看书标记【R语言数据分析项目精解:理论、方法、实战 3】
看书标记——关于R语言
- chapter 3 互联网运营指标的建立
-
-
- 3.1 项目背景、目标及方案
-
- 3.1.1 项目背景
- 3.1.2 项目目标
- 3.1.3 项目方案
- 3.2 项目技术理论简介
-
- 3.2.1 骨灰级流量指标
-
- 1.PV(page views 访问页面数)
- 2. UV(Unique Vistors 唯一访问人数)
- 3.Visit (会话)
- 3.2.2 登录和激活
- 3.2.3 访问深度和吸引力
-
- 1.PV/Visit
-
- 2.Vist/UV
- 3.Duration
- 4.积极访问者
- 5.快速浏览用户
- 6.留存率 Retention Rate
- 7.退出率 Exit Rate
- 3.2.4订单指标
-
- 1.订单量
- 2.成交比率
- 3.订单用户构成
- 4.客户价值
- 3.2.5网站性能指标
-
- 1.页面平均响应时间
- 2.同时在线人数
- 3.2.6转化率
- 3.2.7层次分析法
-
- 1.层次分析法概论
- 2.层次分析法的基本思想
-
-
- 3.层次分析法的基本步骤
-
- 3.3项目实战
-
- 3.3.1搭建运营指标系统
-
- 3.3.2制作对比型指标及趋势线
- 1.同比、环比、定基比
- 2.趋势线
- 3.3.3创建用户价值和活跃度指标
-
【R语言数据分析项目精解:理论、方法、实战】
chapter 3 互联网运营指标的建立
3.1 项目背景、目标及方案
3.1.1 项目背景
运营团队希望有一套完整的指标系统来实时监控运营环境,用来更好地了解和掌握产品线上情况并可以及时发现问题。运营团队负责人找到数据分析团队,提出希望能根据产品本身创造一套运营指标报表;不仅如此,运营团队还需要知道每个月销售的增长情况、用户流量的长期趋势情况;此外还希望有一个综合评分来展现整体用户价值情况。
;最后还希望每天知道访问的用户当中哪些是活跃用户。
3.1.2 项目目标
(1)根据产品运营情况创建运营指标体系
(2)以日和周为单位,分别制作日报和周报。日报一般存放粒度较细的指标,周报则多以趋势分析为主。此外还需要创建一些对比型和趋势性指标。
(3)根据运营指标体系整合和创建一个用户价值指标
(4)创建一个用户活跃度指标,使得该指标能更好地监控产品和运营效果和效率。
3.1.3 项目方案
(1)根据公司业务情况,搭建运营指标。
(2)制作一些对比型的指标和趋势性指标来说明每个指标的趋势对比。
(3)通过数据分析团队的讨论,决定用层次分析法创建用户价值指标。
3.2 项目技术理论简介
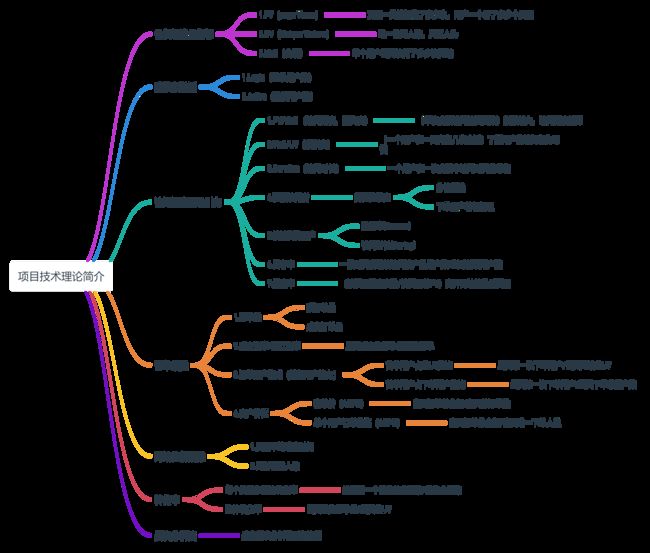
