复现五 LMDeploy 的量化和部署
0基础知识
一步一步跟着教程复现第五:LMDeploy 的量化和部署
复现一:
轻松玩转书生·浦语大模型internlm-demo 配置验证过程_ssh -cng -l 7860:127.0.0.1:6006 [email protected]博客文章浏览阅读827次,点赞17次,收藏24次。InternLM-chat-7B InternLM 模型_ssh -cng -l 7860:127.0.0.1:6006 [email protected] -p 35205https://blog.csdn.net/cq99312254/article/details/135625924?spm=1001.2014.3001.5501
复现二:Lagent智能题调用Demo-CSDN博客
浦语·灵笔图文理解创作 Demo-CSDN博客
复现三: 基于 InternLM 和 LangChain 搭建你的知识库-CSDN博客
复现四: XTuner复现-CSDN博客
XTuner InternLM-Chat 个人小助手认知微调实践-CSDN博客
1 环境配置
1.1克隆开发环境
bash /root/share/install_conda_env_internlm_base.sh lmdeploy 
可以进入Python检查一下 PyTorch 和 lmdeploy 的版本。由于 PyTorch 在官方提供的环境里,我们应该可以看到版本显示,而 lmdeploy 需要我们自己安装。
# 解决 ModuleNotFoundError: No module named 'packaging' 问题
pip install packaging
# 使用 flash_attn 的预编译包解决安装过慢问题
pip install /root/share/wheels/flash_attn-2.4.2+cu118torch2.0cxx11abiTRUE-cp310-cp310-linux_x86_64.whl
#由于默认安装的是 runtime 依赖包,但是我们这里还需要部署和量化,所以,这里选择 [all]
pip install 'lmdeploy[all]==v0.1.0' 
检测lmdeploy安装情况

2 服务部署
这一部分主要涉及本地推理和部署,基本原理如图:

我们把从架构上把整个服务流程分成下面几个模块。
- 模型推理/服务。主要提供模型本身的推理,一般来说可以和具体业务解耦,专注模型推理本身性能的优化。可以以模块、API等多种方式提供。
- Client。可以理解为前端,与用户交互的地方。
- API Server。一般作为前端的后端,提供与产品和服务相关的数据和功能支持。
值得说明的是,以上的划分是一个相对完整的模型,但在实际中这并不是绝对的。比如可以把“模型推理”和“API Server”合并,有的甚至是三个流程打包在一起提供服务。
接下来,我们看一下lmdeploy提供的部署功能。
2.1 模型转换
使用 TurboMind 推理模型需要先将模型转化为 TurboMind 的格式,目前支持在线转换和离线转换两种形式。在线转换可以直接加载 Huggingface 模型,离线转换需需要先保存模型再加载。
TurboMind 是一款关于 LLM 推理的高效推理引擎,基于英伟达的 FasterTransformer 研发而成。它的主要功能包括:LLaMa 结构模型的支持,persistent batch 推理模式和可扩展的 KV 缓存管理器。
2.1.1 在线转换
lmdeploy 支持直接读取 Huggingface 模型权重,目前共支持三种类型:
- 在 huggingface.co 上面通过 lmdeploy 量化的模型,如 llama2-70b-4bit, internlm-chat-20b-4bit
- huggingface.co 上面其他 LM 模型,如 Qwen/Qwen-7B-Chat
示例如下:
# 需要能访问 Huggingface 的网络环境
lmdeploy chat turbomind internlm/internlm-chat-20b-4bit --model-name internlm-chat-20b
lmdeploy chat turbomind Qwen/Qwen-7B-Chat --model-name qwen-7b上面两行命令分别展示了如何直接加载 Huggingface 的模型,第一条命令是加载使用 lmdeploy 量化的版本,第二条命令是加载其他 LLM 模型。
也可以直接启动本地的 Huggingface 模型,如下所示:
lmdeploy chat turbomind /share/temp/model_repos/internlm-chat-7b/ --model-name internlm-chat-7b以上命令都会启动一个本地对话界面,通过 Bash 可以与 LLM 进行对话。
2.1.2 离线转换
离线转换需要在启动服务之前,将模型转为 lmdeploy TurboMind 的格式,如下所示:
# 转换模型(FastTransformer格式) TurboMind
lmdeploy convert internlm-chat-7b /path/to/internlm-chat-7b使用官方提供的模型文件,就在用户根目录执行,如下所示:
lmdeploy convert internlm-chat-7b /root/share/temp/model_repos/internlm-chat-7b/执行完成后将会在当前目录生成一个 workspace 的文件夹。这里面包含的就是 TurboMind 和 Triton “模型推理”需要到的文件。

