数据库SQL实战(牛客网真题)31~40题
文章目录
- SQL32 将employees表的所有员工的last_name和first_name拼接起来作为Name
-
- 知识点
-
- `concat、concat_ws、group_concat`函数用法
- SQL33 创建一个actor表,包含如下列信息
- SQL34 批量插入数据
- SQL35 批量插入数据,不使用replace操作
-
- 知识点
-
- `insert ignore into`:若没有则插入,若存在则忽略
- ` replace into`:若没有则正常插入,若存在则先删除后插入
- SQL36 创建一个actor_name表
-
- 知识点
-
- MYSQL创建数据表的三种方法:**
- SQL37 对first_name创建唯一索引uniq_idx_firstname
-
- 知识点
-
- 1. 创建索引
-
- 1.1 使用Alter创建索引
- 1.2 使用Create创建索引
- 1.3 两种创建索引方式的区别
- 2 删除索引
- SQL38 针对actor表创建视图actor_name_view
-
- 知识点
- SQL39 针对上面的salaries表emp_no字段创建索引idx_emp_no
-
- 知识点
-
- 关于强制索引的一些解释
- SQL40 在last_update后面新增加一列名字为create_date
SQL32 将employees表的所有员工的last_name和first_name拼接起来作为Name
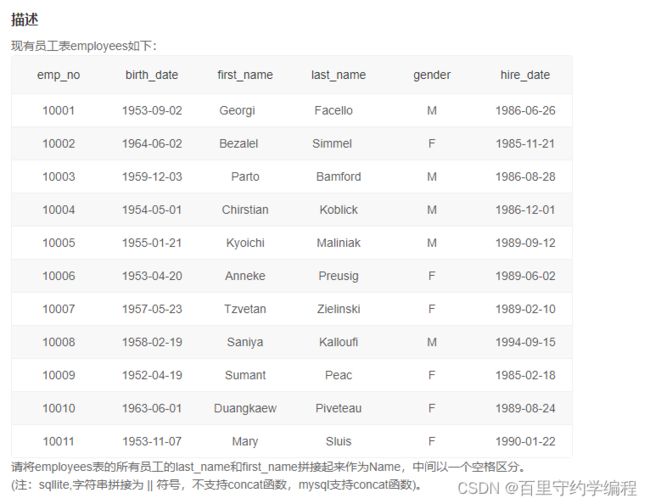

示例1
输入:
drop table if exists `employees` ;
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10003,'1959-12-03','Parto','Bamford','M','1986-08-28');
INSERT INTO employees VALUES(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01');
INSERT INTO employees VALUES(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12');
INSERT INTO employees VALUES(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02');
INSERT INTO employees VALUES(10007,'1957-05-23','Tzvetan','Zielinski','F','1989-02-10');
INSERT INTO employees VALUES(10008,'1958-02-19','Saniya','Kalloufi','M','1994-09-15');
INSERT INTO employees VALUES(10009,'1952-04-19','Sumant','Peac','F','1985-02-18');
INSERT INTO employees VALUES(10010,'1963-06-01','Duangkaew','Piveteau','F','1989-08-24');
INSERT INTO employees VALUES(10011,'1953-11-07','Mary','Sluis','F','1990-01-22');
输出:
Facello Georgi
Simmel Bezalel
Bamford Parto
Koblick Chirstian
Maliniak Kyoichi
Preusig Anneke
Zielinski Tzvetan
Kalloufi Saniya
Peac Sumant
Piveteau Duangkaew
Sluis Mary
知识点
concat、concat_ws、group_concat函数用法
一、concat()函数可以连接一个或者多个字符串
CONCAT(str1,str2,…) 返回结果为连接参数产生的字符串。如有任何一个参数为NULL ,则返回值为 NULL。
select concat('11','22','33'); 112233
二、CONCAT_WS(separator,str1,str2,…)
是CONCAT()的特殊形式。第一个参数是其它参数的分隔符,WS表示的就是With Separator。分隔符的位置放在要连接的两个字符串之间。分隔符可以是一个字符串,也可以是其它参数。
select concat_ws(',','11','22','33'); 11,22,33
三、group_concat()分组拼接函数
group_concat([DISTINCT 要连接的字段] [Order BY ASC/DESC 排序字段] [Separator ‘分隔符’])
对下面的一组数据使用 group_concat(),假设表名为aa
| id | name |
|---|---|
| 1 | 10 |
| 1 | 20 |
| 1 | 20 |
| 2 | 20 |
| 3 | 200 |
| 3 | 500 |
select id,group_concat(name) from aa group by id;
| id | name |
|---|---|
| 1 | 10,20,20 |
| 2 | 20 |
| 3 | 200,500 |
select id,group_concat(name separator ';') from aa group by id;
| id | name |
|---|---|
| 1 | 10;20;20 |
| 2 | 20 |
| 3 | 200;500 |
select id,group_concat(name order by name desc) from aa group by id;
| id | name |
|---|---|
| 1 | 20,20,10 |
| 2 | 20 |
| 3 | 500,200 |
select id,group_concat(distinct name) from aa group by id;
| id | name |
|---|---|
| 1 | 10,20 |
| 2 | 20 |
| 3 | 200,500 |
此时再看题目就很简单了
select
concat_ws(" ", last_name, first_name) as Name
from
employees;

SQL33 创建一个actor表,包含如下列信息

drop table if exists `actor`;
create table actor (
actor_id smallint(5) primary key comment '主键id',
first_name varchar(45) not null comment '名字',
last_name varchar(45) not null comment '姓氏',
last_update date not null comment '日期'
);

SQL34 批量插入数据
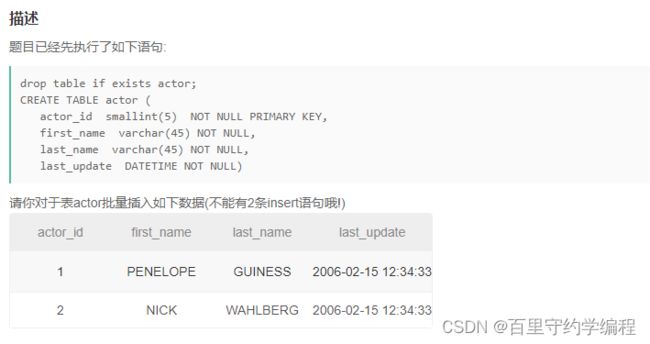
示例1
输入:
drop table if exists actor;
CREATE TABLE actor (
actor_id smallint(5) NOT NULL PRIMARY KEY,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
last_update DATETIME NOT NULL)
输出:
1|PENELOPE|GUINESS|2006-02-15 12:34:33
2|NICK|WAHLBERG|2006-02-15 12:34:33
insert into
actor
values
(1, 'PENELOPE', 'GUINESS', '2006-02-15 12:34:33'),
(2, 'NICK', 'WAHLBERG', '2006-02-15 12:34:33');

SQL35 批量插入数据,不使用replace操作
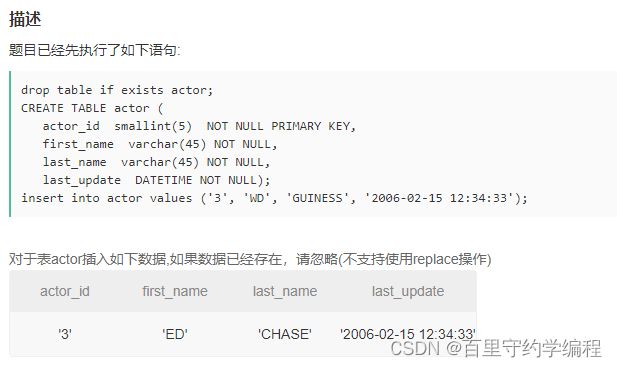
示例1
输入:
drop table if exists actor;
CREATE TABLE actor (
actor_id smallint(5) NOT NULL PRIMARY KEY,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
last_update DATETIME NOT NULL);
insert into actor values ('3', 'WD', 'GUINESS', '2006-02-15 12:34:33');
输出:
3|WD|GUINESS|2006-02-15 12:34:33
知识点
insert ignore into:若没有则插入,若存在则忽略
replace into:若没有则正常插入,若存在则先删除后插入
insert ignore into
actor
values
(3, 'ED', 'CHASE', '2006-02-15 12:34:33');

SQL36 创建一个actor_name表

示例1
输入:
drop table if exists actor;
CREATE TABLE actor (
actor_id smallint(5) NOT NULL PRIMARY KEY,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
last_update datetime NOT NULL);
insert into actor values ('1', 'PENELOPE', 'GUINESS', '2006-02-15 12:34:33'), ('2', 'NICK', 'WAHLBERG', '2006-02-15 12:34:33');
输出:
PENELOPE|GUINESS
NICK|WAHLBERG
知识点
MYSQL创建数据表的三种方法:**
1. 常规创建
create table if not exists 目标表
2. 复制表
create 目标表 like 来源表
3. 将table1的部分拿来创建table2
create table if not exists actor_name
(
first_name varchar(45) not null,
last_name varchar(45) not null
)
select first_name,last_name
from actor
插入数据时,也可以直接用查询结果插入,题解如下
drop table if exists actor_name;
CREATE TABLE actor_name (
first_name varchar(45) NOT NULL comment '名字',
last_name varchar(45) NOT NULL comment '姓氏'
);
insert into
actor_name
select
first_name,
last_name
from
actor;

SQL37 对first_name创建唯一索引uniq_idx_firstname

知识点
1. 创建索引
1.1 使用Alter创建索引
- 添加主键索引
特点:数据列不允许重复,不能为null,一张表只能有一个主键;Mysql主动将该字段进行排序
ALTER TABLE 表名 ADD Primary key (col);
- 添加唯一索引
特点:索引列是唯一的,可以null;Mysql主动将该字段进行排序
ALTER TABLE 表名 ADD unique <索引名> (col1, col2, ...col3);
- 添加普通索引
特点:添加普通索引, 索引值不唯一,可为null
Alter table 表名 ADD index <索引名> (col1, col2, ...,);
1.2 使用Create创建索引
语法:create index 索引名 on 表名(字段)
- 添加普通索引
create index 索引名 on 表名(col1, col2, ..., )
- 添加唯一索引
create unique index 索引名 on 表名(col1, col2, ..., )
1.3 两种创建索引方式的区别
-
Alter可以省略索引名。如果省略索引名,数据库会默认根据第一个索引列赋予一个名称;Create必须指定索引名称。
-
Create不能用于创建Primary key索引;
-
Alter允许一条语句同时创建多个索引;Create一次只能创建一个索引
ALTER TABLE 表名 ADD Primary key (id), ADD index <索引名> (col1, col2, ...,)
2 删除索引
- 第一种方式
drop index 索引名 on 表名;
- 第二种方式
Alter table 表名 drop index 索引名;
- 第三种方式
Alter table 表名 drop primary key
分析:
- 第三种方式只在删除primary key中使用。因一个表只能存在一个primary key索引,则不需要指定索引名;
- 对于第三种方式,若没有创建primary key索引,但表中具有一个或多个unique索引,则默认删除第一个unique索引;
- 若删除表中的某列,索引会受到影响。对于多列组合的索引,如果删除其中的某一列,则该列会从对应的索引中被删除(删除列,不删除索引);多删除组成索引的所有列,则索引将被删除(不仅删除列,还删除索引)。
题解:
create unique index uniq_idx_firstname on actor(first_name);
create index idx_lastname on actor(last_name);
或者
alter table actor add unique uniq_idx_firstname (first_name),add index idx_lastname (last_name);

SQL38 针对actor表创建视图actor_name_view

示例1
输入:
drop table if exists actor;
CREATE TABLE actor (
actor_id smallint(5) NOT NULL PRIMARY KEY,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
last_update datetime NOT NULL);
insert into actor values ('1', 'PENELOPE', 'GUINESS', '2006-02-15 12:34:33'), ('2', 'NICK', 'WAHLBERG', '2006-02-15 12:34:33');
输出:
['first_name_v', 'last_name_v']
PENELOPE|GUINESS
NICK|WAHLBERG
知识点
创建视图的代码为CREATE VIEW <视图名> AS
create view actor_name_view as
select
first_name as first_name_v,
last_name as last_name_v
from actor;
为视图的列命名也有两种写法:
- 直接在视图名的后面用小括号创建视图中的字段名
create view actor_name_view (first_name_v,last_name_v) as
select
first_name,
last_name
from actor;
- 在select后面对列重命名为视图的字段名
create view actor_name_view as
select
first_name first_name_v,
last_name last_name_v
from
actor;
SQL39 针对上面的salaries表emp_no字段创建索引idx_emp_no

示例1
输入:
drop table if exists salaries;
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
create index idx_emp_no on salaries(emp_no);
INSERT INTO salaries VALUES(10005,78228,'1989-09-12','1990-09-12');
INSERT INTO salaries VALUES(10005,94692,'2001-09-09','9999-01-01');
输出:
10005|78228|1989-09-12|1990-09-12
10005|94692|2001-09-09|9999-01-01
知识点
关于强制索引的一些解释
查询优化器是MySQL数据库服务器中的一个组件,它为SQL语句提供最佳的执行计划; 查询优化器使用可用的统计信息来提出所有候选计划中成本最低的计划;
例如,查询可能会请求价格在10到80之间的产品。如果统计数据显示80%的产品具有这些价格范围,那么它可能会认为全表扫描效率最高。但是,如果统计数据显示很少有产品具有这些价格范围,那么读取索引后跟表访问可能比全表扫描更快,更有效。如果查询优化器忽略索引,您可以使用FORCE INDEX提示来指示它使用索引。
题解:
select
*
from
salaries force index (idx_emp_no)
where
emp_no = 10005;

SQL40 在last_update后面新增加一列名字为create_date
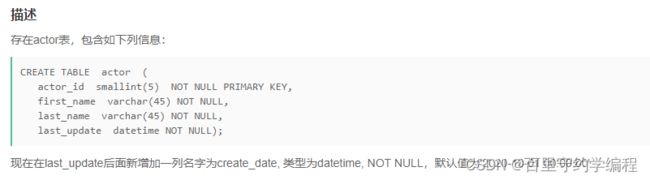
示例1
输入:
drop table if exists actor;
CREATE TABLE actor (
actor_id smallint(5) NOT NULL PRIMARY KEY,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
last_update datetime NOT NULL);
输出:
1
添加字段语法:
ALTER TABLE <表名> ADD COLUMN <新字段名> <数据类型> [约束条件] [FIRST|AFTER 已存在的字段名];
-- first 和 after 是可选的,表示在某个字段之前或者之后,默认是加在最后一个字段之后
题解:
alter table
actor
add
column create_date datetime not null default '2020-10-01 00:00:00' after last_update;
