都会产生新的变量, tf.get_variable() 如果遇到了同样名字的变量时, 它会单纯的提取这个同样名字的变量(避免产生新变量). 而在重复使用的时候, 一定要在代码中强调 scope.reuse_variables(), 否则系统将会报错, 以为你只是单纯的不小心重复使用到了一个变量.
with tf.variable_scope("a_variable_scope") as scope:
initializer = tf.constant_initializer(value=3)
var3 = tf.get_variable(name='var3', shape=[1], dtype=tf.float32, initializer=initializer)
scope.reuse_variables()
var3_reuse = tf.get_variable(name='var3',)
var4 = tf.Variable(name='var4', initial_value=[4], dtype=tf.float32)
var4_reuse = tf.Variable(name='var4', initial_value=[4], dtype=tf.float32)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(var3.name) # a_variable_scope/var3:0
print(sess.run(var3)) # [ 3.]
print(var3_reuse.name) # a_variable_scope/var3:0
print(sess.run(var3_reuse)) # [ 3.]
print(var4.name) # a_variable_scope/var4:0
print(sess.run(var4)) # [ 4.]
print(var4_reuse.name) # a_variable_scope/var4_1:0
print(sess.run(var4_reuse)) # [ 4.]
(3)RNN应用例子
RNN 例子的代码在这里, 整个 RNN 的结构已经在这里定义好了. 在 training RNN 和 test RNN 的时候, RNN 的 time_steps 会有不同的取值, 这将会影响到整个 RNN 的结构, 所以导致在 test 的时候, 不能单纯地使用 training 时建立的那个 RNN. 但是 training RNN 和 test RNN 又必须是有同样的 weights biases 的参数. 所以, 这时, 就是使用 reuse variable 的好时机.
首先定义training 和 test 的不同参数.
class TrainConfig:
batch_size = 20
time_steps = 20
input_size = 10
output_size = 2
cell_size = 11
learning_rate = 0.01
class TestConfig(TrainConfig):
time_steps = 1
train_config = TrainConfig()
test_config = TestConfig()
然后让 train_rnn 和 test_rnn 在同一个 tf.variable_scope(‘rnn’) 之下. 并且定义 scope.reuse_variables(), 使我们能把 train_rnn 的所有 weights, biases 参数全部绑定到 test_rnn 中. 这样, 不管两者的 time_steps 有多不同, 结构有多不同, train_rnn W, b 参数更新成什么样, test_rnn 的参数也更新成什么样.
with tf.variable_scope('rnn') as scope:
sess = tf.Session()
train_rnn = RNN(train_config)
scope.reuse_variables()
test_rnn = RNN(test_config)
sess.run(tf.global_variables_initializer())
5.18 什么是批标准化(Batch Normalization)
- 普通数据标准化
- 每层都做标准化
- BN 添加位置
- BN 效果
- BN 算法
(1)普通数据标准化

Batch Normalization, 批标准化, 和普通的数据标准化类似, 是将分散的数据统一的一种做法, 也是优化神经网络的一种方法. 具有统一规格的数据, 能让机器学习更容易学习到数据之中的规律.
(2)每层都做标准化

在神经网络中, 数据分布对训练会产生影响. 比如某个神经元 x 的值为1, 某个 Weights 的初始值为 0.1, 这样后一层神经元计算结果就是 Wx = 0.1; 又或者 x = 20, 这样 Wx 的结果就为 2. 现在还不能看出什么问题, 但是, 当我们加上一层激励函数, 激活这个 Wx 值的时候, 问题就来了. 如果使用 像 tanh 的激励函数, Wx 的激活值就变成了 ~0.1 和 ~1, 接近于 1 的部已经处在了 激励函数的饱和阶段, 也就是如果 x 无论再怎么扩大, tanh 激励函数输出值也还是 接近1. 换句话说, 神经网络在初始阶段已经不对那些比较大的 x 特征范围 敏感了. 这样很糟糕, 想象我轻轻拍自己的感觉和重重打自己的感觉居然没什么差别, 这就证明我的感官系统失效了. 当然我们是可以用之前提到的对数据做 normalization 预处理, 使得输入的 x 变化范围不会太大, 让输入值经过激励函数的敏感部分. 但刚刚这个不敏感问题不仅仅发生在神经网络的输入层, 而且在隐藏层中也经常会发生.

只是时候 x 换到了隐藏层当中, 我们能不能对隐藏层的输入结果进行像之前那样的normalization 处理呢? 答案是可以的, 因为大牛们发明了一种技术, 叫做 batch normalization, 正是处理这种情况.
(3)BN 添加位置

Batch normalization 的 batch 是批数据, 把数据分成小批小批进行 stochastic gradient descent. 而且在每批数据进行前向传递 forward propagation 的时候, 对每一层都进行 normalization 的处理.
(4)BN 效果
Batch normalization 也可以被看做一个层面. 在一层层的添加神经网络的时候, 我们先有数据 X, 再添加全连接层, 全连接层的计算结果会经过 激励函数 成为下一层的输入, 接着重复之前的操作. Batch Normalization (BN) 就被添加在每一个全连接和激励函数之间.

之前说过, 计算结果在进入激励函数前的值很重要, 如果我们不单单看一个值, 我们可以说, 计算结果值的分布对于激励函数很重要. 对于数据值大多分布在这个区间的数据, 才能进行更有效的传递. 对比这两个在激活之前的值的分布. 上者没有进行 normalization, 下者进行了 normalization, 这样当然是下者能够更有效地利用 tanh 进行非线性化的过程.

没有 normalize 的数据 使用 tanh 激活以后, 激活值大部分都分布到了饱和阶段, 也就是大部分的激活值不是-1, 就是1, 而 normalize 以后, 大部分的激活值在每个分布区间都还有存在. 再将这个激活后的分布传递到下一层神经网络进行后续计算, 每个区间都有分布的这一种对于神经网络就会更加有价值. Batch normalization 不仅仅 normalize 了一下数据, 他还进行了反 normalize 的手续. 为什么要这样呢?
(5)BN 算法

我们引入一些 batch normalization 的公式. 这三步就是我们在刚刚一直说的 normalization 工序, 但是公式的后面还有一个反向操作, 将 normalize 后的数据再扩展和平移. 原来这是为了让神经网络自己去学着使用和修改这个扩展参数 gamma, 和 平移参数 β, 这样神经网络就能自己慢慢琢磨出前面的 normalization 操作到底有没有起到优化的作用, 如果没有起到作用, 我就使用 gamma 和 belt 来抵消一些 normalization 的操作.

