Python3.11.5的入门与实战
第一章 Python的环境搭建
- 首先我们应在python的官网下载python安装包
点击这里>> 官网

- 安装时注意勾选添加环境变量,不然就只能安装后手动添加了

- 安装完成后进入cmd,输入python看到进入交互模式则表示安装完成

- 在cmd里面编程是不方便的,我们还需要IDE,下载pycharm
点击这里>>Pycharm
向下滚动页面,找到社区版,除非你有高级的需求,否则不需要使用到专业版

Pycharm是很棒的pythonIDE,安装后选择自己的运行环境和项目路径后,创建新的文件就可以开始愉快的写代码啦
第二章 基本数据类型
2.1 变量和标识符
什么是变量?
变量(variable):在程序运行时,可以发生变化的量,被称为变量
python如何定义变量?
python是弱数据类型语言,变量类型不固定,值是什么类型,变量就会自动变成什么类型。
而强数据类型的语言,例如Java,当定义数据类型后,不允许存储其他数据类型。
a = 10
如所示,这样就可以轻松的定义一个变量。
但在实际使用中最好是遵守如下的命名规范:
1> 变量名称只能由有效字符(大小写字母,数字,下划线)组成(name+ 报错语法错误)
2> 不能以数字开头
3> 不能是关键字或者是保留字
4> 变量命名尽量有意义(name age sex )
5> 小驼峰法 userAddress(除了第一个单词,其他单词首字母大写)
6> 下划线法(官方推荐)
标识符的命名规范
所谓的标识符就是对变量、常量、函数、类等对象起的名字。
首先必须说明的是,Python语言在任何场景都严格区分大小写!
Python对于标识符的命名有如下规定:
-
第一个字符必须是字母表中的字母或下划线’_’
-
标识符的其他的部分由字母、数字和下划线组成
-
标识符对大小写敏感
python的常量
python并没有定义常量的方式,常量是通过变量来模拟的
常量的命名规范:所有字母大写的单词是常量,这是一种约定俗成的方式而非强制约束。
python的关键字
关键字:在编程语言中有特殊含义的单词
保留字:目前版本还没使用,但后面可能会用的单词

2.2 数据类型
基本数据类型
int #整数
float #浮点
bool #布尔
True False
str #字符串
ord() #用来获取单个字符的编码(ASCII)
chr() #用来把编码转换成对应字符
| 转义 | 字符 描述 |
|---|---|
| (\在行尾时) | 续行符 |
| (\\) | 反斜杠 |
| (\') | 单引号 |
| (\") | 双引号 |
| \b | 退格(Backspace) |
| \000 | 空 |
| \n | 换行 |
| \r | 回车 |
| \f | 换页 |
| \yyy | 以\数字0开头后跟三位八进制数 |
| \xyy | 以\字母x开头后跟至少2位十六进制数 |
数据类型转换
# 使用这种方式可以转换数据类型,
num = int(input())
2.3 常见的运算符
算术运算符
| 运算符 | 含义 | 备注 |
|---|---|---|
| + | 加法运算 | |
| - | 减法运算 | |
| * | 乘法运算 | |
| / | 除法运算 | 在c++ C Java等强数据类型语言是整除运算 |
| % | 取余运算 | 求模或者求余数 |
| // | 整除运算 | 整除(只要整数部分) |
| ** | 幂次方运算 |
关系运算符
| 运算符 | 含义 |
|---|---|
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| == | 等于 |
| != | 不等 |
注意: 一般情况下关系运算符的值是一个布尔值,只有True和False
逻辑运算符
| 运算符 | 含义 | 备注 |
|---|---|---|
| and | 且 | 多个条件必须同时满足,则结果是true |
| or | 或 | 多个条件,至少一个为真,则为真 |
| not | 非 | 取反 ,一般会和In关键字一起使用,表示意义相反 |
赋值运算符
| 运算符 | 含义 | 备注 |
|---|---|---|
| = | 等于 | 赋值 |
| += | 加等 | a += 值 等价于 a = a + 值 |
| -= | 减等 | |
| *= | 乘等 | |
| /= | 除等 | |
| **= | 幂次方等 | |
| //= | 整除等 |
注意: python中没有自加自减运算
身份运算符
| 运算符 | 含义 | 备注 |
|---|---|---|
| is | 判断两个标识符是不是引用自一个对象 | x is y,类似id(x)==id(y),如果引用的是同一个对象则返回True,否则返回False |
| is not | 判断两个标识符是不是引用自不同对象 | x is not y |
注意: is与比较运算符“==” 的区别,两者有根本上的区别:
is用于判断两个变量的引用是否为同一个对象,而“==”用于判断变量引用的对象的值是否相等!
简单的说: ==是用来对变量的值进行判断的,而is判断的是内存地址。
成员运算符
in 与 not in是Python独有的运算符(全部都是小写字母),用于判断对象是否某个集合的元素之一

位运算符
a = 0011 1100
b = 0000 1101
a & b = 0000 1100
a | b = 0011 1101
a ^ b = 0011 0001
~ a = 1100 001

三目运算符
在python中的格式为:为真时的结果 if 判定条件 else 为假时的结果
例如:
a = input()
b = input()
max = a if a > b else b
print(max)
# 此代码,当满足a > b 时,输出if前面的值也就是a,不满足则输出else后面的值,也就是b
示例
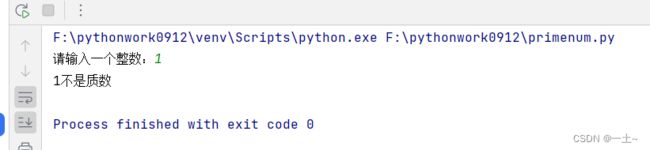
1. 设计一个程序,判断输入的数字是不是质数
prime_num = int(input("请输入一个整数:")) #获取用户输入内容
if prime_num <= 1: #这个条件语句检查用户输入是否小于等于1;是:输出不是质数;否:执行后面的语句
print(f"{prime_num}不是质数")
else:
for i in range(2, int(prime_num**0.5)+1): #如果输入大于1进入else。开始for循环,从2开始逐个遍历直到prime_num的平方根
if prime_num % i == 0: #检查prime_num是否能被i整除;
print(f"{prime_num}不是质数") #有能被整除的则打印不是质数
break #使用break跳出循环
else:
print(f"{prime_num}是一个质数") #若循环正常结束则没有可以整除的,打印是一个质数
结果展示:




2. 使用turtle画一个五环
import turtle as t #导入turtle库取别名为t,方便书写
color = ["blue","black","red","yellow","green"] #定义一个列表来存储五环的五种颜色
coordinate = [(-220, 50), (0, 50),(220, 50), (-110, -85), (110, -85)] #定义列表来存储五环的圆心坐标
t.pensize(10) #设置画笔的粗细
for i in range(5): #for循环开始画圆画5个圆就循环5次
t.color(color[i]) #根据i的值读取color列表的值获取颜色
t.penup() #把笔抬起来
t.goto(coordinate[i]) #根据i的值读取coordinate列表的值获取坐标
t.pendown() #把笔放下
t.circle(100) #开始画圆半径100
t.done() #停止画笔,但不关闭窗口
如下图所示:这是绘制完成的样子

3. 使用循环显示四种模式,使用嵌套循环在四个独立的程序中显示下面四种模式。

print("模式A")
for i in range(1, 7): #外部循环,控制行数,表示6行输出
for num in range(1, i + 1): #内部循环,控制每行打印的数字,从1开始到i结束
print(num, end=" ") #循环一次打印一次num的值,并在num后面有个空格
print() #换行,循环结束,开始从头循环
print("模式B")
for i in range(6, 0, -1): #外部循环,控制行数,表示6行输出,i的值将从6-1倒序
for num in range(1, i + 1): #内部循环,控制数字,第一行从1开始i结束
print(num, end=" ") #循环一次打印一次num的值,并在num后面有个空格
print() #换行,循环结束,开始从头循环
print("模式C")
for i in range(1,7):
for space in range(6-i): #内部循环,控制空格个数,从0开始到6-i-1
print(" ",end=" ")
for num in range(i,0,-1): #内部循环,控制输出数字,从i开始到1结束,每次递减1
print(num,end=" ")
print()
print("模式D")
for i in range(6, 0, -1):
for space in range(6 - i):
print(" ", end=" ")
for num in range(1, i + 1): #内部循环,1开始1结束,默认每次+1
print(num, end=" ")
print()
执行结果展示:
F:\pythonwork0912\venv\Scripts\python.exe F:\pythonwork0912\for-demoABCD.py
模式A
1
1 2
1 2 3
1 2 3 4
1 2 3 4 5
1 2 3 4 5 6
模式B
1 2 3 4 5 6
1 2 3 4 5
1 2 3 4
1 2 3
1 2
1
模式C
1
2 1
3 2 1
4 3 2 1
5 4 3 2 1
6 5 4 3 2 1
模式D
1 2 3 4 5 6
1 2 3 4 5
1 2 3 4
1 2 3
1 2
1
Process finished with exit code 0
4. 在金字塔模式中显示数字,编写一个嵌套for循环来显示下面的输出。

for i in range(0, 8):
for space in range(1, 9 - i): # 控制左侧倒三角空白区域
print("\t",end="")
for num_lift in range(0, i + 1): # 控制左侧数字
print(2 ** num_lift, end="\t")
for num_right in range(i, 0, -1): # 控制右侧数字
print(2 ** (num_right - 1), end="\t")
print()
结果为:

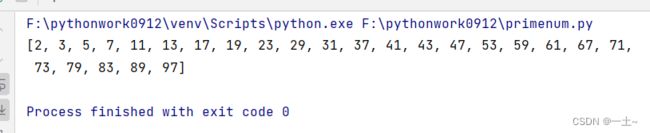
5. 实现求1-100之间的质数
prime_nums = [] #定义一个空列表
for prime_num in range(0,101): #遍历0-100
if prime_num <=1: #过滤2以下的
TF_prime = False
else:
TF_prime =True
for num in range(2, int(prime_num**0.5)+1): #循环迭代2到数字的平方根
if prime_num % num == 0: #检查是否有因子
TF_prime = False #有则设为False
break
if TF_prime: #这句实际是 if TF_prime == True,简写就是这样,bool为真则加入列表
prime_nums.append(prime_num)
print(prime_nums)
结果为:
第三章 程序控制流程
3.1 顺序流程
程序的执行顺序:
自上而下的,书写顺序就是执行顺序
一般思路:
初始化变量;数值输入;算法处理;输出。
示例:
#代码执行时会先进入阻塞状态,直到用户输入华氏度或者按下enter
F = int(input("请输入华氏温度:"))
#转换算法
C = 5 / 9 * (F - 32)
#输出结果
print("摄氏温度为:%.2f" % C)
3.2 选择结构
单分支
# 注意python是强缩进语句,一般使用tab进行缩进
if 条件
#执行语句
双分支
if 条件:
#执行语句
else:
#执行不满足的语句
多分支
if 条件1:
#执行条件1满足的代码
elif 条件2:
#执行条件2满足的代码
…………
elif 条件n
#执行条件n满足的代码
else:
#前面所有条件都不满足的情况
#else不是必须的
3.3 while循环
一般循环用for,while不咋好用。适合不知道循环边界时使用
while 条件:
循环体
#输出99乘法表
i = 1
while i <= 9:
j = 1
while j <= i:
print("%s X %s = %s " %(i,j,(i*j)),end = "")
j += 1
print()
i += 1
3.4 for循环
for 循环 常用的循环结构,一般使用for in 结构用来遍历容器.
# 打印0~10
for i in range(0,11)
#range 范围:左闭右开默认步长1
print(i)
3.5 break和continue关键字
break:终止循环
continue:跳过本次继续下一次循环
for i in range(101):
if i == 50:
break #终止循环
print(i)
else:
print("break了就不进来了")
print(“循环结束了”)
#此代码只会打印最后一个print,不会进入else
for i in range(101):
if i == 50:
continue
print(i)
else:
print("break了就不进来了")
print("循环结束了")
#此代码会进入else执行print语句
第四章 内置容器
4.1 列表 list
#列表定义
ls = [2,3,4,5]
ls = list([1,2,"wzh"])
#如何遍历容器
for i in ls:
print(i)
#while循环
Index = 0
While index < len(ls):
Print(ls[index])
Index += 1
| 方法名 | 含义 |
|---|---|
| append() | 向列表尾部追加元素 |
| insert(index, object) | 向指定的位置追加元素 |
| sort() | 列表排序(只能排Int)字母按照ASCII值进行排序,类型不能混淆 |
| index() | 查找元素第一次在列表中出现的位置,如果没有这个元素则会报错 |
| reverse() | 将列表元素顺序翻转 |
| remove() | 通过元素来移除元素,如果元素不存在则抛出异常 |
| count() | 统计元素在列表中的个数 |
| clear() | 清除元素 |
| copy() | 浅拷贝对象(拷贝) 不等价于 = (引用传递),在堆内存中进行对象拷贝 |
| extend() | 合并列表 |
| pop() | 与append()相反,删除列表最后一个元素,并返回值这个元素,要删除指定位置的元素,用pop(i)方法,其中i是索引位置 |
| 内存模型: |
栈(stack):
先进后出,后进先出
堆(heap):
队列:先进先出,后进后出
4.2 集合 set
集合是无序的,不能重复的
创建集合的方法:
| 方法 | 含义 |
|---|---|
| s= set() | 使用全局函数set()创建一个集合 |
| s = set({1,3,4,5}) | 创建集合并赋值 |
| s = {} | 如果使用空的{}来创建一个对象,改对象是一个字典,不是一个集合 |
| s = {元素} | {}至少要有一个元素,此时才是集合 |
常见使用方法:
| 方法 | 含义 |
|---|---|
| Clear | 用于清空集合中的所有元素,使其成为空集合 |
| remove | 用于从集合中移除指定的元素。如果指定的元素不存在于集合中,它会引发 KeyError 异常 |
| copy | 用于创建集合的副本。它返回一个新的集合,该新集合包含与原始集合相同的元素。这个方法通常用于在不影响原始集合的情况下进行操作 |
| add | 添加元素,如果元素重复,不能添加,涉及到hash算法 |
| difference | 差集 |
| intersection | 交集 |
| union | 并集 |
| update | 更新集合,合并集合 |
| discard | 移除元素,但是元素如果不存在,则不做任何操作 |
4.3 元组 tuple
元组的创建:
弱数据类型创建 t = (1,2,3,4)
tuple全局函数创建 t = tuple() t = tuple((元素……))
元组是一个不可变类型,元组的元素一旦定义下来,则无法改变
注意:
虽然元组不可变,如果元组内部元素是可变类型,那么改元组就可变
4.4 字典 dict
d = {“name”:”zhangsan”,”age”:16,”gender”:”男”}
dd = dict()
dd = dict({“name”:”zhangsan”,”age”:16,”gender”:”男”})
通过key来访问对应的值 d[“name”]
字典对象[key] 返回key对应的值,如果没有抛出异常
字典对象[key] = 新值
字典对象新[key] = 新值 增加新的键值对
常用方法:
| 方法名 | 说明 |
|---|---|
| clear | |
| copy | |
| get | 和字典对象[key]类似,通过key值获取值,注意,如果没有该键,则返回none |
| keys | 返回所有的键 |
| values | 返回所有的值 |
| setdefault | 设置一个默认值 |
| items | 返回键值对 |
| pop(key) | 通过键来移除键值对,如果没有,则抛出异常 |
| popitem | 移除键值对(按照LIFO后进先出的顺序) |
4.5 排序算法
冒泡排序
冒泡排序是一种排序算法,通过重复的遍历元素列表,比较相邻的元素并交换他们,如果顺序不正确则一直重复,他的基本思想就是对比两个元素把大的那个往后移,就像气泡那样,不断上升。
#给定一个列表
ls = [9, 54, 3, 6, 8, 10, 66, 99, 30, 44, 28]
# 遍历这个列表,缩小范围,用于将最大的元素冒泡到正确的位置
for i in range(0, len(ls) - 1):
# 用于比较相邻的元素并交换
for j in range(0, len(ls) - 1 - i):
#如果ls[j]>ls[j+1]那么交换位置,将大的元素往后移动
if ls[j] > ls[j + 1]:
ls[j], ls[j + 1] = ls[j + 1], ls[j]
print(ls)
选择排序
选择排序将未排序的部分中的最大值/最小值,放在已排序的末尾。不断重复,直到排序完成
ls = [9, 54, 3, 6, 8, 10, 66, 99, 30, 44, 28]
# 每次大循环会确定第一个元素为最小值。当序列为n时,比较n -1次即可完成排序
for i in range(0, len(ls) - 1):
# 每次大循环会确定第一个元素为最小值。
# 所以比较范围从左不断向右-1
# 这使得内层循环的左边界为i+1,右边界不变
for j in range(i + 1, len(ls)):
if ls[i] > ls[j]:
ls[i], ls[j] = ls[j], ls[i]
print(ls)
插入排序
插入排序将待排序的列表分成已排序和未排序的部分,从未排序的部分中逐个选择元素,比较和已排序元素的大小并不断向左移动已排序元素来完成。
arr = [8, 3, 2, 6, 1, 4, 9, 7]
#遍历未排序部分,
for i in range(1, len(arr)):
# 用于比较当前元素arr[i]与已排序部分元素arr[j-1],并不断向左移动已排序元素,直到找到适当的位置。
for j in range(i, 0, -1):
if arr[j] <= arr[j - 1]:
arr[j], arr[j - 1] = arr[j - 1], arr[j]
print(arr)
计数排序
计数排序是一种非比较性的排序算法,统计每个元素在待排序序列中出现的次数,然后根据这些统计信息重新给出列表。
- 首先找出最大和最小值。
- 创建一个计数数组(counting array)来统计每个元素在待排序序列中出现的次数。计数数组的大小是max - min + 1,每个元素的索引对应着待排序元素的取值。初始时,计数数组的所有元素都初始化为0。
- 遍历待排序序列,将每个元素的值作为计数数组的索引,并将对应索引的计数加1。
- 根据计数数组中的统计信息,重建有序序列。遍历计数数组,根据每个元素出现的次数,依次将元素放回原始序列中。可以根据计数数组的索引来确定元素的值,同时更新计数数组中的统计信息,确保相同元素的位置不会发生冲突。
# 计数排序
ls = [9, 54, 3, 6, 8, 10, 66, 99, 30, 44, 28]
# 找到ls中的最大值
max_v = ls[0]
for i in range(1, len(ls)):
if max_v < ls[i]:
max_v = ls[i]
# 找到ls中的最小值
min_v = ls[0]
for i in range(1, len(ls)):
if min_v > ls[i]:
min_v = ls[i]
# 根据最大值和最小值生成一个升序的字典,其中每一个key的value 都是记录该key在ls中出现的次数
dc = dict()
for i in range(min_v, max_v + 1):
dc[i] = 0
for item in ls:
dc[item] += 1
# 根据字典记录新的列表,如果某个选项出现了n次,则往新列表中添加n个
ls_new = []
for key, value in dc.items():
for i in range(value):
ls_new.append(key)
print(ls_new)
4.6 查找算法-二分查找
二分查找是一种高效的查找算法,用于在有序的数组中查找指定元素的位置,每次查找的范围减半,首先确定区间,第一个和最后一个,计算中间的元素的索引,如果找到中间元素==目标元素则完成查找,返回中间的元素索引。
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2 # 计算中间元素的索引
if arr[mid] == target:
return mid # 找到目标元素,返回索引
elif arr[mid] < target:
left = mid + 1 # 缩小查找区间为右半部分
else:
right = mid - 1 # 缩小查找区间为左半部分
return -1 # 目标元素不在数组中
# 测试二分查找
my_list = [1, 3, 6, 8, 9, 12, 15, 18, 21, 24]
target = 9
result = binary_search(my_list, target)
if result != -1:
print(f"目标元素 {target} 在列表中的索引为 {result}")
else:
print(f"目标元素 {target} 不在列表中")
第五章 函数
5.1 函数的基础
函数的定义
在Python中,函数是一段可重用的代码块,用于执行特定的任务。您可以使用def关键字来定义一个函数,并在函数体内编写代码。以下是一个简单的函数定义示例:
def greet(name):
print(f"Hello, {name}!")
函数的调用
要调用函数,只需使用函数名并传递所需的参数(如果有的话)。例如:
greet("Alice")
这将打印出:Hello, Alice!
参数传递
Python函数可以接受多个参数,参数之间使用逗号分隔。参数可以是任何数据类型,包括整数、字符串、列表、字典等。函数可以根据需要使用这些参数来执行操作。
def add(a, b):
result = a + b
return result
sum = add(3, 4)
默认参数
您还可以为函数参数提供默认值,这使得某些参数成为可选的。如果调用函数时没有传递这些参数,将使用默认值。
def greet(name, greeting="Hello"):
print(f"{greeting}, {name}!")
greet("Alice") # 输出:Hello, Alice!
greet("Bob", "Hi") # 输出:Hi, Bob!
可变数量参数
有时候,您不知道函数将接受多少个参数。在这种情况下,您可以使用可变数量参数。使用*前缀的参数将收集所有传递给函数的额外参数,并将它们作为元组传递给函数。
def average(*numbers):
total = sum(numbers)
count = len(numbers)
return total / count
avg = average(1, 2, 3, 4, 5)
5.2 返回值
使用return语句
函数可以使用return语句来返回一个值。返回值可以是任何数据类型。如果函数没有return语句,将默认返回None。
def add(a, b):
return a + b
result = add(3, 4)
多个返回值
Python函数也可以返回多个值,实际上,它返回一个元组(tuple)。这使得您可以方便地返回多个相关的值。
def get_name_and_age():
name = "Alice"
age = 30
return name, age
person_info = get_name_and_age()
>>>('Alice', 30)
函数文档字符串(docstring)
函数文档字符串是一种可选的字符串,用于描述函数的目的、用法和参数等信息。它们通常位于函数定义的顶部,并由三重引号括起来。
def add(a, b):
"""
这个函数用于计算两个数的和。
参数:
a -- 第一个数
b -- 第二个数
返回值:
两个数的和
"""
return a + b
可以使用help()函数或在交互式环境中键入函数名来查看函数的文档字符串。
5.3 作用域
全局作用域
在Python中,变量可以具有不同的作用域。全局作用域是在整个程序中可见的作用域,通常在函数外定义的变量具有全局作用域。
x = 10
def print_x():
print(x)
print_x() # 输出:10
局部作用域
局部作用域是在函数内部可见的作用域。在函数内定义的变量通常具有局部作用域,不能在函数外部访问。
def print_local_var():
y = 5
print(y)
print_local_var() # 输出:5
# print(y) # 会引发NameError,因为y是局部变量
global和nonlocal关键字
如果需要在函数内部修改全局变量,可以使用global关键字。类似地,如果在嵌套函数内部修改外部函数的局部变量,可以使用nonlocal关键字。
x = 10
def modify_global():
global x
x = 20
modify_global()
print(x) # 输出:20
5.4 递归函数
什么是递归
递归是一种算法设计技巧,其中一个函数在其自身内部调用。在递归函数中,问题被分解成一个
或多个更小的相似问题,直到达到基本情况,然后开始返回结果并合并答案。
递归示例
一个经典的递归示例是计算阶乘。
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n - 1)
result = factorial(5) # 计算5的阶乘
递归 vs 迭代
递归是一种强大的技巧,但它可能导致堆栈溢出错误。在某些情况下,迭代可能更有效。因此,在选择使用递归还是迭代时,需要谨慎考虑。
迭代器
迭代器是一种特殊的对象,它允许您逐个访问元素,而不是一次性加载整个数据集。迭代器通常使用iter()和next()函数来实现。
fruits = ["apple", "banana", "cherry"]
iterator = iter(fruits)
print(next(iterator)) # 输出:apple
print(next(iterator)) # 输出:banana
print(next(iterator)) # 输出:cherry
当没有更多的元素可供迭代时,next()函数会引发StopIteration异常。
迭代与递归的比较
迭代和递归都用于处理重复任务,但它们之间有一些重要的区别:
- 递归是通过函数内部的自我调用来处理任务,而迭代是通过循环执行来处理任务。
- 递归通常需要更多的内存,因为它会在函数调用栈上创建多个副本,而迭代通常需要较少的内存。
- 在某些情况下,递归更容易理解和编写,而在其他情况下,迭代可能更有效。
5.5 高级函数技巧
匿名函数(Lambda函数)
Lambda函数是一种轻量级的函数,通常用于临时的、简单的操作。它们可以在不定义具名函数的情况下创建。
add = lambda x, y: x + y
result = add(3, 4)
高阶函数
Python支持高阶函数,这意味着您可以将函数作为参数传递给其他函数,或从函数中返回函数。
def apply(func, x):
return func(x)
def double(x):
return x * 2
result = apply(double, 5)
闭包
闭包是包含了自由变量(在函数内部引用但不在函数参数中定义的变量)的函数。它们可以捕获外部函数的状态。
def outer_function(x):
def inner_function(y):
return x + y
return inner_function
closure = outer_function(10)
result = closure(5) # 结果是15
装饰器
装饰器是一种高级函数技巧,用于修改其他函数的行为。它们通常用于添加功能,如日志记录、性能测量等,而无需修改原始函数的代码。
def my_decorator(func):
def wrapper():
print("Something is happening before the function is called.")
func()
print("Something is happening after the function is called.")
return wrapper
@my_decorator
def say_hello():
print("Hello!")
say_hello()
示例二
- 实现扫描全盘的函数
import os # 导入操作系统模块
# 定义一个函数,用于递归扫描指定目录下的文件和目录,并计算它们的数量
def scan_disk(dir, count=[0, 0]):
# 获取目录下的所有文件和子目录
files = os.listdir(dir)
# 遍历目录下的所有文件和子目录
for file in files:
# 使用os.path.join()构建当前文件或目录的完整路径,并规范化路径
file_path = os.path.join(dir, file)
file_path = os.path.normpath(file_path)
# 打印当前文件或目录的路径
print(file_path)
# 检查当前项是文件还是目录
if os.path.isdir(file_path):
# 如果当前项是目录,增加目录计数,并递归调用scan_disk函数扫描子目录
count[0] += 1
scan_disk(file_path, count)
else:
# 如果当前项是文件,增加文件计数
count[1] += 1
# 返回文件和目录计数的列表
return count
# 调用函数开始扫描指定目录
result = scan_disk('F:/test001')
# 打印文件数和目录数
print("文件数", result[1])
print("目录数", result[0])

- 编写程序显示前 100个回文素数。每行显示 10个数字,并且准确对齐
def prime_num(n): #判断是不是素数
if n <= 1:
return False
for i in range(2, int(n ** 0.5) + 1):
if n % i == 0:
return False
return True
def pali(n): #判断是不是回文数
return str(n) == str(n)[::-1] #将n转换成字符串,切片反转字符串,比较是不是相等
def find_pp(): #查找前100个
count = 0
num = 2
while count < 100:
if prime_num(num) and pali(num): #两个函数都返回true
print(f"{num:7}", end=" ") #格式化打印num七个字符宽度
count += 1
if count % 10 == 0: #没十个换行
print()
num += 1
find_pp() # 调用函数

- 编写一个测试程序,读入三角形三边的值,若输人有效则计算面积。否则,显示输入无效
import math #导入数学模块
a = float(input("请输入边a"))
b = float(input("请输入边b"))
c = float(input("请输入边c"))
if a + b > c and a + c > b and b + c > a:#两边之和大于第三边
s = (a + b + c) / 2 #计算半周长
area = math.sqrt(s * (s - a) * (s - b) * (s - c)) #海伦公式
print(f"面积为:{area}")
else:
print("无法构成三角形,请重新输入")

第六章 字符串和切片
字符串对象和常见方法
python字符串的定义方式
-
由弱数据类型语言的特性决定的:
- 单引号
- 双引号
- 三引号(允许换行)
- str
- s = str(“字符串”)
字符串常见方法
| 方法名 | 说明 |
|---|---|
| capitalize() | 格式化字符串,将字符串的首字母大写 |
| center(width,[fillchar])之前\t(4个空格) | 设置字符串按照长度居中(,如果长度小于字符串,不做任何操作整个长度是50的中间,单位是符号位,字符串在50的),fillchar默认是空格,是可选参数 |
| count() | 统计字符或字符串的出现次数 |
| endswith() | 判断字符串是否以XXX结尾 |
| startswith() | 判断字符串是否以XXX开头 |
| index() | 查找字符或者字符串在字符串第一次出现的位置,如果不存在则抛出异常 |
| rindex | 从右向左找,查找字符或者字符串在字符串中最后一个的位置 |
| find | 查找字符或者字符串在字符串第一次出现的位置,如果不存在返回-1 |
| rfind | 从右向左找,查找字符或者字符串在字符串中最后一个的位置 |
| encode(对应的编码) | python3提供将字符串转换为字节的方法(网络传输的时候需要将电信息存储到磁盘上,存储到字符串上是需要二进制数据,在python2中涉及到字符转换非常的麻烦,他不支持中文)(转换的时候需要指定编码集utf-8,转换成功后是字节,type,bxxxx是字节数据)如果字节想转换为字符串?--------decode(对应的的编码)((dir(t) t是字节) 不是字符串的方法) -------字节的方法 |
| format | 格式化字符串 n =2 nn=3 print(“n={},nn={}”.format(n,nn)) |
| islower | 判断是否都是小写字母 |
| isupper | 判断是否都是大写字母 |
| istitle | 判断字符串是否是标题 |
| isspace | 判断是不是空格位(不常用,了解就行) |
| isdigit | 判断是否为数字(将字符串转换为整数,如果不是数字不能转int) |
| isalnum | 不是判断是不是全是数字,判断是否是有效符号(*$%) |
| isalpha | 判断是否都是字母 |
| title | 将字符串转换为标题格式 |
| lower | 将字符串转换为小写 |
| upper | 将字符串转换为大写 |
| split(“符号”) | 按照指定的符号将字符串进行切割(ls = s.split(" ") -----以空格分割),返回一个列表 |
| join | 按照特定的符号将一个可迭代对象拼接成字符串(" ".jion(ls) ------空格拼,不是列表的方法) |
| strip | 清除字符串两侧的空格(java里面有trim()),不能清除字符串中间的空格,例如注册信息的时候,容易打空格,后台接收到的字符串含有很多空格“name ” ,如果用户以"name"登录的时候会登录失败 |
| lstrip | 清除字符串左侧的空格 |
| rstrip | 清除字符串右侧的空格 |
| replace(“原字符串”,“新字符串”) | 替换对应的字符串 |
| ljust | 左对齐 |
| rjust | 右对齐 |
字符串切片
切片操作基本表达式:object[start_index : end_index : step]
step:正负数均可,其绝对值大小决定了切取数据时的“步长”,而正负号决定了****“切取方向”,正表示“从左往右”取值,负表示“从右往左”取值。当step省略时,默认为1,即从左往右以增量1取值。“切取方向非常重要!”“切取方向非常重要!”“切取方向非常重要!”,重要的事情说三遍!
start_index:表示起始索引(包含该索引本身);该参数省略时,表示从对象“端点”开始取值,至于是从“起点”还是从“终点”开始,则由step参数的正负决定,step为正从“起点”开始,为负从“终点”开始。
end_index:表示终止索引(不包含该索引本身);该参数省略时,表示一直取到数据”端点“,至于是到”起点“还是到”终点“,同样由step参数的正负决定,step为正时直到”终点“,为负时直到”起点“
对象[start:] 从start位置开始切割字符串,切到末尾,包含strat位置
对象[start:end] 从start位置开始切割字符串,切到end位置为止,包含strat位置,不包含end位置
对象[start:end:step] 从start位置开始切割字符串,切到end位置为止,step为步长,默认值为1,当步长为负数的时候,会反向切割
第七章 内置模块
import xxx就是引用模块
OS模块
| 方法 | 说明 |
|---|---|
| chdir(path) | 修改当前工作目录 os.chdir(“c:\”)------os.chdir(“…”) ,一般不会更改 |
| curdir | 获取当前目录 属性 注意返回的是相对路径 (绝对路径os.path.abspath(os.curdir)) |
| chmod() | 修改权限 主要用在linux,help(os.chmod)(不做演示) |
| close | 关闭文件路径(不做演示) |
| cpu_count() | 返回cpu的核对应线程数(2核4线程) |
| getcwd() | 获取当前路径,返回的是绝对路径 ,相当于linux的pwd |
| getpid() | 获取当前进程的进程编号(任务管理器—详细信息) |
| getppid() | 获取当前进程的父进程的进程编号 |
| kill() | 通过进程编号杀死进程(明白就行) |
| linesep | 对应系统下的换行符 |
| listdir() | 返回对应目录下的所有文件及文件夹(隐藏文件也可以调取出来),返回的是列表 |
| makedirs() | 创建目录,支持创建多层目录(文件夹)os.makedirs(“a/b/c/d”) |
| mkdir | 创建目录,只支持一层创建,不能创建多层 |
| open | 创建文件,等价于全局函数open (IO流详细讲) |
| pathsep | 获取环境变量的分隔符 windows ; linux : |
| sep | 路径的分割符 windows \ linux / |
| remove(文件名或者路径) | 删除文件 os.remove(b.text) |
| removedirs() | 移除目录,支持多级删除,递归删除 |
| system | 执行终端命令 |
os.path模块
| 方法 | 说明 |
|---|---|
| abspath(相对路径) | 返回路径对应的绝对路径(完整的路径) path.abspath(“.”) |
| altsep | 查看python中的各种符号 |
| basename | 文件名称,shell编程里面也有 path.basename(“路径”) |
| dirname | 文件所在的目录,shell编程里面也有 |
| exists | 判断文件或者目录是否存在(特别有用,使用爬虫爬取数据的时候需要判断是否有这个文件或者文件夹) |
| getctime | 创建时间(不做演示) |
| getmtime | 修改时间(不做演示) |
| getsize | 获取文件的大小,单位是字节 |
| isdir | 判断path是不是目录(文件夹) |
| isfile | 判断path是不是文件 |
| isabs | 判断是不是绝对路径(不演示) |
| islink | 判断是不是连接(不演示) |
| ismount | 判断是不是挂载文件(Linux下要用的)(不演示) |
| join (p1,p2) | 拼接路径 name=“123.txt” url=“C:/a/b/c” url +“/”+name path.jion(url,name) |
| sep | 路径分隔符 url + path.sep +name |
| split | 分割路径 path.split(“C://desktop”) |
| realpath | 返回真实路径 和abspath一样 |
UUID模块
UUID是一种标识符,通常用于标识信息或对象的唯一性。
import uuid
# 生成随机的UUID
unique_id = uuid.uuid4()
print(unique_id)
加密模块
hashlib模块
import hashlib
dir(hashlib)
哈希算法
1、 注意:hashlib所有的hash操作起来是一样的,就是你学会一个其它的用法都市一样的,只改变名称就可以,但是在Java里就不一样了,每个算法不一样
cmd窗口:md5 = hashlib.md5()
md5
2、 使用步骤:
创建算法对象(md5 sha256),返回一个算法对象
注意:调用MD5的时候一定要给参数,例如:md5 = hashlib.md5(“12345”),这个错误不是其他错误,需要接收字节数据不能是字符串md5 = hashlib.md5(“12345”.encode(“utf-8”))
如果不做盐值混淆,直接调用hexdigest() md5.hexdigest()
哈希算法的特点:结果唯一、不可逆,哈希算法是无法反向解密的,安全性特别强,因为结果唯一,可以使用碰撞破解,先把MD5的值存下来,下一次遇到的话就可以破解了
解密 这个网站可以对MD5密码解密
在数据校验、安全检查的时候一定不要做盐值混淆(淘宝买东西,订单的10000元可以手动改成1元,所以淘宝会对订单的生成做一个数据校验,价格、数量、时间戳(类似一个随机数)等做一个md5)
在注册账号的时候,需要输入密码和账号存储到数据库中,密码可以铭文存储到数据库吗?不可以,运维人员一定可以看的得到所有人的密码和账号,这样就很不安全,使用密码校验的时候使用的密文校验
3、 盐值混淆
Hash容易碰撞破解,一般建议使用盐值混淆
Md5.update(salt)
md5 = hashlib.md5("12345".encode("utf-8"))
md5.uptate("!@@@@&%hhh".encode("utf-8"))
md5.hexdigest()
hmac模块
hmac也是一个哈希加密库,而且用到了对称加密
参数:第一个参数是要加密的字符串,第二个参数是盐值 ,第三个参数是加密算法
hmac.new(“123456”.encode(“utf-8”),“hahhah”.encode("utf-8),md5)
首先会使用对称加密(密钥就是盐值),之后将加密后的数据再做一次hash加密,盐值混淆,所以整个结果十分安全
第八章 IO及对象序列化
什么是IO stream
- 什么是IO流
Input output Stream 的缩写
IO流主要是计算机的输入和输出操作
常见的IO操作,一般说的是内存与磁盘之间的输入输出(侠义)
IO流操作是一种持久化操作,将数据持久化在磁盘上(例如淘宝账号和密码是使用数据库持久化,下一次登录不需要输入密码)
- Python操作IO流
掌握open函数即可
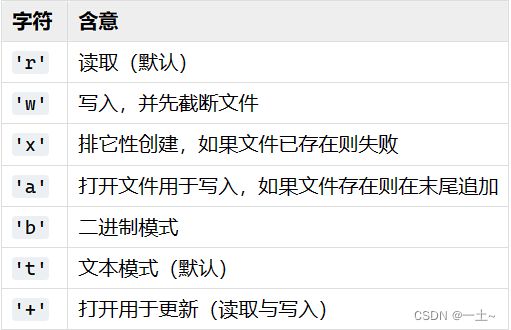
open函数主要作用是打开本地的一个文件
- open函数的解析(help(open))
第一个参数file 代表要打开或者创建文件的名称或者路径
第二个参数表示打开的模式(默认的是字符输入流)
其他参数
Open的简单使用
from os import path
path.abspath(".")
#在当前路径下建立一个 文件(里面写上一句话)
open("xxx.txt")
open("路径//xxx.txt")
f = open("xxx.txt","r")
dir(f)
f.read()
#打印时文件里面的语句
f.read()
#返回的是空,io流打开是一个指针,open函数的第三个参数
F = open(path,”r”)
#一般会把读到的数据保存在变量中
Msg = f.read()
#关闭IO流,操作完成一定要关闭,不然文件删除不了
f.close()
流的分类
-
IO流的分类:
-
根据数据流动(站在内存的角度上来说)的方向
输入流
输出流
例子:把数据保存在硬盘里是输入还是输出流?----输出流
根据数据的类型
字节流(存储图片、视频等)
字符流
字符流
f=open("xxx.txt",mode="w")
f.write("哈哈哈哈哈哈,嘿嘿嘿")
#会返回字符的个数
#这个时候打开xxx.txt 没有这一句话,没有关闭,所以没有保存
#会把写入的数据保存到缓存区,缓存区满了才会写入
#第一种方式 关闭流 关闭的时候会自动调用flus 刷新缓存区
f.close()
#不覆盖的写法
f=open("xxx.txt",mode="a")
f.write("哈哈哈哈哈哈,嘿嘿嘿")
f.close()
字节流
字符流一般不会设计内存不够用的情况,即使500w字也不会有很大的内存,一个字符一个字节,1024个字=1k
help(open)
b ------------ binary mode
视频、图片、音频、可执行文件都是二进制数据,需要使用字节流
mode=“b” --------------表示字节流操作IO流
注意:字节流操作大数据的时候,不建议一次性读取
字节可以操作任何数据,字符只能操作字符数据
def copy_file(src,dest):
f = open(src,"rb")
f2 = open(dest,"wb")
#不推荐
#f2.write(f.read())
while True:
#以M为单位读取
data = f.read(1024*1024)
#字符流读到最后会返回空 字节流b""
if data == b"":
print("数据读取 完成")
break
else:
f2.write(data)
f.close()
f2.close()
if __name__ == '__main__':
copy_file("a.wmv","C:\\Users\wx\\Desktop\\a.wmv")
def copy_file():
src = input("请输入要备份的数据的路径:")
dest = input("请输入要保存的路径:")
f = open(src,"rb")
f2 = open(dest,"wb")
#不推荐
#f2.write(f.read())
while True:
#以M为单位读取
data = f.read(1024*1024)
#字符流读到最后会返回空 字节流b""
if data == b"":
print("数据读取 完成")
break
else:
f2.write(data)
f.close()
f2.close()
if __name__ == '__main__':
copy_file()
运行过程:python xxx.py
请输入要备份的数据的路径:c:\user\wx\desktop\xxx.mp4
请输入保存备份的路径:c:\user\wx\xxx.mp4
问题:python xxx.py
请输入要备份的数据的路径:c:\user\wx\desktop\xxx.mp4
请输入保存备份的路径:c:\user\wx
对象序列化
列表、字典、集合等是对象,对象都是抽象的,是我们想象的虚拟对象,需要将对象持久化,将它保存到磁盘等,所以需要序列化,
对象序列化:将内存中像对象这种抽象的概念转化为真正的字符或者字节的数据
pickle模块
可以将对象转换为字节数据
import pickle
dir(pickle)
dumps ---------------将对象序列化为字节数据 ls = [1,2,3,4,5,6,7] data = pickle.dumps(ls) f = open(“C:\Users\wx\ls.dat”,“wb”) f.write(data) f.close() 怎么读取?
loads ------------- 将字节数据反序列化为对象 f = open(“c:\ls.dat”,“rb”) show = f.read() show pickle.loads(show)
dump ---------------- 注意将对象序列化为字节数据,并且保存到file中 ls = pickle.loads(show) ls pickle.dump(ls,open(“C:\Users\wx\a.txt”,“wb”))
load ---------------- 将一个file对象反序列化为对象 pickle.load(open(“C:\Users\wx\a.txt”,“rb”))
json模块
注意:json这个模块一般用来序列化字典对象,或者转换json数据,并不是只能用来序列化字典,其他也可以
ls = [1,2,3,4,5,6]
pickle.dumps(ls)
s = json.dumps(ls)
f = open("c:\\aa.txt","w")
f.write(s)
f.close()
json.loads(open("c:\aa.txt").read())
ss = json.loads(open("c:\aa.txt").read())
第九章 面向对象
面向对象编程思想
-
面向对象就是在编程的时候尽可能的去模拟现实世界,现实世界中,任何一个操作辑的实现都需要一个实体来完成,实体就是动作的支配者,没有实体,就没有动作的发生
-
思考:上例报名过程中,有哪些动词:提出、提供、缴纳、获得、分配、增加,那么有动词就一定有实现这个动作的实体
-
分析:
-
第一步:分析哪些动作是由哪些实体发出的:
- 学生:提出报名
- 学生:提供相关资料
- 学生:缴费
- 机构:收费
- 教师:分配教室
- 班级:增加学生信息
- 整个过程中,一共有四个实体:学生、机构、教师、班级
-
第二步:定义这些实体,为其增加相应的属性和功能

-
第三步:让实体去执行相应的功能或动作
- 学生:提出报名
- 学生:提供相关资料
- 教师:登记学生信息
- 学生:缴费
- 机构:收费
- 教师:分配教室
- 班级:增加学生信息
-
面向过程向面向对象思想迁移
- 以前写代码:首先考虑实现什么功能,然后调用函数,之后按部就班的执行
- 以后写代码:首先考虑应该由什么样的主体去实现什么样的功能,再把该主体的属性和功能统一的进行封装,最后才去实现各个实体的功能
- 注意:面向对象并不是一种技术,而是一种思想,是一种解决问题的思维方式
- 面向对象的核心思想是:对调用该功能的主体进行封装,在使用的过程中,先得到对应的主体,再使用主体去实现相关的功能
类与对象
对象
- 概念:是一个抽象概念,对象是事物存在的实体,如:一个人
- 每一个现实业务逻辑的一个动作实体就对应着OOP编程中的一个对象
- 对象分为2部分
- 静态部分:属性,客观存在,不可忽视,如:人的性别
- 动态部分:行为,对象执行的动作,如:人跑步
- 对象使用属性(property)保存数据,对象使用方法(method)管理数据
类
Python中,采用类(class)来生产对象,用类来规定对象的属性和方法即要得到对象,必须先有类
为什么要引入类的概念?
- 类本来就是对现实世界的一种模拟,在现实生活中,任何一个实体都有一个类别
- 类就是具有相同或相似属性和动作的一组实体的集合
- 所以,在Python中,对象是指现实中的一个具体的实体,由于实体都有一个类别,所以OOP中的对象也都有一个类
类的定义
class Person():
# 属性
# 方法(函数)
def eat(self):
print('我喜欢吃零食')
def drink(self):
print('我喜欢喝可乐')
类的本质也是一个特殊的对象
- python中一切皆为对象,类是一个特殊的对象即类对象
- 程序运行时,类也会被加载到内存
- 类对象在内存中只有一份,可以创建出多个对象实例
类中的self关键字
- self是Python内置的关键字之一,其指向了类实例对象本身,用于访问类中的属性和方法,在方法调用时会自动传递实际参数self
# 1、定义一个类
class Person():
# 定义一个方法
def speak(self):
print(self)
print('Nice to meet you!')
# 2、类的实例化(生成对象)
p1 = Person()
print(p1) # 注意观察地址
p1.speak()
p2 = Person()
print(p2)
p2.speak()
类的属性
创建类的属性:
-
概念:定义在类中并且在函数体外的属性变量,类属性可以在类的所有实例之间共享值,是公用属性,一般记录这个类的相关特征
-
类属性可以通过类名或实例名访问
类的方法
类中得变量和方法都叫做类成员
创建_ _ init _ _()方法 (初始化方法)
- 在Python中,
__xxx__()的函数叫做魔术方法,指的是具有特殊功能的函数 - 思考:人的姓名、年龄等信息都是与生俱来的属性,可不可以在生产过程中就赋予这些属性呢?
- 类创建后,可以手动创建一个_ _ init _ _()方法,该方法是一个特殊方法,类似java的构造方法,在创建一个对象时默认被调用,不需要手动调用
- _ _ init _ _()方法必须包含一个self参数,且必须是第一个参数,其指向实例本身,没有写self或位置不对,则会报错
- _ _ init _ _()方法开头结尾的双下划线(中间没有空格),是一种特殊约定,旨在区分默认方法和普通方法
类的方法
-
类的成员主要由实例方法和数据成员组成
-
实例方法本质是类中定义的函数
- 方法名:一般使用小写字母开头
- self:必要参数,表示类的实例
- 其它参数:多个参数使用逗号隔开
- 方法体:实现具体的功能
-
实例方法与函数的区别:python函数实现的是某个独立的功能,实例方法是实现类中的一个行为,是类的一部分
-
使用格式:实例化对象.方法名(实际参数)
创建类的静态方法
- 作用:在开发时,如果需要在类中封装一个方法,这个方法
- 既 不需要访问实例属性或者调用实例方法
- 也 不需要访问类属性或者调用类方法
- 一般打印提示、帮助等信息
- 格式:@staticmethod,其用于修饰类中的方法,使其可以再不创建类实例的情况下进行调用,优点是执行效率高,该方法一般被成为静态方法。静态方法不可以引用类中的属性或方法,其参数列表也不需要约定的默认参数self
对象的创建和调用
属性概念:
- Python中,任何一个对象都应该由两部分组成:属性 + 方法
- 属性即是特征,比如:人的姓名、年龄、身高、体重…都是对象的属性
- 对象属性既可以在类外面创建和获取,也能在类里面创建和获取
创建实例属性(默认的对象属性)
- 概念:定义在类方法中的属性,只作用于当前对象
封装
封装是OOP中的第一个关键概念。它指的是将数据(属性)和操作数据的方法(方法)组合成一个单一的单元,称为类。类是对象的蓝图,它定义了对象的结构和行为。
class Car:
def __init__(self, make, model):
self.make = make
self.model = model
def start_engine(self):
print(f"{self.make} {self.model}'s engine started.")
在这个例子中,我们创建了一个Car类,它具有make和model属性以及start_engine方法。属性封装了数据,方法封装了操作。
继承
继承是OOP中的第二个重要概念。它允许您创建一个新的类,从现有的类派生出来,并继承其属性和方法。这使得代码重用和层次结构变得更加容易。
class ElectricCar(Car):
def __init__(self, make, model, battery_capacity):
super().__init__(make, model)
self.battery_capacity = battery_capacity
def start_engine(self):
print(f"{self.make} {self.model}'s electric motor started.")
在这个例子中,我们创建了一个ElectricCar类,它继承了Car类的属性和start_engine方法。我们还可以在子类中重写方法,以改变其行为。这允许我们在不影响原始类的情况下创建特定类型的对象。
多态
多态是OOP的第三个关键概念。它允许不同类的对象对相同的方法做出不同的响应。这使得我们能够编写通用的代码,能够处理多种对象类型。
def drive_vehicle(vehicle):
vehicle.start_engine()
my_car = Car("Toyota", "Camry")
my_electric_car = ElectricCar("Tesla", "Model 3", "75 kWh")
drive_vehicle(my_car) # 输出:Toyota Camry's engine started.
drive_vehicle(my_electric_car) # 输出:Tesla Model 3's electric motor started.
在这个例子中,drive_vehicle函数接受任何具有start_engine方法的车辆对象。这展示了多态的强大之处,因为它允许我们在不知道具体对象类型的情况下调用方法。
总结一下,Python的面向对象编程通过封装、继承和多态提供了强大的工具,使代码更模块化、可重用和易于维护。这些概念是Python中创建复杂应用程序和系统的关键。
第十章 异常处理
异常处理是Python编程中不可或缺的一部分。它允许您在程序出现错误或异常情况时采取适当的措施,以确保程序能够继续执行或以优雅的方式失败。
什么是异常?
在编程中,异常是指程序在执行过程中遇到的问题或错误。这些问题可以是语法错误、逻辑错误或运行时错误。Python将异常视为对象,这些对象包含有关问题的信息,如错误消息、行号和堆栈跟踪。
异常的类型
Python提供了许多内置的异常类型,用于处理各种错误情况。以下是一些常见的异常类型:
SyntaxError:语法错误,通常是由于代码不符合Python语法规则引起的。TypeError:类型错误,发生在操作不兼容的数据类型时。NameError:名称错误,通常是由于尝试使用未定义的变量或函数引起的。ValueError:值错误,发生在使用正确类型的数据,但其值不合法时。ZeroDivisionError:零除错误,发生在试图除以零时。FileNotFoundError:文件未找到错误,通常在尝试打开不存在的文件时引发。Exception:所有异常的基类,可以用于捕获任何异常。
异常处理的语法
在Python中,异常处理使用try和except语句来实现。try块包含可能引发异常的代码,而except块包含在发生异常时要执行的代码。以下是一个简单的异常处理示例:
try:
# 可能引发异常的代码
result = 10 / 0
except ZeroDivisionError:
# 处理特定类型的异常
print("除以零错误发生了!")
在这个示例中,try块中的除法操作可能引发ZeroDivisionError异常。如果异常发生,程序将跳转到except块,然后打印错误消息。
使用else和finally
除了try和except,Python还提供了else和finally块:
else:在try块中没有发生异常时执行的代码块。finally:无论是否发生异常,都会执行的代码块。
try:
result = 10 / 2
except ZeroDivisionError:
print("除以零错误发生了!")
else:
print(f"结果为:{result}")
finally:
print("无论如何都会执行这里的代码")
主动引发异常
除了捕获异常,您还可以使用raise语句主动引发异常。这对于在特定条件下引发自定义异常非常有用。
age = -1
if age < 0:
raise ValueError("年龄不能为负数")
自定义异常
您还可以创建自定义异常类,以便更好地组织和处理程序中的异常情况。自定义异常类通常继承自内置的Exception类。
class MyCustomException(Exception):
def __init__(self, message):
super().__init__(message)
try:
# 某种条件触发自定义异常
if some_condition:
raise MyCustomException("自定义异常发生了!")
except MyCustomException as e:
print(e)
异常处理的最佳实践
- 明确处理异常:始终尽量明确地处理异常,不要忽略它们。
- 只处理必要的异常:不要捕获过于宽泛的异常,只捕获您能够处理的异常类型。
- 记录异常:使用日志记录来记录异常,以便更容易调试和监视应用程序。
- 使用
finally块:如果您有需要在无论异常是否发生时都执行的清理代码,使用finally块。
示例三
- 设计一套带有界面的可以注册登录的程序
# 导入模块
import os
import hashlib
import uuid
# 定义常量:UI
UI = """
*************
1.注册
2.登陆
*************
"""
# 判断 password.txt是否存在,不存在就创建
if not os.path.isfile("F:/password.txt"):
open("F:/password.txt", "w").close()
# 生成盐值
def get_salt():
return str(uuid.uuid4())
# 对密码进行+盐计算
def hash_pass(password, salt):
# 给一个字符串:用户输入的密码+随机盐值
salt_password = password + salt
# 通过md5加密字符串,并返回16进制字符串
hash_password = hashlib.md5(salt_password.encode()).hexdigest()
return hash_password
# 注册账户
def register():
username = input("请输入账户")
password = input("请输入密码")
#通过get_salt函数获取随机盐值
salt = get_salt()
#通过hash_pass函数,传入password和salt
hash_password = hash_pass(password, salt)
with open("F:/password.txt", "a") as f:
f.writelines(f"{username}:{hash_password}:{salt}\n")
print("注册成功")
# 获取密码
def fromPassword():
# 创建一个字典
dc = {}
#检查文件是否存在
if os.path.isfile("F:/password.txt"):
# 打开文件
with open("F:/password.txt", "r") as f:
#遍历将文件内容给line
for line in f:
# 通过:分割字符串,
username, ha_pass, salt = line.strip().split(":")
#返回username键对应的值
dc[username] = (ha_pass, salt)
return dc
# 登录模块
def login():
username = input("请输入账户")
password = input("请输入密码")
# 获取dc返回username键对应的值
dc = fromPassword()
# 如果username在dc里面
if username in dc:
# 将注册时的加盐密码和盐值取出,重新加密
ha_pass, salt = dc[username]
# 对输入的密码加盐加密
input_hashed_password = hash_pass(password, salt)
# 如果两个密码一样则登录成功
if ha_pass == input_hashed_password:
print('登录成功')
#不一样就是密码错误
else:
print('密码错误')
# 如果username没读到则账户不存在
else:
print("账户不存在")
# 主函数
if __name__ == '__main__':
# 程序阻塞
while True:
# 打印UI
print(UI)
select = int(input('请输入序号选择功能:'))
# 如果输入1,执行注册函数
if select == 1:
register()
# 输入2,执行登录函数
elif select == 2:
login()
测试结果:



- 创建一个shape类有两个属性center x,center y表示中心坐标 创建一个Rectangle类继承Shape 新增宽高属性 再创建一个circle类继承Shape新增半径属性 矩形和圆形都有一个方法叫做is in(self,x,y) 判断坐标(x,y)是否在图形范围中,如果 (x,y) 在则返回true反之返回false
- 如何确定x,y在矩形或者圆形范围内
矩形:确定矩形的左上角和右下角坐标。检查给出坐标是否在这两点之间
圆形:使用坐标(x,y)和圆心坐标计算与圆心的距离,若小于等于半径,则坐标在圆内。
import math
# 初始化两个图形
class Shape:
def __init__(self, center_x, center_y):
self.center_x = center_x
self.center_y = center_y
# 矩形模块
class Rectangle(Shape):
def __init__(self, center_x, center_y, width, height):
super().__init__(center_x, center_y)
self.width = width
self.height = height
def rect_in(self, x, y):
half_width = self.width / 2
half_height = self.height / 2
left = self.center_x - half_width
right = self.center_x + half_width
top = self.center_y + half_height
tail = self.center_y - half_height
if left <= x <= right and tail <= y <= top:
return "在矩形内"
else:
return None
# 圆形模块
class Circle(Shape):
def __init__(self, center_x, center_y, r):
super().__init__(center_x, center_y)
self.r = r
def cir_in(self, x, y):
distance = math.sqrt((x - self.center_x) ** 2 + (y - self.center_y) ** 2)
if distance <= self.r:
return "在圆内"
else:
return None
#交互,要求用户输入
rect = input("请输入矩形的中心 x 坐标,中心 y 坐标,宽度和高度(以空格分隔):")
rect_values = rect.split() # 拆分输入值
circle = input("请输入圆形的圆心坐标(x,y)和半径r(以空格分隔)")
circle_values = circle.split()
#检查输入的是否正确
if len(rect_values) != 4 or len(circle_values) != 3:
print("输入格式不正确,请输入正确的值。")
else:
#map用来返回一个迭代器。相当于rect_center_x = float(rect_values),按顺序给每个变量赋值
rect_center_x, rect_center_y, rect_width, rect_height = map(float, rect_values)
circle_center_x, circle_center_y, circle_center_r = map(float, circle_values)
rect = Rectangle(rect_center_x, rect_center_y, rect_width, rect_height)
circle = Circle(circle_center_x, circle_center_y, circle_center_r)
print("矩形已创建。")
print("圆形以创建")
x = float(input("请输入要测试的 x 坐标:"))
y = float(input("请输入要测试的 y 坐标:"))
rect_result = rect.rect_in(x, y)
circle_result = circle.cir_in(x, y)
#根据函数返回判断点在哪
if rect_result and circle_result:
print("点" + rect_result + ",点" + circle_result)
print("点既在矩形内又在圆内")
elif rect_result:
print("点" + rect_result)
elif circle_result:
print("点" + circle_result)
else:
print("不在这两个图形中")