深入理解java之字符串String类型
一。简介
java中String不是基本数据类型,String中之所以能够保存字符串是因为其中定义了一个数组。
源码:

通过上图可以发现 定义了一个char型数组
二、字符串的比较
public class StringDemo {
public static void main(String[] args) {
String strA= "abc";
String strB=new String("abc");
System.out.println(strA==strB);
}
}
结果:false
如上,字符串内容虽然相同,但是==的结果却是false,若是想要实现比较字符串内容的比较,需要用equals方法。
public class StringDemo {
public static void main(String[] args) {
String strA= "abc";
String strB=new String("abc");
System.out.println(strA.equals(strB));
}
结果:true
equals源码:
public boolean equals(Object anObject) {
//比较传入对象的地址是否相等,如果相等返回true
if (this == anObject) {
return true;
}
//如果地址不相等继续比较字符串的内容(instanceof是判断传入的参数是不是String的实例)
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
//判断当前字符数组长度是否等于入参的字符数组长
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
说明:
●String中的equals方法是被重写过的,因为Object的equals方法是比较的
对象的内存地址,而String的equals方法比较的是对象的值。
●
当创建String类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要
创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创
建一个String对象。
ps:这里介绍一个典型的面试题:
请解释String比较中“==”与equals()区别?
- == :进行的是数值比较,如果用于对象比较上比较的是两个内存的地址数值。
- equals() :是类所提供的一个比较方法,可以直接进行字符串内容比较。
三。String的实例化方式
1.直接赋值方式
public class StringDemo {
public static void main(String[] args) {
String strA = "abc";
String strB = "abc";
System.out.println(strA == strB);
}
}
结果:true
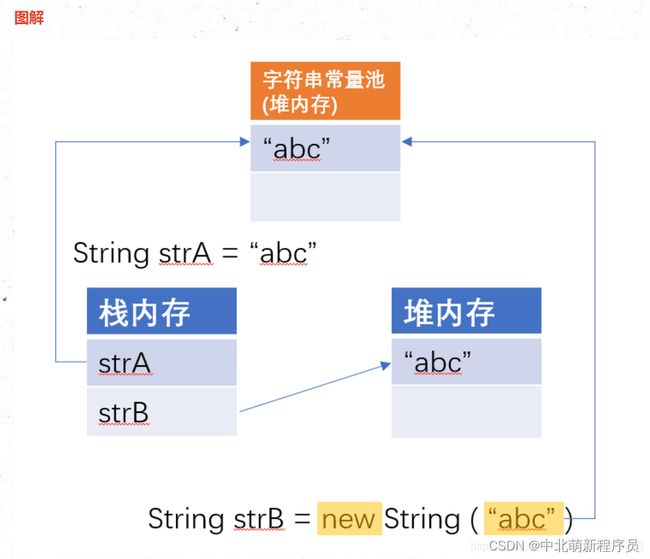
如上,==返回结果是true,因为Java底层专门提供了一个字符串常量池,在给strB赋值时,会首先去字符串常量池中查找是否有这个值,没有的话会在常量池中加入,有的话会直接将其地址给strB。
图解:

2.构造方法实例化

构造方法实例化,会构造两块堆内存空间,只使用一块,匿名对象开辟的内存空间会成为垃圾空间。
String strA = new String( “abc” );
构造方法实例化String对象不会自动保存到字符串常量池中。
所以以下执行的结果为false
public class StringDemo {
public static void main(String[] args) {
String strB=new String("abc");
String strA= "abc";
System.out.println(strA==strB);
}
}
字符串字面量:
1.当你使用字符串字面量创建字符串时,Java 会检查字符串池(String Pool)。
2.如果池中已经存在相同内容的字符串,那么将会返回池中的引用,而不是创建新的对象。
3. 这是为了节省内存,避免创建多个相同内容的字符串对象。
解释:
- 在代码中,strA 直接使用字符串字面量 “abc”,Java 会检查字符串池,看是否已经存在 “abc”,如果存在则返回池中的引用。
- 当使用 new String(“abc”) 时,它会创建一个新的字符串对象,不管字符串池中是否已经存在相同内容的字符串。 即使字符串内容相同,使用 new String() 会强制创建一个新的对象。
- 在代码中,strB 和 strA 指向的是两个不同的对象,尽管它们的内容相同。所以,strA == strB 返回 false。要比较字符串内容是否相同,应该使用 equals() 方法而不是 ==。
但是构造方法有办法实现手动入池的操作,即intern方法,如下结果就是true,因为都引用的常量池里的"abc"
public class StringDemo {
public static void main(String[] args) {
String strB=new String("abc").intern();
String strA= "abc";
System.out.println(strA==strB);
}
}
ps:这里再介绍一个典型的面试题:
请解释String中两种对象实例化方法的区别?