3.2.1 骨灰级流量指标
在物理学中,流量是指单位时间内流经管道有效截面的流体量。把这个概念移植到互联网中,物理学指的管道有效截面就变成了网站的有效访问,这个概念生动形象地反映了互联网的受欢迎程度。在互联网中有3个骨灰级流量指标: PV (访问页面数)、UV (唯一访问人数)和Visit (会话)。这3个指标对移动互联网APP同样适用。
1.PV(page views 访问页面数)
PV是指页面一共被加载了多少次,简单理解就是用户一共看了多少个页面,例如,一个用户一天查看了10个页面,那么这个用户这一天的PV就是10,当天所有用户查看的页面数量总和就是当天这个网站或APP的所有PV。
2. UV(Unique Vistors 唯一访问人数)
UV是指唯一访问人数。在线上,开发人员通常会在页面上埋一个Cookie来识别同一个用户,只有当用户清理缓存时才会重新生成一个新的Cookie。在APP上,开发人员同样可以生成一个id来识别用户。UV更直观的理解就是当天有多少个用户(去重)访问了APP。例如,同一个用户在一天内多次访问,计算UV时该用户只被统计一次。
UV的计算口径一般有如下几个:日UV、周UV、月UV、季度UV、半年度UV和年度UV。对应的统计方式就是时间范围的不同,日UV是每天去重的访问人数,周UV是每周去重的访问人数等。
3.Visit (会话)
Visit是指一个用户当天访问了多少次网站或APP。初看起来这个概念很模糊,这里的多少次是怎么区分的呢?通常情况下,若一个用户两次访问时间超过30分钟,则认为该用户的两次访问属于两个不同的会话。
3.2.2 登录和激活
Login登录用户数和Active激活用户数
3.2.3 访问深度和吸引力
1.PV/Visit
即单次会话访问的页面数,该指标越大说明用户访问深度越深,另一方面,这一指标也可以度量“迷失度”,所以这一指标过大过小都应该引起重视。
2.Vist/UV
即一个用户在一天内有几次会话,反映的是网站对用户的吸引度,也可以帮助运营了解用户的访问行为习惯。
3.Duration
即用户访问时长,指一个用户在一次会话中访问时间的总和,该页面的访问时长=该页面下一个页面的访问时间-该页面的访问时间
(这种计算方法的一个缺陷是,每个会话最后一个页面的访问时长无法计算)
会话访问时长=∑该会话中每个页面的访问时长总和
4.积极访问者
有两种定义:
(用户级别)一次会话中访问页面大于某个数的用户占到当天总UV的比率;
(会话级别)一次会话中访问页面大于某个数的会话数占到当天总会话数的比率;
(用户级别)一次会话的访问时长大于某个时间的用户占到当天总UV的比率;
(会话级别)一次会话的访问时长大于某个时间的会话数占到当天总会话数的比率。
- 如何确定阈值?
(1)分位数法:
a.选取一个周期内的所有用户作为样本
b.计算每个用户每次会话的访问页面数和访问时长
c.计算出b中访问页面数和访问时长的均值及75%分位数
d.选取合适的分位数作为阈值,当访问页面数或访问时长大于这个阈值时,该用户就可以打上积极访问者的标签
(但是分位数法易受长尾指影响,建议通过分位数、箱型图或者LOF算法进行离群点检测,剔除离群值后再进行计算)。
(2)下单用户特征抽取:
a.统计出单位周期内下单用户单次会话的访问页面数和访问时长
b.通过离群点检测去除长尾数据
c.计算均值并将其作为积极访问者的阈值
(特征抽取的意义更重大,得到的用户在某个特征上与真实用户相同,更加接近真实用户,比分位数法得出的积极访问者要求更严)。
5.快速浏览用户
与积极访问者相反,快速浏览用户指访问深度较浅的用户,对应的指标有:
(1)跳出率Bounce Rate:一次会话中,用户只访问了一个页面,跳出率=每天跳出的会话数/当天总的会话数
(2)访问时长During:取得阈值后,访问时长=当天会话访问时长小于阈值的会话数/当天总的会话数
6.留存率 Retention Rate
通常指用户在某个时间开始使用,经过一段时间后继续访问该产品,称为留存,留存率体现了一个网站的质量和维护用户的能力。
留存率的本质体现了一种转化率,从初期不稳定的用户转换到稳定活跃用户的过程可以帮助运营人员了解用户生命周期,找出可以在哪个时间点开始改善产品。
7.退出率 Exit Rate
退出率=该页面退出的次数占该页面总流量PV的比
3.2.4订单指标
1.订单量
(1)预定订单量:用户预订产品或已购买的订单总量,可以反映出当天大致的订单总数。
(2)成交订单量:用户完成订单,付款后或产品已到生效日期的订单,由企业自己具体定义。
2.成交比率
当天成交的订单与预定的订单之间的比例,也是另一个反映退订比的指标。
3.订单用户构成
(1)首单用户占总UV的比:当天第一次下单用户/当天网站总UV
(2)首单用户占下单用户的比:当天第一次下单用户/当天下单总用户数
这两个指标反映了网站招揽新用户的能力,运营环境不变时,这个指标应该相对稳定,节假日或活动期间会有所波动,可以用其波动幅度来考虑运营效果的好坏。
4.客户价值
(1)客单价(ARPO):当天订单总金额/当天总订单数
(2)单个用户订单价格(ARPU):当天订单总金额/当天唯一下单人数(只算人头)
3.2.5网站性能指标
网站性能指标用于反映后台性能的一系列指标
1.页面平均响应时间
每天每个页面平均的加载响应时间(单位:mm)。
2.同时在线人数
每小时或者每分钟同时在线人数,同时在线人数可以作为服务器后台支撑容量的参考值,可以指导开发人员评估知否需要扩充服务器,
3.2.6转化率
转化率直接影响销售结果,转化率偏低,营销成本就会上升。转化率问题的根源往往会体现在网站的内容、结构等不合理,营销活动受众人群不精准等,转化率指标的计算有两种:
(1)每个关键步骤的转化率
达到某个目的的会话数/总的会话数;用户达到某个步骤的会话数/用户达到上一个步骤的会话数。每个关键步骤计算出来就会形成一个转化率漏斗,通过分析漏斗可以看出用户主要卡在哪一步,从而有针对性地进行调整。
(2)整体转化率
当天总的订单量/当天总的UV。
3.2.7层次分析法
1.层次分析法概论
层次分析法是一种多目标或多方案的决策方法,结合定性和定量分析思维,使定性方法定量化,把决策过程层次化、数量化,将决策问题分解成目标、准则、方案等层次,把人的主观判断进行客观量化进行判断决策,所以适用于量化定性判断。
2.层次分析法的基本思想
(1)确定分析问题的目标
(2)将问题层次化,根据总目标将问题分成不同的组成因素
(3)由因素间的相互关系和隶属关系,将因素按不同层次组合排序,形成多层次结构模型后,就成为可以赋予权重和优次的问题了。
(4)根据判断矩阵从下往上计算每一层相对于上一层因素影响的权重
3.层次分析法的基本步骤
建立层次结构模型》构造判断矩阵》一致性检验》层次单排序》层次总排序
- 建立层次结构模型
Tip:
a.每层下属的因素一般不超过11个
b.每层下属的因素需具有代表性且相互独立
c.每层下属的因素解释性强 - 构造判断矩阵
每层元素两两之间进行比较,构成判断矩阵,也叫正反矩阵(对角导数矩阵) - 一致性检验
一致矩阵用于评判判断矩阵是否对重要性的度量在同一水平。
a.判断矩阵偏离完全一致性的程度CI
b.查表得到平均一致性指标RI
c.随机一致性比率CR=CI/RI - 层次单排序
一致性通过后开始计算某层次的因素相对于上一层次中某个因素的相对重要性,具体的计算过程和实例(代数的一些简单计算)在P91。 - 层次总排序
底层因素相对于最高层的相对重要性或相对优势的排序值。
3.3项目实战
3.3.1搭建运营指标系统
该流程具体内容如下:
- 用户行为数据由开发人员进行技术采集并存放在分布式数据库中,首先需要数据工程师团队的同事从生产库中把用户行为日志落到本地服务器的数据仓库(DW层)中,并且进行数据格式的整理和字段拆分,便于后续数据分析师使用。(数据清洗)
- 然后,数据分析师根据指标定义,从本地服务器数据仓库的日志表中,通过聚合汇总将数据整合成数据中间层(OLAP层),整合的主要目的是对数据进行有效聚合,减少数据表的大小,在后续工作中只访问OLAP层的表即可,不需要再直接访问底层大数据表,节省资源。(数据整合)
- 接着,数据分析师根据指标定义创建运营指标逻辑代码,并把最终结果输出到更细一级的报表层(REPORT层)﹔最后,通过前端展示工具把结果用合适的图表展现出来。(数据可视化)
日报数据指标


3.3.2制作对比型指标及趋势线
1.同比、环比、定基比
这三个比率是描述性统计类别下趋势性判别最基本的三个指标。
同比:不同周期、相同时刻的增长幅度
环比:相邻两个周期的增长幅度
定基比:不同时期对于固定时期的增长幅度
周同比yoy=(x_this-x_last)/x_last 其余比率相似
2.趋势线
拟合趋势线具体量化其趋势幅度,清楚了两个指标的大致趋势后,我们需要进一步量化两个指标变化幅度
setwd("C:\\Users\\用户路径") #设定工作空间目录
index<-read.csv("index.csv",header=TRUE) #读取指标数据
#规范化指标数据,规范化后的指标形成新的字段
index$index1_sc<-scale(index$index1)
index$index2_sc<-scale(index$index2)
index$id<-1:nrow(index) #生成自增序列,用于后面一元线性回归
#建立一元线性回归模型
lm_ind1<-lm(index$index1_sc ~ index$id)
lm_ind2<-lm(index$index2_sc ~ index$id)
#画出拟合图
plot(index$index1_sc,type='l')
lines(fitted(lm_ind1),col='blue')
plot(index$index2_sc,type='l')
lines(fitted(lm_ind2),col='blue')
#查看一次项系数
lm_ind1
lm_ind2
这样的方法可以快速简便的知道指标的一个趋势性,但此方法易受异常值影响,所以在分析前对异常值进行一定的处理。制定完指标后,对日报和周报中的每个指标都加上趋势图、配上趋 势线、计算其规范化后一次线性回归的一次项回归系数,同时制作一张 指标增长幅度趋势量化指标报表。日报中每个指标都计算周同比,周报 中所有指标都计算周环比。

3.3.3创建用户价值和活跃度指标
层次结构模型
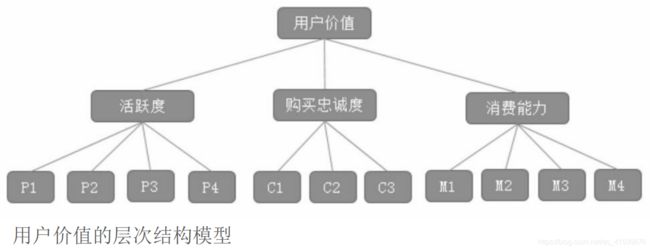
层次结构模型对应的各因素指标:

运营和产品经理对各因素重要性进行比较后给出判断矩阵:

判断矩阵需要进行一致性检验,通常一致性检验都不容易通过,这个时候数据分析师要不断的对修正后的判断矩阵进行检验,并根据检验结果给出修正指导(填入的修正值前面有提到,填入的是固定的数据集,修正是不断地修正)。当一致性检验通过时,每层每个因素对应的上层权重也能得到:
######################################################################
#函数功能:判断矩阵是否为一致性矩阵
#参数说明:judgematrix:判断矩阵
######################################################################
##第三层到第二层
myahp<-function(judgematrix){
n<-ncol(judgematrix)
#判断是否为方正