weights 和 tokenizer 目录分别放的是拆分后的参数和 Tokenizer。如果我们进一步查看 weights 的目录,就会发现参数是按层和模块拆开的,如下图所示:
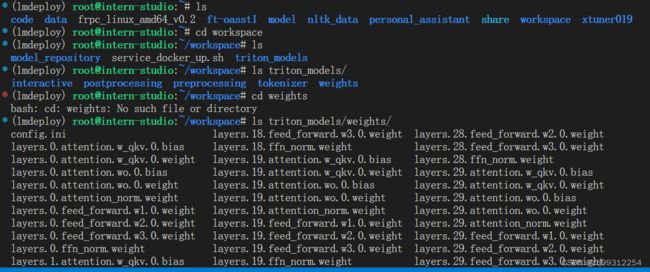
每一份参数第一个 0 表示“层”的索引,后面的那个0表示 Tensor 并行的索引,因为我们只有一张卡,所以被拆分成 1 份。如果有两张卡可以用来推理,则会生成0和1两份,也就是说,会把同一个参数拆成两份。比如 layers.0.attention.w_qkv.0.weight 会变成 layers.0.attention.w_qkv.0.weight 和 layers.0.attention.w_qkv.1.weight。执行 lmdeploy convert 命令时,可以通过 --tp 指定(tp 表示 tensor parallel),该参数默认值为1(也就是一张卡)。
关于Tensor并行
Tensor并行一般分为行并行或列并行,原理如图所示:
列并行,如下图:

行并列,如下图:

简单来说,就是把一个大的张量(参数)分到多张卡上,分别计算各部分的结果,然后再同步汇总。
2.2 TurboMind 推理+命令行本地对话
模型转换完成后,我们就具备了使用模型推理的条件,接下来就可以进行真正的模型推理环节。
我们先尝试本地对话(Bash Local Chat),下面用(Local Chat 表示)在这里其实是跳过 API Server 直接调用 TurboMind。简单来说,就是命令行代码直接执行 TurboMind。所以说,实际和前面的架构图是有区别的。
这里支持多种方式运行,比如Turbomind、PyTorch、DeepSpeed。但 PyTorch 和 DeepSpeed 调用的其实都是 Huggingface 的 Transformers 包,PyTorch表示原生的 Transformer 包,DeepSpeed 表示使用了 DeepSpeed 作为推理框架。Pytorch/DeepSpeed 目前功能都比较弱,不具备生产能力,不推荐使用。
执行命令如下(输入后要按两次回车?有点搞不懂为什么):
# Turbomind + Bash Local Chat
lmdeploy chat turbomind ./workspace