- 直接赋值:只会产生一个实例化对象,并且可以自动保存到String对象(常量)池
- 构造方法:会产生两个实例化对象,并且不会自动入池,但是可以利用intern方法。
想要了解为啥产生两个实例化对象可以看这个 理解
String stra="zhangsan";
String strb="zhangsan";
System.out.println(stra==strb);//true
String str1=new String("zhangsan");
String str2=new String("zhangsan");
System.out.println(str1==str2);//false
String str3=new String("zhangsan").intern();
String str4=new String("zhangsan").intern();
System.out.println(str3==str4);//true
四. String对象(常量)池
1.常量池(String pool)
- String 的字符串常量池(String Pool)是一个固定大小的HashTable(数组+链表的数据结构),故不存在两个相同的字符串。也叫StringTable。
- StringTable是放在本地内存的,是C++写的,里面放的是字符串对象的引用,真实的字符串对象是在堆里。
- JDK8字符串常量池放到堆空间,其引用指向元空间(方法区)的常量池。常量池设计 就是一种缓存池,为了提高程序性能。
- 为字符串开辟一个字符串常量池,类似于缓存区
- 创建字符串常量时,首先查询字符串常量池是否存在该字符串
- 存在该字符串,返回引用实例,不存在,实例化该字符串并放入池中
对象池主要的目的是为了实现数据的共享,在Java中String对象池分为两种:
- 字符串常量池String Table的数据结构是一个哈希表,但是这个哈希表与Java集合中的哈希表不用,无法进行扩容操作,并且字符串种类复杂,很可能发生哈希碰撞现象,一旦字符串在哈希表中形成了链表等数据结构,就会使字符串常量池的性能下降,所以字符串常量池中需要加入垃圾回收机制。
| 类别 | 解释 |
|---|---|
| 静态常量池 | 指的是程序在加载的时候会自动将此程序中保存的字符串、常量、类和方法等,全部进行分配; |
| 运行时常量池 | 当一个程序加载之后,里面可能有一些变量,这个时候提供的常量池。 |
静态常量池与运行时常量池
静态常量池
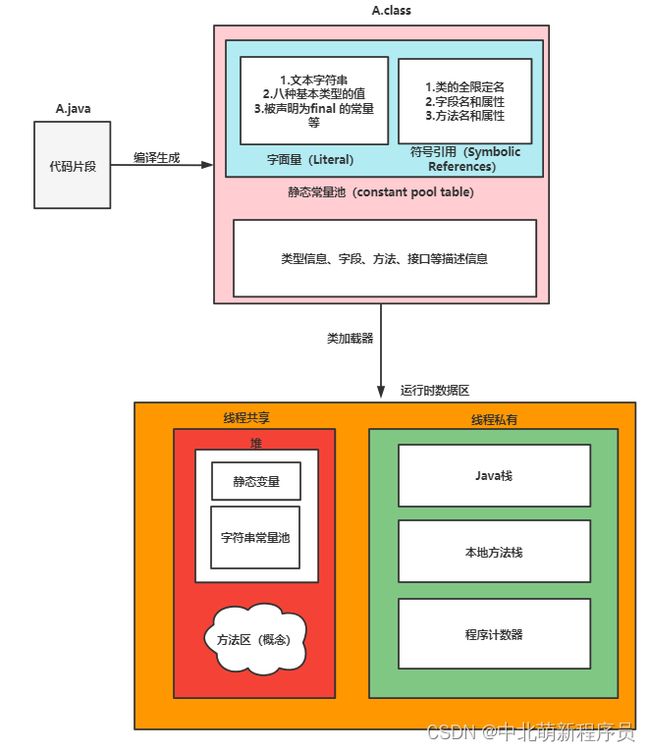
像这些静态的、未加载的.class文件的数据被称为静态常量池,但经过jvm把.class文件装入内存、加载到方法区后,常量池就会变为运行时常量池

当类加载到内存中后,jvm就会将class常量池中的内容存放到运行时常量池中,运行时常量池存在于内存中,也就是class常量池被加载到内存之后的版本。
不同之处是:它的字面量可以动态的添加(String#intern()),符号引用可以被解析为直接引用。
