【工程项目】训练yolov5模型并转换为rknn部署到RK3588S开发板
一. 部署概述
环境:Ubuntu20.04、python3.8
芯片:RK3568
二. 开发板刷系统
进入官网,下载必要文件

这里我选择下载ubuntu系统镜像。

1. 安装驱动
进入DriverAssitant_v5.1.1文件夹,开始安装驱动。

2. 安装系统
进入RKDevTool_Release_v2.93文件夹,启动开发工具。
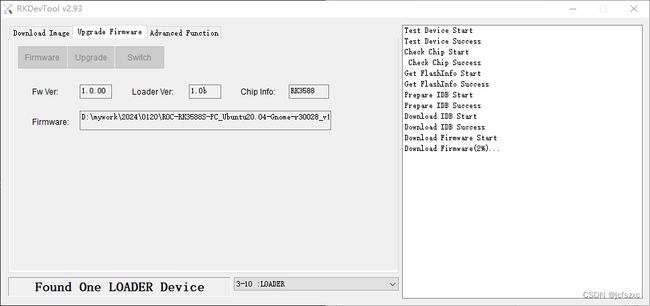
插上开发板电源,并通过typec接口与电脑连接
当开发工具显示检测到ADB设备后,选择下载好的镜像。

点击Upgrade开始烧录系统。
三. 准备模型
接下来的操作在另一台linux系统上进行!
接下来的操作在另一台linux系统上进行!!
接下来的操作在另一台linux系统上进行!!!
重要的事情说三遍。
1.配置基本环境
安装anaconda3,如果没安装过的话,可以参考我这篇博客。【记录】使用ssh在Ubuntu Server上配置环境
2. 下载yolov5
yolov5(V6.0版本) github
创建虚拟环境conda
conda create -n yolov5 python=3.8
conda activate yolov5
conda install -n yolov5 conda=23.7.3 conda-build=3.26.1
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt -i https://pypi.douban.com/simple
pip install numpy==1.20.3 -i https://pypi.douban.com/simple
pip install onnx==1.12.0 -i https://pypi.douban.com/simple
3. 配置RKNN环境
建议采用通过Docker镜像安装的方式,后续不用担心因环境搭建引起的问题。其中包含的项目代码和docker镜像在github。
rknn-toolkit2-1.6.0-cp38-docker.tar.gz
rknn-toolkit2-master.zip
安装docker
sudo apt-get install docker.io
# 加载镜像
docker load --input rknn-toolkit2-1.6.0-cp38-docker.tar.gz
feef05f055c9: Loading layer [==================================================>] 75.13MB/75.13MB
27a0fcbed699: Loading layer [==================================================>] 3.584kB/3.584kB
f62852363a2c: Loading layer [==================================================>] 424MB/424MB
d3193fc26692: Loading layer [==================================================>] 4.608kB/4.608kB
85943b0adcca: Loading layer [==================================================>] 9.397MB/9.397MB
0bec62724c1a: Loading layer [==================================================>] 9.303MB/9.303MB
e71db98f482d: Loading layer [==================================================>] 262.1MB/262.1MB
bde01abfb33a: Loading layer [==================================================>] 4.498MB/4.498MB
da9eed9f1e11: Loading layer [==================================================>] 5.228GB/5.228GB
85893de9b3b8: Loading layer [==================================================>] 106.7MB/106.7MB
0c9ec6e0b723: Loading layer [==================================================>] 106.7MB/106.7MB
d16b85c303bc: Loading layer [==================================================>] 106.7MB/106.7MB
Loaded image: rknn-toolkit2:1.6.0-cp38
# 检查镜像
docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
rknn-toolkit2 1.6.0-cp38 afab63ce3679 7 months ago 6.29GB
hello-world latest feb5d9fea6a5 19 months ago 13.3kB
