机器学习周记(第二十四周:文献阅读-DSTGN续)2024.1.1~2024.1.7
目录
摘要
ABSTRACT
1 动态图矩阵估计(Dynamic Graph Matrix Estimation,DGME)
2 自适应导引传播(Adaptive Guided Propagation,AGP)
2.1 引导矩阵估计器(Guide Matrix Estimator)
2.2 自适应传播(Adaptively Propagation)
3 时间卷积模块(Temporal Convolution Module)
4 优化目标(Optimization Objective)
摘要
本周继续阅读了上周的论文,明白了论文模型DSTGN中的各个模块。DSTGN主要包括动态图矩阵估计、自适应导引传播、时间卷积模块三大模块。其中动态图矩阵估计又包括节点级信息融合、动态依赖推断、图矩阵级信息融合、图损失四个模块;自适应导引传播包括引导矩阵估计器、自适应传播两个模块。动态图矩阵估计能够基于动态语义信息和静态拓扑信息有效捕获节点间的动态依赖关系,自适应导引传播能够根据网络不同层的参数和学习到的图自动改变邻居之间的权重。
ABSTRACT
This week, We continued reading the paper from last week and gained a comprehensive understanding of the various modules in the DSTGN model. DSTGN primarily consists of three major modules: dynamic graph matrix estimation, adaptive guided propagation, and time convolution module. The dynamic graph matrix estimation module further includes four sub-modules: node-level information fusion, dynamic dependency inference, graph matrix-level information fusion, and graph loss. The adaptive guided propagation module comprises two sub-modules: guiding matrix estimator and adaptive propagation. The dynamic graph matrix estimation effectively captures dynamic dependencies among nodes based on dynamic semantic information and static topological information. Meanwhile, adaptive guided propagation automatically adjusts the weights between neighbors based on the parameters of different layers in the network and the learned graph.
1 动态图矩阵估计(Dynamic Graph Matrix Estimation,DGME)
为了基于动态语义信息(节点级输入)和静态拓扑信息有效捕获节点间的动态依赖关系,设计了动态图矩阵估计,包括节点级信息融合(Node-level Information Fusion)、动态依赖推断(Dynamic Dependencies Inference)、图矩阵级信息融合(Graph Matrix-level Information Fusion)和图损失(Graph Loss)。首先给出了这两类信息的形式化定义,然后详细描述了所提出的图估计方法。
