Linux | makefile简单教程 | Makefile的工作原理
前言
在学习完了Linux的基本操作之后,我们知道在linux中编写代码,编译代码都是要手动gcc命令,来执行这串代码的。
![]()
但是我们难道在以后运行代码的时候,难道都要自己敲gcc命令嘛?这是不是有点太烦了?
在vs中,我们编写好代码之后,直接点击构建项目,就会直接帮我们自动化构建好了,我们在linux中构建的时候,有的时候上百个文件,还是比较麻烦的,所以到底有没有一些简单的做法呢?当然是有的啦~
这个工具呢就是Makefile/make项目自动化构建工具。
- 会不会写Makefile,从一个侧面说明了一个人是否具有完成大型工程的能力;
- 一个工程的源文件不计其数,其按类型、功能、模板分别放在一个若干个目录中,Makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作;
- Makefile带来的好处就是——自动化编译。一旦写好,只需要一个make命令,整个工程就完成自动化编译,极大提高了软件开发的效率;
- make是一个命令工具,是一个解释Makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,visual C++的make,linux下GNU的make。可见,Makefile都成为了一种在工程方面的编译方法。
- make是一个命令,Makefile是一个文件,两个搭配使用,完成项目自动化构建。
实例理解
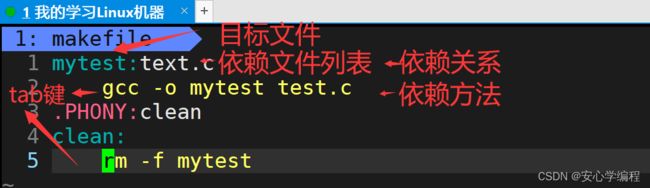
在上图中,mytest:text.c与gcc -o mytest test.c是匹配的,clean:与rm -f mytest是匹配的。这两组中的每个第一句是依赖关系,两组的下面称为依赖方法。
Makefile实现原理
以图为例(与上图例子一致,为了方便大家查看,就在下面也放一份):
Makefile文件写好之后,当我们实际在命令行运行make的时候,对应的make程序,会在当前目录下找这个Makefile,读取Makefile里面的内容:
- make会根据Makefile里面的内容,完成编译、清理工作。
- 根据Makefile里面的依赖关系,将依赖关系以依赖方法形成目标文件。
(如上图:编译器就会知道依赖关系test.c文件形成mytest的目标文件,那么怎么形成呢?就是根据对应的gcc -o mytest test.c这样的依赖方法)
依赖关系
那么到底如何理解依赖关系和依赖方法呢?
这里就给大家将一个小故事咯~便于大家理解:
小明是某大学里的在校生,这天他没有生活费了。他就打电话给那个人:“爸!我是你儿子!”在小明看来,你是我爸你就应该给我生活费;但是在老爹看来,你小子说这话是啥意思?你想干啥?老爹是一脸懵啊。小明挂了电话之后,就又想了想:“爸!我是你儿子!给我点生活费!”这下他老爹才懂了,原来他儿子没有生活费了,想要生活费。
所以在上面的小故事中,“我是你儿子”就是依赖关系,“给我点生活费”就是依赖方法。在日常生活中,我们也难免得需要拜托谁做一件什么事,在计算机中也是一样的,完成一件事的必然要素少不了依赖关系与依赖方法。
在上图中的依赖关系如下:

其实,我们知道程序翻译运行的过程为:预处理、编译、汇编和链接。
| 翻译的过程 |
gcc命令 |
说明 |
|
| 预处理 (进行宏替换) |
gcc -E test.c -o test.i |
-E 让gcc在预处理结束后,就停止编译 “从现在开始进行程序的翻译,预处理完成,就停下来” |
宏替换 去注释 头文件展开 条件编译 生成.i文件 |
| 编译 (生成编译) |
gcc -S test.i -o test.s |
-S 只进行编译不进行汇编,生成汇编代码 “从现在开始进行程序的编译,汇编完成就停下来” |
检查代码规范性 检查语法错误 (确认无误后汇编) 将C语言代码翻译成汇编语言 生成.s文件 |
| 汇编 |
gcc -C test.o -o test.o |
-C “从开始带现在进行程序的翻译”,汇编完成就停下来 |
将汇编语言编译成二进制目标文件 生成.o文件 |
| 链接 |
gcc test.o -o my.exe |
形成可执行程序 生成.exe文件 |
|
所以将上面gcc -o mytest test.c指令写完整就是如下:


诶?很奇怪啊,怎么感觉顺序呢不太对?在这里我们就要说一下Makefile的工作原理了:
- Makefile在执行过程中,是从上往下进行扫描的;
- 当它看到的第一个文件时,其实并不是.c文件,第一个是.o文件;
- 也就是识别的从上往下,第一组依赖关系;
- 可是识别的依赖关系中的.o文件并不存在,所以它下面的命令,也就是依赖方法不能被执行,就无法形成可执行程序;
- 所以Makefile就会自动在后续,继续再找下一组依赖关系,根据下一组依赖关系来形成.o文件;
- 但是在形成.o文件还是需要依赖.s文件,依次类推直到遇到依赖文件存在.c文件;
- 所以存在.c文件,就会有.i文件、.s文件以及.o文件;
- 所以就下往上执行了,很类似与递归问题。
在上图中:
- 上面的文件 mytest ,它依赖 mytest.o
- mytest.o , 它依赖 mytest.s
- mytest.s , 它依赖 mytest.i
- mytest.i , 它依赖 mytest.c
- make、Makefile会自动根据文件中的依赖关系,进行自动推导,帮助我们执行所有相关的依赖方法。
这里注意一下,因为Makefile就是类似于一个选择器,里面包含了各种指令的选项,但是一般默认智慧运行第一个依赖关系所对应的指令,所以上面的各组依赖关系是可以乱序的,但是必须要将最重要的一条指令放在最前面,如下图:
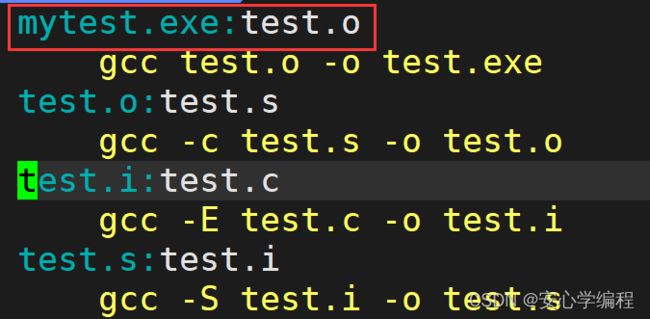
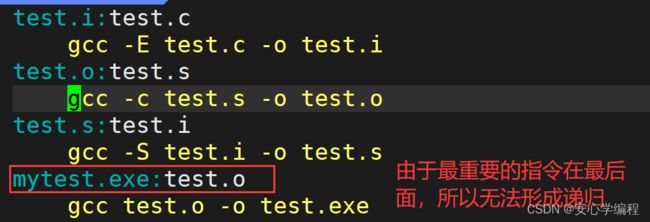
上面的依赖关系,是为了让大家能够理解,这里不建议大家写成这样,直接就gcc -o mytest test.c指令就可以。
依赖文件列表
依赖文件列表可以为多个文件,按照空格分割分。

mytest:依赖文件1 依赖文件2 依赖文件3 ... ![]()
我们刚刚也说了clean:与rm -f mytest是匹配的。根据上图我们也不难看出,clean后面是空的,也就是说clean不依赖任何文件,也就是说:
- 依赖文件列表可以为空。
依赖方法
依赖方法的指令前必须打一个[Tab]键,按四下空格会报错。
![]()
![]()
多条依赖方法
- 依赖方法不限于一条,可以是多条的。
项目清理
.PHONY含义
在Makefile文件执行的时候,如下图,我们发现在使用make的时候默认执行的是Makefile文件中的第一对的依赖关系和依赖方法:
- Makefile默认形成第一个可执行文件。
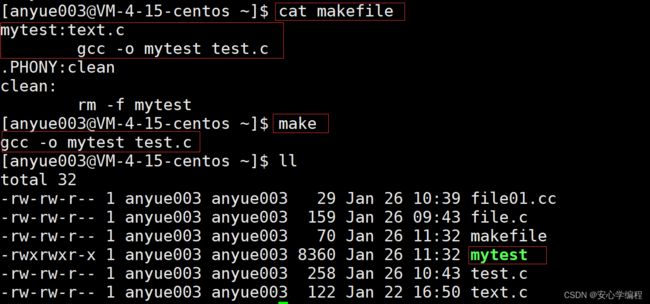
其次,我们看下边运行过程:
make: `mytest' is up to date. :当前可执行程序是最新的。
- 所以Makefile会在源代码的内容没有修改,没有变化时,Makefile默认就会拦截再一次的make命令。

那么如果今天我们就想让其一直执行,不要拦截,即使在没有被修改源码的情况下,也要让make指令一直执行,那么怎么做呢?只需要:
- .PHONY : XXX
- XXX对应的方法总是要被执行的。


当然我们理解了原理之后,小编还是建议大家之后再清理的命令加上总是可执行即可。所以我们目前标准的就是以下5行:

以后我们需要的Makefile文件
通配符认识
| 符号 | 含义 |
|---|---|
| $^ | 所有依赖文件列表 |
| $@ | 所有目标文件 |
| $< | 所有依赖文件的第一个文件 |
在这里,我们可以将$,理解为取内容。
如下图,gcc在编译的过程,Makefile会自动进行符号替换:
- 把对应的$@就会自动替换为目标文件;
- 把对应的$^就会自动替换为所有依赖文件。

变量
Makefile也是支持变量的。但是并不是之前学习的编程语言中的整形、浮点型int/double=1/1.0等等。Makefile是解释性的,所以它的变量直接就是符号,比如说,“‘形成的可执行程序’为‘XX’”:
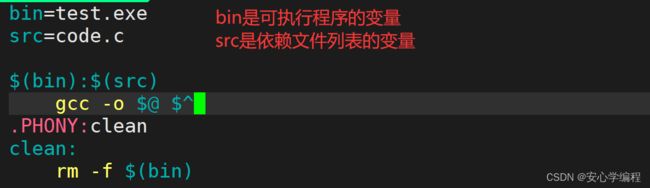
- bin是“目标文件可执行程序”的变量 ;
- src是“依赖文件列表”的变量;
- $可以理解为去内容;
- $(bin):取出bin变量中的内容,即目标文件;
- $(src):取出src变量中的内容,即依赖文件列表;
- $@:所有的目标文件;
- $^:所有的依赖文件列表。
在执行make的时候,Makefile就会进行变量替换,可以理解成为宏的替换,也可以执行程序。
将来你可能会有很多地方遇到使用make的项目与文件,那就只需要将变量的内容修改,就可以完成不同文件的make指令进行执行,就会很简单方便。
make指令打印隐藏
在命令行输入make指令之后,系统都会自己打印出我们底层所输入的依赖方法对应的指令,那么如何将make指令进行隐藏也就是让它不再打印呢?
直接在命令前面加一个“@”符号:
![]()
推荐使用的Makefile模板
bin=test.exe
src=test.c
@gcc -o $@ $^
@echo "compiler $(src) to $(bin)..."
.PHONY:clean
clean:
@rm -f $(bin)
@echo "clean project..."
- 其中echo是打印字符串。
如下图就会有提示信息:

必熟知知识
为什么Makefile对最新的可执行程序,默认不想重新形成?
今天,我们编译的代码只有一个源文件,以后我们编译的源代码是两千个源文件,成百上千个源文件,在我们修改bug的时候,可能只是修改几行代码,做完改动之后,如果我们要将所有的源文件重新编译一遍,那么就是效率很低,又或者说,如果我们没有修改,又make的话,那么编译器又会重新编译,假如一个文件需要用0.1秒,那么成百上千个代码就需要十几分钟甚至几个小时,所以效率是极其低的。
- 所以在Makefile为了调高效率,就默认对最新的可执行程序,不重新形成。
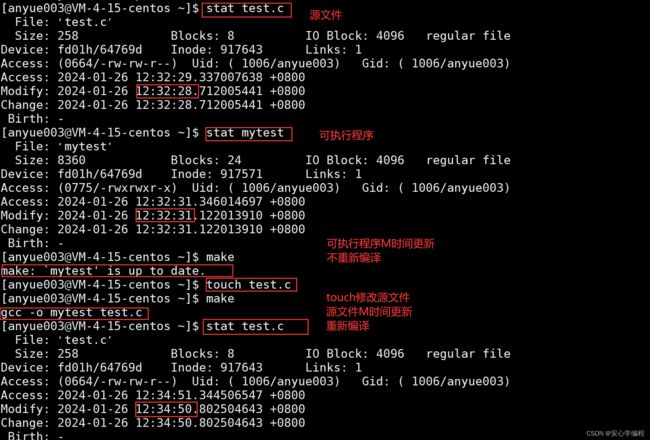
Makefile怎么知道程序需要被编译的呢?
ACM时间是Linux系统下分别代表Access,Modify和Change三个时间。
- Access:文件最近被访问的时间(访问)
- Modify : 文件内容最近被修改的时间(修改)
- Change : 文件属性最近被修改的时间(改变)

当然我们要知道的是:
- 源代码与可执行程序的文件内容最近被修改的时间(修改)一定是不同的。
因为我们基本先写源代码,再进行编译;所以可执行程序一般是比源代码的时间更新的。如果修改的源代码,那么此时源代码比可执行程序的时间更新,所以就需要重新编译。
Makefile怎么知道程序需要被编译的呢?
- 对比可执行程序的最近修改时间和源文件最近的修改时间,谁更新。如果可执行程序更新,就不需要重新编译了;反之,源文件更新,就需要重新编译。
所以我们在用vs写代码的时候,出现错误 ,再修改了很多次,仍旧报这个错误,这个时候,可以重新清理一下,重新构建一下,重新生成解决方案,这个问题就会可能解决。