Apache 辅助系统工具
一丶Apache Sqoop
1.Sqoop的介绍:
Sqoop的工作机制是将导入或者导出的命令翻译成MapReduce实现,Sqoop可以理解为:SQL到Hadoop或者Hadoop到SQL
2.Sqoop的安装
配置文件修改:
cd $SQOOP_HOME/conf
mv sqoop-env-template.sh sqoop-env.sh
vi sqoop-env.sh
export HADOOP_COMMON_HOME= /export/servers/hadoop-2.7.5
export HADOOP_MAPRED_HOME= /export/servers/hadoop-2.7.5
export HIVE_HOME= /export/servers/hive
加入 mysql 的 jdbc 驱动包
cp /hive/lib/mysql-connector-java-5.1.32.jar $SQOOP_HOME/lib/
验证启动
注意,sqoop验证的命令必须要在一行写完,此处我使用了\来表示一行
bin/sqoop list-databases \
--connect jdbc:mysql://localhost:3306/ \
--username root --password hadoop
本命令会列出所有 mysql 的数据库。
到这里,整个 Sqoop 安装工作完成。
3.Sqoop导入
1.全量导入数据到hdfs
- mysql的地址尽量不要使用localhost 请使用ip或host
- 如果不指定导入到hdfs的分隔符是“,”
- 可以通过-fields-teminated-by '\t'指定分隔符
- 如果表的数据比较大 可以并行启动多个maptask执行导入操作,如果表没有主键,需要指定根据哪个字段进行切分
bin/sqoop import \ --connect jdbc:mysql://node03:3306/userdb \ --username root \ --password 123456 \ --target-dir /sqoopresult214 \ --fields-terminated-by '\t' \ --split-by id \ --table emp --m 2
2.导入表数据子集(query查询)
使用 query sql 语句来进行查找不能加参数--table ; 并且必须要添加 where 条件; 并且 where 条件后面必须带一个$CONDITIONS 这个字符串; 并且这个 sql 语句必须用单引号,不能用双引号;
3.增量数据的导入
所谓的增量数据指的是上次至今中间新增加的数据
sqoop支持两种模式的增量导入
- append追加 根据数值类型字段进行追加导入 大于指定的last-value
- lastmodified 根据时间戳类型字段进行追加 大于等于指定的last-value
- 注意在lastmodified 模式下 还分为两种情形:append merge-key
关于lastmodified 中的两种模式:
- append 只会追加增量数据到一个新的文件中 并且会产生数据的重复问题,因为默认是从指定的last-value 大于等于其值的数据开始导入
- merge-key 把增量的数据合并到一个文件中 处理追加增量数据之外 如果之前的数据有变化修改,也可以进行修改操作 底层相当于进行了一次完整的mr作业。数据不会重复。
4.数据导出操作
注意:导出的目标表需要自己手动提前创建 也就是sqoop并不会帮我们创建复制表结构
导出有三种模式:
- 默认模式 目标表是空表 底层把数据一条条insert进去
- 更新模式 底层是update语句
- 调用模式 调用存储过程
相关配置参数:
- 导出文件的分隔符 如果不指定 默认以“,”去切割读取数据文件 --input-fields-terminated-by
- 如果文件的字段顺序和表中顺序不一致 需要--columns 指定 多个字段之间以","
- 导出的时候需要指定导出数据的目的 export-dir 和导出到目标的表名或者存储过程名
- 针对空字符串类型和非字符串类型的转换 “\n”
5.更新导出
updateonly 只更新已经存在的数据 不会执行insert增加新的数据
allowinsert 更新已有的数据 插入新的数据 底层相当于insert&update
4.sqoop的job作业操作
1.创建作业(--create)
在这里,我们创建一个名为myjob,这可以从RDBMS表的数据导入到HDFS作业。下面的命令用于创建一个从DB数据库的employee表导入到HDFS文件的作业。
bin/sqoop job --create itcastjob1 -- import --connect jdbc:mysql://node-1:3306/userdb \
--username root \
--password hadoop \
--target-dir /sqoopresult555 \
--table emp --m 1
注意import前要有空格
2.查看作业列表 (--list)
‘--list’ 参数是用来验证保存的作业。下面的命令用来验证保存Sqoop作业的列表。
bin/sqoop job --list
它显示了保存作业列表。
Available jobs: myjob
3.查看作业内容(--show)
‘--show’ 参数用于检查或验证特定的工作,及其详细信息。以下命令和样本输出用来验证一个名为myjob的作业。
bin/sqoop job --show myjob
它显示了工具和它们的选择,这是使用在myjob中作业情况。
Job: myjob Tool: import Options: ---------------------------- direct.import = true codegen.input.delimiters.record = 0 hdfs.append.dir = false db.table = employee ... incremental.last.value = 1206 ...
