使用MMYOLO中yolov8训练自己VOC数据集实战
概述
MMYOLO是商汤公司基于PyTorch框架和YOLO系列算法开源的工具箱
- 目前支持的任务
- 目标检测
- 旋转框目标检测
- 支持的算法
- YOLOv5
- YOLOv6
- YOLOv7
- YOLOv8
- YOLOX
- RTMDet
- RTMDet-Rotated
- 支持的数据集
-
COCO Dataset
-
VOC Dataset
-
CrowdHuman Dataset
-
DOTA 1.0 Dataset
安装和验证
conda create -n mmyolo python=3.8 -y
conda activate mmyolo
# 如果你有 GPU
conda install pytorch torchvision -c pytorch
# 如果你是 CPU
# conda install pytorch torchvision cpuonly -c pytorch
git clone https://github.com/open-mmlab/mmyolo.git
cd mmyolo
pip install -U openmim
mim install -r requirements/mminstall.txt
# Install albumentations
mim install -r requirements/albu.txt
# Install MMYOLO
mim install -v -e .
# "-v" 指详细说明,或更多的输出
# "-e" 表示在可编辑模式下安装项目,因此对代码所做的任何本地修改都会生效,从而无需重新安装。
请参考以下链接
link
一,数据集准备
1. voc 转labelme
虽然官方显示支持VOC格式的数据集,但是只找到由labelme转换yolo的的示例,因此我先将voc格式转yolo,
1.1 voc格式如下
VOCdevkit/
VOC2007/
Annotations/
JPEGImages/
1.2转换后的格式如下

1.3 转换代码如下
'''
VOC格式转换为labelme的json格式
-------------------
VOCdevkit/
VOC2007/
Annotations/
JPEGImages/
----------------
python voc_to_labelme.py
命令行参数解释:
--voc_dir VOC数据集目录,默认VOCdevkit/VOC2007
--labelme_version Labelme版本号,默认3.2.6
--labelme_shape Labelme标记框形状,支持rectangle或polygon,默认rectangle
--image_data Labelme的imageData节点是否输出数据,默认True
--out_dir Labelme格式数据集的输出目录
'''
import argparse
import glob
import base64
import logging
import io
import os
import PIL
import PIL.Image
import xml.etree.ElementTree as ET
import json
import shutil
def parse_opt(known=False):
parser = argparse.ArgumentParser(description='xml2json')
parser.add_argument('--voc_dir', default='/home/ai-developer/桌面/VOCdevkit/VOC2007', help='voc directory')
parser.add_argument('--labelme_version', default='5.1.1', help='labelme version')
parser.add_argument('--labelme_shape', default='rectangle', help='labelme shape')
parser.add_argument('--image_data', default=True, type=bool, help='wether write image data to json')
parser.add_argument('--out_dir', default='/home/ai-developer/桌面/labelme', help='the path of output directory')
opt = parser.parse_args()
return opt
def read_xml_gtbox_and_label(xml_path):
tree = ET.parse(xml_path)
root = tree.getroot()
size = root.find('size')
width = int(size.find('width').text)
height = int(size.find('height').text)
depth = int(size.find('depth').text)
points = []
for obj in root.iter('object'):
cls = obj.find('name').text
pose = obj.find('pose').text
xmlbox = obj.find('bndbox')
xmin = float(xmlbox.find('xmin').text)
xmax = float(xmlbox.find('xmax').text)
ymin = float(xmlbox.find('ymin').text)
ymax = float(xmlbox.find('ymax').text)
point = [cls, xmin, ymin, xmax, ymax]
points.append(point)
return points, width, height
def voc_bndbox_to_labelme(opt):
xml_dir = os.path.join(opt.voc_dir,'Annotations')
img_dir = os.path.join(opt.voc_dir,'JPEGImages')
if not os.path.exists(opt.out_dir):
os.makedirs(opt.out_dir)
xml_files = glob.glob(os.path.join(xml_dir,'*.xml'))
for xml_file in xml_files:
_, filename = os.path.split(xml_file)
filename = filename.rstrip('.xml')
# print('filename',filename)
img_name = filename + '.jpg'
img_path = os.path.join(img_dir, img_name)
points, width, height = read_xml_gtbox_and_label(xml_file)
json_str = {}
json_str['version'] = opt.labelme_version
json_str['flags'] = {}
shapes = []
for i in range(len(points)):
cls, xmin, ymin, xmax, ymax = points[i]
shape = {}
shape['label'] = cls
if opt.labelme_shape == 'rectangle':
shape['points'] = [[xmin, ymin],[xmax, ymax]]
else: #polygon
shape['points'] = [[xmin, ymin],[xmax, ymin],[xmax, ymax],[xmin, ymax]]
shape['group_id'] = None
# shape['fill_color'] = None
shape['shape_type'] = opt.labelme_shape
shape['flags'] = {}
shapes.append(shape)
json_str['imagePath'] = "../images/"+img_name
json_str['imageData'] = "null"
json_str['imageHeight'] = height
json_str['imageWidth'] = width
json_str['shapes'] = shapes
target_path = os.path.join(opt.out_dir,img_name)
shutil.copy(img_path, target_path)
json_file = os.path.join(opt.out_dir, filename + '.json')
with open(json_file, 'w') as f:
json.dump(json_str, f, indent=2,ensure_ascii=False)
def main(opt):
voc_bndbox_to_labelme(opt)
if __name__ == '__main__':
opt = parse_opt()
main(opt)
1.4.转换后的效果图

1.5,使用MMYOLO脚本将labelme的label转换为COCO的label:
python tools/dataset_converters/labelme2coco.py --img-dir ${图片文件夹路径} \
--labels-dir ${label 文件夹位置} \
--out ${输出 COCO label json 路径} \
[--class-id-txt ${class_with_id.txt 路径}]
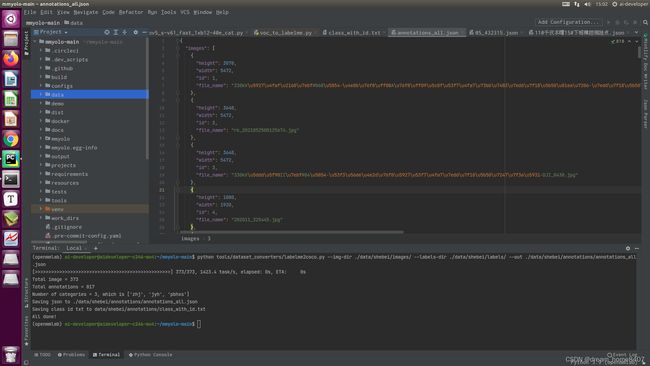
1.6 检查转换的 COCO labe
python tools/analysis_tools/browse_coco_json.py --img-dir ${图片文件夹路径} \
--ann-file ${COCO label json 路径}
1.7 数据集划分为训练集、验证集和测试集
python tools/misc/coco_split.py --json ${COCO label json 路径} \
--out-dir ${划分 label json 保存根路径} \
--ratios ${划分比例} \
[--shuffle] \
[--seed ${划分的随机种子}]

1.7 修改config文件
1.8 数据集可视化分析
python tools/analysis_tools/dataset_analysis.py configs/custom_dataset/yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py \
--out-dir work_dirs/dataset_analysis_cat/train_dataset
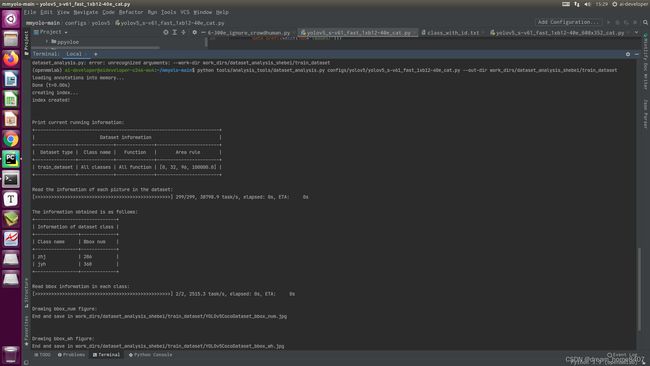
1.9 计算anchor
python tools/analysis_tools/optimize_anchors.py configs/custom_dataset/yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py \
--algorithm v5-k-means \
--input-shape 640 640 \
--prior-match-thr 4.0 \
--out-dir work_dirs/dataset_analysis_cat

2.0 开始训练

2.1 推理
python demo/image_demo.py ./test_images/ ./work_dirs/yolov8_shebei/yolov8_s_fast_1xb12-40e_cat.py ./work_dirs/yolov8_shebei/epoch_80.pth --out-dir ./result/
或者
from mmdet.apis import init_detector, inference_detector
config_file = '/home/ai-developer/mmyolo-main/work_dirs/yolov8_s_fast_1xb12-40e_cat/yolov8_s_fast_1xb12-40e_cat.py'
checkpoint_file = '/home/ai-developer/mmyolo-main/work_dirs/yolov8_s_fast_1xb12-40e_cat/epoch_40.pth'
model = init_detector(config_file, checkpoint_file, device='cuda') # or device='cuda:0'
result=inference_detector(model, '/home/ai-developer/mmyolo-main/test_images/rk_2021052500119850.jpg')
pred_instances = result.pred_instances[
result.pred_instances.scores >0.3]
# dataset_classes = model.dataset_meta.get('classes')
# print('dataset_classes:-----------------------',dataset_classes)
# print(pred_instances['scores'])
# print(pred_instances['labels'])
# print(pred_instances['bboxes'])
for i in range(0,len(pred_instances['scores'])):
result_list = []
result_list.append(float(pred_instances['scores'][i]))
result_list.append((pred_instances['labels'][i]).tolist())
result_list.append((pred_instances['bboxes'][i]).tolist())
print(result_list)