# 运行镜像并将examples映射到镜像空间。根据自己路径修改命令中的路径。
docker run -t -i --privileged -v /dev/bus/usb:/dev/bus/usb -v/Projects/zxc/rknn-toolkit2-master/rknn-toolkit2/examples//:/examples rknn-toolkit2:1.6.0-cp38 /bin/bash
bin boot dev etc examples home lib lib32 lib64 libx32 media mnt opt packages proc root run sbin srv sys tmp usr var
# 运行demo
python test.py
W __init__: rknn-toolkit2 version: 1.4.0-22dcfef4
--> Config model
W config: 'target_platform' is None, use rk3566 as default, Please set according to the actual platform!
done
--> Loading model
2023-04-20 15:21:12.334160: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /usr/local/lib/python3.8/dist-packages/cv2/../../lib64:
2023-04-20 15:21:12.334291: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
done
--> Building model
I base_optimize ...
I base_optimize done.
I …………………………………………
D RKNN: [15:21:23.735] ----------------------------------------
D RKNN: [15:21:23.735] Total Weight Memory Size: 4365632
D RKNN: [15:21:23.735] Total Internal Memory Size: 1756160
D RKNN: [15:21:23.735] Predict Internal Memory RW Amount: 10331296
D RKNN: [15:21:23.735] Predict Weight Memory RW Amount: 4365552
D RKNN: [15:21:23.735] ----------------------------------------
D RKNN: [15:21:23.735] <<<<<<<< end: N4rknn21RKNNMemStatisticsPassE
I rknn buiding done
done
--> Export rknn model
done
--> Init runtime environment
W init_runtime: Target is None, use simulator!
done
--> Running model
Analysing : 100%|█████████████████████████████████████████████████| 60/60 [00:00<00:00, 1236.81it/s]
Preparing : 100%|██████████████████████████████████████████████████| 60/60 [00:00<00:00, 448.14it/s]
mobilenet_v1
-----TOP 5-----
[156]: 0.9345703125
[155]: 0.0570068359375
[205]: 0.00429534912109375
[284]: 0.003116607666015625
[285]: 0.00017178058624267578
done
4. 测试rk官方提供的yolov5s.onnx
进入目录/rknn-toolkit2-1.4.0/examples/onnx/yolov5,执行
python test.py
class: person, score: 0.8223356008529663
box coordinate left,top,right,down: [473.26745200157166, 231.93780636787415, 562.1268351078033, 519.7597033977509]
class: person, score: 0.817978024482727
box coordinate left,top,right,down: [211.9896697998047, 245.0290389060974, 283.70787048339844, 513.9374527931213]
class: person, score: 0.7971192598342896
box coordinate left,top,right,down: [115.24964022636414, 232.44154334068298, 207.7837154865265, 546.1097872257233]
class: person, score: 0.4627230763435364
box coordinate left,top,right,down: [79.09242534637451, 339.18042743206024, 121.60038471221924, 514.234916806221]