4.删除作业 (--exec)
bin/sqoop job --delete jobname
5.执行作业 (--exec)
‘--exec’ 选项用于执行保存的作业。下面的命令用于执行保存的作业称为myjob。
bin/sqoop job --exec myjob sqoop需要输入mysql密码 它会显示下面的输出。
10/08/19 13:08:45 INFO tool.CodeGenTool: Beginning code generation ...
6.job的免密输入
sqoop在创建job时,使用--password-file参数,可以避免输入mysql密码,如果使用--password将出现警告,并且每次都要手动输入密码才能执行job,sqoop规定密码文件必须存放在HDFS上,并且权限必须是400。
echo -n "hadoop" > itcastmysql.pwd hdfs dfs -mkdir -p /input/sqoop/pwd/ hdfs dfs -put itcastmysql.pwd /input/sqoop/pwd/ hdfs dfs -chmod 400 /input/sqoop/pwd/itcastmysql.pwd
检查sqoop的sqoop-site.xml是否存在如下配置:
sqoop.metastore.client.record.password
true
If true, allow saved passwords in the metastore.
创建sqoop job
在创建job时,使用--password-file参数
bin/sqoop job --create itcastjob2 -- import --connect jdbc:mysql://node03:3306/userdb \
--username root \
--password-file /input/sqoop/pwd/itcastmysql.pwd \
--target-dir /sqoopresult666 \
--table emp --m 1
执行job
通过命令验证
sqoop job -exec itcastjob1
二丶Apache Flume
1.Flume的介绍
- 概述
flume是一款大数据中海量数据采集传输汇总的软件。特别指的是数据流转的过程,或者说是数据搬运的过程。把数据从一个存储介质通过flume传递到另一个存储介质中。 - 核心组件
source:用于对接各个不同的数据源
sink: 用于对接各个不同存储数据的目的地(数据下沉地)
channle:用于中间临时存储缓存数据 - 运行机制
flume本身是java程序,在需要数据采集的机器上启动agent进程
agent进程里面包含了:source sink channel
在flume中,数据被包装成event 真实 的数据是放在event body中,event是flume中最小的数据单元 - 运行架构
1.简单架构:
只需要部署一个agent进程即可
2.复杂架构:
多个agent之间的串联 相当于大家手拉手共同完成数据的采集传输工作,在串联架构中没有主从之分 大家的地位都是一样的。
2.Flume的安装部署
在conf/flume-env.sh 中导入java环境变量
保证flume工作的时候一定可以正确加载到环境变量
flume的开发步骤
-
根据业务需求编写采集方案配置文件
-
文件名要见名知意,例如:source-sink.conf
-
具体需要描述清楚sink source channel组件配置信息 结合官网配置
-
启动命令
bin/flume-ng agent --conf conf --conf-file conf/netcat-logger.conf --name a1 -Dflume.root.logger=INFO,console
案例:监控目录数据变化到hdfs
hdfs sink 配置文件编写
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1# Describe/configure the source
##注意:不能往监控目中重复丢同名文件
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/logs2
a1.sources.r1.fileHeader = true# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
spooldir source
- 注意其监控的文件夹下面不能有同名文件的产生
- 如果有 报错且罢工 后去就不在进行数据的监视采集了
- 在企业中 通常给文件追加时间戳命名的方式保证文件不会重名
3.Flume负载均衡
- 所谓的负载均衡,用于解决一个进程处理不了所有请求 多个进程一起解决
- 同一个请求只能交给一个进行处理 避免数据重复
- 如何分配请求就涉及到了负载均衡的算法:轮询(round_dobin) 随机(random) 权重
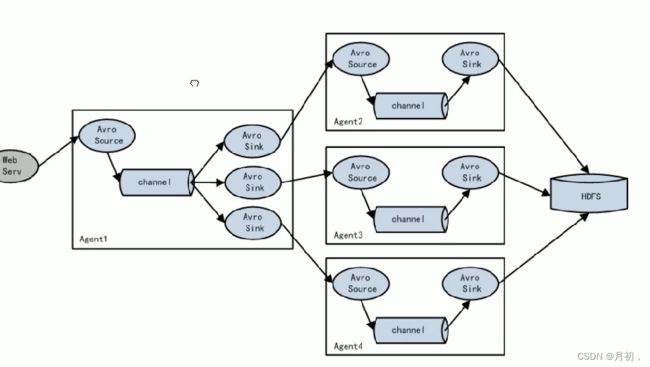
flume串联跨网络传输数据
avro sink 和 avro source
使用上述两个组件指定绑定的端口ip就可以满足数据跨网络的传递 通常用于flume串联架构中
flume串联启动通常从远离数据源的一端启动
3.Flume failover(容错)
- 容错又称为故障转移 容忍错误的发生
- 通常用于解决单点故障 给容易出故障的地方设置备份、
- 备份越多 容错能力越强 但是资源浪费越严重
4.静态拦截器
如果没有使用静态拦截器
Event: { headers:{} body: 36 Sun Jun 2 18:26 }
使用静态拦截器之后 自己添加kv标识对
Event: { headers:{type=access} body: 36 Sun Jun 2 18:26 }
Event: { headers:{type=nginx} body: 36 Sun Jun 2 18:26 }