语义信息(Semantic Information):节点上随时间变化的观测值就是语义信息,这是节点间影响力扩散的结果。模型使用CNN来每个节点的时间特征,即![]() ,使用大小为
,使用大小为![]() 的
的 个卷积核。由此,给定时间序列
个卷积核。由此,给定时间序列![]() (其中特征维度
(其中特征维度 是1),可以得到每个节点的语义信息
是1),可以得到每个节点的语义信息![]() 。
。
拓扑信息(Topology Information):在本文中,采用节点嵌入来推断结构信息,即![]() ,其中
,其中![]() 和
和 是可训练的节点嵌入。与之前的方法不同的地方在于,论文没有使用ReLU和Sigmoid函数来去除负值以及归一化,主要原因是作者没有将
是可训练的节点嵌入。与之前的方法不同的地方在于,论文没有使用ReLU和Sigmoid函数来去除负值以及归一化,主要原因是作者没有将![]() 视为邻接矩阵,而是将其视为固定的结构信息。
视为邻接矩阵,而是将其视为固定的结构信息。
节点级信息融合(Node-level Information Fusion):为了捕获隐藏在节点级输入中的动态关联模式,同时确保图学习良好收敛,在节点上融合语义信息和结构信息。受信息融合结构的启发,论文使用门控机制自适应地融合节点上的两类信息。类似于门控机制中长短期信息的融合,将静态结构信息(节点嵌入)作为长期信息,将动态语义信息(节点级输入)作为短期信息。公式定义如下:
![]() (1)
(1)
![]() (2)
(2)
![]() (3)
(3)
![]() (4)
(4)
其中·表示矩阵乘法, 表示哈达玛积,
表示哈达玛积, 表示门控机制的可训练参数,
表示门控机制的可训练参数,![]() 表示节点在时间窗口
表示节点在时间窗口 的融合结果。
的融合结果。
动态依赖推断(Dynamic Dependencies Inference):例如GAT,我们可以很自然地推断节点与节点级特征之间的联系,即:![]() ,其中
,其中 ,
, 分别表示第
分别表示第 个节点和第
个节点和第 个节点的特征,和
个节点的特征,和![]() 表示共享的可训练参数,
表示共享的可训练参数,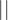 表示连接操作,
表示连接操作,![]() 表示第个节点和第个节点的边权重。然而,GAT计算的注意力非常有限,其中权重分数的排名是不以query节点为条件的。因此,在论文的工作中,作者设计了一个包含多头关系推理和前馈网络的动态依赖推理。与GAT类似,因为余弦相似度具有良好的计算特性和强大的学习能力,论文使用余弦相似度来推断节点之间的关联,提出了一个多头版本,从多子空间中学习节点之间的边权重。具体过程如下:
表示第个节点和第个节点的边权重。然而,GAT计算的注意力非常有限,其中权重分数的排名是不以query节点为条件的。因此,在论文的工作中,作者设计了一个包含多头关系推理和前馈网络的动态依赖推理。与GAT类似,因为余弦相似度具有良好的计算特性和强大的学习能力,论文使用余弦相似度来推断节点之间的关联,提出了一个多头版本,从多子空间中学习节点之间的边权重。具体过程如下:
![]() (5)
(5)
其中![]() 是稳定训练过程的LayerNorm。
是稳定训练过程的LayerNorm。 ,
, 表示第
表示第 头的两个不同的非线性映射。
头的两个不同的非线性映射。![]() 表示内积运算。
表示内积运算。 是每个头的维度。
是每个头的维度。![]() 和
和![]() 表示第个节点和第个节点的融合结果。
表示第个节点和第个节点的融合结果。![]() 表示顶点
表示顶点 和
和 之间的第个子空间的边权重。本文添加了dropout,以迫使模型学习更一般化的变化模式,并防止过拟合问题。最后,论文使用
之间的第个子空间的边权重。本文添加了dropout,以迫使模型学习更一般化的变化模式,并防止过拟合问题。最后,论文使用![]() 对
对![]() 的非线性映射,并使用残差连接来简化训练过程,如下面的等式所示:
的非线性映射,并使用残差连接来简化训练过程,如下面的等式所示:
![]() (6)
(6)
为避免推断出的图矩阵双指数收敛到秩1矩阵,论文对多子空间捕获的关联进行求和,并添加跳跃连接,如公式(7)所示,其中![]() 表示共享的可训练权重。注意,这里的跳跃连接和非线性映射
表示共享的可训练权重。注意,这里的跳跃连接和非线性映射 的作用不同于公式(6),前者是通过引入由初始节点特征
的作用不同于公式(6),前者是通过引入由初始节点特征![]() 计算的相似性度量来防止推断图矩阵的坍缩,后者是增加依赖推断的非线性能力。
计算的相似性度量来防止推断图矩阵的坍缩,后者是增加依赖推断的非线性能力。
![]() (7)
(7)
最后,受transformer结构的启发,使用一个两层的前馈网络来获得第和第个节点之间的最终关联![]() ,即
,即![]() 。
。
图矩阵级信息融合(Graph Matrix-level information fusion):为了使图学习方法更快地收敛,通过将学习到的关联关系![]() 和从结构信息
和从结构信息![]() 推断出的关联关系进行矩阵级的信息融合。因此,在矩阵级融合中,将静态结构信息推断出的相关性作为先验偏差,以确保动态图更好地收敛。同样,为了更快地训练并防止过拟合问题,我们使用LayerNorm和Dropout,即
推断出的关联关系进行矩阵级的信息融合。因此,在矩阵级融合中,将静态结构信息推断出的相关性作为先验偏差,以确保动态图更好地收敛。同样,为了更快地训练并防止过拟合问题,我们使用LayerNorm和Dropout,即![]() 。最后,我们使用ReLU消除相关性中的负值,并使用SoftMax进行归一化。公式如式(8),其中
。最后,我们使用ReLU消除相关性中的负值,并使用SoftMax进行归一化。公式如式(8),其中![]() 表示节点和在时间窗口的最终推断关系。
表示节点和在时间窗口的最终推断关系。
![]() (8)
(8)
图损失(Graph Loss):在实际应用中,评估学习到的图结构的质量是很重要的,如平滑性和连通性。先前的工作已经证明了图卷积实际上是拉普拉斯平滑的一种特殊形式,这是GCNs工作的关键原因。学习到的图结构自然要符合拉普拉斯平滑,因此引入拉普拉斯平滑作为图的评估。此外还需要控制图的稀疏性。因此,论文将第二项作为学习到的图的额外约束,其中![]() 表示矩阵的弗罗贝尼乌斯范数(Frobenius Norm)。最终的图损失公式如式(9)所示。
表示矩阵的弗罗贝尼乌斯范数(Frobenius Norm)。最终的图损失公式如式(9)所示。
![]() (9)
(9)
其中![]() ,
,![]() 表示节点和的输入信号,
表示节点和的输入信号, 表示超参数。第一项惩罚不连通图的形成,第二项通过惩罚第一项造成的大度数来控制稀疏性。
表示超参数。第一项惩罚不连通图的形成,第二项通过惩罚第一项造成的大度数来控制稀疏性。
2 自适应导引传播(Adaptive Guided Propagation,AGP)
图卷积操作可以看作是基于图矩阵的信息传播过程。目前的时空图神经网络一般采用堆叠的时间卷积和图卷积交互捕捉数据中的时空信息,并假设每层中的信息传播过程是相同的,即共享相同的图结构。然而,神经网络有效的原因是它在每一层捕获不同的信息。基于这种直觉,提出了一种自适应引导传播算法,它包括引导矩阵估计器(Guide Matrix Estimator)和自适应传播(Adaptively Propagation),其核心是在网络的不同层自适应地学习传播过程。因此,将可学习引导矩阵纳入图卷积框架。请注意,引导图矩阵不是从头开始学习的,而是对学习到的图的调整。具体来说,根据网络不同层的参数和学习到的图自动改变邻居之间的权重。
2.1 引导矩阵估计器(Guide Matrix Estimator)
引导矩阵的目的是反映模型不同层的个性化传播需求,因此该矩阵既考虑了从不同层提取的特征,又考虑了学习到的图结构。从属性空间的角度,应用一个独立于图的多层感知器(MLP)从每个节点的时间特征中提取信息,即![]() ,其中是MLP的可训练权重,
,其中是MLP的可训练权重,![]() 表示从第
表示从第 层时间卷积中提取的时间特征,
层时间卷积中提取的时间特征,![]() 表示节点从第层提取的特征。受前面研究的启发,可以从每个节点的特征空间中获得结果,这可以增强其局部影响力。因此,我们可以利用每层得到的特征
表示节点从第层提取的特征。受前面研究的启发,可以从每个节点的特征空间中获得结果,这可以增强其局部影响力。因此,我们可以利用每层得到的特征 来推断每个节点的预测结果,以增强每层提取的特征的重要性,公式如式(10)(11)所示。
来推断每个节点的预测结果,以增强每层提取的特征的重要性,公式如式(10)(11)所示。
![]() (10)
(10)
![]() (11)
(11)
其中![]() 是平均绝对误差,
是平均绝对误差,![]() 是第个节点的预测标签,
是第个节点的预测标签,![]() 表示所有的可训练参数。如等式(10)(11)所示,我们首先将
表示所有的可训练参数。如等式(10)(11)所示,我们首先将![]() 连接到由两个卷积模块组成的输出模块,以推断预测结果。然后,对于每一层,我们可以通过最小化损失
连接到由两个卷积模块组成的输出模块,以推断预测结果。然后,对于每一层,我们可以通过最小化损失![]() 来训练特征矩阵
来训练特征矩阵![]() 。现在,基于每一层节点的特征空间
。现在,基于每一层节点的特征空间![]() ,我们可以从特征空间中开发每一层的引导矩阵,即节点特征空间的内积。同时,由于引导矩阵是图结构的自适应,作者引入了学习矩阵,公式如式(12)所示。
,我们可以从特征空间中开发每一层的引导矩阵,即节点特征空间的内积。同时,由于引导矩阵是图结构的自适应,作者引入了学习矩阵,公式如式(12)所示。
![]() (12)
(12)
选择矩阵信息![]() 的原因是这里需要的是完整的结构信息,而不是节点的连接。为了增强引导矩阵的学习能力,作者增加了两层MLP以增加非线性拟合能力,并跳过连接以更容易优化,公式如式(13)所示。
的原因是这里需要的是完整的结构信息,而不是节点的连接。为了增强引导矩阵的学习能力,作者增加了两层MLP以增加非线性拟合能力,并跳过连接以更容易优化,公式如式(13)所示。
![]() (13)
(13)
其中![]() 和
和![]() 表示可训练的MLP,
表示可训练的MLP, ![]() 是第层引导矩阵。它基于从各层时间卷积中提取的特征进行发展,能够反映各层的个性化传播需求。
是第层引导矩阵。它基于从各层时间卷积中提取的特征进行发展,能够反映各层的个性化传播需求。
2.2 自适应传播(Adaptively Propagation)
图卷积操作融合节点及其邻居的特征以派生新的节点特征,该方法的核心之一是网络不同层之间的自适应学习传播过程。因此,将可学习引导矩阵纳入到图卷积框架中,并自动改变邻域间的传播权重。设![]() 表示输入信号,
表示输入信号,![]() 表示可学习的权重。所提方法在第层的传播过程如下:
表示可学习的权重。所提方法在第层的传播过程如下:
![]() (14)
(14)
其中是元素点积运算,![]() 表示第个图卷积层的输出。注意,
表示第个图卷积层的输出。注意,![]() 与相关,即不同层的不同引导矩阵,同时
与相关,即不同层的不同引导矩阵,同时![]() 由所有层共享(等式(8))。上述卷积操作遵循GCN,但图信号在时空数据中的传播类似于扩散过程。因此,本文最终的图卷积操作如公式(15)所示。
由所有层共享(等式(8))。上述卷积操作遵循GCN,但图信号在时空数据中的传播类似于扩散过程。因此,本文最终的图卷积操作如公式(15)所示。
![]() (15)
(15)
其中![]() 为转移矩阵,k为幂级数。在截断k步信息传播的图卷积的第层中,我们通过引导矩阵
为转移矩阵,k为幂级数。在截断k步信息传播的图卷积的第层中,我们通过引导矩阵![]() 改变图矩阵
改变图矩阵 的邻域权重。参数矩阵
的邻域权重。参数矩阵 作为特征选择器。在不存在空间依赖关系的极端情况下,聚合邻域信息只会给每个节点增加无用的噪声。因此,引入信息选择步骤(),过滤掉每一跳产生的重要信息。当给定的图结构不包含空间依赖关系时,式(15)仍然能够通过将所有
