知识图谱de构建与应用(七):大规模知识图谱预训练
目录
7.1 知识预训练概述
7.1.1 预训练语言模型
7.1.2 知识图谱中的结构化上下文信息
7.1.3 基于知识增强的预训练模型
7.1.4 预训练知识图谱模型与预训练语言模型的区别
7.2 商品知识图谱静态预训练模型
7.2.1 预训练知识图谱查询框架
7.2.2 预训练知识图谱查询模块
7.2.3 预训练知识图谱查询服务
7.2.4 在任务模块中使用查询服务
7.3 商品知识图谱动态预训练模型
7.3.1 上下文模块和整合模块
7.3.2 预训练阶段和微调阶段
7.4 商品知识图谱预训练实践案例
7.4.1 基于知识图谱预训练的商品分类
7.4.2 基于知识图谱预训练的商品对齐
7.4.3 基于知识图谱预训练的商品推荐
7.4.4 基于商品知识预训练的实体识别
7.4.5 基于商品知识预训练的关系抽取与属性补齐
7.4.6 基于商品知识预训练的标题生成
7.5 总结与展望
本章首先介绍预训练知识图谱模型和预训练语言模型的异同点;然后基于商品知识图谱,介绍知识图谱静态预训练模型、知识图谱动态预训练模型的相关研究;最后介绍商品知识图谱的静态和动态预训练技术在业务场景中如何落地,以及相关技术带来的业务效果提升。
7.1 知识预训练概述
知识图谱虽然包含大量有价值的信息,但通常以三元组形式的结构化数据存储,机器无法直接读取和使用。表示学习能将知识图谱中的实体和关系映射到连续空间中用向量表示,并能利用向量的代数运算,很好地建模知识图谱中的结构特征。向量表示被广泛应用在知识图谱相关任务及NLP任务上,且都取得了不错的效果。针对不同的建模任务和目标,相关工作已经提出了不同的知识图谱表示学习方法。随着GPT、BERT、XLNET等预训练语言模型在多项自然语言处理领域任务上刷新了之前的最好效果,预训练受到了各界的广泛关注。预训练在本质上是表示学习的一种,其核心思想是“预训练和微调”方法,具体包括以下步骤:首先利用大量的自然语言数据训练一个语言模型,获取文本中包含的通用知识信息;然后在下游任务微调阶段,针对不同的下游任务,设计相应的目标函数,基于相对较少的监督数据,便可得到不错的效果。
受预训练语言模型的启发,我们将“预训练和微调”的思想应用到了商品知识图谱表示中。商品知识图谱包含亿级的节点信息,同时还包含丰富的结构信息,这对如何高效地建模商品知识图谱带来了挑战。
大规模商品知识图谱预训练包含三个主要方向:
- 商品知识图谱静态预训练;
- 商品知识图谱动态预训练;
- 知识增强的预训练语言模型;
其中,商品知识图谱静态预训练和商品知识图谱动态预训练是对商品知识图谱自身信息的表示学习,而知识增强的预训练语言模型则侧重于非结构化文本场景。
不同的预训练方法有不同的业务场景,细节将在后续章节详细阐述。
知识图谱预训练对于具有亿级节点的阿里巴巴商品知识图谱极为重要,因为它能够避免对庞大的商品知识图谱重复训练,从而能够更高效、快速地为下游任务场景提供服务。
7.1.1 预训练语言模型
随着深度学习的发展,神经网络已广泛用于解决自然语言处理(NLP)任务。深度学习模型能在一系列NLP任务里获得很好的实验效果,但同时模型参数数量也在快速增长,所以需要更大的数据集来防止过拟合。但是由于标注数据成本极高,对于大多数自然语言处理任务来说,构建大规模的有标签数据集是一项巨大的挑战,尤其是对于语法和语义等相关任务。
人类的语言是高度抽象且富含知识的,文本数据只是人类大脑对信息进行处理后的一个载体,所以沉淀的文本数据本身具有大量有价值的信息。互联网上沉淀了大规模的自然文本数据,基于这些海量文本,可以设计自监督训练任务,学习好的表示模型,然后将这些表示模型用于其他任务。基于这种思想,最近几年提出的预训练语言模型(Pre-trained Language Model)在许多自然语言处理任务中都被证明有效,并且能够显著提升相关任务的实验结果。
预训练语言模型可以学习通用的语言表示,捕捉语言中内含的结构知识,特别是针对下游任务标注数据量少的低资源场景,采用“预训练+微调”的模式,能够显著提升效果。预训练语言模型的输入通常是一个文本序列片段,神经编码器会编码输入序列,针对每个输入单元,会编码得到对应的向量表示。区别于传统Word2Vec词向量,预训练得到的向量表示是上下文相关的,因为向量是编码器根据输入动态计算得到的,所以能够捕捉上下文语义信息。相对于传统词向量的静态性,预训练得到的向量表示具有一定的多义词表达能力。至于更高语义级别的文本表示,如句子表示、文档表示等,都是当前前沿研究的内容。
McCann等人利用机器翻译(Machine Translation,MT)任务从注意序列到序列模型预训练了一个深度LSTM编码器,并通过预训练编码器输出的上下文向量(Context Vectors,CoVe)可以提高多种常见自然语言处理任务的性能。Peters等人采用双向语言模型(Bidirectional Language Model,BiLM)预训练的两层LSTM编码器,包括前向语言模型和后向语言模型。而通过预训练的BiLM输出的上下文表示,ELMo模型在学得来自语言模型的向量表示后,在自然语言处理任务领域发挥了巨大的作用。
但是,这些预训练语言模型通常用作特征提取器来生成上下文词向量,当这些词向量被用到下游任务的主要模型中时是固定的,而模型中的其他参数仍需要从头开始训练。Ramachandran等人发现,可以通过无监督的预训练显著改善Seq2Seq模型效果。编码器和解码器的权重都使用两种语言模型的预训练权重初始化,然后使用标记的数据微调。ULMFiT模型尝试将微调用于文本分类(Text Classification,TC)的预训练语言模型,并在六种广泛使用的文本分类数据集上取得了更好的效果。
最近一段时间,深层预训练语言模型在学习通用语言表示形式方面显示出了强大的能力。例如,基于生成式预训练模型的OpenAI GPT和基于Transformer的双向编码器的BERT模型,以及越来越多的自监督预训练语言模型能够从大规模文本语料库中获取更多知识,在大量自然语言处理任务中获得了成功。