if(nrow(judgematrix)!=ncol(judgematrix)){
ifsquarematrix<-1
message("错误:判断矩阵不是方正")
} else {ifsquarematrix<-0}
#判断因素个数是否超过11个
if(n>11){
nlength_index<-1
message("错误:指标个数过多,请控制在11个之内")
} else {nlength_index<-0}
#判断矩阵对角元素是否互为倒数
ifreciprocal<-0
if(ifsquarematrix==0){
for (i in 1:n){
for (j in 1:i){
if(judgematrix[i,j]<1/judgematrix[j,i]*0.99||judgematrix[i,j]>1/judgematrix[j,i]*1.01){
ifreciprocal<-1
message(paste("错误:请检查a[",i,",",j,"] 和 a[",j,",",i,"]是否为倒数",sep=""))
}
}
}
}
if(ifsquarematrix==0 & nlength_index==0 & ifreciprocal==0){
#求最大特征根和特征向量
rowprod<-apply(judgematrix,1,prod)
rowprod_sqrt<-rowprod^(1/n)
weight<-rowprod_sqrt/sum(rowprod_sqrt) #特征向量
aw<-judgematrix%*%weight
lamda_max<-sum(aw/(weight*n)) #最大特征值
#计算一致性
ri <- c(0, 0, 0.58, 0.9, 1.12, 1.24, 1.32, 1.41, 1.45, 1.49, 1.51)
ci <- (lamda_max - n)/(n - 1)
cr <- round(ci/ri[n],4)
if(cr>=0.1){
consistency<-"一致性检验不通过,请调整判断矩阵"
} else {consistency<-"判断矩阵符合一致性要求"}
crresult<-matrix(c(0,0),nrow=1)
colnames(crresult)<-c("cr","是否一致性")
crresult[1,1]<-cr
crresult[1,2]<-consistency
result<-list(max_eigenvalue=lamda_max,weight=weight,consistency=crresult)
return(result)
}
}
p<-c(1,1/3,1/5,5,3,1,3,3,5,1/3,1,5,1/5,1/3,1/5,1)
P<-matrix(p,nrow=4,byrow=T)
c<-c(1,1/5,1/5,5,1,5,5,1/5,1)
C<-matrix(c,nrow=3,byrow=T)
m<-c(1,5,3,7,1/5,1,5,7,1/3,1/5,1,7,1/7,1/7,1/7,1)
M<-matrix(m,nrow=4,byrow=T)
#对判断矩阵进行一致性检验,并计算特征向量和权重
myahp(P)
myahp(M)
myahp(C)
#调整后判断矩阵
p<-c(1,1/5,1/3,5,5,1,3,7,3,1/3,1,5,1/5,1/7,1/5,1)
P<-matrix(p,nrow=4,byrow=T)
c<-c(1,1/7,1/5,7,1,3,5,1/3,1)
C<-matrix(c,nrow=3,byrow=T)
m<-c(1,5,3,7,1/5,1,1/3,5,1/3,3,1,7,1/7,1/5,1/7,1)
M<-matrix(m,nrow=4,byrow=T)
myahp(P)
myahp(C)
myahp(M)
##第二层到第一层
#活跃度、购买忠诚度、消费能力
f<-c(1,1/5,1/3,5,1,3,3,1/3,1)
F<-matrix(f,nrow=3,byrow=T)
myahp(F)

Tip:
评分标准需要统一、指标是否需要消除量纲、评分范围、权重模型计算出层次结构模型。模型建立的最终意义在于将运营指标、描述趋势性和制作用户价值、活跃度指标的任务形成系统,后期打包整个计算流程就可以实现自动化,这正是数据价值的初步体现。