最后我们来看看一张神经网络训练到最后, 代表了每层输出值的结果的分布图. 这样我们就能一眼看出 Batch normalization 的功效啦. 让每一层的值在有效的范围内传递下去.
5.19 Batch Normalization 批标准化
- 什么是Bacth Normalization
- 搭建网络
- 创建数据
- Bacth Normalization 代码
- 对比有无BN
相关论文链接:论文
相关代码:
"""
visit https://mofanpy.com/tutorials/ for more!
Build two networks.
1. Without batch normalization
2. With batch normalization
Run tests on these two networks.
"""
# 23 Batch Normalization
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
ACTIVATION = tf.nn.relu
N_LAYERS = 7
N_HIDDEN_UNITS = 30
def fix_seed(seed=1):
# reproducible
np.random.seed(seed)
tf.set_random_seed(seed)
def plot_his(inputs, inputs_norm):
# plot histogram for the inputs of every layer
for j, all_inputs in enumerate([inputs, inputs_norm]):
for i, input in enumerate(all_inputs):
plt.subplot(2, len(all_inputs), j*len(all_inputs)+(i+1))
plt.cla()
if i == 0:
the_range = (-7, 10)
else:
the_range = (-1, 1)
plt.hist(input.ravel(), bins=15, range=the_range, color='#FF5733')
plt.yticks(())
if j == 1:
plt.xticks(the_range)
else:
plt.xticks(())
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
plt.title("%s normalizing" % ("Without" if j == 0 else "With"))
plt.draw()
plt.pause(0.01)
def built_net(xs, ys, norm):
def add_layer(inputs, in_size, out_size, activation_function=None, norm=False):
# weights and biases (bad initialization for this case)
Weights = tf.Variable(tf.random_normal([in_size, out_size], mean=0., stddev=1.))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
# fully connected product
Wx_plus_b = tf.matmul(inputs, Weights) + biases
# normalize fully connected product
if norm:
# Batch Normalize
fc_mean, fc_var = tf.nn.moments(
Wx_plus_b,
axes=[0], # the dimension you wanna normalize, here [0] for batch
# for image, you wanna do [0, 1, 2] for [batch, height, width] but not channel
)
scale = tf.Variable(tf.ones([out_size]))
shift = tf.Variable(tf.zeros([out_size]))
epsilon = 0.001
# apply moving average for mean and var when train on batch
ema = tf.train.ExponentialMovingAverage(decay=0.5)
def mean_var_with_update():
ema_apply_op = ema.apply([fc_mean, fc_var])
with tf.control_dependencies([ema_apply_op]):
return tf.identity(fc_mean), tf.identity(fc_var)
mean, var = mean_var_with_update()
Wx_plus_b = tf.nn.batch_normalization(Wx_plus_b, mean, var, shift, scale, epsilon)
# similar with this two steps:
# Wx_plus_b = (Wx_plus_b - fc_mean) / tf.sqrt(fc_var + 0.001)
# Wx_plus_b = Wx_plus_b * scale + shift
# activation
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs
fix_seed(1)
if norm:
# BN for the first input
fc_mean, fc_var = tf.nn.moments(
xs,
axes=[0],
)
scale = tf.Variable(tf.ones([1]))
shift = tf.Variable(tf.zeros([1]))
epsilon = 0.001
# apply moving average for mean and var when train on batch
ema = tf.train.ExponentialMovingAverage(decay=0.5)
def mean_var_with_update():
ema_apply_op = ema.apply([fc_mean, fc_var])
with tf.control_dependencies([ema_apply_op]):
return tf.identity(fc_mean), tf.identity(fc_var)
mean, var = mean_var_with_update()
xs = tf.nn.batch_normalization(xs, mean, var, shift, scale, epsilon)
# record inputs for every layer
layers_inputs = [xs]
# build hidden layers
for l_n in range(N_LAYERS):
layer_input = layers_inputs[l_n]
in_size = layers_inputs[l_n].get_shape()[1].value
output = add_layer(
layer_input, # input
in_size, # input size
N_HIDDEN_UNITS, # output size
ACTIVATION, # activation function
norm, # normalize before activation
)
layers_inputs.append(output) # add output for next run
# build output layer
prediction = add_layer(layers_inputs[-1], 30, 1, activation_function=None)
cost = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction), reduction_indices=[1]))
train_op = tf.train.GradientDescentOptimizer(0.001).minimize(cost)
return [train_op, cost, layers_inputs]
# make up data
fix_seed(1)
x_data = np.linspace(-7, 10, 2500)[:, np.newaxis]
np.random.shuffle(x_data)
noise = np.random.normal(0, 8, x_data.shape)
y_data = np.square(x_data) - 5 + noise
# plot input data
plt.scatter(x_data, y_data)
plt.show()
xs = tf.placeholder(tf.float32, [None, 1]) # [num_samples, num_features]
ys = tf.placeholder(tf.float32, [None, 1])
train_op, cost, layers_inputs = built_net(xs, ys, norm=False) # without BN
train_op_norm, cost_norm, layers_inputs_norm = built_net(xs, ys, norm=True) # with BN
sess = tf.Session()
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
# record cost
cost_his = []
cost_his_norm = []
record_step = 5
plt.ion()
plt.figure(figsize=(7, 3))
for i in range(250):
if i % 50 == 0:
# plot histogram
all_inputs, all_inputs_norm = sess.run([layers_inputs, layers_inputs_norm], feed_dict={xs: x_data, ys: y_data})
plot_his(all_inputs, all_inputs_norm)
# train on batch
sess.run([train_op, train_op_norm], feed_dict={xs: x_data[i*10:i*10+10], ys: y_data[i*10:i*10+10]})
if i % record_step == 0:
# record cost
cost_his.append(sess.run(cost, feed_dict={xs: x_data, ys: y_data}))
cost_his_norm.append(sess.run(cost_norm, feed_dict={xs: x_data, ys: y_data}))
plt.ioff()
plt.figure()
plt.plot(np.arange(len(cost_his))*record_step, np.array(cost_his), label='no BN') # no norm
plt.plot(np.arange(len(cost_his))*record_step, np.array(cost_his_norm), label='BN') # norm
plt.legend()
plt.show()
(1)什么是Bacth Normalization
请参考我制作的 Batch normalization 简介,Batch normalization 是一种解决深度神经网络层数太多, 而没办法有效前向传递(forward propagate)的问题. 因为每一层的输出值都会有不同的 均值(mean) 和 方差(deviation), 所以输出数据的分布也不一样, 如下图, 从左到右是每一层的输入数据分布, 上排的没有 Batch normalization, 下排的有 Batch normalization.