以BERT模型为例,预训练语言模型首先在大型数据集上根据一些无监督任务进行训练,包括下一个语句预测任务(Next Sentence Prediction,NSP)和掩码语言模型任务(Masked Language Model),这部分被称为预训练。接着在微调阶段,根据后续下游任务,例如文本分类、词性标注和问答系统等,对基于预训练的语言模型进行微调,使得B E RT模型无须调整结构,只调整输入/输出数据和训练部分的参数,就可以在不同的任务上取得很好的效果。
图7-1(a)展示了BERT模型在预训练阶段的结构,图7-1(b)展示了在多个不同数据集和任务上进行微调的结构示意图。BERT模型具有很好的兼容性、扩展性,并在多种自然语言处理下游任务上达到顶尖的实验效果。
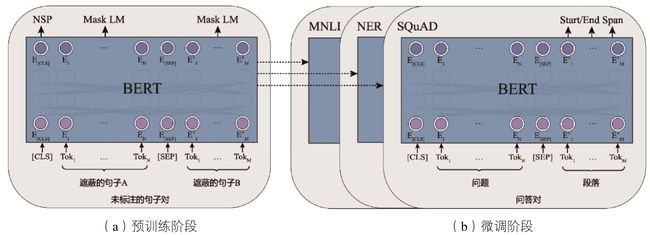 图7-1 BERT模型的预训练和微调过程的模型结构示意图
图7-1 BERT模型的预训练和微调过程的模型结构示意图
预训练语言模型的优点可被总结如下:
(1)对庞大的文本语料库进行预训练,学习通用语言表示形式并协助完成下游任务。
(2)预训练提供了更好的模型初始化,通常可以带来更好的泛化性能,并加快目标任务的收敛速度。
(3)可以将预训练视为一种正则化,以避免对小数据过拟合。
7.1.2 知识图谱中的结构化上下文信息
给定一个知识图谱G={E,R,T},其中E是实体(Entity)的集合,R是关系(Relation)的集合,T是三元组(Triple)的集合。每个三元组(h,r,t)∈T由头实体(Head)、关系(Relation)和尾实体(Tail)构成,于是这些三元组集合可以用符号表示为T={(h,r,t)|h,t∈E,r∈R},其中头实体h和尾实体t都属于集合E,关系r属于集合R。
- 对于某个实体而言,那些包含了该实体若干三元组的集合往往隐含这个实体丰富的结构和语义特征,例如(姚明,性别是,男性)、(姚明,职业,篮球运动员),(中国篮球协会,…的主席,姚明)等三元组能很好地刻画“姚明”这个实体。
- 类似地,对于某个特定的关系,知识图谱中也拥有丰富的包含了该关系的三元组集合,将其称为结构化上下文三元组(Structure Contextual Triples)集合,或者简称为上下文三元组,并用符号C(x)表示,其中x表示某个实体或某种关系。
因此不难看出,在知识图谱中,有两种类型的上下文三元组:
- 实体上下文三元组C(e):
实体上下文三元组C(e)定义为包含实体e的三元组集合,无论实体e是某个三元组中的头实体还是尾实体,只要包含了实体e的三元组都可以归入这个集合。用符号语言表示就是
C(e)={(e,r,t)|(e,r,t)∈T,e,t∈E,r∈R}∪{(h,r,e)|(h,r,e)∈T,e,h∈E,r∈R};
- 关系上下文三元组C(r);
类似地,关系上下文三元组C(r)定义为包含关系r的三元组集合,可以表示为
C (r)={(e1,r,e2)|(e1,r,e2)∈T,e1,e2∈E,r∈R}
为了更直观地展示上下文三元组在知识图谱中的结构,画了一张简单的示意图来描述,如图7-2所示。图中的实心圆圈代表实体,圆圈之间的短线代表关系。虚线框中的蓝色圆圈、橙色圆圈和粉色短线,构成了一个特定三元组,分别代表头实体、尾实体和关系。
- 对于头实体h(蓝色圆圈)来说,它的上下文三元组C(h)就是与蓝色圆圈相连的三元组,即图中用蓝色短线连接起来的两两实体对组成的集合;
- 同理,尾实体t(橙色圆圈)的上下文三元组C(t)即图中用橙色短线连接起来的三元组集合;
- 对于关系r的上下文三元组C(r),图中用平行的、粉色的短线表示同一种关系r,那么用这些粉色短线相连的三元组集合就是所期望的关系上下文三元组C(r)。
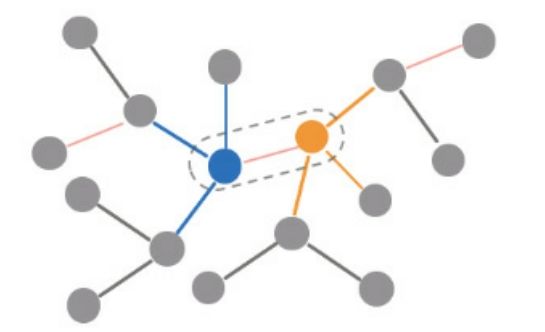 图7-2 知识图谱中的上下文三元组
图7-2 知识图谱中的上下文三元组
7.1.3 基于知识增强的预训练模型
预训练语言模型主要学习通用语言表征,但是缺乏领域特定的知识。
因此可以考虑把外部的知识融入预训练过程中,让模型同时捕获“上下文信息”和“外部的知识”。
早期的工作主要是将知识图谱向量表示和词向量一起训练。从BERT开始,涌现了一些融入外部知识的预训练任务,代表性工作有SentiLR、ERNIE和K-BERT等模型。
1.SentiLR模型
引入单词级别的语言学知识,包括单词的词性标签和单词的情感极性(Sentiment Polarity),然后将掩码语言模型(Masked Language Modeling,MLM)拓展为具有标签感知的语言模型进行预训练。
给定句子层面的标签和进行单词层面的知识的预测,包括词性和情感极性。
基于语言学增强的上下文进行句子层面的情感倾向预测。
论文作者的做法是把句子层面的标签或单词层面的标签转化为向量表示,然后加到序列的指定位置上,类似BERT模型的做法。然后,实验表明该方法在下游的情感分析任务中能够达到不错的效果。图7-3所示为SentiLR模型结构图,首先从SentiWordNet数据集中获取词级情感极性,然后为每个单词添加相应的词性标记。
在预训练过程中,利用基于标签级别的掩码语言模型和下一句预测对模型进行训练,经过预训练的SentiLR模型可以基于情感分析任务进行简单的微调,并在句子层级的情感分类任务上达到了不错的实验效果。
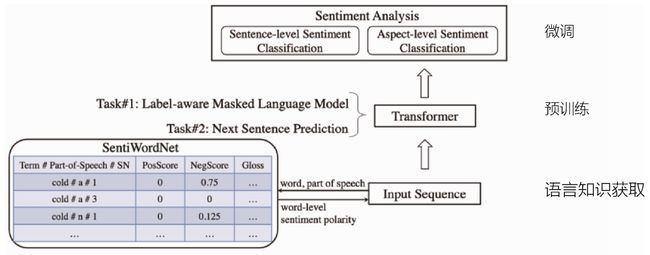 图7-3 SentiLR模型结构图
图7-3 SentiLR模型结构图
2.ERNIE模型
ERNIE模型将知识图谱上预训练得到的向量表示融入文本中相对应的实体上,以提升文本的表达能力。
具体而言,先利用TransE模型在知识图谱上训练学习实体向量,作为外部的知识。然后用Transformer在文本上提取文本向量,将文本向量以及文本上实体对应的知识图谱实体向量进行异构信息融合。
学习的目标包括掩码语言模型中掩盖掉的单词预测;以及掩码文本中的实体,并预测知识图谱上与之对齐的实体。类似的工作还包括KnowBERT模型和KEPLER模型等,都是通过实体向量表示的方式将知识图谱上的结构化信息引入预训练过程中。图7-4(a)所示为ERNIE模型结构,文本输入首先经过Transformer的编码,然后引入实体输入,共同经过聚合器的编码,得到文本和实体各自的输出向量;图7-4(b)所示为聚合器结构,将文本和实体的输入分别经过多层多头的注意力模型,然后进行对齐操作并融合信息。
