【AI算法】数据王国的大冒险-谈三种数据降维的机理
在一个遥远的数据王国里,高维数据们快乐地生活在一起。他们每个人都有许多特征,就像彩虹有七种颜色一样。然而,随着时间的推移,高维数据们发现自己越来越难以管理,因为每个特征都需要大量的存储空间和维护工作。
为了解决这个问题,数据王国决定举办一场降维大赛。他们邀请了王国中最聪明和最勇敢的数据科学家们来参加这场比赛,看看谁能找到最有效的降维方法。
降维大赛
国王说道,为了简化管理,我引入了一种名为降维的策略。这就像是将一个复杂的七彩光谱简化为红、黄、蓝三原色,以降低其管理的复杂性。首先,我强调保留主要特征的原则。这意味着在降维的过程中,我会特别关注那些对分类、预测等任务最为关键的特征,确保它们在降维后仍能得到体现。
为了捕捉数据中的非线性关系,我鼓励使用一些创新的方法,如t-SNE、UMAP和自组织映射等。这些方法在保持数据的非线性特性方面非常有效,从而能够保留数据中的复杂关系。
同时,我强调保持数据的原始分布。这就像是保持一个国家的多元文化,让每个数据点都保持其独特的个性。通过使用如主成分分析(PCA)和线性判别分析(LDA)等方法,我们可以找到能够解释数据变异性最大的方向或特征,从而在降维的同时保持数据的多样性。
降维在数据可视化方面也发挥了重要作用。由于高维数据的复杂性,直接观察和理解它们可能非常困难。通过降维技术,我们可以将这些高维数据投影到二维或三维空间中,使其更容易被人们观察和理解。这就像是将一个复杂的国家治理问题简化为二维的地图或图表,使得国民们能够直观地了解情况。
此外,我也意识到监督与非监督方法在降维中的重要性。监督方法利用标签数据进行指导,这在处理具有特定目标变量的数据时非常有用。而非监督方法则基于数据本身的内在结构和相似性进行降维,无需依赖标签数据。这就像是在治理国家时,既需要依靠法律法规的指导,也需要尊重国民的意愿和习俗。
在选择降维方法时,我注重稳定性。这意味着选择的降维方法应该能够稳定地处理数据,避免在遇到噪声或异常值时出现大的波动。这样能够确保降维结果的可靠性,为数据国民们提供一个稳定的生活环境。
最后,我强调降维方法的可解释性。降维后的结果应该具有实际意义,能够直观地解释数据的内在结构和关系。这样国民们才能真正理解降维的意义,更好地参与到国家的治理中来。
众多参赛者
参赛者们来自不同的领域,每个人都有自己的独特技能。有的擅长数学运算,有的善于发明新的算法。他们纷纷展示出自己的才华,用各种方法尝试将高维数据降低维,使其更容易处理和可视化。
在众多参赛者中,有一位年轻的科学家名叫PCA。他使用了一种名为主成分分析的方法,能够找到数据中的主要变化方向,从而将高维数据投射到低维空间。PCA的方法简单而有效,很快受到了大家的关注。
PCA方法如下:
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# 构造示例数据
data = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
# 创建DataFrame对象
df = pd.DataFrame(data, columns=['feature1', 'feature2', 'feature3', 'feature4'])
# 创建PCA对象,并指定降维后的维度
pca = PCA(n_components=2)
# 执行PCA降维
reduced_features = pca.fit_transform(df)
# 输出降维后的结果
print(reduced_features)
# 绘制降维结果
plt.figure(figsize=(8, 6))
plt.scatter(reduced_features[:, 0], reduced_features[:, 1], edgecolor='k', s=50)
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.title('PCA Dimensionality Reduction')
plt.show()
PCA效果图输出
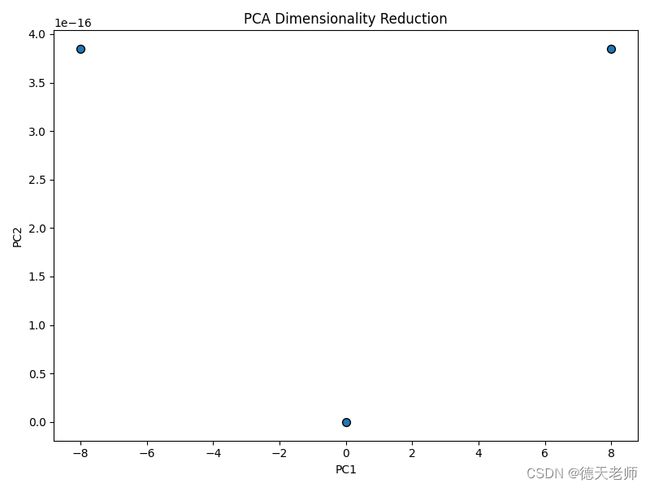
PCA好处及应用
PCA(主成分分析)是一种常用的降维方法,它通过找到数据中的主要变化方向,将高维数据投射到低维空间。这种方法的好处和应用场景如下:
好处:
降低数据维度:PCA可以显著降低数据的维度,从而减少计算复杂性和存储需求。
保留重要信息:PCA通过保留数据中的主要变化方向,确保降维后的数据仍然包含原始数据中的重要信息。
可视化:低维数据更易于进行可视化,有助于更好地理解数据的结构和特征。
提取主要特征:PCA可以用于提取数据中的主要特征,这在许多机器学习任务中非常有用。
应用场景:
数据压缩:在处理大规模数据集时,PCA可以用于数据压缩,减少存储和传输需求。
特征选择:在机器学习任务中,PCA可以帮助选择最重要的特征,从而提高模型的性能和可解释性。
异常检测:通过PCA将数据降维,可以更容易地识别出异常值或离群点。
可视化和探索性分析:PCA降维后的数据更易于可视化,有助于更好地理解数据的结构。
推荐系统:PCA可以用于提取用户和项目的主要特征,从而用于推荐系统的构建。
另一位参赛者是LDA,他使用线性判别分析的方法。LDA认为,降维不仅仅是减少数据的维度,更重要的是保留数据的内在结构。他通过寻找能够最大化类间差异和最小化类内差异的方向,将数据降到低维空间。
LDA方法如下:
# 导入所需的库和模块
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import numpy as np
import matplotlib.pyplot as plt
# 构造示例数据
np.random.seed(42) # 设置随机数生成器的种子,确保结果可重复
mean1 = [0, 0] # 第一个数据集的均值
mean2 = [3, 3] # 第二个数据集的均值
cov = [[1, 0.5], [0.5, 1]] # 协方差矩阵
X1 = np.random.multivariate_normal(mean1, cov, 100) # 生成第一个数据集
X2 = np.random.multivariate_normal(mean2, cov, 100) # 生成第二个数据集
X = np.concatenate((X1, X2)) # 将两个数据集合并
y = np.concatenate((np.zeros(100), np.ones(100))) # 对应的标签,0和1分别代表两个数据集
# 创建LDA模型并进行降维
lda = LinearDiscriminantAnalysis(n_components=1) # 创建一个LDA对象,降维到1维
X_lda = lda.fit_transform(X, y) # 使用LDA模型对数据进行拟合和转换
# 可视化LDA降维结果
plt.figure(figsize=(8, 6)) # 设置图形的大小为8x6单位
plt.scatter(X_lda[:, 0], np.zeros_like(X_lda[:, 0]), c=y, edgecolor='k', s=50) # 使用散点图可视化降维后的数据,x轴表示LDA的第一维度,y轴为0,颜色根据标签y的值决定(0为蓝色,1为红色)
plt.xlabel('LDA 1') # 设置x轴的标签为“LDA 1”
plt.title('LDA Dimensionality Reduction') # 设置图形的标题为“LDA Dimensionality Reduction”
plt.show() # 显示图形
LDA输出效果图
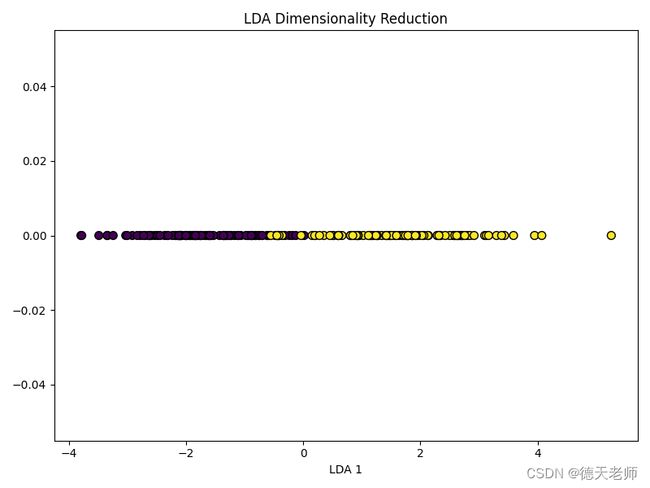
LDA(线性判别分析)好处及应用
LDA(线性判别分析)是一种经典的机器学习算法,用于分类任务的降维方法。它认为降维不仅仅是减少数据的维度,更重要的是保留数据的内在结构。通过寻找能够最大化类间差异和最小化类内差异的方向,LDA将数据降到低维空间。LDA的好处和应用如下:
好处:
降维效果和分类能力:LDA具有较好的降维效果和分类能力,能够有效地将不同类的样本分开。
抗噪声能力:LDA对噪声具有一定的抗干扰能力,能够在存在噪声的情况下仍能保持较好的分类性能。
简单易用:LDA算法相对简单,易于理解和实现。
应用场景:
生物信息学:在生物信息学中,LDA可用于基因表达数据的降维和分类,以识别疾病标志物或药物反应相关基因。
图像识别:在图像识别任务中,LDA可以用于将图像特征降维,以提高分类准确率。
文本分类:在文本分类任务中,LDA可以用于将文本特征向量降维,以便更快速地进行分类。
