万字长文深度解读亚信安慧AntDB-T数据库锁——性能和稳定性的保障
前言
亚信安慧AntDB-T数据库是一款企业级通用分布式关系型数据库,而并发控制是数据库系统中最核心的概念之一,其目的是保证多个并发操作能够正确地读取和修改数据库,AntDB-T数据库实现并发控制的基本方法是使用锁来控制临界区互斥访问。
在多用户并发访问数据库时,如果没有合适的锁机制,可能会导致数据不一致等一系列潜在问题。例如,两个用户同时修改同一行数据可能会导致数据冲突或被损坏。如果使用锁,AntDB-T数据库可以确保一次只有一个用户可以修改数据,从而避免上述情况发生。为了确保复杂的事务可以安全地同时运行,AntDB-T提供了各种级别的锁来控制对各种数据对象的并发访问,使得对数据库关键部分的更改序列化。
在数据库管理系统(DBMS)中,锁是维护数据一致性和完整性的重要工具。AntDB-T数据库同样依赖于锁来确保并发操作的数据一致性和完整性。本文主要阐述AntDB-T数据库的锁的分类、常规锁概念、常规锁的设计以及应用场景。
AntDB-T数据库锁的分类
本部分主要介绍AntDB-T数据库锁的分类。AntDB-T数据库中定义了三种锁,分别是SpinLock、 LWLock和RegularLock。
SpinLock(自旋锁)
SpinLock是最底层的锁, 它分为与机器相关的实现方法和与机器不相关的实现方法。如果机器支持TAS (test-and-set)指令集,那么AntDB-T数据库就会采用s_lock.h和s_lock.c中定义的SpinLock实现机制;但是如果机器不支持TAS指令集,那么不依赖于硬件的SpinLock的实现定义在spin.h和spin.c中,它需要用到AntDB-T数据库定义的信号量PGSemaphore。
作为一种最底层的锁,一般不直接使用SpinLock,而是利用它来实现其他锁(例如轻量级锁LWLock)。毫无疑问,依赖于硬件的SpinLock机制肯定比不依赖于硬件的SpinLock机制速度快,因为不依赖于硬件的SpinLock机制需要使用PG信号量来仿真SpinLock。
SpinLock的特点是:封锁时间很短、没有等待队列和死锁检测机制、事务结束时不会自动释放SpinLock。
LWLock(轻量级锁)
LWLock (轻量级锁)主要提供对共享存储器的数据结构的互斥访问,它主要是保护这些共享存储器中的数据结构。LWLock有两种锁模式,一种为排他模式,另一种为共享模式。LWLock 不提供死锁检测,但LWLock 管理器在elog恢复期间被自动释放,所以持有LWLock 的期间调用elog发出错误消息不会出现LWLock 未释放的问题。
LWLock 利用SpinLock实现,当没有锁的竞争时可以很快获得或释放LWLock。当一个进程阻塞在一个LWLock上时,相当于它阻塞在一个信号量上,所以不会消耗CPU时间,等待的进程将会以先来后到的顺序被授予锁。
简单来说, LWLock 的特点是:有等待队列、无死锁检测、能自动释放锁。
RegularLock(常规锁)
RegularLock(常规锁)指的是一般数据库事务管理中所指的锁,也简称为Lock。RegularLock(常规锁)它保护的临界区是数据库对象的操作,而不是单纯的共享内存变量或者某一个原子变量。AntDB-T数据库中的数据库对象包括表、页面、元组、事务ID等,RegularLock(常规锁)在这些对象的保护性质中就像是读写锁。
RegularLock(常规锁)由LWLock(轻量级锁)实现,其特点是:有等待队列,有死锁检测,能自动释放锁。后文主要为RegularLock(常规锁)的相关设计。
AntDB-T数据库常规锁
锁类型
-
锁方法:AntDB-T数据库包含两种加RegularLock(常规锁)的方法:DEFAULT_LOCKMETHOD和USER_LOCKMETHOD。前者是默认锁方法,后者为用户锁方法。AntDB-T数据库通常使用DEFAULT_LOCKMETHOD作为默认加锁方法。当然,用户也可以定义自己的锁方法,例如建议锁(Advisory Lock)就是用户创建的锁类型之一。
-
锁粒度:根据锁对象的不同,分为:表级锁、行级锁、页级锁等,具体如下图1所示,每个锁对象的含义如下表所示。

图1:锁对象类型
表1:锁的LOCKTAG类型及说明

从上表可以看出,常规锁不仅可以对表加锁,也可以对各类对象加锁,我们平时说的表锁(表级锁)、页锁、咨询锁等等(行锁除外),实际上都是常规锁根据不同锁定对象划分的子类。但是这里说的行锁除外, 因为AntDB-T数据库采用元组级常规锁+xmax结合的方式来实现行锁,并不是单纯用元组级常规锁来实现的。
常规锁最常用于给表加锁,表级锁:两个事务在同一时刻不能在同一个表上持有互相冲突的锁,但是可以同时持有不冲突的锁。
表2:常规锁模式说明(按排他级别从低到高排序)

表3:常规锁冲突的锁模式(按排他级别从低到高排序)
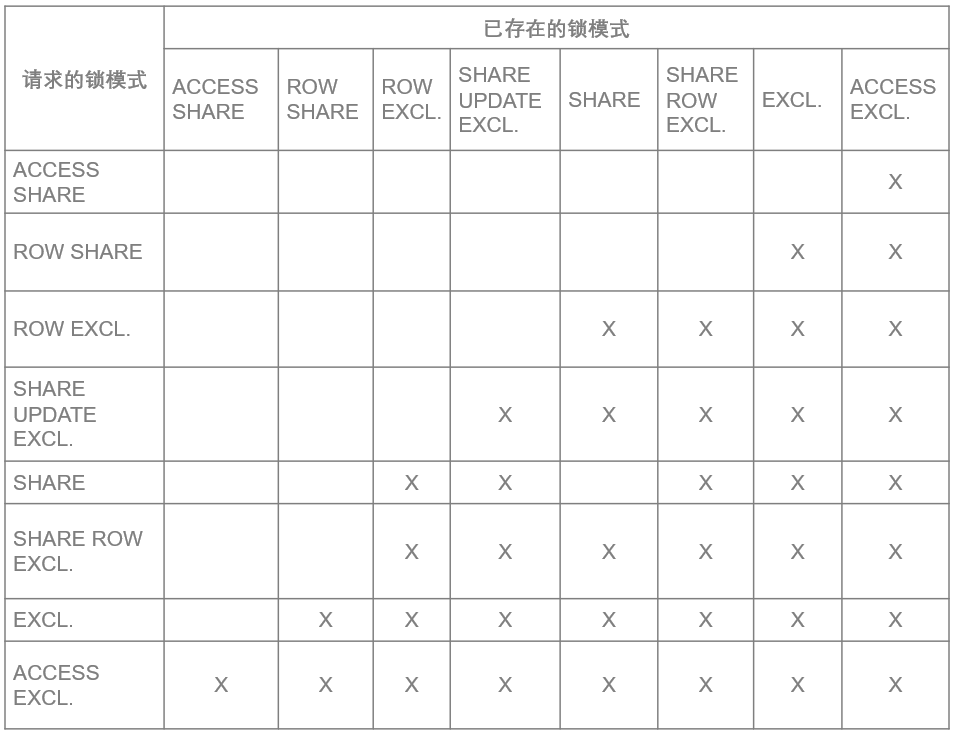
AntDB-T数据库常规锁设计
基础数据结构
1、LockMethodData表示锁方法表,是锁设计里面比较基础的一个结构。定义如下图2所示:

图2:LockMethodData数据结构
一个锁方法表的控制结构定义在 LockMethodData中,它存在于共享内存中。其中字段numLockModes表示在锁表上定义的锁模式数量,常规锁的锁模式在上图2中有宏定义,其中NoLock 的宏定义为0,其本身不是一种锁模式的标志,这里可以用来表示没有获得锁,numLockModes字段的数值必须小于或等于 MAX_LOCKMODES,MAX_LOCKMODES定义值为10。
字段lockModeNames 表示用于Debug时打印用锁模式名字用,具体锁模式名字见上图2所示,字段trace_flag 表示指本锁方法GUC traceflag 的指针。
字段conlictTab显示锁模式冲突的位掩码数组,它用于指示持有或请求的锁模式的集合,锁模式的取值为1至numLockModes,所以conflictTab[0]未使用。通过不同位来表示的锁的模式不同,每个位上都对应一个锁模式,取值1或者0,来代表有无锁,这就是bit格式的便利,例如加ShareLock锁,对应的锁模式为5,则将1左位移5位,通过查看该字段要判断的对应数组的第五位的值是否为1,来表示是否已经持有ShareLock。
conflictTab字段还可用来判断锁冲突,例如:如果锁模式i和j冲突,那么conflictTab[i] 的第j位为1。下图3是锁模式冲突表(LockConflicts)的源码定义:

图3: LockConflicts 冲突表定义
其中LOCKBIT_ON 的定位为:#define LOCKBIT_ON(lockmode) (1 << (lockmode)),这个LockConflicts冲突表并没有直接设定某种类型锁的冲突bitmask ,而是采用位移运算加或运算,目的是让我们更直观的了解到,各种类型的锁之间相互冲突情况。例如:AccessExclusiveLock锁的冲突情况,代表这个锁的冲突情况的bitmask值为1111111110,即跟任何一种锁类型(no lock 除外,表示没有锁)的LOCKBIT ON(lock mode)的值取&,结果都会为真,表示都冲突。
2、LOCKTAG表示加锁对象标识,即锁对象,一个LOCKTAG的值唯一标识一个可加锁对象。定义如下图4所示:

图4:加锁对象标识数据结构
在LOCKTAG结构中,字段locktag_type表示锁对象的类型,具体枚举值前面图1有介绍,字段locktag_lockmethodid表示加锁的方法,即采用如种方式加锁的,采用数据库默认的方式加锁,还是采用用户命令的方式加锁(用户采用select for update, lock table等一些命令),字段locktag_field1~ locktag_field4没有具体指明这些变量的用途,因为针对不同的LockTagType,这些 locktag_field1~ locktag_field4 中保存的数据不一定相同。
比如当LockTagType 为 LOCKTAG_RELATION时,要求的 locktag_field 包括 DB OID +REL OID,当 LockTagType为LOCKTAG_TRANSACTION,则只需要该事务的 XID。
3、LOCK表示加锁对象描述体,用于表示已经加锁的资源或是请求加锁的可锁资源,定义如下图5所示:

图5:加锁对象描述体数据结构
其中字段tag表示为加锁对象的描述符即锁对象,字段grantMask表示当前在该对象上分配的所有锁模式的掩码,字段waitMask表示当前在该对象上等待的所有锁模式的掩码,字段procLocks表示这个对象锁上的所有进程PROCLOCK对象队列,字段waitProcs表示等待该对象上锁的进程的等待队列,字段requested[MAX_LOCKMODES]表示记录每种模式的锁请求(持有+等待)该锁的次数,字段nRequested表示requested数组元素的个数,即所有的锁模式的锁请求的总的数量,字段granted[MAX_LOCKMODES]表示每一种锁模式上的已分配的锁的数量,字段nGranted表示granted数组中元素的个数。
在AntDB-T数据库中,有很多会话可能会同时访问一个对象,这些会话请求的锁模式可能相同,也可能不同,可能兼容,也可能不兼容。为了方便表示所有会话在这个对象上总共加了哪些模式的锁,总共还有哪些处于waiting中,所以采用了一个LOCKMASK(bitmask)来表示这两种情况,其中grantMask、waitMask这2个字段就是用于判断已持锁与请求锁是否冲突。
初始化RegularLock(常规锁)
RegularLock(常规锁)的初始化操作由函数InitLocks(void)实现,该函数初始化锁管理器的数据结构,主要工作有初始化LockMethodLockHash、LockMethodProcLockHash 和 LockMethodLocalHash 这三个 Hash 表。
-
LockMethodLockHash:数据库级别的锁表,为Lock 数据结构创建的hash表hash key 用 LOCKTAG 通过hash函数生成,整个hash表会存储到共享内存中。
-
LockMethodProcLockHash:进程级别的锁表,为 ProcLock 数据结构创建的hash 表,hash key用 PROCLOCKTAG 通过hash函数生成,同样会存储到共享内存中。
-
LockMethodLocalHash:本地锁表,为LocalLock数据结构创建的hash表,LOCALLOCKTAG 通过hash 函数生成hash-key,存储到本地。
加RegularLock(常规锁)
RegularLock(常规锁)的加锁操作在函数LockAcquire(const LOCKTAG *locktag,LOCKMODE lockmode,bool sessionLock,bool dontWait)中定义。
其中参数含义如下:locktag 表示是被锁对象的唯一标识;lockmode指示要获得的锁模式;sessionLock表示加锁的模式,如果为TRUE,表示为会话加锁,如果为FALSE,则为当前事务申请锁;dontWait表示申请锁是否允许等待,如果为 TRUE,则在检查到无法获得锁之后不等待,如果为 FALSE,则可以等待。该函数的返回值LockAcquireResult,它是一个枚举值,表示加锁是否成功等结果信息。
申请加RegularLock(常规锁)的流程如下:
1)用locktag(锁对象)和lockmode(加锁模式)组成一个具体的加锁类型作为hash-key,然后在本地锁表对应的hash表(LockMethodLocalHash)中查找此加锁类型的信息。
2)如果没有找到此加锁类型的信息,则构造一条插入本地锁表中;否则找到此加锁类型的信息,分配空间以记录锁拥有者的信息。
3)如果当前事务已经持有过此类型的锁(locallock->nLocks >0),在本地表的计数器上加1并更新锁资源拥有者里面的计算器也加1,然后直接退出。
4)如果锁模式是AccessExclusiveLock且锁对象是 Relation(表),则会尝试分配一个transactionid(事务id) 来在后续加锁成功之后写一条 WAL record。
5)满足快速锁模式时,加锁并返回加锁成功。加快速锁前提是当前会话之前没有添加过强锁且还有充足的保存弱锁的位置。
6)如果申请的是强锁,则会先将当前进程持有的强锁的计数自增,并将快速锁信息从会话本地转移到主锁表中(共享内存中)。
7)在全局的锁表(LockMethodLockHash)中查找这个锁,如果在“Lock Hash”中找不到,则在"Lock Hash”中插入一个新元素。然后在 ProcLock-Hash (LockMethodProcLockHash)表里也查找对应的 ProcLock,如果在ProcLock Hash表找不到,则插入该ProcLock。
8)检查新增的锁模式会不会与已加的锁模式发生冲突,如果不会,则加锁;否则,根据函数参数决定等待还是退出。如果退出,还需清除锁表中相应的元素以保持一致性。
9)如果是AccessExclusiveLock锁模式,则需要记录一条WAL record。
释放RegularLock(常规锁)
与加RegularLock(常规锁)相对应的操作是解RegularLock(常规锁),RegularLock 的解锁操作定义在函数LockRelease(const LOCKTAG *locktag, LOCKMODE lockmode, bool sessionLock)中定义。
其中参数含义如下:locktag 表示是被锁对象的唯一标识;lockmode指示要获得的锁模式;sessionLock表示加锁的模式,如果为TRUE,表示为会话加锁,如果为FALSE,则为当前事务申请锁。该函数在本地锁表(LockMethodLocalHash)中查找锁标记为LockTag的锁,并释放该锁;如果SessionLock为TRUE,则释放一个会话锁(SessionLock),否则,释放一个常规的事务锁。如果发现任何等待进程现在是可以被唤醒的,将请求的锁赋予它们并将其唤醒。
申请解RegularLock(常规锁)的流程如下:
1)用locktag(锁对象)和lockmode(加锁模式)组成一个具体的加锁类型作为hash-key,然后在本地锁表对应的hash表(LockMethodLocalHash)中查找此加锁类型的信息。
2)找到此类型锁的拥有者,在它持有锁的计数器上减 1。如果它已经不再持有此锁,则删除这个拥有者的信息。
3)如果这个类型的锁并没有真正释放,只是计数器减1,直接退出。
4)如果是快速锁则清除快速锁的加锁标记,如果解锁成功就返回。
5)如果不是快速锁,则在全局的“Lock Hash”(LockMethodLockHash)和"ProcLock Hash”(LockMethodProcLockHash)表里查找此锁对应的 Lock 和 ProcLock,调用UnGrantLock修改其信息。唤醒可以被唤醒的进程,并从“Local Hash"( LockMethodLocalHash)里移除该类型锁。
清理RegularLock(常规锁)
RegularLock(常规锁)的清理在函数 CleanUpLock 中,在释放锁之后执行,主要是清理LockMethodProcLockHash、LockMethodLockHash队列,以及唤醒可以被唤醒的进程。
AntDB-T数据库常规锁使用场景
前面部分介绍了锁相关的理论部分,下面举个常规锁的例子来体会下锁。
1、数据准备:建表,构造数据,具体SQL 如下图6所示:

图6:数据准备
2、会话一执行开始事务和UPDATE语句如下图7所示,此时会话表上的锁模式为RowExclusiveLock 。

图7:开始事务和更新表
3、会话二执行ALTER TABLE语句,这时看到修改表语句处于等待状态,如下图8所示:此时会话表上需要加锁的模式是AccessExclusiveLock,该模式与会话一上持有的锁模式冲突,所以此SQL语句会一直等在那里。

图8:修改表
4、会话三查找锁等待的进程号以及锁信息,如下图9所示:

图9:查找锁等待的进程信息
这里可以看到等待的锁时一个表锁,锁模式是AccessExclusiveLock,pid为541258。
5、会话三根据锁等待的进程pid找到当前持有锁的进程,并查看持有锁进程的详细情况,比如对应的应用、SQL、等待事件等,如下图10所示:

图10:查找锁持有的进程信息
6、验证等待锁、持有锁的进程pid是否正确,用ps查看过滤下想要的进程, 如下图11所示:

图11:验证等待锁持有锁的进程pid
从上图11中可以看出,等待锁的进程pid 为541258 在执行ALTER TABLE操作,与图9查出的进程pid一致,持有锁的进程pid为541046,处在空闲事务状态,与图10查出的进程pid一致。会话二语句目前一直等在那里,要等到会话一结束,才能执行成功。如果会话一忘记COMMIT/ROLLBACK了,也不要太担心,AntDB-T数据库提供了一些超时参数,当超过配置的参数时,就会自动结束会话。
-
参数idle_in_transaction_session_timeout:在一个空闲的事务中,空闲时间超过这个值,将视为超时,0表示禁用,一般默认都是禁用。获取一个表,索引,行上的锁超过这个时间,直接报错,不等待,0为禁用.
-
参数lock_timeout:获取一个表,索引,行上的锁超过这个时间,直接报错,不等待,0为禁用。
-
参数statement_timeout:当SQL语句的执行时间超过这个设置时间,终止执行SQL,0为禁用。
-
参数deadlock_timeout:死锁时间超过这个值将直接报错,不会等待,默认设置为1s。
总结与展望
本文主要讲述了AntDB-T数据库锁的分类、常规锁的基本概念、常规锁的设计以及常规锁具体使用的场景。限于篇幅原因,与常规锁相关的死锁检测、行锁等相关内容没有涉及,以后有机会将会进行分享。
在未来,随着云计算、大数据和人工智能等技术的持续发展,数据的应用场景和规模也将不断扩大。为了满足不同的数据应用需求,AntDB-T数据库的锁机制也将不断升级和优化。通过与其他数据库技术相结合,更好地满足企业和用户的需求,成为企业数据应用的重要保障和支持,为数据的安全和可靠性保驾护航。
关于亚信安慧AntDB数据库
AntDB数据库始于2008年,在运营商的核心系统上,服务国内24个省市自治区的数亿用户,具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔通信核心交易,保障系统持续稳定运行超十年,并在通信、金融、交通、能源、物联网等行业成功商用落地。