 图7-4 ERNIE模型结构
图7-4 ERNIE模型结构
3.K-BERT模型
将知识图谱中与句子实体相关的三元组信息作为领域知识注入句子中,形成树形拓展形式的句子。然后可以加载BERT模型的预训练参数,不需要重新预训练。也就是说,作者关注的不是预训练,而是直接将外部的知识图谱信息融入句子中,并借助BERT已经预训练好的参数,微调下游任务。这里的难点在于,异构信息的融合和知识的噪声处理,需要设计合适的网络结构,融合不同向量空间下的向量,以及充分利用并融入的三元组信息。图7-5所示为K-BERT模型,对Tim Cook is currently visiting Beijing now(库克正在访问北京)这句话,模型对Cook这个词语引入知识图谱中的三元组信息(Tim Cook,CEO,Apple),类似地对Beijing这个词语引入(Beijing,is_a Capital,China)及(Beijing,is_a,City)等三元组,可以进一步丰富语义的信息。
 图7-5 K-BERT模型
图7-5 K-BERT模型
4.KnowBERT模型
如图7-6所示为KnowBERT模型,模型通过显示地建模指称检测(Mention Detection)、实体链接(Entity Linking),把实体信息以向量表示的形式通过注意力机制融入文本表示中,从而引入图谱知识。
具体地,模型结构图中的模块1、2在于生成指称表示,模块3为不同指称表示之间的自注意力操作,意在建模指称之间的关系。给定一个指称通常会对应多个候选实体,模块4对不同的候选实体进行加权,得到一个统一的表示。模块5把模块3的指称表示和模块4加权的实体表示相加,并送入模块6进行自注意力操作。这样模块7得到的便是融入了实体信息的文本向量表示。基于文本向量表示输出,可以做不同下游任务的应用。
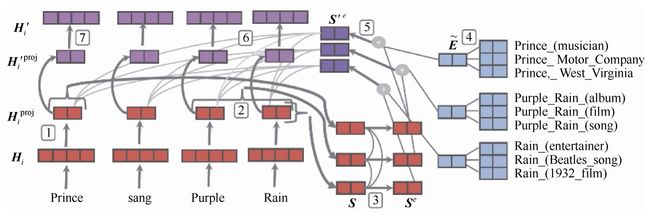 图7-6 KnowBERT模型
图7-6 KnowBERT模型
7.1.4 预训练知识图谱模型与预训练语言模型的区别
预训练语言模型与预训练知识图谱模型(Pre-traind Knowledge Graph Model,PKGM)的主要区别有以下三点。
(1)训练数据类型不同。预训练语言模型的输入数据是上下文单词序列,作为提取单词和句子中的语义特征的重要信息,而预训练知识图谱模型的输入数据是结构化的图网络,并以两两实体之间的关系作为桥梁。
(2)模型的输入不同。预训练语言模型的输入数据一般是单独的句子或者两个句子合并拼接成的单词序列,而预训练知识图谱模型的输入数据是上下文三元组序列。
(3)模型的训练目标不同。
- 预训练语言模型的训练目标是提取文本的词义特征和句子的语义特征,用于单词层面或者句子层面任务的判断,即使是知识增强型的预训练语言模型,仍然着眼于这些任务,只是增加了知识信息来更好地提升试验结果;
- 预训练知识图谱模型的训练目标主要是提升有关在知识图谱下游任务的实验结果,例如实体对齐、三元组分类等方面,不会纯粹地考虑文本和句子层面的任务,可能会引入文本信号,但重点还是放在提升知识的特征和有关知识图谱实验和任务的有效性上。
7.2 商品知识图谱静态预训练模型
利用知识图谱中的结构化上下文信息预训练,为下游任务提供知识信息,形成知识增强的任务,从而更好地提升效果。
具体来说,知识图谱静态预训练模型的静态体现在为下游任务提供预训练好的知识图谱向量表示,通过实体或者关系的id,能够直接查询获取到其对应的向量表示,在下游任务中运用和参与计算,而无须将下游任务的数据输入模型中,来获取对应的向量。
将预先训练好的商品知识图谱模型作为知识增强任务的知识提供者,既能避免烦琐的数据选择和模型设计,又能克服商品知识图谱的不完整性。类似于预训练语言模型在一个连续的向量空间中对每个词进行编码生成向量表示,能为多种不同的下游任务提供帮助。
预训练知识图谱模型的目的是在连续向量空间中提供服务,使下游任务通过向量表示计算得到必要的事实知识,而不需要访问知识图谱中的三元组。
7.2.1 预训练知识图谱查询框架
预训练知识图谱模型有两种常见的查询(Query)方式:三元组查询和关系查询。
三元组查询(Triple Query)是在给定头实体h、关系r的条件下,查询预测缺失的尾实体,于是该查询任务可以简写为Qtriple(h,r)。具体地,查询任务体用SPARQL可以表示为

关系查询(Relation Query)用于查询一个项目是否具有给定的关系或属性。
关系查询任务是针对给定的某一实体,查询预测与该实体相连的关系。该查询任务体用SPARQL可以表示为

因此,考虑到商品知识图谱的不完整性问题,预训练知识图谱模型应该能够具有以下功能:
● 对于某一实体,显示该实体是否存在与之相连的某个指定关系。
● 对于某一头实体,显示该给定头实体的尾实体是什么。
● 为给定的头实体和关系(如果存在)预测缺失的尾实体。
经过预训练,三元组查询模块和关系查询模块可以为任意给定的目标实体提供知识服务向量。
更具体地说:
- 一方面,关系查询模块为目标实体提供包含不同关系存在信息的服务向量,如果目标实体具有或应该具有关系,则服务向量将趋于零向量;
- 另一方面,三元组查询模块为目标实体提供包含不同关系的尾部实体信息的服务向量。
预训练知识图谱模型通过向量空间计算为其他任务提供项目知识服务。
在预训练阶段,首先会在十亿规模的商品知识图谱上对模型进行预训练,使预训练模型具备为三元组查询和关系查询提供知识信息的能力。
在服务(Servicing)阶段,对于需要三元组知识的任务,预训练知识图谱模型提供包含三元组信息的向量表示,然后将其应用于基于向量表示的知识增强任务模型中。
7.2.2 预训练知识图谱查询模块
基于关系查询和三元组查询方式,虽然可以构建对应的模块和评分函数用于模型预训练,模拟连续向量空间中的三元组访问,学习三元组中包含的各种特征信息,但是很难将它们直接应用在下游任务中,如图7-7所示。