社交网络分析:通过应用LDA,可以分析社交网络中的用户行为和偏好,以实现更准确的用户分类和推荐。
金融市场分析:在金融市场分析中,LDA可以用于将股票价格等数据降维,以揭示市场趋势和预测未来走势。
还有一位参赛者是t-SNE,他使用了一种称为t-分布邻域嵌入的方法。t-SNE相信,数据中的相似性和差异性对于理解数据的结构至关重要。他通过计算数据点之间的相似度,将它们投射到低维空间中,同时尽量保持点之间的相对位置不变。
t_SNE方法如下
# 导入t-SNE模块,用于高维数据的降维
from sklearn.manifold import TSNE
# 导入numpy库,用于生成随机数和数组操作
import numpy as np
# 导入matplotlib.pyplot模块,用于数据可视化
import matplotlib.pyplot as plt
# 设置随机数生成器的种子,以确保结果可重复
np.random.seed(42)
# 定义样本数量和特征数量
n_samples = 200
n_features = 100
# 使用numpy的随机函数生成指定数量和维度的样本数据
X = np.random.randn(n_samples, n_features)
# 创建t-SNE模型对象,并设置要降到的维度为2,随机种子为42以确保结果可重复
tsne = TSNE(n_components=2, random_state=42)
# 使用t-SNE模型对数据进行降维处理
X_tsne = tsne.fit_transform(X)
# 设置图形的大小为8x6单位
plt.figure(figsize=(8, 6))
# 使用散点图可视化降维后的数据,x轴表示第一个t-SNE维度,y轴表示第二个t-SNE维度,边缘颜色为黑色,点的大小为50
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], edgecolor='k', s=50)
# 设置x轴的标签为“t-SNE 1”
plt.xlabel('t-SNE 1')
# 设置y轴的标签为“t-SNE 2”
plt.ylabel('t-SNE 2')
# 设置图形的标题为“t-SNE Dimensionality Reduction”
plt.title('t-SNE Dimensionality Reduction')
# 显示图形
plt.show()
t-SNE效果图
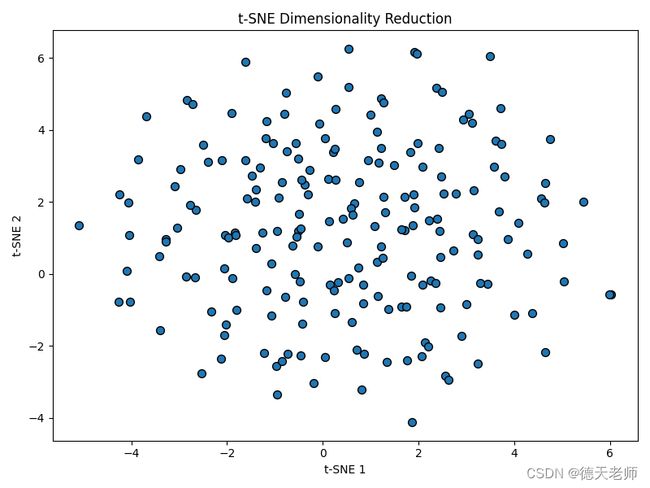
t-SNE好处及应用
t-SNE(t-Distributed Stochastic Neighbor Embedding)是一种强大的技术,用于高维数据的降维和可视化。它认为数据中的相似性和差异性对于理解数据的结构至关重要,通过计算数据点之间的相似度,将这些点投射到低维空间中,同时尽量保持点之间的相对位置不变。t-SNE的好处和应用如下:
好处:
保留局部特征:t-SNE特别关注数据的局部结构,能够更好地保留高维数据中的局部特征。
适用于高维数据:t-SNE适用于处理高维数据,能够有效地处理高维数据中的异常值。
计算效率:虽然t-SNE的计算复杂度较高,但与PCA相比,它在某些情况下可能更高效。
应用场景:
生物信息学:在生物信息学领域,t-SNE被广泛用于分析基因表达数据和其他类型的组学数据,以揭示生物过程的潜在机制。
图像处理:在图像处理中,t-SNE常用于将像素或特征向量降维到二维空间,以便进行可视化或分类。
社交网络分析:通过应用t-SNE,可以揭示社交网络中用户或群体的潜在结构,从而更好地理解网络行为和动态。
自然语言处理:在自然语言处理中,t-SNE可用于将文本数据降维,以揭示主题、情感或语义模式。
推荐系统:通过应用t-SNE,可以分析用户行为和偏好,以构建更精确的推荐系统。
PCA获奖
最后,数据王国的评委们根据每种方法的性能、效率和可解释性进行评估。经过激烈的角逐,PCA凭借其简单性和有效性获得了冠军。LDA和t-SNE也分别获得了最佳结构和最佳可视化的奖项。
通过这次大赛,数据王国的居民们学到了很多关于降维的知识。他们发现,不同的降维算法各有千秋,需要根据具体的应用场景和需求来选择合适的方法。从此以后,数据王国变得更加繁荣和有序,高维数据们也更加珍惜彼此的差异和特点。