class: bus , score: 0.7545359134674072
box coordinate left,top,right,down: [86.41703361272812, 134.41848754882812, 558.1083570122719, 460.4184875488281]
执行完在此路径下可以看到生成了一张result.jpg,打开可以看到预测结果图。
5.转换yolov5s-Pytorch模型并测试推理
5.1 pt转onnx
注意!
注意!!
注意!!!
接下来的步骤很关键,我在网上找的博客提供的方案都不能正常推理。
转换步骤:
- 修改
models/yolo.py,修改class Detect(nn.Module):的forward函数,注意!!!仅在转换时修改,在训练时改回原状态!再训练时不要忘记哦!
# def forward(self, x):
# z = [] # inference output
# for i in range(self.nl):
# x[i] = self.m[i](x[i]) # conv
# bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
# x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
#
# if not self.training: # inference
# if self.grid[i].shape[2:4] != x[i].shape[2:4] or self.onnx_dynamic:
# self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
#
# y = x[i].sigmoid()
# if self.inplace:
# y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
# y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
# else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
# xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
# wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
# y = torch.cat((xy, wh, y[..., 4:]), -1)
# z.append(y.view(bs, -1, self.no))
#
# return x if self.training else (torch.cat(z, 1), x)
# 很多博主的修改是这一版本,但是这一版本会导致最终部署在RK3588S开发板上是出现测试结果出错
# 出现重复框选,选框混乱,置信度高于1的错误。
# def forward(self, x):
# z = [] # inference output
# for i in range(self.nl):
# x[i] = self.m[i](x[i]) # conv
# return x
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
if os.getenv('RKNN_model_hack', '0') != '0':
x[i] = torch.sigmoid(self.m[i](x[i])) # conv
return x
- 将
export.py文件中的run函数下的语句:
shape = tuple((y[0] if isinstance(y, tuple) else y).shape) # model output shape
改为:
# 这里同样和别人不同,记得更新成我的这个版本
shape = tuple(y[0].shape) # model output shape
并且在代码开头添加:
import os
os.environ['RKNN_model_hack'] = 'npu_2'
运行指令:
# 可以将模型路径修改为自己训练保存的模型路径
python export.py --weights best.pt --img 640 --batch 1 --include onnx --opset 12
- 然后在主文件夹下出现了一个
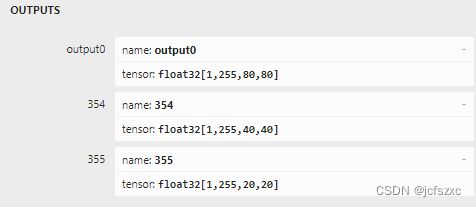
best.onnx文件,在Netron中查看模型是否正确 - 点击左上角菜单->Properties…
- 查看右侧OUTPUTS是否出现三个输出节点,是则ONNX模型转换成功。
- 如果转换好的best.onnx模型不是三个输出节点,则不用尝试下一步,会各种报错。
5.2 onnx转rknn并在PC上仿真测试
修改examples/onnx/yolov5/test.py文件
- 修改onnx路径
- 修改rknn保存路径
- 修改img测试图片路径
- 修改类别数
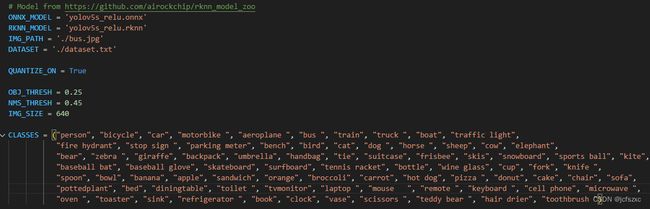
修改完成后运行脚本,获得推理坐标值和rknn模型文件,推理结果如下:
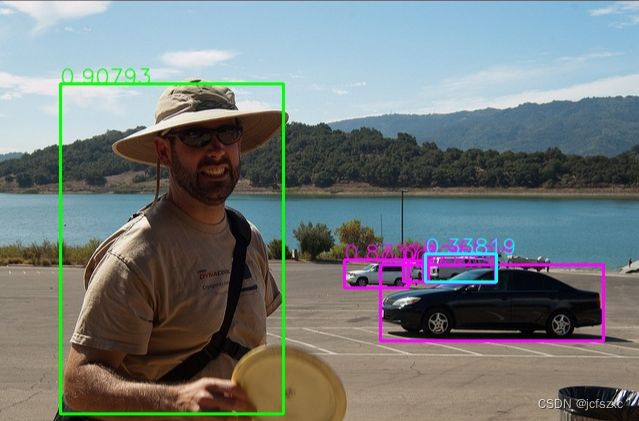
5.3 用自己数据集训练的模型板端推理
- 进入
/rknpu2/examples/rknn_yolov5_demo_v5/convert_rknn_demo/yolov5目录,修改onnx2rknn.py:
- 修改platform
- 修改模型路径
- 修改输入图片大小