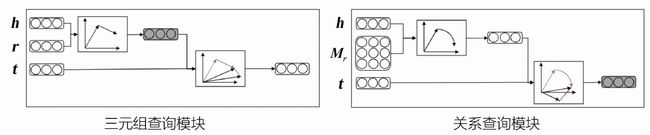
图7-7 知识图谱静态预训练模型
(1)三元组查询模块Mtriple。对于某个三元组查询Qtriple(h,r)需求,三元组查询模块Mtriple会生成一个服务向量,用于表示候选尾部实体。对于某个正确的三元组(h,r,t),认为在向量空间中将头实体h和关系r组合后,可以转化为尾实体t,并用评分函数ftriple(h,r,t)表示。
因为将实体和关系映射到向量空间的表示学习方法被大量的实验证明是有效的,因此在三元组查询模块Mtriple中,采用了表示学习中相对简单而有效的TransE模型。每个实体e∈E和关系r∈R被编码为向量,那么头实体h、关系r和尾实体t对应的向量可以表示为h、r和t。根据转换模型的假设,对于每个正确的三元组(h,r,t),存在h+r≈t的关系,其中这些都是d维的向量,表示为h∈Rd、r∈Rd和t∈Rd。于是它们的评分函数可以表示为
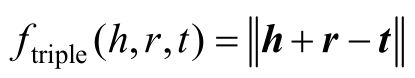
式中,||x||表示向量x的L1范数。对于正确的三元组,要让和向量h+r越接近于t向量越好;相反,对于错误的三元组,和向量h+r要尽可能远离t向量。
(2)关系查询模块Mrelation。设置关系查询模块主要是为了编码某个实体h是否存在与之相连的某种关系r,评分函数可以写为frel(h,r),并且定义存在这种关系用零向量0来表示。如果实体h与关系r相连,函数frel(h,r)接近于零向量0,即frel(h,r)≈0;如果该实体h与关系r不存在相连的情况,那么函数frel(h,r)尽可能远离零向量0。在细节上,对于每一个关系r还定义了转化矩阵Mr,可以将向量h转化为向量r,通过这种方式,可以使得正确的三元组中的Mrh尽可能接近于r,即Mrh-r≈0。于是,评分函数可以表示为
frel(h,r)=Mrh-r
7.2.3 预训练知识图谱查询服务
经过包含了上述两个查询模块的训练后,利用知识图谱预训练模型中已经训练好的模型参数,包括头实体h、关系r和尾实体t的向量、转化矩阵Mr等,可以为特定任务提供两类对应的知识服务。
(1)三元组查询服务Striple。给定头实体h和关系r,三元组查询服务Striple可以给出预测的候选尾实体:
Striple(h, r)=h+r
如果在知识图谱数据集K中的确存在三元组,即(h,r,t)∈K,那么Striple(h,r)会非常接近于尾实体t的向量t;如果数据集中不存在包含h和r的三元组,那么Striple(h,r)会给出一个实体向量表示最有可能的尾实体t。这在本质上就是三元组补全,作为被广泛使用和验证的知识图谱补全任务的具体形式。
(2)关系查询服务Srel。类似于上述的三元组查询服务,关系查询服务Srel能够提供一个向量来表示实体h是否存在包含关系r的三元组:
Srel(h,r)=Mrh-r
在这里会有以下三种情况:一是实体h显式地与关系r相连,即存在同时包含h和r的三元组,那么此时Srel会接近于零向量0;二是实体h隐式地与关系r相连,即不存在直接包含h和r的三元组,但是在真实情况中,实体h能够与关系r相连,此时Srel仍然接近于零向量0;三是实体h真的与关系r不相连,数据集中不包含这样的三元组,真实世界中也不存在,那么Srel应该远离零向量0。
将上述的三元组查询模块和关系查询模块各自的两个阶段的函数汇总并列在表7-1中,可以更清晰地看出两者的差别和联系。
表7-1 知识图谱静态预训练模型的预训练阶段和服务阶段的函数

给定头实体h和关系r,通过知识图谱静态预训练模型的查询服务得到的知识有非常显著的优势:一方面,可以通过向量空间的运算间接地得到对应的尾实体t,这使得查询服务能够独立于数据本身,从而更好地保护数据,尤其是隐私数据;另一方面,通过给定的头实体h和关系r输入对,经过两个查询服务能够分别得到两个向量,而不是未经处理的三元组数据本身,能够以更简单的方式应用在多种特定任务中。除此以外,这两个服务模块还能够通过推理计算得到知识图谱数据集暂未包含的、但真实情况中存在的三元组,能够极大地克服知识图谱不完整性的劣势。
7.2.4 在任务模块中使用查询服务
在知识图谱中,通过某个给定的实体的上下文信息(具体可参看7.1.2节),可以生成来自三元组查询模块和关系查询模块的服务向量序列,分别表示为

和,类似于自然语言处理领域中描述文本或者特征标签的单词向量序列。其中,从某个实体e得到的上下文三元组(h,r,t)中抽取出所有的关系r,组成核心关系集合Re,而k表示核心关系集合Re中的第k个关系。
基于目标实体生成包含知识图谱结构化信息的两种服务向量位于同一个统一的、连续的向量空间中,便于后续多种知识增强任务的应用需求。根据目标实体输入模型的向量个数,可以将下游基于向量的模型分为两类,分别是输入多个向量序列的模型和输入单个向量的模型。
(1)向量序列模型。向量序列模型的输入是一整串多个向量,往往包含较多的信息,例如由某个实体的文本描述或者由标签特征生成的向量序列,可以表示为
。考虑到序列模块能够自动捕捉元素之间的交互信息,类似于BERT模型中使用的双向Transformer模块,所以可以将基于某个实体e得到的和两种服务向量序列,直接拼接到原本输入序列的尾部,能够让原先的文本单词信息与知识图谱信息自动融合,充分交互学习。此时,模型的输入就变为,即先加入三元组查询模块的服务向量,再加入关系查询模块的服务向量序列。图7-8所示为将服务向量添加到向量序列模型尾部的示意图。
(2)单个向量模型。单个向量模型是指只输入一个有关目标实体e的向量的模型。这里的单个向量指的是实体e在潜在向量空间中对应的向量,并将其表示为Ee,如图7-8的左侧部分所示。
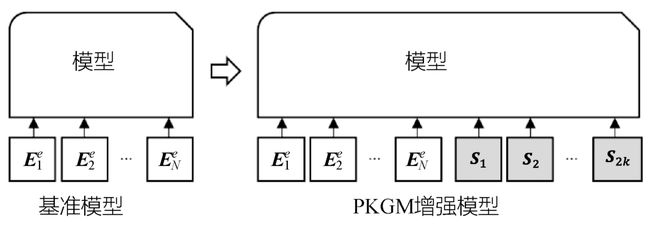
图7-8 将服务向量添加到向量序列模型尾部的示意图
考虑到整个原始模型的输入只有一个向量,需要在模型原始的输入向量和融合了知识的服务向量之间取一个平衡,因此在这里将

和融合为一个向量。具体来说,需要将基于相同关系但来源于不同模块的两个向量和一起考虑,在这里直接将它们拼接生成新的向量,如下所示:
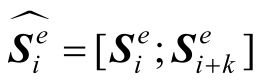
式中,i是1~k的一个整数,即i∈[1,k];[x;y]表示向量x和向量y拼接形成的服务整合向量。
然后,将生成的向量序列进一步整合,平均池化为单个向量:
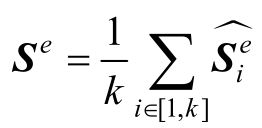
最后,将充分融合了结构化知识信息的向量Se和原始的向量Ee拼接为单个向量。图7-9所示为将服务向量添加到单个向量模型的示意图。
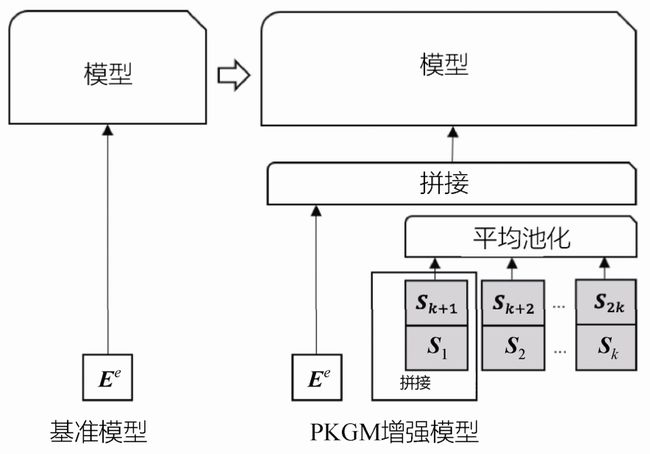
图7-9 将服务向量添加到单个向量模型的示意图
7.3 商品知识图谱动态预训练模型
相对于静态预训练模型仅能为下游任务提供已经包含了结构化信息的向量表(Embedding Table),知识图谱动态预训练模型能够根据下游任务的特征动态调整模型结构和模型参数,根据下游任务对于知识图谱中某些特征的倾向性进行微调和适配,具有更好的兼容性和扩展性。
7.3.1 上下文模块和整合模块
整个知识图谱动态预训练模型主要由上下文模块和整合模块两部分构成,前者获取目标三元组的上下文三元组序列,并将每个上下文三元组的三个向量融合为一个向量,后者主要整合、交互学习上下文三元组向量序列,挖掘潜在的结构性特征,利用得分函数计算三元组分类任务的效果并用于训练。
(1)上下文模块。在上下文模块(Contextual Module,C-Mod)中,首先给定一个目标三元组τ=(h,r,t),可以通过7.1.2节对结构化上下文信息的定义,得到该三元组的上下文三元组集合:
C(h,r,t)={C(h)∪C(r)∪C(t)}
即该目标三元组的头实体h、关系r和尾实体t各自的上下文三元组的并集。
然后,对于每个上下文三元组c,例如目标三元组的第x个上下文三元组(hx,rx,tx)∈C(h,r,t),需要将原本对应的三个向量hx、rx和tx编码成一个向量cx:
cx=C-Mod(<hx, rx, tx>)
式中,<a,b,c>表示向量a、b和c组成的序列,并且向量满足hx∈Rd、rx∈Rd和tx∈Rd。
对于C-Mod中的具体编码方式,可以有多种选择,比如简单的单层前馈神经网络。在这里选择Transformer对向量序列进行学习和融合编码,而在将上下文三元组向量序列输入Transformer之前,需要在<hx,rx,tx>序列之前加入特殊的标签[TRI],生成得到一个新的序列<[TRI],hx,rx,tx>,该序列对应的向量表示为<k[TRI],hx,rx,tx>,其中k[TRI]∈Rd表示标签[TRI]对应的向量。在Transformer最后一层的标记[TRI]对应位置上的向量为充分交互学习后融合了该三元组所有特征的向量,即向量cx。那么,头实体h、关系r和尾实体t各自的上下文三元组特征向量序列seq可以表示为
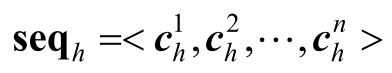
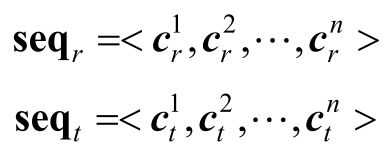
式中,
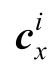
表示头实体h、关系r或者尾实体t中的某个x∈{h,r,t}的第i个上下文三元组特征向量;n表示上下文三元组个数。
(2)整合模块。整合模块(Aggregation Module,A-Mod)将给定的一个目标三元组(h,r,t)的上下文三元组向量序列seq整合编码输出为对应的整合向量a,即
a=A-Mod(seqh,seqr,seqt)
为了增强目标三元组(h,r,t)中每个元素对应的上下文三元组在训练过程中的独立性,给每个三元组特征向量都加上一个段向量。具体地,总共有三种段向量:sh用于表示头实体h对应的上下文三元组的段向量,类似地,关系r和尾实体t对应的段向量为sr和st。将上下文三元组特征向量加上段向量后,生成新的特征向量:
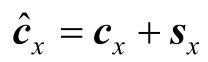
式中,x∈{h,r,t}。三元组特征向量序列也可以表示为
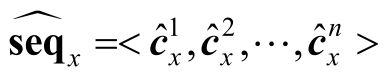
同时,在将h、r、t三者的上下文三元组更新后的特征向量序列拼接在一起输入整个模块之前,还需加入特定的标记来进一步区分三者。类似于上下文模块的[TRI]标签,引入[HEA]、[REL]和[TAI]标签,对应的向量表示为k[HEA]、k[REL]和k[TAI],分别加入头实体h、关系r或者尾实体t的更新后的上下文三元组特征向量序列之前,得到更新后的输入向量序列i:
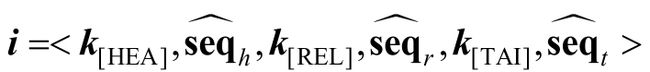
整合模块用另一个不同参数的多层双向Transformer编码学习输入的向量序列i,并在训练结束后,取出最后一层Transformer中[HEA]、[REL]和[TAI]标签对应的向量ah、 ar和at,表示经过充分整合交互学习后,包含了丰富的知识图谱结构化信息的特征向量。
最后,将得到的三个向量拼接并经过一个全连接层,融合为一个统一的整合向量:
aτ=[ah;ar;at]Wagg+bagg
式中,[x;y;z]表示将向量x、向量y和向量z拼接在一起;Wagg∈R3d×d表示该整合模块的权重矩阵;bagg∈Rd表示该整合模块的偏置向量。
(3)评分函数和损失函数。根据上述的上下文模块和整合模块,对于目标三元组τ=(h,r,t),可以将评分函数定义为
sτ=f (h,r,t)=Softmax(aτWcls)
式中,Wcls∈Rd×2是分类权重矩阵,而经过Softmax操作之后得到的sτ∈R2是二维向量,并且满足预测为正确的得分sτ1和预测为错误的得分sτ0之和为1,即
sτ0+sτ1=1
给定构造好的正样本三元组集合D+和负样本三元组集合D-,可以基于评分sτ和标签lτ进行交叉熵计算,得到损失函数L:
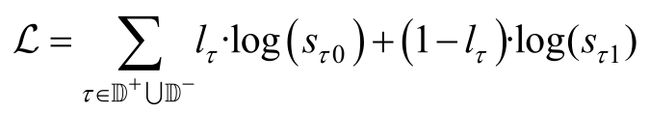
式中,lτ∈{0,1}表示三元组τ是否正确的标签,当三元组τ是正确的,或者说τ是正样本三元组集合D+的其中一个元素τ∈D+时,则标签lτ为1;如果τ是错误的,则标签lτ为0。
7.3.2 预训练阶段和微调阶段
类似于自然语言处理中的预训练模型,知识图谱动态预训练模型也包括预训练和微调两个阶段。预训练阶段会对海量的数据进行无监督学习,而微调阶段相对轻量。
对特定任务和特定数据集,模型结构会有所改变进行适配,并在预训练阶段模型参数的基础上再次训练和微调,使之在特定任务上能更快地获得更好的效果。
(1)预训练阶段。在预训练(Pre-training)阶段,动态预训练模型利用三元组分类任务训练。三元组分类任务是无监督任务,基于数据库中存在的三元组(h,r,t)并将其视为正样本,同时生成替换实体或关系,生成原本数据集中不存在的三元组并作为负样本。训练目标为二分类任务,即判断该三元组是否正确。对于每个输入的三元组,预训练模型都获取其上下文三元组并采样、聚合,通过三元组分类任务训练学习得到其中的结构化信息。预训练阶段输入的是三元组(h,r,t),而用输出的向量判断三元组是正确的(True,T)还是错误的(False,F),如图7-10所示。给定一个目标三元组(h,r,t),找到它的上下文三元组,并通过上下文模块和整合模块将它们输入知识图谱动态预训练模型中,最后得到聚合输出表示向量。
预训练阶段需要用到尽可能大的,甚至全量的知识图谱数据集,这样才能更好地学习到知识图谱中深层次的结构化信息,才真正能够帮助下游任务。例如,BERT模型使用了包含8亿个单词的BooksCorpus数据集和25亿个单词的Wikipedia数据集进行预训练。两个大小不同的模型包括1.1亿个参数的BERTBASE模型和3.4亿个参数的BERTLARGE模型,分别都在16个TPU上训练四天才完成。
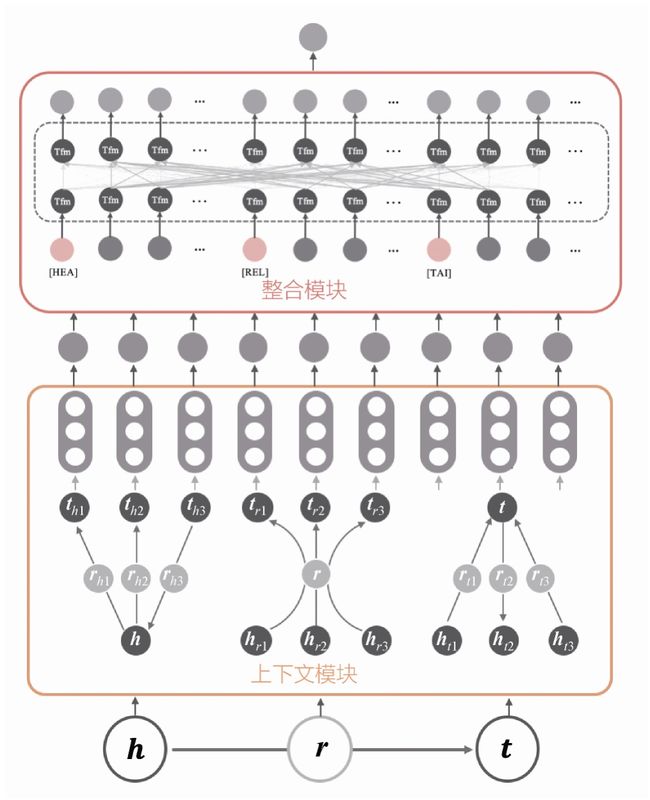 图7-10 模型结构示意图
图7-10 模型结构示意图
对于知识图谱的数据集而言,难以构造横跨多个不同知识图谱数据集的全量数据集,比如FB15K、WN18、YAGO等,甚至基于它们各自最原始的数据集Freebase和WordNet等都难以直接合并成一个数据集,因为每个数据集中的实体和关系都是以不同的文本和组织方式构建的,很难直接建立起不同数据集之间的联系。当然,我们还是找到了合适的方法去间接构造一个足够大而丰富的知识图谱预训练数据集:利用对真实世界描述的WordNet数据集,其中包含了名词、动词、形容词和副词等词性的单个词语,最大限度地反映真实场景和语言习惯,建立起不同知识图谱数据集关联的桥梁。而其他知识图谱数据集中的实体或者关系往往是由多个单词构成的,可以利用类似于短语包含某些单词的关系,构建实体与实体之间的联系,以及潜在类似的关系。而在阿里巴巴电商知识图谱中,可以直接利用海量商品的属性和属性值等三元组,用预训练模型学习商品知识图谱的结构化信息。商品知识图谱足够大,有着10亿级的商品和100亿级的三元组,可以满足预训练的数据需求,并且能够在下游任务中很好地发挥出预训练模型的作用。
(2)微调阶段。在微调(Fine-tuning)阶段中,模型的输入输出结构会根据具体的任务和数据集特性调整,同时将调整后的模型在特定数据集上微调训练,最后得到符合该特定任务需求并有不错效果的模型。
例如,实体对齐任务的目标是在真实世界中找到本质上是同一个事物或者事件,而在输入的知识图谱数据集中有两种或者多种表示的实体,比如中文语义下的实体对(漂亮的,美丽的)、(睡觉,睡眠)和(狗,犬)等,虽然表达的含义相同,却有不同的文字描述。在实体对齐任务上,模型的输入从原来的三元组(Head,Relation,Tail)变为头尾实体对(Head,Tail),即去掉了关系(Relation)这一项元素,剩下前后两个实体。而更进一步地讲,这两个实体就是判断是否具有相同含义的实体对(Entity1,Entity2)。相应地,模型的输出部分也需要替换为描述两个实体是否对齐的训练函数,具体可以参考图7-11(b)。
又如实体类型预测任务,需要找到某个实体所属的类别,而这个类别是存在于知识图谱的另一个实体中,即预测(实体,实体类型)中缺失的实体类型。比如,(老虎,猫科动物)、(中文,语言)和(T细胞,淋巴细胞)等实体类型对。类似于上述的实体对齐任务,实体类型预测任务中的模型输入也变为一个实体对,而输出部分是判断这个实体类型对是否正确的评分函数,如图7-11(c)所示。
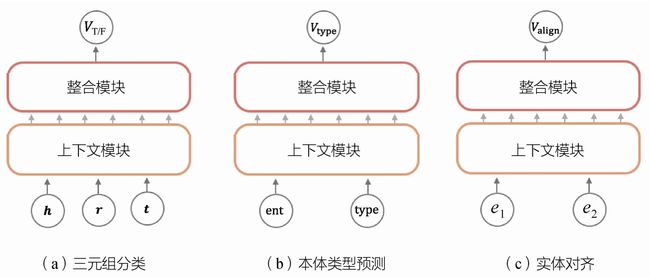
图7-11 微调步骤
7.4 商品知识图谱预训练实践案例
基于电子商务平台上亿级的庞大商品库,电子商务交易得以不断增长。为了更好地支持日常业务,需要将这些海量的商品以一种更优的方式进行描述、存储和计算,并且需要支持融合不同来源的数据,建立实体之间的语义连接,因此采用了知识图谱这种数据构架。
阿里巴巴积累了上千亿规模的商品数据作为商品知识图谱,这些数据来源于淘宝、天猫、阿里巴巴等在内的多个阿里旗下平台,囊括了品牌制造商、消费者、国家机构、物流提供商等多方利益相关者的数据。从知识产权保护或购物体验的角度来看,商品信息的标准化和内外部数据的深度关联挖掘,对电子商务业务至关重要。利用自然语言处理、语义推理和深度学习方法的最新进展,通过提供产品的全球概况、假冒产品治理、行业运营的完整产品信息,可以为搜索业务、推荐业务、平台治理、智能问答等开发人工智能相关服务,为消费者提供更好的使用体验。目前,商品知识图谱包含标准产品、标准品牌、标准条码和标准分类四个关键组成部分,集成了公众情感、百科全书、国家行业标准等九大本体论数据集,运用实体识别、实体链接、语义分析等方法构建了大规模的知识图谱。目前,商品知识图谱包含700多亿个三元组和300多万个规则,建立了一个完整而庞大的数据视图,极大地支撑了基于知识的项目服务。例如,商品知识图谱能支持语义搜索、智能问答、商品推荐等各种知识增强任务。