退出时输入exit 回车两次即可。此时,Server 就是本地跑起来的模型(TurboMind),命令行可以看作是前端。
2.3 TurboMind推理+API服务
在上面的部分我们尝试了直接用命令行启动 Client,接下来我们尝试如何运用 lmdepoy 进行服务化。
”模型推理/服务“目前提供了 Turbomind 和 TritonServer 两种服务化方式。此时,Server 是 TurboMind 或 TritonServer,API Server 可以提供对外的 API 服务。我们推荐使用 TurboMind,TritonServer 使用方式详见https://github.com/InternLM/tutorial/blob/8404bee4e8eb7a75128992c38cae8a3db5abd64e/lmdeploy/lmdeploy.md#24-%E7%BD%91%E9%A1%B5-demo-%E6%BC%94%E7%A4%BA。
首先,通过下面命令启动服务。
# ApiServer+Turbomind api_server => AsyncEngine => TurboMind
lmdeploy serve api_server ./workspace \
--server_name 0.0.0.0 \
--server_port 23333 \
--instance_num 64 \
--tp 1 上面的参数中 server_name 和 server_port 分别表示服务地址和端口,tp 参数我们之前已经提到过了,表示 Tensor 并行。还剩下一个 instance_num 参数,表示实例数,可以理解成 Batch 的大小。执行后如下图所示。
以Windows为例,打开windows powershell,输入
#由于开发机每次启动节点不同,建议添加 StrictHostKeyChecking=no 和 UserKnownHostsFile=/dev/null 绕过指纹检查
ssh -CNg -L 23333:127.0.0.1:23333 [email protected] -p 35253 -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null
#如何配置本地端口访问服务器,请查看复现一![]()
然后在本地IE中输入:http://127.0.0.1:2333,出现如下界面。

2.4 网页 Demo 演示
这一部分主要是将 Gradio 作为前端 Demo 演示。在上一节的基础上,我们不执行后面的 api_client 或 triton_client,而是执行 gradio。
由于 Gradio 需要本地访问展示界面,因此也需要通过 ssh 将数据转发到本地。命令如下:
ssh -CNg -L 6006:127.0.0.1:6006 [email protected] -p <你的 ssh 端口号>
2.4.1 TurboMind 服务作为后端
API Server 的启动和上一节一样,这里直接启动作为前端的 Gradio。
# Gradio+ApiServer。必须先开启 Server,此时 Gradio 为 Client
lmdeploy serve gradio http://0.0.0.0:23333 \
--server_name 0.0.0.0 \
--server_port 6006 \
--restful_api True 这一步没有实现,显示端口被占用,重启虚拟机也没有用。
2.4.2 TurboMind 推理作为后端
当然,Gradio 也可以直接和 TurboMind 连接,如下所示。
# Gradio+Turbomind(local)
lmdeploy serve gradio ./workspace
(切记不可以用弹出来的窗口)
 ,
,
在网页中输入http://127.0.0.1:6006,出现如下界面。


2.5 TurboMind 推理 + Python 代码集成
前面介绍的都是通过 API 或某种前端与”模型推理/服务“进行交互,lmdeploy 还支持 Python 直接与 TurboMind 进行交互,如下所示。
from lmdeploy import turbomind as tm
# load model
model_path = "/root/share/temp/model_repos/internlm-chat-7b/"
tm_model = tm.TurboMind.from_pretrained(model_path, model_name='internlm-chat-20b')
generator = tm_model.create_instance()
# process query
query = "你好啊兄嘚"
prompt = tm_model.model.get_prompt(query)
input_ids = tm_model.tokenizer.encode(prompt)
# inference
for outputs in generator.stream_infer(
session_id=0,
input_ids=[input_ids]):
res, tokens = outputs[0]
response = tm_model.tokenizer.decode(res.tolist())
print(response)在上面的代码中,我们首先加载模型,然后构造输入,最后执行推理。
加载模型可以显式指定模型路径,也可以直接指定 Huggingface 的 repo_id,还可以使用上面生成过的 workspace。这里的 tm.TurboMind 其实是对 C++ TurboMind 的封装。
构造输入这里主要是把用户的 query 构造成 InternLLM 支持的输入格式,比如上面的例子中, query 是“你好啊兄嘚”,构造好的 Prompt 如下所示。
"""
<|System|>:You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
<|User|>:你好啊兄嘚
<|Bot|>:
"""Prompt 其实就是增加了 <|System|> 消息和 <|User|> 消息(即用户的 query),以及一个 <|Bot|> 的标记,表示接下来该模型输出响应了。最终输出的响应内容如下所示。