Event: { headers:{type=web} body: 36 Sun Jun 2 18:26 }
后续在存放数据的时候可以使用flume的规则语法获取到拦截器添加的kv内容
%{type}
模拟数据实时产生
while true; do echo "access access....." >> /root/logs/access.log;sleep 0.5;done
while true; do echo "web web....." >> /root/logs/web.log;sleep 0.5;done
while true; do echo "nginx nginx....." >> /root/logs/nginx.log;sleep 0.5;done三丶Azkaban调度器
1.Azkaban介绍
是由领英推出的一款免费开源的工作流调度软件
特点
- 功能强大 可以带哦度几乎所有的软件执行
- 配置简单 job配置文件
- 提供了web页面使用
- java语言开发 源码清晰可见 可以进行二次开发
架构
- web 服务器 :对外提供web服务 用户在页面上进行项目的相关管理
- excutor服务器:负责具体的工作流的调度提交。
- 数据库:用于保存工作流相关信息(如mysql)
部署模式
- 单节点模式 :web,excutor 在同一个进程用于测试体验
- two-server:web,excutor 在不同进程中,可以使用第三发数据库
- mutil-excutor-server:web,excutor在不同机器上 可以部署多个excutor服务器
2.azkaban的安装部署
单节点部署模式 注意时区 内存检测要关闭
启动时必须在安装包的根目录下启动
bin/start-solo.shAzkaban的开发流程:
- 编写job的配置文件xxx.job
type=command ....... command=xxxx - 把所有的job配置打成一个zip压缩包
- 登录页面node03:8081 创建工程(默认用户名密码都是azkaban)
- 上传zip压缩包
- 选择调度schduler或者立即执行executor
、
2.two server模式部署
-
该模式的特点是web服务器和executor服务器分别位于不同的进程中
-
使用第三方的数据库进行数据的保存 :mysql
-
安装部署注意事项
-
先对mysql进行初始化操作
-
配置azkaban.properties 注意时区 mysql相关 ssl
-
启动时候注意需要自己手动的激活executor服务器 在根目录下启动
-
如果启动出错 通过安装包根目录下的日志进行判断
-
访问的页面https
特别注意:executor启动(包括重启)的时候 默认不会激活 需要自己手动激活对应的mysql中的表executors active :0 表示未激活 1表示激活可以自己手动修改数据提交激活 也可以使用官方的命令请求激活-
curl -G "node03:$(<./executor.port)/executor?action=activate" && echo
-
-
azkaban调度总结
-
理论上任何一款软件,只有可以通过shell command执行 都可以转化成为azkaban的调度执行
-
type=command command = sh xxx.sh
Apache Oozie
1.Oozie的介绍
- oozie是一个工作调度软件 oozie的目的是根据一个定义的DAG(有向无环图)执行工作流程
- oozie本身的配置是一种xml格式的配置文件 oozie跟hue配合使用很方便
- oozie的特点是顺序执行 周期重复定时 可视化 追踪结果
2.Oozie的构造
- Oozie client: 主要是提供一种方式给用户进行工作流的提交启动(client javaapi restfor)
- Ooize server:(本身是一个java web 应用)
- Hadoop生态圈
ooize各种类型任务提交底层依赖于mr程序 首先启动一个没有Reducetask的mr 通过这个reduce吧各个不同类型的任务提交到具体的集群上执行
3.Ooize的流程节点
ooize核心配置是在应该workflow.xml文件中顶一个工作流程规则
类型:
- control node 控制工作流的执行路径:start end fork join kill
- action node 具体的任务类型: mr spark shell java hive
- 上述两种类型结合起来 就可以描绘出应该工作流的DAG 图
4.oozie 工作类型
- workflow 基本类型的工作流 只会按照定义T恤执行 无定时触发
- coordinator 定时触发任务 当满足执行时间 或者输入数据可用 触发workflow执行
- Bundle 批处理任务一次提交多个 coordinator
5.Ooize的安装配置
5.1 配置 httpfs 服务
修改 hadoop 的配置文件 core-site.xml
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
5.2 配置 jobhistory 服务
修改 hadoop 的配置文件 mapred-site.xml
mapreduce.jobhistory.address
node01:10020
MapReduce JobHistory Server IPC host:port
mapreduce.jobhistory.webapp.address
node01:19888
MapReduce JobHistory Server Web UI host:port
mapreduce.jobhistory.done-dir
/export/data/history/done
mapreduce.jobhistory.intermediate-done-dir