在阿里巴巴电商实际场景中,围绕商品知识图谱展开了一系列的技术研究和应用,其中主要业务场景包括商品分类、同款商品识别、商品推荐、商品标签发现、商品属性预测等。为了在不同的任务中使用知识图谱信息,应用知识图谱预训练(Pre-trained Knowledge Graph,PKG)技术对知识图谱进行建模,并基于“预训练+微调”的模式,使知识图谱能够方便、有效地服务于各种与商品相关的任务。其中,“方便”特性具体是指在阿里巴巴平台上提供统一的商品知识表示向量,而不再需要烦琐的数据选择,同时对于不同的下游任务,只需要微调模型的一部分来适应这些任务上特定的背景知识,而无须烦琐的模型设计工作。对于“有效”特性,通过实验和工程证明在阿里巴巴业务场景中的多种任务可以通过知识增强的预训练模型获得更好的性能,尤其在数据量比较少的情况下,相较于其他模型有更明显的提升。
7.4.1 基于知识图谱预训练的商品分类
商品分类任务的目标是将商品分类为给定类目列表中的某一类。商品分类在阿里巴巴电商平台中是一项非常常见的任务,不仅包括该商品具体属于哪一大类,还包括商品各种属性上的分类,包括商品适合的生活场景、商品适合的人群等。同时,商品的各类信息总是会随着时间发生变化,比如新增的标签和属性,而用传统方法再次为新的标签或属性进行学习和训练往往过于耗时。
商品分类用符号语言可以描述定义为:给定一个数据集D={P,T,C,R},其中P、T和C分别是商品(Product)集合、标题(Title)集合和类别(Class)集合,而R是一系列商品p以及它们各自对应的标题t与类别c的记录(Record)集合,可以表示为R={(p,t,c)|p∈P,t∈T,c∈C}。每个商品标题是有序的单词序列,即t=[w1,w2,w3,…,wn]。于是,商品分类任务可以转化为训练一个从标题集合T到类别集合C的映射函数:
f:T →C
此时,商品分类任务转化为文本分类任务。在阿里巴巴电商平台上,绝大多数商品都有卖家填写的标题以及选择的商品类别选项,可以用于训练数据。
对于文本分类任务,基于深度学习的模型被证明优于传统的分类方法。给定输入文本,映射函数f首先利用表示学习方法学习它的稠密表示向量,然后使用该表示向量做最终的分类任务。近年来,大规模的预训练语言模型如ELMo模型、GPT模型和BERT模型已经在事实上成为许多自然语言处理任务首选的表示学习方法。在这里,我们采用BERT模型作为项目分类的基础模型。
BERT是一种预训练语言模型,利用多层Transformer的双向编码器,在所有层次上对上下文单词进行联合交叉训练,预训练无标签的文本数据,学习深层双向表示向量。BERT模型基于海量文本进行训练和学习,获得了不错的实验结果,因此BERT已经成为文本编码任务中的常见方法。在这里,使用Google发布、经过预训练的BERT模型和参数进行商品分类任务的实验,而模型架构的细节实现描述可以参考其源代码和参考指南。
图7-12所示为商品分类任务模型,展示了商品分类任务模型的结构示意图。
(1)基准模型。基准模型中输入的是商品标题描述文本序列,输出[CLS]标签对应的向量C,结合全连接层用于分类训练,即
y=σ(WC+b)
式中,

是权重矩阵;b∈Rd是偏置矩阵;d是单词向量的维度,在BERT模型中也被称为隐含层大小;nc是当前任务类别的数量。
(2)知识增强模型在商品分类的应用。在商品类目错放等部分业务场景中,可以直接获取到当前商品在知识图谱中的相关信息。基于7.2节提到的内容,可以用知识图谱预训练模型提供的知识服务增强模型,融入来自两个查询模块各自的k个服务向量。在具体实现业务模型时,考虑到模型的通用性和性能,只引入了商品向量作为服务向量。在原有商品标题文本序列后面先加入[SEP]标签,然后融入对应的商品向量。特别地,实验中发现在原始BERT模型的底层(如输入层)融入商品向量,效果不如在高层(如模型输出层)融入商品向量。引入知识增强的模型相对于基准模型(86%),商品分类任务的准确率有3%的提升。
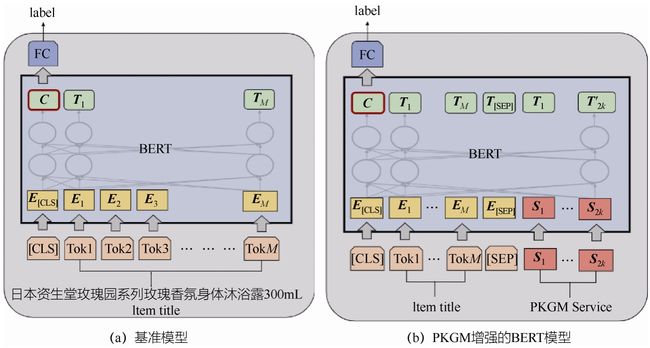
图7-12 商品分类任务模型
应用知识增强模型的前提条件是,可以获取当前商品节点在商品知识图谱中的相关信息。但是在如商品发布等业务场景中,当前商品节点正在被创建,无法获取到知识图谱中的信息。在这种场景下,使用知识增强的语言模型做商品分类任务。具体地,基于商品知识图谱,定制化地改进了KnowBERT模型,使用带有结构信息的节点替换原来的实体向量信息,同时引入知识图谱的Loss作为知识图谱节点的训练信号,图7-13所示为商品知识图谱增强的预训练语言模型。模型通过预训练,能学习到一定的商品知识信息,增强模型在下游任务的泛化能力。
(3)实验与案例分析。我们从阿里巴巴真实场景中抽取出1293个类别以及类别下的商品,生成正样本和负样本为1∶1的数据集,如表7-2所示。为了更好地证明结合文本的知识图谱预训练模型的能力,在数据准备过程中,将每个类别的实例(商品)限制在100个以下,可以展现出在较少的训练样本数据情况下,下游任务的实验效果。为此,还特意生成每个类别不同实例个数的三种数据集——dataset-20、dataset-50和dataset-100,分别表示每个类别只有20个、50个或100个实例个数的数据集。表格中的#Train、#Test和#Dev分别代表由三元组构成的训练集、测试集和验证集。
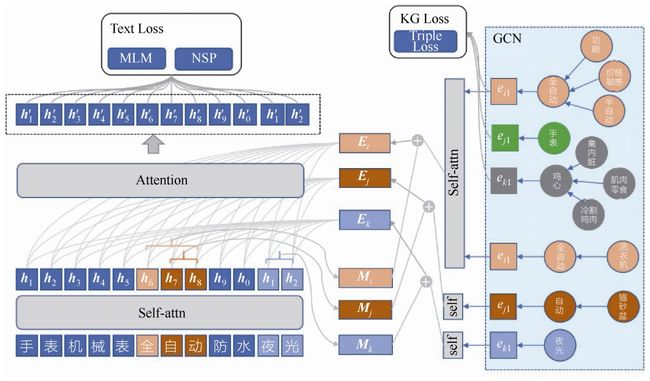
图7-13 商品知识图谱增强的预训练语言模型
表7-2 商品分类任务的数据集

在实验中,采用预训练语言模型BERTBASE在中文语言数据集上的训练模型作为基准模型,其中包含12层Transformer、12个注意力头(Attention Head)和大小为768的向量维度。类似于BERT模型,在输入数据序列之前会加上特殊的分类符[CLS],其在最后一层模型对应位置的向量被用于表示整合了这个输入序列的向量。在这里,将整个序列长度固定为128,包含一个[CLS]分类符和长度为127的标题序列,对于原始标题文本长度不够的补零,超出的则截取最前面的127个字符序列。
对于融合了经过知识图谱预训练得到的服务向量模型BERTPKGM-all,将基准模型BERT输入序列的最后2k个向量替换为k个关系查询模块的服务向量序列和k个三元组查询模块的服务向量序列,然后进行微调阶段的训练。类似地,只替换输入序列中最后k个向量为k个关系查询模块服务向量序列的模型,写为BERTPKGM-T,将T替换为三元组查询模块服务向量的模型,则写为BERTPKGM-R。