作为特征选择器。在不存在空间依赖关系的极端情况下,聚合邻域信息只会给每个节点增加无用的噪声。因此,引入信息选择步骤(),过滤掉每一跳产生的重要信息。当给定的图结构不包含空间依赖关系时,式(15)仍然能够通过将所有![]() 的调整为0来保留原始的节点自信息。
的调整为0来保留原始的节点自信息。
3 时间卷积模块(Temporal Convolution Module)
论文中的时间卷积模块采用基于CNN的方法,采用门控机制控制信息流。为了有效处理长时间数据和多尺度时间依赖,我们使用堆叠膨胀卷积和inception。门控机制可以有效地控制网络各层的信息流,其中只包含一个输出门。给定输入![]() ,公式如式(16)所示。
,公式如式(16)所示。
![]() (16)
(16)
Dilated Inception Convolutions:为了捕获不同范围的时间模式并处理长序列,在一个感知层中同时采用多个卷积核,即1 × 2,1 × 3,1 × 6,1 × 7,可以覆盖时间信号的固有周期。给定输入 和由
和由![]() ,
, ![]() ,
,![]() ,
,![]() 组成的filters,膨胀inception层采用等式(17)的形式。
组成的filters,膨胀inception层采用等式(17)的形式。
![]() (17)
(17)
其中,四个滤波器的输出根据最大滤波器截断到相同的长度,并跨通道维度进行级联,膨胀卷积由![]() 表示定义为
表示定义为![]() ,其中是膨胀因子。通过将具有膨胀因子的膨胀卷积层按递增顺序堆叠,模型的感受野呈指数级增长。它使膨胀卷积网络能够用更少的层捕获更长的序列,从而节省了计算资源。
,其中是膨胀因子。通过将具有膨胀因子的膨胀卷积层按递增顺序堆叠,模型的感受野呈指数级增长。它使膨胀卷积网络能够用更少的层捕获更长的序列,从而节省了计算资源。
4 优化目标(Optimization Objective)
算法1整个框架由动态图矩阵估计、自适应引导图传播、时间卷积和输出模块组成。在堆叠网络中,我们将每个时间卷积层的结果连接到输出模块。输出模块由两个卷积组成,DSTGN的最终预测如公式(18)(19)所示。
![]() (18)
(18)
![]() (19)
(19)
其中![]() 是通过跳跃连接来自第层的时间卷积(等式(16)),
是通过跳跃连接来自第层的时间卷积(等式(16)),![]() 表示平均绝对误差,
表示平均绝对误差,![]() 表示等式(19)中的可训练参数。跳跃连接本质上是
表示等式(19)中的可训练参数。跳跃连接本质上是![]() 标准卷积,其中
标准卷积,其中 是输入的序列长度。它对跳转到输出模块的信息进行标准化,使其具有相同的序列长度1。然后根据最终输出
是输入的序列长度。它对跳转到输出模块的信息进行标准化,使其具有相同的序列长度1。然后根据最终输出![]() 得到最优
得到最优![]() 。
。
在这个模型中,动态图由动态图估计模块学习,该模块使用图损失(等式(9))来控制动态图的质量,并进一步用于图卷积操作。为满足模型不同层的个性化传播需求,提出自适应引导传播,根据不同层的节点特征自动改变邻居间的权值。通过堆叠的时空卷积提取时空特征,并通过跳跃连接连接到输出模块得到预测结果。即动态图估计、自适应传播和模型参数学习三者相互增强。因此,我们将这些目标结合起来,以端到端的方式训练整个过程,即等式(20),其中 和
和 是平衡超参数。
是平衡超参数。
![]() (20)
(20)
整个算法流程如算法1所示。可以看到,我们的模型根据可训练的节点嵌入和动态节点级输入(等式(8))推断动态关系矩阵,同时使用图损失来确保学习到的邻接矩阵的属性(等式(9))。在堆叠的L层网络中,我们首先使用时间卷积模块独立提取每个节点的时间特征(等式(16)),然后根据捕获的特征估计层的引导矩阵(等式(13))。基于引导矩阵和动态图,在每一层执行信息自适应引导传播过程。最后,我们根据混合损失(等式(20))联合优化模型的参数。