- 修改dataset.txt:

- 运行脚本,将onnx转为rknn;
python onnx2rknn.py

-
复制rknn模型到
/rknpu2/examples/rknn_yolov5_demo_c4/model/RK3588 -
进入
/rknpu2/examples/rknn_yolov5_demo_c4/model目录,修改coco_80_labels_list.txt:

- 修改
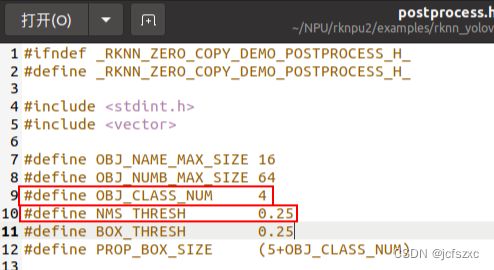
/rknpu2/examples/rknn_yolov5_demo_c4/include/postprocess.h,修改类别数和置信度阈值:
7.进入/rknpu2/examples/rknn_yolov5_demo目录,运行build-linux_RK356X.sh脚本编译程序,编译成功会生成一个install/和build/文件夹:
bash ./build-linux_RK356X.sh
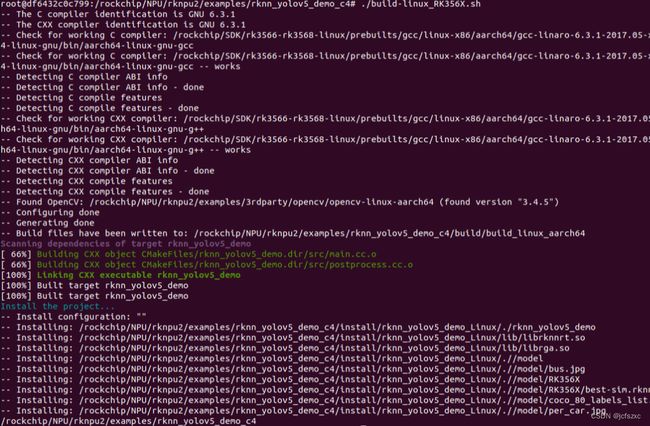
编译成功会生成一个install/和build/文件夹,

将install文件夹下的文件全部复制到开发板中,赋予rknn_yolov5_demo可执行权限,进入开发板中运行程序测试推理:
[root@RK356X:/mnt/rknn_yolov5_demo_Linux_c4]# chmod a+x rknn_yolov5_demo
[root@RK356X:/mnt/rknn_yolov5_demo_Linux_c4]# ./rknn_yolov5_demo ./model/RK356X/best-sim.rknn ./model/per_car.jpg
post process config: box_conf_threshold = 0.25, nms_threshold = 0.25
Read ./model/per_car.jpg ...
img width = 640, img height = 640
Loading mode...
sdk version: 1.4.0 (a10f100eb@2022-09-09T09:07:14) driver version: 0.4.2
model input num: 1, output num: 3
index=0, name=images, n_dims=4, dims=[1, 640, 640, 3], n_elems=1228800, size=1228800, fmt=NHWC, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003922
index=0, name=output, n_dims=4, dims=[1, 27, 80, 80], n_elems=172800, size=172800, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=64, scale=0.122568
index=1, name=320, n_dims=4, dims=[1, 27, 40, 40], n_elems=43200, size=43200, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=38, scale=0.110903
index=2, name=321, n_dims=4, dims=[1, 27, 20, 20], n_elems=10800, size=10800, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=36, scale=0.099831
model is NHWC input fmt
model input height=640, width=640, channel=3
once run use 86.341000 ms
loadLabelName ./model/coco_80_labels_list.txt
person @ (61 190 284 520) 0.907933
car @ (381 370 604 446) 0.897453
car @ (343 366 412 394) 0.873785
car @ (404 367 429 388) 0.628984
car @ (425 361 494 388) 0.365345
loop count = 10 , average run 96.655700 ms
推理结果如下: