RISC-V RVWMO 内存模型解释
RISC-V RVWMO 内存模型解释
引言
本文介绍 RISC-V RVWMO 内存模型。RVWMO 内存模型定义了什么样的全局内存顺序才是合法的。本引言部分将解释为什么会出现不合法的全局内存顺序,以及为什么需要内存模型。
首先引起乱序的全局内存顺序(指令重排序)有两种原因,一种是软件编译器带来的,另外一种是硬件执行上带来的。
软件带来指令重排序很好理解,如下面的例子:
x = 1;
while(x)
x = memory[0];
y = 1;
在程序编译时期编译器无法预知多核执行的动态性,因此编译器可以认为语句 y = 1 和 x 的值没有必然联系,因此 y = 1 可能比 x = 1 先执行,从而跳过循环,在编译器看来这并不违反语义。
第二种由硬件执行产生的指令重排序,在单核单线程程序中,程序的执行的顺序看起来应该总是和程序设计的顺序一致,但是在硬件实现的视角中,情况却完全不同,首先我们定义对于内存操作,有两种内存操作原语,即读内存和写内存。
我们定义一个完成一个读操作是瞬时原子的,因为读操作不需要通知其他线程,因此读操作一旦完成,其他线程默认均可见。但是写操作的情况却完全不同,一个写操作可能不是原子,这有点反直觉,但确实如此,一个写操作需要通知所有其他线程修改了写地址上的内容之后,一个写操作才算完成,称为写可见性。
如果读取了一个未完成的写操作,即写操作还没有对所有的线程都可见,此时就会发生读非原子的写操作,此时读写会发生重排序,通常情况下,处理器内核通常具有写缓冲区,例如下面的例子:
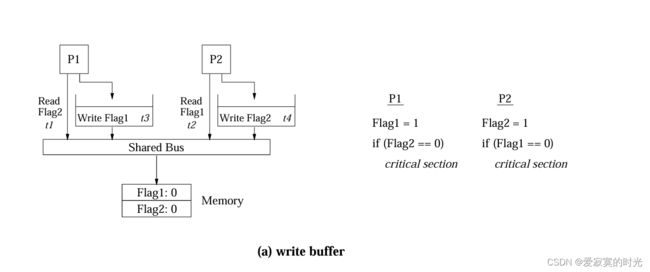
程序依次发生的顺序为:
- 首先 P1 将
Flag1 = 1写入缓冲区,此时Flag1 = 1对线程 P2 不可见。 - P2 将
Flag2 = 1写入缓冲区,此时Flag2 = 1对线程 P1 不可见。 - P1 读取 Flag2 的值为 0,进入临界区。
- P2 读取 Flag1 的值为 0,进入临界区。
Flag1 = 1从写缓冲区写入内存。Flag2 = 1从写缓冲区写入内存。
在这种情况下,因为写的非原子性,产生了乱序的读写,导致两个线程同时进入临界区。但是写缓冲区带来了屏蔽等待写入时间的效果(将指令执行的时间重叠)。
除了写缓冲区,硬件还有其他的实现,例如 Overlapped writes, Non−blocking reads 这些都会产生读写的重排序。
不同的 Relaxed Memory 内存模型允许不同情况的重排序,RISC-V 采用了 RVWMO 内存模型,方便软件产生最大程度上的优化,以及最大程度上的硬件实现自由。
程序顺序、全局内存顺序以及保留程序顺序
在多线程内存模型中,存在三种程序执行顺序,即程序顺序、全局内存顺序以及保留程序顺序。最容易理解的是程序顺序,一个程序顺序定义为程序在指令流中的顺序,也是程序设计者所编写的顺序,例如对于一个 Hart 看到的指令流:
(a) li t1, 1
(b) sw t1, 0(s0)
(c) lw a0, 0(s0)
则称在程序顺序中指令 (b) 先于指令 (c) 。
上文已经解释过假设有两个线程 A 和线程 B ,为什么线程 B 看到 A 的执行顺序与线程 A 的程序顺序完全不同。而全局内存顺序定义了所有线程所看到的内存的全局性事件列表,例如对于两个 Hart 的指令流:
Hart 0:
(a) li t1, 1
(b) sw t1, 0(s0)
Hart 1:
(c) li t1, 2
(d) sw t1, 0(s0)
(e) lw a0, 0(s0)
则对于线程0来说,一种可能的全局内存顺序为: (c)(d)(a)(b)(e) ,即在事件 (c)(d) 结束后,线程0观测到了线程1的 (a)(b) 发出的全局事件,因此指令 (e) 读取到的值为1。
保留程序顺序在原文中的定义为:
Preserved program order represents the subset of program order that must be respected within the global memory order.
简单的理解为,因为全局内存顺序无法保证和程序顺序相同,但是为了程序语义的正确,至少必须保证程序顺序的一个子集,称为保留程序顺序,在全局内存顺序中和程序顺序相同。
RISC-V RVWMO 模型定义了13条保留程序顺序的规则和3条公理,本文剩下的部分将讲解这13条规则和3条公理。
3条公理
加载值公理(Load Value Axiom)
加载值公理定义了一个具有 load 语义的指令可以返回值,原文如下:
Load Value Axiom: Each byte of each load i returns the value written to that byte by the store that is the latest in global memory order among the following stores:
- Stores that write that byte and that precede i in the global memory order
- Stores that write that byte and that precede i in program order
也就是说 load 指令可以返回的值必须是在全局内存顺序以及在当前线程程序顺序中的最后一条 store 指令所写入的值。
该公理引入 RVWMO 内存模型中对写原子性的规定,即一个线程可以读取自己一条还未完成的写入指令所写入的值,即 RVWMO 中的 store 指令是非原子写的(此时写可能对其他线程不可见)。这个规则允许硬件优化写入时间(非阻塞写),通常由一个写缓冲区(store buffer)实现,对于具体的写缓冲区的实现,读者可以参考计算机体系结构相关的书籍。
在 RISC-V 规范中给出了第一个示例:

上图的结果按时间顺序的解释为:
(a)执行并将1写入自己的私有写缓冲区。(b)读取自己写缓冲区的值(store buffer forwarding)(之前(a)写入的)。(c)确保之前的读取已完成。(d)读取当前内存y的值为0。(e)执行并将1写入自己的私有写缓冲区。(f)读取自己写缓冲区的值(之前(e)写入的)。(g)确保之前的读取已完成。(h)读取当前内存x的值为0。(a)写缓冲区将1写入内存x。(e)写缓冲区将1写入内存x。
接下来规范中给出的一个更加极端的例子:
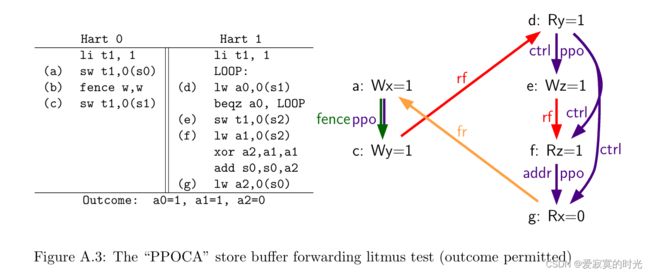
对于结果的解释为:
- 线程1认为控制性依赖
(d)循环不会对(e)(f)(g)产生影响,因为地址不同(即使其他线程写入了相同的地址,但是线程1无法预测是否真的有其他线程在写入),因此(e)(f)(g)允许先比(d)执行,也不会改变当前线程的程序顺序的语义,此时(e)写入自己的私有写缓冲区z=1。 (f)读取自己写缓冲区的值(之前(e)写入的)。(g)读取内存中的x值为0。(a)执行写入私有写缓冲区x=1。(b)确保私有写缓冲区的任务已经全部写入,将x=1写入内存。(c)执行写入私有写缓冲区y=1,之后将y=1写入内存。(d)执行成功,读取到1,跳出循环。(e)预测成功,将z=1从缓冲区写入内存。
原子性公理(Atomicity Axiom)
Atomicity Axiom (for Aligned Atomics): If r and w are paired load and store operations generated by aligned LR and SC instructions in a hart h, s is a store to byte x, and r returns a value written by s, then s must precede w in the global memory order, and there can be no store from a hart other than h to byte x following s and preceding w in the global memory order.
RISC-V 提供了两种原子性指令,一种是 AMO ,AMO 把读和写两种操作打包为一种原子性操作,因此该指令本身就是原子的,而另外一种 LR/SC 指令则不同,该公理说明了什么是成对的 LR/SC (原子性),只有成对的 LR/SC , SC 操作才能成功。
该公理说若在线程 h 中 LR 和 SC 是成对的,那么在两者之间除了线程 h 可以修改被保留的地址为,其他线程在全局内存序中均不允许修改。
但是,该公理允许在全局内存序上有下面的操作:
- 其他线程或线程 h 读取或修改了非 LR/SC 重叠的地址上的内存。
- 允许线程 h 读取或修改 LR/SC 重叠的地址上的内存。
- LR 和 SC 不必成对出现,可以嵌套。
第一条比较好理解,对于第二条,下面的例子中的 LR/SC 可能成对:
(a) lr.d a0, 0(s0)
(b) sd t1, 0(s0)
(c) sc.d t2, 0(s0)
对于第三条,下面的例子中的 LR/SC 可能成对:
(a) lr.w a0, 0(s0)
(b) sw t1, 4(s0)
(c) sc.w t2, 8(s0)
其中 (c) 可能和之前的 LR 成对, (a) 不影响 (c) 是否成功。
需要注意的是,如果在程序顺序中一对 LR 和 SC 之间出现了另外一个 SC ,无论该 SC 是否成功失败,最后一个 SC 必将失败。
渐近性公理(Progress Axiom)
原文如下:
Progress Axiom: No memory operation may be preceded in the global memory order by an infinite sequence of other memory operations.
渐近性公理较好理解,它确保了一个内存操作应该在有限的时间内完成(被所有的线程可见)。如果渐近性公理不成立,那么用户将无法实现自旋锁等一些同步操作,因为可能一次写入永远都不会对其他线程可见。
如果一个具有缓存的系统,应该通过缓存一致性协议来确保在有限的时间内,内存操作对所有线程可见。
13条规则
在介绍13条规则之前,我们首先制定一个通用约定:
- 指令
a和指令b都是内存操作指令(而不是IO区域) - 在程序顺序中,
a先于b - 若
a和b满足下面任意一条规则,则必须保证在保留程序顺序(当然也在全局内存顺序)中,a也先于b
重叠地址顺序(Overlapping-Address Orderings)(1-3)
Rule 1: b is a store, and a and b access overlapping memory addresses
规则1说若b是一个 store 指令,并且 a 和 b 有重叠的地址,那么 a 就不能排到 b 后面。这是显然的,因为若调换两个指令的执行顺序,则连程序顺序语义都得不到保证。但是若 a 是一个 store 指令 b 是一个 load 指令,则不受该规则约束, load 可以先于 store 出现在全局内存序中,因为硬件通常需要实现写缓冲区。
Rule 2: a and b are loads, x is a byte read by both a and b, there is no store to x between a and b in program order, and a and b return values for x written by different memory operations
规则2说若 a 和 b 都是 load 指令,并且 a 和 b 有重叠的地址,并且在程序顺序中 a 和 b 之间没有地址重叠的 store 指令,并且 a 和 b 的值是由不同 store 指令写入的。这条规则十分抽象,但至少应遵守的一条规则是一个新的 load 指令不应该比一个旧的 load 指令返回一个更旧的值,这条规则被称为 CoRR (Coherence for Read-Read pairs)规则。
规范中给出了两个具体的例子分别解释了规则2的第二句话和第三句话,首先看例子1:

给出的结果解释是:
(d)指令由于某种原因暂停了执行。(e)执行,并放到写缓冲区。(f)执行并读取写缓冲区的值。(g)(h)(i)分别按顺序执行。(a)(b)(c)按顺序执行,并将 x=1 和 y=1 依次从写缓冲区写入内存。(d)指令跳过写缓冲区,读取内存中y=1。(e)将写缓冲区的值写回内存。
对应的全局内存顺序为 (f)(i)(a)(c)(d)(e) ,注意到虽然 (f) 排在 (d) 之前,但是 (f) 却比 (d) 读取的值要新,因此不违反 CoRR 规则,在 (f) 和 (d) 之间夹入了一条在程序顺序上和两者地址重合的 load 指令,该重排序是合法的。
读者可能疑惑,在全局内存顺序中 load 指令的返回值并不遵循全局内存顺序的读写顺序,毕竟 load 的返回值和全局内存顺序并无直接关系,全局内存顺序无法唯一的决定 load 的返回值,具体详见上文加载值公理。
第二个例子:

假设 z 的值已经被其他线程写入v,若全局内存序为 (h)(k)(a)(c)(d)(g) ,注意虽然 (h) 在 (g) 之前,但是 (h) 并没有比 (g) 读到更旧的值,因此也不违反 CoRR 规则。
但是,假设 z 的值已经被其他线程写入v不成立, (g) 和 (h) 可能读到不同的值,此时必须要求 (g) 在 (h) 前执行,即值是由不同 store 指令写入的。
Rule 3: a is generated by an AMO or SC instruction, b is a load, and b returns a value written by a
规则3定义了 AMO 和 SC 指令的原子性,若 a 是 AMO 或者 SC 指令, b 是 load 指令,并且 b 返回由 a 写入的值。上文说过 RVWMO 允许普通的 store 非原子性写,但是 AMO 和 SC 指令必须具有原子性写,在 a 对所有线程可见之前,b 都不应该读取 a 写入的值。
最后需要提醒读者的一点是,重叠地址指的是部分重叠就算是重叠,因为存在不同位宽的内存操作指令。
内存栅栏(Fences)(4)
Rule 4: There is a FENCE instruction that orders a before b
该规则比显然,一个 FENCE 指令指定了全局内存序的要求,该指令具有八个可以设置的位,指定了在内存栅栏前的需要定序的指令和之后需要定序的指令,具体请参考 FENCE 指令说明。
显式同步(Explicit Synchronization)(5-8)
Rule 5: a has an acquire annotation
规则5规定了一个“获取”语义,正如字面意思“获取”经常是获取锁进入临界区(Critical section),因此不能把获取锁之后的操作拿到获取锁之前来执行,否则就会违反临界区原则。
RISC-V 提供了两种实现“获取”语义的方法,一种是原子指令的 aq 位,另外一种由 FENCE R,RW 提供。

上图中的例子使用 aq 位实现“获取”语义,注意 aq 位规定临界区内的指令不能在临界区外(之前)执行,并没有规定临界区外(之前)的指令能不能在临界区内执行,因此两个无关的 store 和 load 指令在临界区内执行是允许的。

上图中使用 FENCE R,RW 定序临界区,和 aq 位不同的是,该指令具有额外的要求,无关的 ld 指令不能再临界区内执行,相比来看 aq 位具有更贴近的“获取”语义,允许硬件有额外的优化。
Rule 6: b has a release annotation
规则6和规则5相似,只是位置不同,一个“释放”语义,通常是释放锁,不允许临界区内的操作在临界区外执行(之后),同样也提供了2中方案,一是设置原子指令的 rl 位,另外是使用 FENCE RW,W 定序。
Rule 7: a and b both have RCsc annotations
一个 RCsc 记号指的是一个 AMO 、LR或是SC指令具有 aq 或是 rl 标记。具有该记号的指令不能被重排序,规则5、6、7共同组成了临界区规则。
因为 RVWMO 目前还没有 RCpc 记号的指令,因此关于 RCpc 和 RCsc 的细节请见后文参考资料。
Rule 8: a is paired with b
规则8目前成对的指令只有 LR 和 SC 指令,规定 LR 和 SC 不能重排序。
句法依赖(Syntactic Dependencies)(9-11)
Rule 9: b has a syntactic address dependency on a
Rule 10: b has a syntactic data dependency on a
Rule 11: b is a store, and b has a syntactic control dependency on a
规则9和10从直觉上来讲是合理的。 a 指令确定了 b 指令的地址,或者执行 b 需要 a 的结果,又或者是 b 是 store 指令, a 控制 b 的执行,那么 a 指令就需要在 b 指令执行之前执行。
需要强调的是,这里的依赖指的是句法依赖,而不是语义依赖,换句话说,即使重排序从结果上是正确的,但是如果是句法依赖,该规则也不允许重排序,例如:

上图中,尽管 xor a2, a1, a1 的值永远是0,重排序两个 load 指令从语义上看起来没问题,但是句法依赖却不允许这种重排序。该规则提供一个轻量级的定序语义,相反若使用 FENCE R,R 则会定序所有的 load 指令。
对于控制依赖也具有相同的句法依赖性,例如:

尽管 next 标签总是执行,但也存在对于第一条指令的依赖,同理:

尽管 bne 指令从语义上讲没有实际的作用效果,但是 next 标签的指令也存在对于第一条指令的依赖。
SC 指令的成功和失败也会产生依赖:

假设不规定SC 指令的依赖,则一种可能的执行结果是,线程为了保证 (b)(c) 成对执行成功,先让 (d)(e)(f)(a) 执行,此时 (c) 可以提前返回 0,然后执行 (b)(c) 其中 (c) 执行成功。规则11不允许这样的执行。
其他例如 CSR 指令、浮点指令也存在依赖情况,具体请参考规范说明。
流水线依赖(Pipeline Dependencies)(12-13)
Rule 12: b is a load, and there exists some store m between a and b in program order such that m has an address or data dependency on a, and b returns a value written by m
流水线依赖描述了一种传递性依赖,规则12指明了 load 只有当之前的 store 指令的地址和数据都确定了, load 才可以提前读 store 指令写入的值。

这里例子中 (d) 一定是比 (f) 先执行的,只有执行了 (d) 那么 (e) 的数据才准备好, (f) 才能执行,这一般受限于处理器设计中的流水线依赖,因此叫做流水线依赖。
下面的例子情况则完完全不同:
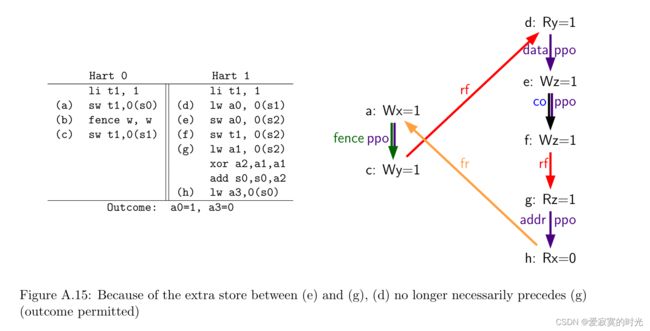
虽然上一个例子 (d)(e) 和 (g) 之间有流水线依赖,但是这里例子中额外的 (f) 打破了这种依赖, (f) 的地址和数据可以先准备好, (g) 允许读 (f) 写入的数据。
Rule 13: b is a store, and there exists some instruction m between a and b in program order such that m has an address dependency on a
规则13说若 b 是一个 store 指令,并且 a 和 b 在程序顺序中存在其他指令的地址依赖于 a 的结果,那么 a 和 b 不能重排序,看下面的例子:

若 (f) 比 (d) 先执行,存在一种情况当 a1 = s0 的时候,此时 (e) 无法读取到在 (f) 之前写入的值了,因为这样违反加载值公理。因此 (d) 一定比 (f) 先执行。
IO内存
对于内存和IO内存,RISC-V 定义了物理内存属性(Physical Memory Attributes,PMAs)来描述一段内存区域,具体可参考 RISC-V 特权规范。
对于IO内存,加载值公理和原子性公理不再适用,在IO内存中,读操作可能有明显的副作用(side effects),并且读操作的值可能不是由 store 指令写入的,这取决于IO设备。但是IO内存依然遵循下面的保留程序顺序:
a和b依旧遵循13条保留程序顺序规则,但是a和b要么都是内存操作,要么都是 IO 操作,不能一个是内存操作一个是 IO 操作。a和b对重叠的 IO 地址进行操作。a和b访问相同的强顺序IO区域(strongly-ordered)。a和b访问的IO区域,有一个通道是通道1。a和b访问相同的IO区域通过相同的通道,除了通道0。
RISC-V 的 FENCE 指令区别 IO 操作和内存操作,处理器实现应该总是假设,当设备收到操作指令之后,设备可能立刻访问之前的内存操作,此时就需要 FENCE 指令进行定序:

假设 0(a1) 是一个IO地址,而 0(a0) 是一个内存地址,为了确保设备能够正确读取第一条指令存入的值,需要使用 FENCE W, O 定序。
参考资料
- S. V. Adve and K. Gharachorloo. Shared memory consistency models: A tutorial.
Computer, 29(12):66–76, 1996. - A. Waterman and K. Asanović, editors. The RISC-V Instruction Set Manual,
Volume I: Unprivileged ISA, Version 20191213. December 13, 2019.