全网首次揭秘:微秒级“复活”网络的HARP协议及其关键技术
导读|云计算时代,承担服务器之间数据传输工作的交换机成了数据中心的“神经枢纽”,一旦出故障将波及上层业务。然而单个交换机故障时,腾讯云的新一代高性能网络却可以在100微秒内找到新的通路实现0断链,做到高可用、高可扩展、高性能,从而保证业务不受影响。本文邀请到了腾讯云资深网络专家金峰及其带领的IaaS前沿技术研究团队来揭秘背后的武器——高性能网络传输协议HARP。通过本文希望可以带你了解传统网络传输协议面临的困难和挑战、HARP是如何应对并全网首次解析其中4个关键技术。
腾讯云一直在自研一款高性能网络协议——HARP(Highly Available and Reliable Protocol)。目前,HARP已在腾讯云的块存储等业务上逐步落地,并已成为腾讯自研银杉智能网卡及玄灵芯片的标准化能力。在单个交换机故障时,腾讯云的新一代高性能网络,可以在100微秒内找到新的通路,实现0断链,从而保证上层业务不受影响。本篇中,我们团队将回顾云时代下数据中心网络应对的困难卡点,提出一个高性能传输协议HARP方案并对其中4个关键技术点做全网首度解析。

数据中心网络的问题与挑战
为了满足数据中心的应用规模和性能要求日益增长的需求,数据中心的网络传输面临着巨大挑战:
1)无法保证可靠性
数据中心的交换机虽然已相当稳定,但仍然不可忽视它们出现亚健康的概率(设备软硬件故障或网络变更异常)。例如在我们的某个生产环境中,每年交换机硬件故障的比例约为0.15%。交换机的亚健康会直接影响到经过该交换机的业务应用的服务质量,轻则使得业务的吞吐下降和响应延时增加,重则造成连接中断,导致业务超时或失败。在一些对可靠性有严苛要求的应用,如高性能网络存储中,提高网络传输的可靠性已经迫在眉睫。
2)性能瓶颈
数据中心近年来涌现出很多具有高性能需求的应用,这些性能需求主要体现在高网络带宽,超低且一致的通信时延,超大的网络规模等方面。高带宽需求的应用,如大规模AI训练、高性能网络存储、分布式大数据应用等,促使着数据中心网络基础设施快速迈入100Gbps甚至400Gbps的时代。
然而要充分、稳定地利用好这些基础能力,网络传输在软硬件设计和成本控制上都面临着极大挑战。同时,数据中心里的时延敏感的应用,如内存数据库、传统HPC等,在时延上的极致需求给拥塞控制提出了严苛的挑战。最后,大规模数据中心应用(如分布式大数据应用和HPC)带来的大量的并发数据传输对网络传输协议的可扩展性也提出了更高的要求。

常用传输协议的问题
当前,TCP与RoCE v2(RDMA over Converged Ethernet v2)是数据中心网络中的主流传输协议。面对上述挑战,传统的TCP与RoCE v2传输协议已经无法应对。首先,为了充分利用100Gbps甚至400Gbps的网络带宽能力,基于软件实现的通用协议栈(比如内核TCP协议栈)往往会占用过高的CPU负载。而且其还会受到操作系统大内核的机制及其他运行软件的影响,导致性能不稳定。
其次,硬件卸载的网络协议栈(比如RoCE v2)虽然可以在降低CPU开销的同时获得较好的传输性能,但是由于成本的限制,其片上可以被用于存储连接的状态的资源十分有限。这意味着实现RoCE v2的网卡往往有着并发连接规模小的问题,导致其部署的规模及使用的场景会受到极大的限制。此外,TCP和现有的RoCE v2实现都面临拥塞控制性能不足(动态时延和尾时延大)和可靠性欠佳的问题。
而RoCE v2作为RDMA技术在数据中心的应用,已经被大量部署在生产系统。但其在可靠性和连接故障恢复方面的能力尚难满足应用需求。一方面,RoCE v2的多路径方案MP-RDMA(Multi-path RDMA)目前仅停留在学术界的研究,离实际落地还很遥远。另一方面,智能网卡上有限的片上资源一直制约着RoCE v2在单卡上的并发连接数,也就是其在大规模并发连接场景下的传输性能会急剧下降,增加多路径传输只会让其雪上加霜。
为提高TCP对于网络故障的容忍度,行业内近年来一直在关注MPTCP(Multipath TCP)方案。尽管在广域网开始部署应用,MPTCP应用在数据中心网络时、在路径切换、选择和聚合时存在明显的性能瓶颈。同时,由于它是基于TCP内核工作,在可扩展性方面亦存在较大的缺陷。此外,TCP协议栈更为复杂,很难把全功能稳定地实现在智能网卡上,这也导致其无法在内网场景获得极致的性能。
因此,我们需要设计一套新的网络传输协议,既能满足上层应用对于高可靠网络传输的要求,又能提供高带宽、低时延的数据传输服务,还能保持在大规模部署下的网络性能。