我们以前说过, 为了更有效的学习数据, 我们会对数据预处理, 进行 normalization (请参考我制作的 为什么要特征标准化). 而现在请想象, 我们可以把 每层输出的值 都看成 后面一层所接收的数据. 对每层都进行一次 normalization 会不会更好呢? 这就是 Batch normalization 方法的由来.
(2)搭建网络
输入需要的模块和定义网络的结构
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
ACTIVATION = tf.nn.relu # 每一层都使用 relu
N_LAYERS = 7 # 一共7层隐藏层
N_HIDDEN_UNITS = 30 # 每个层隐藏层有 30 个神经元
使用 build_net() 功能搭建神经网络:
def built_net(xs, ys, norm):
def add_layer(inputs, in_size, out_size, activation_function=None):
# 添加层功能
Weights = tf.Variable(tf.random_normal([in_size, out_size], mean=0., stddev=1.))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs
fix_seed(1)
layers_inputs = [xs] # 记录每层的 input
# loop 建立所有层
for l_n in range(N_LAYERS):
layer_input = layers_inputs[l_n]
in_size = layers_inputs[l_n].get_shape()[1].value
output = add_layer(
layer_input, # input
in_size, # input size
N_HIDDEN_UNITS, # output size
ACTIVATION, # activation function
)
layers_inputs.append(output) # 把 output 加入记录
# 建立 output layer
prediction = add_layer(layers_inputs[-1], 30, 1, activation_function=None)
cost = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction), reduction_indices=[1]))
train_op = tf.train.GradientDescentOptimizer(0.001).minimize(cost)
return [train_op, cost, layers_inputs]
(3)创建数据
创造数据并可视化数据:
x_data = np.linspace(-7, 10, 500)[:, np.newaxis]
noise = np.random.normal(0, 8, x_data.shape)
y_data = np.square(x_data) - 5 + noise
# 可视化 input data
plt.scatter(x_data, y_data)
plt.show()

(4)Bacth Normalization 代码
为了实现 Batch Normalization, 我们要对每一层的代码进行修改, 给 built_net 和 add_layer 都加上 norm 参数, 表示是否是 Batch Normalization 层:
def built_net(xs, ys, norm):
def add_layer(inputs, in_size, out_size, activation_function=None, norm=False):
然后每层的 Wx_plus_b 需要进行一次 batch normalize 的步骤, 这样输出到 activation 的 Wx_plus_b 就已经被 normalize 过了:
if norm: # 判断书否是 BN 层
fc_mean, fc_var = tf.nn.moments(
Wx_plus_b,
axes=[0], # 想要 normalize 的维度, [0] 代表 batch 维度
# 如果是图像数据, 可以传入 [0, 1, 2], 相当于求[batch, height, width] 的均值/方差, 注意不要加入 channel 维度
)
scale = tf.Variable(tf.ones([out_size]))
shift = tf.Variable(tf.zeros([out_size]))
epsilon = 0.001
Wx_plus_b = tf.nn.batch_normalization(Wx_plus_b, fc_mean, fc_var, shift, scale, epsilon)
# 上面那一步, 在做如下事情:
# Wx_plus_b = (Wx_plus_b - fc_mean) / tf.sqrt(fc_var + 0.001)
# Wx_plus_b = Wx_plus_b * scale + shift
# 如果你已经看不懂了, 请去我最上面学习资料里的链接 (我制作的 Batch normalization 简介视频)
如果你是使用 batch 进行每次的更新, 那每个 batch 的 mean/var 都会不同, 所以我们可以使用 moving average 的方法记录并慢慢改进 mean/var 的值. 然后将修改提升后的 mean/var 放入 tf.nn.batch_normalization(). 而且在 test 阶段, 我们就可以直接调用最后一次修改的 mean/var 值进行测试, 而不是采用 test 时的 fcmean/fcvar.
# 对这句进行扩充, 修改前:
Wx_plus_b = tf.nn.batch_normalization(Wx_plus_b, fc_mean, fc_var, shift, scale, epsilon)
# 修改后:
ema = tf.train.ExponentialMovingAverage(decay=0.5) # exponential moving average 的 decay 度
def mean_var_with_update():
ema_apply_op = ema.apply([fc_mean, fc_var])
with tf.control_dependencies([ema_apply_op]):
return tf.identity(fc_mean), tf.identity(fc_var)
mean, var = mean_var_with_update() # 根据新的 batch 数据, 记录并稍微修改之前的 mean/var
# 将修改后的 mean / var 放入下面的公式
Wx_plus_b = tf.nn.batch_normalization(Wx_plus_b, mean, var, shift, scale, epsilon)
那如何确定我们是在 train 阶段还是在 test 阶段呢, 我们可以修改上面的算法, 想办法传入 on_train 参数, 你也可以把 on_train 定义成全局变量. (注意: github 的代码中没有这一段, 想做 test 的同学们需要自己修改)
# 修改前:
mean, var = mean_var_with_update()
# 修改后:
mean, var = tf.cond(on_train, # on_train 的值是 True/False
mean_var_with_update, # 如果是 True, 更新 mean/var
lambda: ( # 如果是 False, 返回之前 fc_mean/fc_var 的Moving Average
ema.average(fc_mean),
ema.average(fc_var)
)
)
同样, 我们也可以在输入数据 xs 时, 给它做一个 normalization, 同样, 如果是最 batch data 来训练的话, 要重复上述的记录修改 mean/var 的步骤:
if norm:
# BN for the first input
fc_mean, fc_var = tf.nn.moments(
xs,
axes=[0],
)
scale = tf.Variable(tf.ones([1]))
shift = tf.Variable(tf.zeros([1]))
epsilon = 0.001
xs = tf.nn.batch_normalization(xs, fc_mean, fc_var, shift, scale, epsilon)
然后我们把在建立网络的循环中的这一步加入 norm 这个参数:
output = add_layer(
layer_input, # input
in_size, # input size
N_HIDDEN_UNITS, # output size
ACTIVATION, # activation function
norm, # normalize before activation
)
(5)对比有无BN
搭建两个神经网络, 一个没有 BN, 一个有 BN:
xs = tf.placeholder(tf.float32, [None, 1]) # [num_samples, num_features]
ys = tf.placeholder(tf.float32, [None, 1])
train_op, cost, layers_inputs = built_net(xs, ys, norm=False) # without BN
train_op_norm, cost_norm, layers_inputs_norm = built_net(xs, ys, norm=True) # with BN
训练神经网络:
代码中的 plot_his() 不会在这里讲解, 请自己在全套代码中查看.
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# 记录两种网络的 cost 变化
cost_his = []
cost_his_norm = []
record_step = 5
plt.ion()
plt.figure(figsize=(7, 3))
for i in range(251):
if i % 50 == 0:
# 每层在 activation 之前计算结果值的分布
all_inputs, all_inputs_norm = sess.run([layers_inputs, layers_inputs_norm], feed_dict={xs: x_data, ys: y_data})
plot_his(all_inputs, all_inputs_norm)
sess.run(train_op, feed_dict={xs: x_data, ys: y_data})
sess.run(train_op_norm, feed_dict={xs: x_data, ys: y_data})
if i % record_step == 0:
# 记录 cost
cost_his.append(sess.run(cost, feed_dict={xs: x_data, ys: y_data}))
cost_his_norm.append(sess.run(cost_norm, feed_dict={xs: x_data, ys: y_data}))
plt.ioff()
plt.figure()
plt.plot(np.arange(len(cost_his))*record_step, np.array(cost_his), label='no BN') # no norm
plt.plot(np.arange(len(cost_his))*record_step, np.array(cost_his_norm), label='BN') # norm
plt.legend()
plt.show()
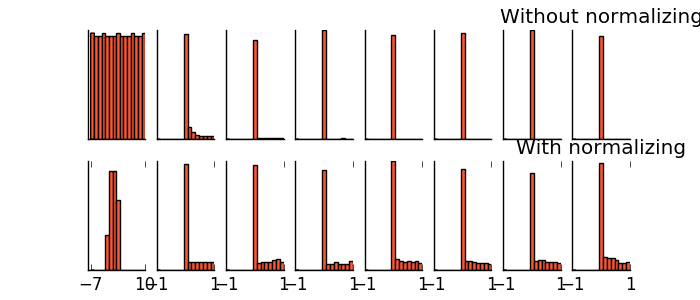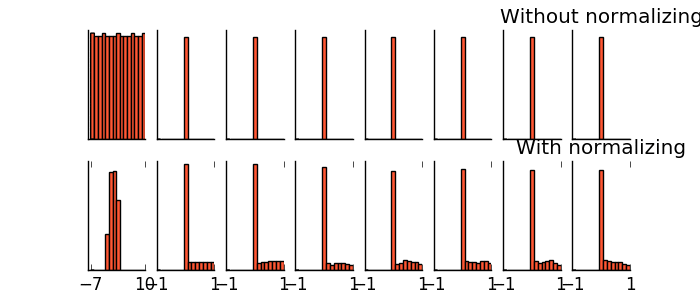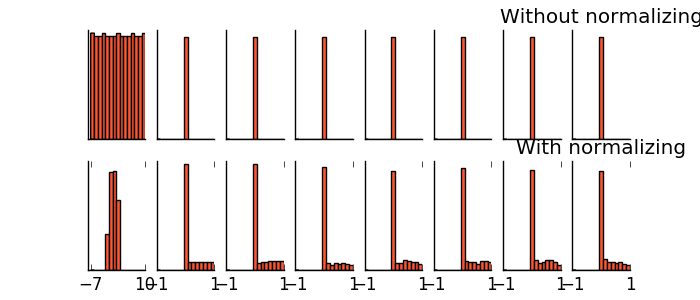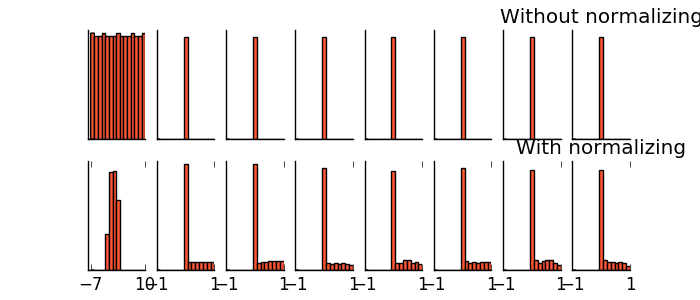
可以看出, 没有用 BN 的时候, 每层的值迅速全部都变为 0, 也可以说, 所有的神经元都已经死了. 而有 BN, relu 过后, 每层的值都能有一个比较好的分布效果, 大部分神经元都还活着. (看不懂了? 没问题, 再去看一遍我制作的 Batch normalization 简介视频).
Relu 激励函数的图在这里:

我们也看看使用 relu cost 的对比:

因为没有使用 NB 的网络, 大部分神经元都死了, 所以连误差曲线都没了.
如果使用不同的 ACTIVATION 会怎么样呢? 不如把 relu 换成 tanh:
ACTIVATION = tf.nn.tanh

可以看出, 没有 NB, 每层的值迅速全部都饱和, 都跑去了 -1/1 这个饱和区间, 有 NB, 即使前一层因变得相对饱和, 但是后面几层的值都被 normalize 到有效的不饱和区间内计算. 确保了一个活的神经网络.
tanh 激励函数的图在这里:

最后我们看一下使用 tanh 的误差对比:

5.20 Tensorflow 2017更新
- 高级方便的功能
(1)高级方便的功能
github 当中的 2017 Tensorflow , 里面汇总了所有之前教学视频的内容, 但是是以更简单, 更精辟的代码结构.
比如:
tf.layers
tf.losses
要提到的一点, Tensorflow 为了实现很多功能, 它已经变得越来越臃肿. 而且亲身试验, 在 RNN 方面, 貌似 pytorch 要比 Tensorflow 快一点. 所以你可以根据自己的需要来调整使用的模块, 如果对 Pytorch 感兴趣的话, 我也有一个 Pytorch 教程.
5.21 用Tensorflow可视化梯度下降
- 要点
- 普通的梯度下降
- 为模型,公式调参
- 局部最优,全局最优
相关代码:
"""
Know more, visit my Python tutorial page: https://morvanzhou.github.io/tutorials/
My Youtube Channel: https://www.youtube.com/user/MorvanZhou
Dependencies:
tensorflow: 1.1.0
matplotlib
numpy
"""
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
LR = 0.1
REAL_PARAMS = [1.2, 2.5]
INIT_PARAMS = [[5, 4],
[5, 1],
[2, 4.5]][2]
x = np.linspace(-1, 1, 200, dtype=np.float32) # x data
# Test (1): Visualize a simple linear function with two parameters,
# you can change LR to 1 to see the different pattern in gradient descent.
# y_fun = lambda a, b: a * x + b
# tf_y_fun = lambda a, b: a * x + b
# Test (2): Using Tensorflow as a calibrating tool for empirical formula like following.
# y_fun = lambda a, b: a * x**3 + b * x**2
# tf_y_fun = lambda a, b: a * x**3 + b * x**2
# Test (3): Most simplest two parameters and two layers Neural Net, and their local & global minimum,
# you can try different INIT_PARAMS set to visualize the gradient descent.
y_fun = lambda a, b: np.sin(b*np.cos(a*x))
tf_y_fun = lambda a, b: tf.sin(b*tf.cos(a*x))
noise = np.random.randn(200)/10
y = y_fun(*REAL_PARAMS) + noise # target
# tensorflow graph
a, b = [tf.Variable(initial_value=p, dtype=tf.float32) for p in INIT_PARAMS]
pred = tf_y_fun(a, b)
mse = tf.reduce_mean(tf.square(y-pred))
train_op = tf.train.GradientDescentOptimizer(LR).minimize(mse)
a_list, b_list, cost_list = [], [], []
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for t in range(400):
a_, b_, mse_ = sess.run([a, b, mse])
a_list.append(a_); b_list.append(b_); cost_list.append(mse_) # record parameter changes
result, _ = sess.run([pred, train_op]) # training
# visualization codes:
print('a=', a_, 'b=', b_)
plt.figure(1)
plt.scatter(x, y, c='b') # plot data
plt.plot(x, result, 'r-', lw=2) # plot line fitting
# 3D cost figure
fig = plt.figure(2); ax = Axes3D(fig)
a3D, b3D = np.meshgrid(np.linspace(-2, 7, 30), np.linspace(-2, 7, 30)) # parameter space
cost3D = np.array([np.mean(np.square(y_fun(a_, b_) - y)) for a_, b_ in zip(a3D.flatten(), b3D.flatten())]).reshape(a3D.shape)
ax.plot_surface(a3D, b3D, cost3D, rstride=1, cstride=1, cmap=plt.get_cmap('rainbow'), alpha=0.5)
ax.scatter(a_list[0], b_list[0], zs=cost_list[0], s=300, c='r') # initial parameter place
ax.set_xlabel('a'); ax.set_ylabel('b')
ax.plot(a_list, b_list, zs=cost_list, zdir='z', c='r', lw=3) # plot 3D gradient descent
plt.show()
(1)要点
这一次, 我们想要真正意义上的看到自己手中的模型是怎么样进行梯度下降 (gradient descent) 的. 打个比方就像下面这张图. 红色圆点就是最开始的参数误差.

同时, 我们还可以扩展开来, 神经网络就是一种梯度下降的方法. 而梯度下降是一种最优化方法, 我们还能拿它来干点其它事. 比如说 为公式调参. 我们会在下面具体讲解.
接着我们还会提到在梯度下降中, 以及神经网络中很难避免的一种现象, 叫做局部最优, 以及局部最优的影响.
(2)普通的梯度下降
这次我们还是以代码的形式直观地展示我们要做的事情. 为了可视化梯度下降的过程, 我们需要用到 Python 中的几个模块, matplotlib, numpy, tensorflow. 如果对画图感兴趣的朋友们, 可以来看看我的 python 画图教程.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 画 3D 图的功能
LR = .1 # 神经网络的学习率
REAL_PARAMS = [1.2, 2.5] # 我们假设的需要被学习的真实参数
INIT_PARAMS = [[5, 4], # 在调参中不同初始化的参数点
[5, 1],
[2, 4.5]][0]
x = np.linspace(-1, 1, 200, dtype=np.float32) # x 数据
我们需要用 tensorflow 来帮我们梯度下降, 我们需要规定的就是最开始从哪里开始梯度下降, 这就是 INIT_PARAMS 的作用了. 我们会在之后的内容中尝试上面不同的初始化地点, 然后看看会有什么样的效果. 同时我们也会看看不同学习效率 LR 对模型学习的影响.
# test 1
y_fun = lambda a, b: a * x + b
tf_y_fun = lambda a, b: a * x + b
接着我们开始定义第一轮测试的公式. 假设我们要来拟合公式 a*x+b 中的参数 a 和 b, 我们就用 python 中的 lambda 来定义一个方程 y_fun. y_fun 的输入就是不同参数 a b 的值, 和 我们之前定义的数据 x, 输出 y 值. 这里的 tf_y_fun 是传给 tensorflow 去优化的方程. y_fun 是用来可视化和计算真是 y 用的.
noise = np.random.randn(200)/10
y = y_fun(*REAL_PARAMS) + noise # target
所以我们就能用 y_fun 来输出 正是 y数据. 当然为了看起来真实点, 我们还加了些随机噪点.
# tensorflow 计算优化图
a, b = [tf.Variable(initial_value=p, dtype=tf.float32) for p in INIT_PARAMS]
pred = tf_y_fun(a, b)
mse = tf.reduce_mean(tf.square(y-pred))
train_op = tf.train.GradientDescentOptimizer(LR).minimize(mse)
接着我们就来定义 Tensorflow 的计算优化图纸. 定义两个参数 a, b 并给他们初始化成我们最开始假设的初始化值 INIT_PARAMS. 然后预测, 然后算误差, 最后优化.
a_list, b_list, cost_list = [], [], []
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for t in range(400):
a_, b_, mse_ = sess.run([a, b, mse])
a_list.append(a_); b_list.append(b_); cost_list.append(mse_) # record parameter changes
result, _ = sess.run([pred, train_op]) # training
接着我们就开始训练, 并时刻记录训练时的 a,b 参数 以及 误差 变化.
最后可视化他们, 因为可视化代码不是重点, 所以想仔细看代码的朋友, 欢迎来我的 Github 中看全套代码.
首先我们先看看训练出来的预测线和数据的拟合度吧:

看起来非常完美, 成功的用一条直线预测出了规律. 那我们看看梯度下降的 3D 图,

看上去他从最开始的红点, 很顺利的滑落到了误差最小的地方. 梯度下降圆满完成.
如果我们来尝试不同的学习效率呢, 比如调整最开始的 LR=1, 就会发生下面这样的事.

貌似这时的梯度下降变得纠结起来, 梯度下不去了. 原来这就是因为学习效率过大的原因, 导致虽然学得快, 但是没办法收敛. 我们也能从学习到的预测线看出来这样的现象, 现在下面的预测线没有办法预测出真实数据了. 所以切记, 当你的模型没办法收敛的时候, 试试调低学习率.

(3)为模型,公式调参
接下来我们看看 Tensorflow 的另一种用途, 为公式调参. 说到底, 神经网络就是用梯度下降, 而梯度下降就是一种优化模式 具体参考我制作的这个短视频. 所以我们也可以使用 Tensorflow 的梯度下降机制来调参. 比如我们将上面的提到的 y_fun 和 tf_y_fun 改成下面这样 (其实上面也是在调参).
# test 2
y_fun = lambda a, b: a * x**3 + b * x**2
tf_y_fun = lambda a, b: a * x**3 + b * x**2
现在有点像一个经验公式了吧. 其实很多时候, 人们总结出来的经验公式其实是很有用的, 我们没必要大费周章来使用神经网络处理所有问题, 首先遇到一个问题, 你要想的是, 在这个问题中, 是否以前有人提出过什么经验公式的, 那我来对这个经验公式调调参. 这可比神经网络方便多了. 而且梯度下降调参只是调参中的一种方式, 还有很多种调参方式, 具体可以看看和使用 python 的另一个模块 scipy 中的 optimization 链接.
好了, 如果你决定用梯度下降调参, 这份代码就是一种途径. 代码的其他部分不用过多更改. 我们直接来看效果吧. 首先看看数据点和拟合参数a, b 后的曲线.

再来看看之前的梯度下降图:

(4)局部最优,全局最优
在回到神经网络的话题中来, 多层的有激活神经网络必定有很多局部最优解的. 我在这个短视频中也提过什么是全局最优和局部最优. 那么我们就来做一个有两个参数的简单神经网络吧. 同样, 我们至于要修改 y_fun 和 tf_y_fun 就好了:
# test 3
y_fun = lambda a, b: np.sin(b*np.cos(a*x))
tf_y_fun = lambda a, b: tf.sin(b*tf.cos(a*x))
想象 np.cos(ax) 是有激活的一层神经层, np.sin(blast_layer) 是有激活的第二层. 那么这个方程就是最简单的一种两层神经网络了. 如果使用的初始参数点是 INIT_PARAMS=[2, 4.5] 他的数据点和拟合曲线是下面这样:

他的梯度下降空间就是我们最开始看到的那个.

从初始的 INIT_PARAMS=[2, 4.5] 这个点开始梯度下降, 我们就能成功的找到接近全局最优的 a=1.2; b=2.5, 但是这个3D 图上有很多局部最优点, 如果我们换一个初始参数位置, 比如 INIT_PARAMS=[5, 1]. 那么就会下降到一个最靠近他的局部最优.

这样, 我们的模型就只能止步在这, 而且并不能继续向前拟合数据点了. 所以可以看出参数的初始化位置的确很重要.

通常, 在初始化神经网络的参数时, 我们可以用到 Normal distribution 等方式, 并且多做几次初始化实验, 看看效果如何. 运气好的时候, 初始化很成功, 带来的比较好的局部最优, 运气不好的时候… 你懂的… 继续做实验吧.
5.22 什么是迁移学习 Transfer Learning
- 机器学习发展
- 怎么迁移
- 还能怎么玩
你会发现聪明人都喜欢”偷懒”, 因为这样的偷懒能帮我们节省大量的时间, 提高效率. 还有一种偷懒是 “站在巨人的肩膀上”. 不仅能看得更远, 还能看到更多. 这也用来表达我们要善于学习先辈的经验, 一个人的成功往往还取决于先辈们累积的知识. 这句话, 放在机器学习中, 这就是今天要说的迁移学习了, transfer learning.

(1)机器学习发展

现在的机器人视觉已经非常先进了, 有些甚至超过了人类. 99.99%的识别准确率都不在话下. 这样的成功, 依赖于强大的机器学习技术, 其中, 神经网络成为了领军人物. 而 CNN 等, 像人一样拥有千千万万个神经联结的结构, 为这种成功贡献了巨大力量. 但是为了更厉害的 CNN, 我们的神经网络设计, 也从简单的几层网络, 变得越来越多, 越来越多, 越来越多… 为什么会越来越多?
因为计算机硬件, 比如 GPU 变得越来越强大, 能够更快速地处理庞大的信息. 在同样的时间内, 机器能学到更多东西. 可是, 不是所有人都拥有这么庞大的计算能力. 而且有时候面对类似的任务时, 我们希望能够借鉴已有的资源.
(2)怎么迁移

这就好比, Google 和百度的关系, facebook 和人人的关系, KFC 和 麦当劳的关系, 同一类型的事业, 不用自己完全从头做, 借鉴对方的经验, 往往能节省很多时间. 有这样的思路, 我们也能偷偷懒, 不用花时间重新训练一个无比庞大的神经网络, 借鉴借鉴一个已经训练好的神经网络就行.

比如这样的一个神经网络, 我花了两天训练完之后, 它已经能正确区分图片中具体描述的是男人, 女人还是眼镜. 说明这个神经网络已经具备对图片信息一定的理解能力. 这些理解能力就以参数的形式存放在每一个神经节点中. 不巧, 领导下达了一个紧急任务,

要求今天之内训练出来一个预测图片里实物价值的模型. 我想这可完蛋了, 上一个图片模型都要花两天, 如果要再搭个模型重新训练, 今天肯定出不来呀. #这时, 迁移学习来拯救我了. 因为这个训练好的模型中已经有了一些对图片的理解能力, 而模型最后输出层的作用是分类之前的图片, 对于现在计算价值的任务是用不到的, #所以我将最后一层替换掉, 变为服务于现在这个任务的输出层. #接着只训练新加的输出层, 让理解力保持始终不变. 前面的神经层庞大的参数不用再训练, 节省了我很多时间, 我也在一天时间内, 将这个任务顺利完成.
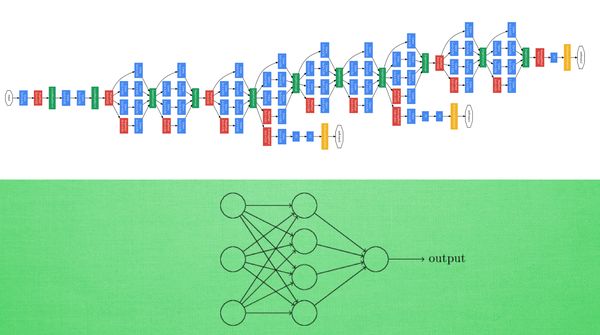
但并不是所有时候我们都需要迁移学习. 比如神经网络很简单, 相比起计算机视觉中庞大的 CNN 或者语音识别的 RNN, 训练小的神经网络并不需要特别多的时间, 我们完全可以直接重头开始训练. 从头开始训练也是有好处的.

如果固定住之前的理解力, 或者使用更小的学习率来更新借鉴来的模型, 就变得有点像认识一个人时的第一印象, 如果迁移前的数据和迁移后的数据差距很大, 或者说我对于这个人的第一印象和后续印象差距很大, 我还不如不要管我的第一印象, 同理, 这时, 迁移来的模型并不会起多大作用, 还可能干扰我后续的决策.
(3)还能怎么玩

了解了一般的迁移学习玩法后, 我们看看前辈们还有哪些新玩法. 多任务学习, 或者强化学习中的 learning to learn, 迁移机器人对运作形式的理解, 解决不同的任务. 炒个蔬菜, 红烧肉, 番茄蛋花汤虽然菜色不同, 但是做菜的原则是类似的.
又或者 google 的翻译模型, 在某些语言上训练, 产生出对语言的理解模型, 将这个理解模型当做迁移模型在另外的语言上训练. 其实说白了, 那个迁移的模型就能看成机器自己发明的一种只有它自己才能看懂的语言. 然后用自己的这个语言模型当成翻译中转站, 将某种语言转成自己的语言, 然后再翻译成另外的语言. 迁移学习的脑洞还有很多, 相信这种站在巨人肩膀上继续学习的方法, 还会带来更多有趣的应用.
5.23 迁移学习 Transfer Learning
- 下载数据
- 迁移VGG
- 训练
- 测试
相关代码:
"""
This is a simple example of transfer learning using VGG.
Fine tune a CNN from a classifier to regressor.
Generate some fake data for describing cat and tiger length.
Fake length setting:
Cat - Normal distribution (40, 8)
Tiger - Normal distribution (100, 30)
The VGG model and parameters are adopted from:
https://github.com/machrisaa/tensorflow-vgg
Learn more, visit my tutorial site: [莫烦Python](https://morvanzhou.github.io)
"""
from urllib.request import urlretrieve
import os
import numpy as np
import tensorflow as tf
import skimage.io
import skimage.transform
import matplotlib.pyplot as plt
def download(): # download tiger and kittycat image
categories = ['tiger', 'kittycat']
for category in categories:
os.makedirs('./for_transfer_learning/data/%s' % category, exist_ok=True)
with open('./for_transfer_learning/imagenet_%s.txt' % category, 'r') as file:
urls = file.readlines()
n_urls = len(urls)
for i, url in enumerate(urls):
try:
urlretrieve(url.strip(), './for_transfer_learning/data/%s/%s' % (category, url.strip().split('/')[-1]))
print('%s %i/%i' % (category, i, n_urls))
except:
print('%s %i/%i' % (category, i, n_urls), 'no image')
def load_img(path):
img = skimage.io.imread(path)
img = img / 255.0
# print "Original Image Shape: ", img.shape
# we crop image from center
short_edge = min(img.shape[:2])
yy = int((img.shape[0] - short_edge) / 2)
xx = int((img.shape[1] - short_edge) / 2)
crop_img = img[yy: yy + short_edge, xx: xx + short_edge]
# resize to 224, 224
resized_img = skimage.transform.resize(crop_img, (224, 224))[None, :, :, :] # shape [1, 224, 224, 3]
return resized_img
def load_data():
imgs = {'tiger': [], 'kittycat': []}
for k in imgs.keys():
dir = './for_transfer_learning/data/' + k
for file in os.listdir(dir):
if not file.lower().endswith('.jpg'):
continue
try:
resized_img = load_img(os.path.join(dir, file))
except OSError:
continue
imgs[k].append(resized_img) # [1, height, width, depth] * n
if len(imgs[k]) == 400: # only use 400 imgs to reduce my memory load
break
# fake length data for tiger and cat
tigers_y = np.maximum(20, np.random.randn(len(imgs['tiger']), 1) * 30 + 100)
cat_y = np.maximum(10, np.random.randn(len(imgs['kittycat']), 1) * 8 + 40)
return imgs['tiger'], imgs['kittycat'], tigers_y, cat_y
class Vgg16:
vgg_mean = [103.939, 116.779, 123.68]
def __init__(self, vgg16_npy_path=None, restore_from=None):
# pre-trained parameters
try:
self.data_dict = np.load(vgg16_npy_path, encoding='latin1').item()
except FileNotFoundError:
print('Please download VGG16 parameters from here https://mega.nz/#!YU1FWJrA!O1ywiCS2IiOlUCtCpI6HTJOMrneN-Qdv3ywQP5poecM\nOr from my Baidu Cloud: https://pan.baidu.com/s/1Spps1Wy0bvrQHH2IMkRfpg')
self.tfx = tf.placeholder(tf.float32, [None, 224, 224, 3])
self.tfy = tf.placeholder(tf.float32, [None, 1])
# Convert RGB to BGR
red, green, blue = tf.split(axis=3, num_or_size_splits=3, value=self.tfx * 255.0)
bgr = tf.concat(axis=3, values=[
blue - self.vgg_mean[0],
green - self.vgg_mean[1],
red - self.vgg_mean[2],
])
# pre-trained VGG layers are fixed in fine-tune
conv1_1 = self.conv_layer(bgr, "conv1_1")
conv1_2 = self.conv_layer(conv1_1, "conv1_2")
pool1 = self.max_pool(conv1_2, 'pool1')
conv2_1 = self.conv_layer(pool1, "conv2_1")
conv2_2 = self.conv_layer(conv2_1, "conv2_2")
pool2 = self.max_pool(conv2_2, 'pool2')
conv3_1 = self.conv_layer(pool2, "conv3_1")
conv3_2 = self.conv_layer(conv3_1, "conv3_2")
conv3_3 = self.conv_layer(conv3_2, "conv3_3")
pool3 = self.max_pool(conv3_3, 'pool3')
conv4_1 = self.conv_layer(pool3, "conv4_1")
conv4_2 = self.conv_layer(conv4_1, "conv4_2")
conv4_3 = self.conv_layer(conv4_2, "conv4_3")
pool4 = self.max_pool(conv4_3, 'pool4')
conv5_1 = self.conv_layer(pool4, "conv5_1")
conv5_2 = self.conv_layer(conv5_1, "conv5_2")
conv5_3 = self.conv_layer(conv5_2, "conv5_3")
pool5 = self.max_pool(conv5_3, 'pool5')
# detach original VGG fc layers and
# reconstruct your own fc layers serve for your own purpose
self.flatten = tf.reshape(pool5, [-1, 7*7*512])
self.fc6 = tf.layers.dense(self.flatten, 256, tf.nn.relu, name='fc6')
self.out = tf.layers.dense(self.fc6, 1, name='out')
self.sess = tf.Session()
if restore_from:
saver = tf.train.Saver()
saver.restore(self.sess, restore_from)
else: # training graph
self.loss = tf.losses.mean_squared_error(labels=self.tfy, predictions=self.out)
self.train_op = tf.train.RMSPropOptimizer(0.001).minimize(self.loss)
self.sess.run(tf.global_variables_initializer())
def max_pool(self, bottom, name):
return tf.nn.max_pool(bottom, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name=name)
def conv_layer(self, bottom, name):
with tf.variable_scope(name): # CNN's filter is constant, NOT Variable that can be trained
conv = tf.nn.conv2d(bottom, self.data_dict[name][0], [1, 1, 1, 1], padding='SAME')
lout = tf.nn.relu(tf.nn.bias_add(conv, self.data_dict[name][1]))
return lout
def train(self, x, y):
loss, _ = self.sess.run([self.loss, self.train_op], {self.tfx: x, self.tfy: y})
return loss
def predict(self, paths):
fig, axs = plt.subplots(1, 2)
for i, path in enumerate(paths):
x = load_img(path)
length = self.sess.run(self.out, {self.tfx: x})
axs[i].imshow(x[0])
axs[i].set_title('Len: %.1f cm' % length)
axs[i].set_xticks(()); axs[i].set_yticks(())
plt.show()
def save(self, path='./for_transfer_learning/model/transfer_learn'):
saver = tf.train.Saver()
saver.save(self.sess, path, write_meta_graph=False)
def train():
tigers_x, cats_x, tigers_y, cats_y = load_data()
# plot fake length distribution
plt.hist(tigers_y, bins=20, label='Tigers')
plt.hist(cats_y, bins=10, label='Cats')
plt.legend()
plt.xlabel('length')
plt.show()
xs = np.concatenate(tigers_x + cats_x, axis=0)
ys = np.concatenate((tigers_y, cats_y), axis=0)
vgg = Vgg16(vgg16_npy_path='./for_transfer_learning/vgg16.npy')
print('Net built')
for i in range(100):
b_idx = np.random.randint(0, len(xs), 6)
train_loss = vgg.train(xs[b_idx], ys[b_idx])
print(i, 'train loss: ', train_loss)
vgg.save('./for_transfer_learning/model/transfer_learn') # save learned fc layers
def eval():
vgg = Vgg16(vgg16_npy_path='./for_transfer_learning/vgg16.npy',
restore_from='./for_transfer_learning/model/transfer_learn')
vgg.predict(
['./for_transfer_learning/data/kittycat/000129037.jpg', './for_transfer_learning/data/tiger/391412.jpg'])
if __name__ == '__main__':
# download()
# train()
eval()
在上次的动画简介中, 我们大概了解了一些迁移学习的原理和为什么要使用迁移学习. 如果用一句话来概括迁移学习, 那务必就是: 为了偷懒, 在训练好了的模型上接着训练其他内容, 充分使用原模型的理解力. 有时候也是为了避免再次花费特别长的时间重复训练大型模型.

CNN 通常都是大型模型, 下面我们拿 CNN 来举个例子. 我训练好了一个区分男人和女人的 CNN. 接着来了个任务, 说我下个任务是区分照片中人的年龄. 这看似完全不相干的两个模型, 但是我们却可以运用到迁移学习, 让之前那个 CNN 当我们的初始模型, 因为区分男女的 CNN 已经对人类有了理解. 基于这个理解开始训练, 总比完全重新开始训练强. 但是如果你下一个任务是区分飞机和大象. 这个 CNN 可能就没那么有用了, 因为这个 CNN 可能并没有对飞机大象有任何的理解.
这一次, 我们就来迁移一个图片分类的 CNN (VGG). 这个 VGG 在1000个类别中训练过. 我们提取这个 VGG 前面的 Conv layers, 重新组建后面的 fully connected layers, 让它做一个和分类完全不相干的事. 我们在网上下载那1000个分类数据中的猫和老虎的图片, 然后伪造一些猫和老虎长度的数据. 最后做到让迁移后的网络分辨出猫和老虎的长度 (regressor).
(1)下载数据
为了达到这次的目的, 我们不需要下载所有的1000个分类的所有图片, 只要找到自己感兴趣的类就好 (老虎和猫). 我选老虎和猫的目的就是因为他们是近亲, 还是有点像的, 可以增加点难度. 如果是飞机和大象的话, 学习难度就被降低了.

上图是这个网址, 你能在 Download 的那个 tag 中, 找到所有图片的 urls, 我将所有老虎和猫的 urls 文件给大家放在下面:
老虎 Tiger: imagenet_tiger.txt
猫 Kitty cat: imagenet_kittycat.txt
我们可以编一个 Python功能 逐个下载里面的图片. 这个功能我定义成 download(). 下载好后就会被放在 data 这个文件夹中了.

因为有些图片url已经过期了, 所以我自己也手动过滤了一遍, 将不是图片的和404的图片给清理掉了. 因为只有两个类, 图片不是很多, 比较好清理. 有网友说一些很多链接和图片已经失联, 我把我收集到的图片数据打包放在我的百度云, 如果用代码下图片感到有困难的同学们, 请直接在我百度云下载吧.
因为现在我们不是预测分类结果了, 所以我伪造了一些体长的数据. 老虎通常要比猫长, 所以它们的 distribution 就差不多是下面这种结构(单位cm).

(2)迁移VGG
处理好图片后, 我们可以开始弄 VGG 的 pre-trained model. 我使用的是machrisaa 改写的 VGG16 的代码. 和他提供的 VGG16 train 好了的 model parameters, 你可以在这里下载 这些 parameters (有网友说这个文件下载不了,我把它放在了百度云共享了). 做好准备, 这个 parameter 文件有500+MB. 可见一般 CNN 的 model 有多大.

为了做迁移学习, 我对他的 tensorflow VGG16 代码进行了改写. 保留了所有 Conv 和 pooling 层, 将后面的所有 fc 层拆了, 改成可以被 train 的两层, 输出一个数字, 这个数字代表了这只猫或老虎的长度.
class Vgg16:
def __init__():
# ...前面的层
pool5 = self.max_pool(conv5_3, 'pool5')
# pool5 是最后的 conv 出来的结果
self.flatten = tf.reshape(pool5, [-1, 7*7*512])
self.fc6 = tf.layers.dense(self.flatten, 256, tf.nn.relu, name='fc6')
self.out = tf.layers.dense(self.fc6, 1, name='out')
在 self.flatten 之前的 layers, 都是不能被 train 的. 而 tf.layers.dense() 建立的 layers 是可以被 train 的. 到时候我们 train 好了, 再定义一个 Saver 来保存由 tf.layers.dense() 建立的 parameters.
class Vgg16:
...
def save(self, path='./for_transfer_learning/model/transfer_learn'):
saver = tf.train.Saver()
saver.save(self.sess, path, write_meta_graph=False)
(3)训练
因为有了训练好了的 VGG16, 你就能将 VGG16 的 Conv 层想象成是一个 feature extractor, 提取或压缩图片中的特征. 和 Autoencoder 中的 encoder 类似. 用这些提取的特征来训练后面的 regressor. 具体代码在这, 下面是简写版.
def train():
xs, ys = ...
vgg = Vgg16(vgg16_npy_path='./for_transfer_learning/vgg16.npy')
print('Net built')
for i in range(100):
b_idx = np.random.randint(0, len(xs), 6)
train_loss = vgg.train(xs[b_idx], ys[b_idx])
print(i, 'train loss: ', train_loss)
vgg.save('./for_transfer_learning/model/transfer_learn')
这里我只 train 了 100次, 如果是重新开始 train 一个 CNN, 100次绝对少了. 而且我使用的是只有 CPU 的电脑, 不好意思, 我暂时没有合适的 GPU… 所以你暂时在 莫烦Python 中基本找不到关于图像处理的教程… 不过! 正因为 transfer learning 让我不用从头 train CNN, 所以我做了这个教程! 否则, 我想用我的 CPU, 估计得一周才能 train 出来这个 VGG 吧.
(4)测试
我们现在已经迁移好了, train 好了后面的 fc layers, 也保存了后面的 fc 参数. 接着我们提取原始的 VGG16 前半部分参数和 train 好的后半部分参数. 进行测试.
def eval():
vgg = Vgg16(vgg16_npy_path='./for_transfer_learning/vgg16.npy',
restore_from='./for_transfer_learning/model/transfer_learn')
vgg.predict(
['./for_transfer_learning/data/kittycat/000129037.jpg',
'./for_transfer_learning/data/tiger/391412.jpg'])
我输入了一张猫, 一张老虎的图, 这个 VGG 给我预测除了他们的长度.

可以想象, 要让 VGG 达到这个目的, VGG必须懂得区分哪些是猫, 哪些是老虎, 而这个认知, 在原始的 VGG conv 层中就已经学出来了. 所以如果我们拆了后面的层, 将后面的 classifier 变成 regressor, 花费相当少的时间就能训练好.
作者:Mamba_BingshengTian