/export/data/history/done_intermediate
启动 history-server
mr-jobhistory-daemon.sh start historyserver
停止 history-server
mr-jobhistory-daemon.sh stop historyserver
通过浏览器访问 Hadoop Jobhistory 的 WEBUI
http://node-1:19888
5.3. . 重启 Hadoop 集群 相关服务
上传 oozie 的安装包并解压
oozie 的安装包上传到/export/softwares
tar -zxvf oozie-4.1.0-cdh5.14.0.tar.gz
解压 hadooplibs 到与 oozie 平行的目录
cd /export/servers/oozie-4.1.0-cdh5.14.0
tar -zxvf oozie-hadooplibs-4.1.0-cdh5.14.0.tar.gz -C ../
添加相关依赖
oozie 的安装路径下创建 libext 目录
cd /export/servers/oozie-4.1.0-cdh5.14.0
mkdir -p libext
拷贝 hadoop 依赖包到 libext
cd /export/servers/oozie-4.1.0-cdh5.14.0
cp -ra hadooplibs/hadooplib-2.6.0-cdh5.14.0.oozie-4.1.0-
cdh5.14.0/* libext/
上传 mysql 的驱动包到 libext
mysql-connector-java-5.1.32.jar
添加 ext-2.2.zip 压缩包到 libext
ext-2.2.zip
5.4 . 修改 oozie-site.xml
cd /export/servers/oozie-4.1.0-cdh5.14.0/conf
vim oozie-site.xml
oozie 默认使用的是 UTC 的时区,需要在 oozie-site.xml 当中配置时区为
GMT+0800 时区
oozie.service.JPAService.jdbc.driver
com.mysql.jdbc.Driver
oozie.service.JPAService.jdbc.url
jdbc:mysql://node03:3306/oozie
oozie.service.JPAService.jdbc.username
root
oozie.service.JPAService.jdbc.password
hadoop
oozie.processing.timezone
GMT+0800
oozie.service.coord.check.maximum.frequency
false
oozie.service.HadoopAccessorService.hadoop.configurations
*=/export/servers/hadoop-2.7.5/etc/hadoop
5.5 . 初始化 mysql 相关信息
上传 oozie 的解压后目录的下的 yarn.tar.gz 到 hdfs 目录
bin/oozie-setup.sh sharelib create -fs hdfs://node01:9000 -
locallib oozie-sharelib-4.1.0-cdh5.14.0-yarn.tar.gz
本质上就是将这些 jar 包解压到了 hdfs 上面的路径下面去
创建 mysql 数据库
mysql -uroot -p
create database oozie;
初始化创建 oozie 的数据库表
cd /export/servers/oozie-4.1.0-cdh5.14.0
bin/oozie-setup.sh db create -run -sqlfile oozie.sql
5.6 打包项目,生成 war 包
cd /export/servers/oozie-4.1.0-cdh5.14.0
bin/oozie-setup.sh prepare-war
5.7 配置 oozie 环境变量
vim /etc/profile
export OOZIE_HOME=/export/servers/oozie-4.1.0-cdh5.14.0
export OOZIE_URL=http://node03.hadoop.com:11000/oozie
export PATH=$PATH:$OOZIE_HOME/binsource /etc/profile
5.8 启动关闭 oozie 服务
启动命令
cd /export/servers/oozie-4.1.0-cdh5.14.0
bin/oozied.sh start
关闭命令
bin/oozied.sh stop
启动的时候产生的 pid 文件,如果是 kill 方式关闭进程 则需要删除该文件
重新启动,否则再次启动会报错。
5.9 . 浏览器 web UI 页面
http://node-1:11000/oozie/
5.10 . 解决 oozie 页面时区显示异常
页面访问的时候,发现 oozie 使用的还是 GMT 的时区,与我们现在的时区
相差一定的时间,所以需要调整一个 js 的获取时区的方法,将其改成我们现在的
时区。
修改 js 当中的时区问题
cd oozie-server/webapps/oozie
vim oozie-console.js
function getTimeZone() {
Ext.state.Manager.setProvider(new Ext.state.CookieProvider());
return Ext.state.Manager.get("TimezoneId","GMT+0800");
}
重启 oozie 即可
cd /export/servers/oozie-4.1.0-cdh5.14.0
bin/oozied.sh stop
bin/oozied.sh start