HARP与TCP、RoCE v2的特性对比
注:MPTCP(Multi-path TCP)方案未被广泛采用。MP-RDMA(Multi-path RDMA)方案停留在实验室阶段。HARP既有智能网卡版本的实现,也有用户态库版本的实现。TCP指最常被使用的内核TCP协议栈。

HARP是什么
HARP是腾讯云完全自研的数据中心高性能传输协议,主要针对上述可靠性、软硬件设计、拥塞控制和可扩展性等难点进行攻克。在保证端到端数据报文可靠传输的同时,HARP可以为上层应用提供高可靠、高性能(高带宽和低时延)、高可扩展的网络传输服务。就目前已经公开的传输协议而言,HARP是首个能够同时提供高可用和高扩展性的高性能传输协议。为达到高可靠传输,HARP采用了确定性多路径出传输,采用多条具有不重叠物理路径的通道进行并行传输,提高了对网络故障的抵抗力。
同时,为了达成高带宽和低时延的性能,HARP采用了软硬件分层设计来提高传输效率,并利用自研的拥塞控制算法(PEAD)保证了优良的数据流公平性和超低的网络排队。最后,为获得对大规模网络的高度扩展性,HARP采用了粒度可控的连接共享模式。通过把一条HARP连接复用来承接多条应用连接的流量,HARP可轻松支持大规模网络应用。

HARP关键技术点
HARP主要有以下四点的关键技术点:


1)软硬件的事务分离与能力结合
HARP采用软硬件分层的事务层和可靠传输层设计,以兼顾硬件可实现性、可靠传输的效率和消息事务的灵活性,如图所示。软硬件分离的架构设计为高效传输和低成本实现引入了新的可能性。在此架构下,可靠传输层可以专注于实现报文粒度的端到端可靠传输,而把更粗粒度的事务处理分化到了软件事务层。
特别地,HARP通过自研的报文编号方案追踪每个报文的发送和接收状态,以极低的开销支持乱序接收和选择性重传。同时,软件事务层可以提供高度灵活(贴合业务特性需求)的消息处理,而不占用昂贵的硬件资源。得益于此架构,HARP的软硬件系统可以在维持成本竞争力的前提下,提供业界领先的网络与业务性能。最终,HARP可以支持在10000节点的网络规模的业务中,提供最高性能输出。
2)粒度可配置的共享连接
为了满足多种业务环境的使用需求(裸金属,VM,CBS等)和大规模组网要求,HARP支持裸连接、VM级共享、主机级共享等粒度的连接模式。通过共享连接,HARP可以大幅减少连接数量,降低硬件实现的资源消耗,实现高度的可扩展性,轻松支持10K+级节点的大规模组网。在拥有N个服务器的大规模网络中,HARP可工作于主机级(IP对)共享模式,如图 2所示。假定每个服务器的通信进程数为P,为应对最严重情形的进程fullmesh通信,传统的TCP或RoCEv2在单服务器上需要N*P*P个连接,而HARP需要的连接数为N。可见HARP的连接规模与通信进程数无关,其在大规模网络有优良的扩展性。例如在100个服务器,每个服务器运行100个进程的场景,TCP/RoCEv2需要的连接数为100*100*100=1000K,这个数字已经远远超出高效率的硬件网卡可高性能支持的范围。
我们注意到业界最先进的RoCEv2网卡在10K连接数附近就已经可观测到严重吞吐损失。而HARP在此场景只需要N=100条连接。在大规模场景,如10K节点,每节点100进程,HARP需要的连接数也只有10K条(与进程数无关)。对于此数量的连接,在分离式优化架构和共享连接的加持下,HARP的硬件化网卡仍可达到最高吞吐。从上面可见,HARP在大规模高性能计算场景把支持的网络规模提高了两个数量级。
3)自研高性能拥塞控制
鉴于现有的拥塞控制难以满足我们多样化且高性能的业务需求,HARP采用深度自研的拥塞控制算法PEAD。PEAD基于交换机普遍支持的概率性ECN(显式拥塞通知)功能通过定制配置精确地感知网络拥塞,在维持高吞吐的同时,带来更公平的流吞吐、更通畅的网络和更准确的网络状态感知能力。相较于TCP,PEAD的消息完成时间FCT的中位数降低了35%(高带宽体现), p99分位值降低了70%(公平性体现),同时PEAD网络排队时延的p99分位值降低了90%(网络通畅性体现),如图所示。另外,HARP也支持使用基于网卡RTT探测的自研算法DARC,可在无任何交换机功能支持的网络中完成高性能拥塞控制。

4)确定性多路径并行传输及快速的故障路径切换
为提高连接对网络热点的规避能力,减轻网络负载不均衡性的影响和增强连接对网络故障的抵抗力,HARP在每个连接内采用多路径传输,如图 4所示。在HARP中,每条路径有独立的拥塞探测能力,连接会根据路径的发送能力(拥塞情况)进行调度发送报文。当某条路径有设备故障时,连接仍然可以通过其他路径继续进行传输。同时,得益于自研拥塞控制算法优良的网络控制和感知能力,连接的路径管理模块可以快速可靠地检测到路径故障,并在百微秒级时间内重新探测一条新的可用路径。例如当有单个Spine交换机故障时,其所在网络的 TCP连接的断链概率为24%,而HARP连接的断链概率为0。而当有单个Edge交换机故障时,其所在机架的 TCP连接的断链概率为75%,而HARP连接的断链概率仍然为0。同时TCP的典型重连恢复时间约为1s,而HARP的路径即使遭遇故障,也可以在百微秒级的时间内探测到新的路径恢复正常,恢复时间相比TCP减小了99.9%以上。HARP的快速故障检测主要得益于自研拥塞控制算法能把网络排队控制得非常低。从而我们可以在百微秒级的时间内以高置信度判断网络出现了故障,继而触发路径切换。
与传统的基于ECMP(等价多路径)哈希的多路径方案不同的是,HARP采用的是确定性多路径传输。原因在于,基于ECMP随机生成的多路径虽然能一定程度上避免网络热点问题,但其不可控的路径走向并不能最大化地发挥多物理路径带来的高带宽和高可靠性潜力。确切地说,一方面,在ECMP多路径方案下,一条连接的多条路径可能会在网络中的一段或多段链路中发生重叠,这会导致连接的有效可用带宽降低;另一方面,若重叠路径的节点发生故障,可能会导致连接的所有路径都故障(部分路径的数据传输和其他路径的ACK传输经过同一个故障设备),如图所示。
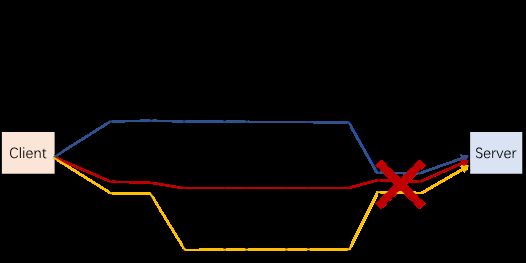

为了规避ECMP多路径的缺陷,在腾讯网络团队带来的自研路径控制能力支持下,HARP的确定性多路径最大限度地使用了非重叠路径的聚合带宽和它们带来的独立冗余性。在有4个Spine交换机的网络测试中,在单Spine交换机故障时,对比相较于基于ECMP的随机多路径的96%的连接存活率,HARP可以达到100%的连接存活率,如图 5所示。而在2个Spine交换机故障时,HARP相比ECMP多路径可以提高55%的连接存活率。


HARP特点与优势
“高可用”:主要面向对服务可靠性极高的存储业务(如腾讯的云硬盘服务(CBS,Cloud Block Storage)),当网络发生故障时上层业务仍然可用且其性能抖动小。
“高可扩展”:主要面向传统的高性能计算业务(如汽车制造商关于汽车流体力学的仿真),当参与计算的处理器核数不断增多时,系统的性能能够保持近似线性增长。
“高性能”:这是该协议的基本目标,主要体现在尽可能避免网络拥塞,并在各种负载时都能获得极高的传输带宽和最小的时延(包括平均时延和尾时延)。
腾讯云独创的“确定性多路径传输”、“自适应连接复用”、“自研拥塞控制算法”及“协议栈Offload”等技术,是HARP实现“高可用”、“高可扩展”、“高性能”等目标的关键。


HARP的典型应用
除面向云硬盘(CBS)与高性能计算(HPC)等基础场景外,HARP作为一个高性能的通信底座,还可以被应用于数据中心对网络性能要求较高的业务中,如AI训练、键值存储、分布式大数据应用、VPC网络等。


HARP发展展望
当前,腾讯云正不断地完善HARP的高性能通信库,包括使用Socket、IB Verbs、libfabric、UCX等通信接口接入HARP传输协议,以扩大HARP的生态。在硬件层面,腾讯云既可以基于友商标准以太网卡使能HARP的高可用、高可扩展的特性,又可以通过硬件卸载的形式将HARP全协议栈运行于自研银杉、玄灵智能网卡,以实现最高性能。此外,在虚拟化场景下,与AWS将EFA构建于SRD之上类似,HARP还将作为虚拟服务器间的高性能网络传输底座。随着HARP生态的不断完善,“HARP for Everything”的目标最终会实现。