简单来说,HotSpot VM(虚拟机)里StringTable是个哈希表,里面存的是驻留字符串的引用(而不是驻留字符串实例自身)。也就是说某些普通的字符串实例被这个StringTable引用之后就等同被赋予了“驻留字符串”的身份。这个StringTable在每个HotSpot VM的实例里只有一份,被所有的类共享。类的运行时常量池里的CONSTANT_String类型的常量,经过解析(resolve)之后,同样存的是字符串的引用;解析的过程会去查询StringTable,以保证运行时常量池所引用的字符串与StringTable所引用的是一致的。
| 字符串常量池 |
|---|
| 字符串常量池 |
| 本质就是一个哈希表 |
| 存储的是字符串实例的引用 |
| 在被整个JVM共享 |
| 在解析运行时常量池中的符号引用时,会去查询字符串常量池,确保运行时常量池中解析后的直接引用跟字符串常量池中的引用是一致的 |
2.字符串常量池的优点
为了避免频繁的创建和销毁对象而影响系统性能,实现了对象的共享。
例如字符串常量池,在编译阶段就把所有的字符串文字放到一个常量池中。
- 节省内存空间:常量池中所有相同的字符串常量被合并,只占用一个空间。
- 节省运行时间:比较字符串时,比equals()快。对于两个引用变量,只用判断引用是否相等,也就可以判断实际值是否相等。
3.字符串拼接中的细节
- 常量与常量的拼接结果在常量池,原理是编译期优化
- 常量池中不会存在相同内容的变量
- 拼接前后,只要其中有一个是变量,结果就在堆中。变量拼接的原理是StringBuilder
- 如果拼接的结果调用intern()方法,根据该字符串是否在常量池中存在,分为:
- 如果存在,则返回字符串在常量池中的地址
- 如果字符串常量池中不存在该字符串,则在常量池中创建一份,并返回此对象的地址
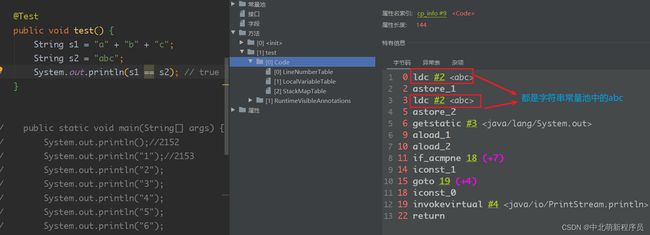
示例1: 常量之间的拼接会进行编译期优化
@Test
public void test() {
String s1 = "a" + "b" + "c";
String s2 = "abc";
System.out.println(s1 == s2); // true
}
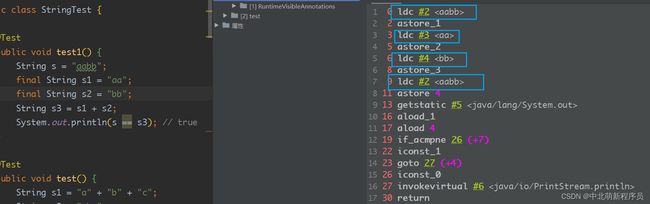
@Test
public void test1() {
String s = "aabb";
final String s1 = "aa";
final String s2 = "bb";
String s3 = s1 + s2;
System.out.println(s == s3); // true
}
示例2:变量与常量、变量与变量拼接
@Test
public void test2() {
String s1 = "a";
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
System.out.println(s3 == s4); // false
}
此时的结果为false,这是因为在拼接过程中实现拼接功能的实际是StringBuilder对象,先创建出一个StringBuilder对象,然后调用StringBuilder中的append方法,最后调用toString方法将其转化成一个String类型的对象。所以最后s4的地址是一个String类的对象,而s3是字符串常量池当中的引用,最终结果为false。
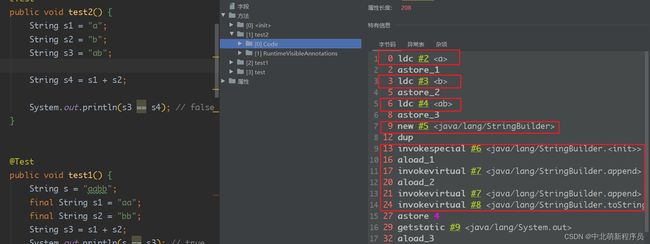
4.intern()方法
说明
intern() 是一种手动将字符串加入常量池中的方法,其优点是执行速度非常快,直接使用==进行比较要比使用equals()方法快很多;内存占用少。但是intern()方法每次操作都需要与常量池中的数据进行比较,查看常量池中是否存在等值数据,所以其主要适用于有限值,并且这些有限值会被重复利用的场景,这样可以减少内存消耗,同时在进行比较操作时减少时耗,提高程序性能。
- String中的intern()方法是一个native方法
public native String intern();
-
字符串常量池池最初是空的,由String类私有地维护。在调用intern方法时,如果池中已经包含了由equals(object)方法确定的与该字符串内容相等的字符串,则返回池中的字符串地址。否则,该字符串对象将被添加到池中,并返回对该字符串对象的地址。
-
如果不是用双引号声明的String对象,可以使用String提供的intern方法:intern方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中。
new Stirng()的细节说明
下面的代码中一共创建了几个对象呢?
@Test
public void test4() {
String s = new String("hello");
}
来看一下字节码指令当中的信息:
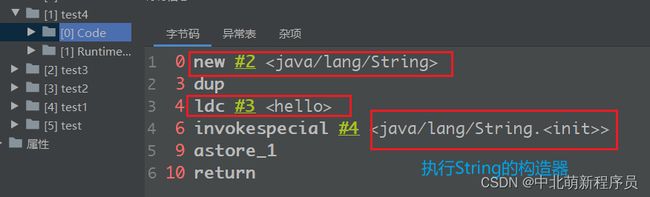
先是创建了一个String类型的对象,然后引入了常量池中的"hello",最后执行了Stirng的构造器。所以一共有两个对象产生。
new Stirng(“xxx”) + new String(“xxx”) 的细节说明
@Test
public void test5() {
String s = new String("Hello") + new String("World");
}
字节码指令当中的细节:

实际上先是创建了一个StringBuilder类的对象,然后调用了StringBuilder的构造器,再从常量池中引入"Hello",创建出一个String类的对象,调用StringBuilder中的append方法将"Hello"加入,之后同样,引入"World",然后创建一个String类的对象,再次appen方法,最后调用StringBuilder中的toString方法。
为什么打印结果输出false呢?
public void test6() {
String s = new String("Hello") + new String("World");
String s2 = "HelloWorld";
System.out.println(s == s2);// false
}
这是因为StringBuilder中的toString()方法:
实际上调用了String类的构造法新建了一个String,而在这个String中只是将原来的char[]中的内容进行了复制,然后将复制的引用返回。所以toString()返回的是一个String类的对象引用,而不是常量池中的引用,所以最后结果是false
@Override
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
//
public String(char value[], int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= value.length) {
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
if (offset > value.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
this.value = Arrays.copyOfRange(value, offset, offset+count);
}
关于intern() 方法的面试题
打印结果是什么呢?为什么是这样的结果呢?
public class StringTest {
public static void main(String[] args) {
// 问题一:
String s = new String("1");
String s1 = s.intern();// 调用此方法之前,字符串常量池中已经存在了"1",所以返回"1"在常量池当中的引用
String s2 = "1";
System.out.println(s == s2);// jdk6:false jdk7/8:false
System.out.println(s1 == s2); // true
// 问题二:
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";// s4变量记录的地址:使用的是上一行代码代码执行时,在常量池中生成的"11"的地址
System.out.println(s3 == s4);// jdk6:false jdk7/8:true
}
}
问题一在注释中以及说明,所以重点来看问题二
首先要明白实际在内存中的细节,才能知道为什么在jdk6中是false,而jdk6之后是true
先来看jdk6中的分析:
-
两个new String()的相加的操作实际上是创建了一个StringBuilder对象进行append操作,最后调用toStirng方法返回一个String类型对象的引用,将其赋给了s3。
-
在调用了intern方法后将"11"加入到常量池中,再此之前常量池是没有"11"的,该方法返回的结果是常量池中的引用
-
而s4直接就是字符串常量池中的引用
-
最后进行比较,s3是String类型对象引用,s4是常量池中的直接引用,所以结果是false。

再来看jdk7/8中的分析: -
同样两个new String()的相加的操作实际上是创建了一个StringBuilder对象进行append操作,最后调用toStirng方法返回一个String类型对象的引用,将其赋给了s3。
-
但是调用intern方法时会对其进行优化,发现在堆区域中已经有了"11"这个内容,于是就堆区中的String类型对象的引用在方法区中保存。
-
因为对字符串常量池进行了优化,所以 s3的值也是在堆中的String类型对象的引用值。
-
最后两者地址值相同,结果为true

拓展
public class StringTest {
public static void main(String[] args) {
//执行完下一行代码以后,字符串常量池中,是否存在"11"呢?
String s3 = new String("1") + new String("1");//new String("11")
//在字符串常量池中生成对象"11",代码顺序换一下,实打实的在字符串常量池里有一个"11"对象
String s4 = "11";
String s5 = s3.intern();
// s3 是堆中的 "ab" ,s4 是字符串常量池中的 "ab"
System.out.println(s3 == s4);//false
// s5 是从字符串常量池中取回来的引用,当然和 s4 相等
System.out.println(s5 == s4);//true
}
}
JDK6和JDK7中该方法的功能是一致的,不同的是常量池位置的改变(JDK7将常量池放在了堆空间中),下面会具体说明。intern的方法返回字符串对象的规范表示形式。其中它做的事情是:首先去判断该字符串是否在常量池中存在,如果存在返回常量池中的字符串,如果在字符串常量池中不存在,先在字符串常量池中添加该字符串,然后返回引用地址
五.String
1.不可变性(为什么呢) 传送门(点我)
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
}
2.定义方式
- 字面量的方式
字面量,常量和变量之间的区别?传送门(点我)
String s1 = "hello";
- new的方式
String s1 = "hello";
String str = new String("hello");
- intern()的方式
如果不是用字面量的方式定义的String对象,可以使用String提供的intern方法:intern方法会从字符串常量池中查询当前字符串是否存在,若存在则返回其引用;若不存在就会将当前字符串放入常量池中,并返回其引用。我们只需牢记返回的是字符串常量池的引用(即哈希表中的值)即可。
public class Main {
public static void main(String[] args) {
String s1 = new String("1");
String s2=s1.intern();
String s3 = "1";
System.out.println(s2 == s3);
}
}
3.常用方法
传送门(点我)
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!