在训练批量大小(Batch Size)为32、学习率(Learning Rate)为2×10-5的参数条件下训练了三个轮次(Epoch),其中来自知识图谱预训练的服务向量是固定不变的,而BERT模型中的相关参数会在训练中被调整优化,最终得到如表7-3所示的商品分类任务实验结果。表格中包括商品分类的预测准确率(Accuracy,AC)和前k个预测值的命中率Hit@k指标,其中Hit@k指标表示在所有的测试数据集中预测正确的类别在所有商品类别的预测值序列中排名前k个的百分比,其中k包括1、3和10三个候选值。
表7-3 商品分类任务的结果
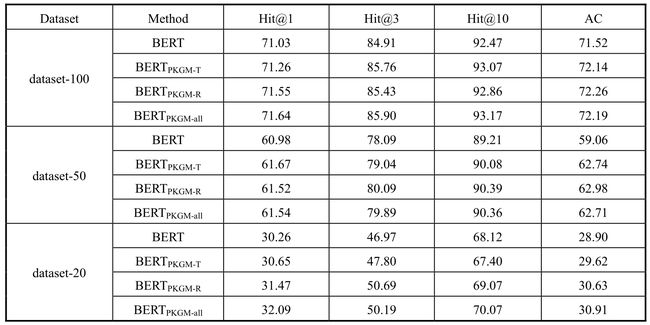
从实验结果中可以看到,在预测准确率和Hit@k指标上,融入了知识服务向量的模型BERTPKGM在三个数据集上都要优于基准模型BERTBASE。具体来说,一方面,同时融入了两种服务向量的BERTPKGM-all模型在Hit@1指标上都取得了最好的效果;另一方面,在Hit@3、Hit@10和预测准确率三个指标上,BERTPKGM-all和BERTPKGM-R两个模型有较好的效果,而且它们中的一个能达到特定条件下的最好实验效果。这也证明了知识图谱预训练模型和提供相应的查询服务向量的有效性,并且其中关系查询模块往往发挥着比三元组查询模块更重要的作用。
当然,在一定程度上,BERTPKGM-R比BERTPKGM-all模型在多数情况下有更好的效果,打破了有更多知识图谱特征向量往往有更好效果的传统认知。我们认为这很可能是因为在商品分类任务上,那些被三元组服务向量序列替换的文本序列比替换它们的三元组服务向量序列更重要,在这些特定指标上,文本序列本身比判断三元组是否成立的信息更有价值。
7.4.2 基于知识图谱预训练的商品对齐
阿里巴巴电商平台上的商品数量数以亿计,给商品管理带来了巨大挑战,其中的一个挑战是商品同款挖掘。商品在商品知识图谱中以实例的形式存在,因此商品同款本质是商品对齐任务,其目标是找到本质上是相同的,但在平台上拥有不同商品id的商品。对于这种同款商品,我们定义为同一款产品。产品指由相同厂家生产的、相同款式、相同属性的,又与具体销售店铺无关的物品,商品定义为不同销售店铺或者商家在平台上设置上传并销售的、可能是相同产品也可以是不同产品的物品,每个商品都有自己唯一的id。例如,不同电商店铺销售的绿色、256GB容量的iPhone X手机有很多,由不同商家在平台上售卖,因此这些商品在电商平台上被存储为不同的商品,但从产品的角度或者销售的商品本身而言,它们是同一款产品。检测两个商品是否为同一款产品的任务对阿里巴巴电商场景的日常业务非常重要。例如,用户想购买一部绿色、256GB容量的iPhone X手机,在搜索框中输入具体的商品需求后,能够显示所有属于该产品的商品,有助于用户方便、深入地比较销售后的价格服务等。更重要的是,产品的数量远小于商品数量,因此从产品的角度来组织商品,有助于减少数据管理和数据挖掘的工作量。
商品对齐用符号语言可以描述定义为:给定一个数据集D={T,R,L},其中T是商品的标题(Title)集合,L是商品的二类别(Class)集合,L={True,False},表示该商品是否正确。R是一系列商品对t1和t2以及这些商品对是否为同款产品的类别l的记录(Record)集合,可以表示为R={(t1,t2,l)|t1∈T,t2∈T,l∈L}。当商品t1和商品t2在本质上为同一款产品时,换句话说这两个商品成功对齐,其类别l为正确,即l=True;当这两个商品不是同款产品时,类别l为错误,即l=False。每个商品标题是有序的单词序列,即t=[w1,w2,w3,…,wn]。于是,商品分类任务可以转化为训练一个从记录集合R到类别集合L的映射函数:
f:R→L
此时,商品对齐任务转化为二分类任务。图7-14所示为商品对齐任务模型,基准模型的输入类似于BERT模型的下游任务,分别输入两个句子的文本,然后做分类任务,具体细节与商品分类任务相似;而在知识增强模型中,在每个句子文本序列后面分别加入[SEP]标签和该商品对应的包含知识信息的服务向量序列。
从商品知识图谱中抽取出女装衬衫、头发饰品和儿童袜类三个类别的三元组集合,作为商品对齐任务的实验数据集。
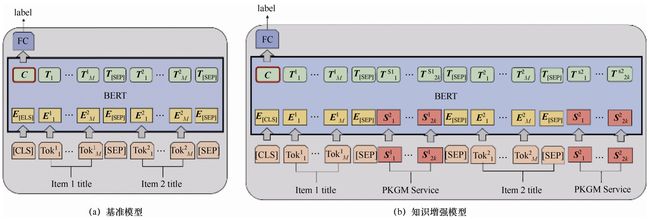
图7-14 商品对齐任务模型
在每个数据集中都有上千个样本,每个样本中包含两个商品对各自的商品标题和判断这两者是否对齐的标签,标签1表示为两个商品对齐而标签0表示两个商品没有对齐。将包含正负样本的所有样本集合按照7∶1.5∶1.5的比例分配成训练集(#Train)、测试集(#Test-C)和验证集(#Dev-C),用于训练和同款商品分类(Classification)指标的测量,但是为了测试前k个预测值的命中率Hit@k指标,需要从中提取出只包含正样本的数据集并排序(Rank),因此得到相应的测试集(#Test-R)和验证集(#Dev-R),具体如表7-4所示。
表7-4 商品对齐任务的数据集

类似于商品分类任务,这里采用BERT作为基准模型,并且有相同的输入格式,只是在输入数据上略有不同。每个输入数据由两个商品的标题文本向量序列组成,在整个序列的第一个位置加入[CLS]标签,在每个标题序列后加入[SEP]标签,并用归一化商品标题长度。表7-5展示了商品对齐任务的Hit@k指标结果,在三个数据集上BERTPKGM-all模型的Hit@3和Hit10指标都优于基准模型BERT,并且在category-2和category-3两个数据集上的所有指标上都有最好的效果,同时展示了知识图谱预训练模型对商品对齐任务的有效性,并且提升了预测准确率。当然,在数据集category-1的Hit@1指标上,基准模型BERT略优于BERTPKGM-all模型,很可能是因为该类别的数据集较大。可以说,足够的标题文本序列对商品对齐任务是有帮助的,而知识图谱预训练模型在少样本数据集上能发挥出更大的作用。
表7-5 商品对齐任务的Hit@k指标的实验结果
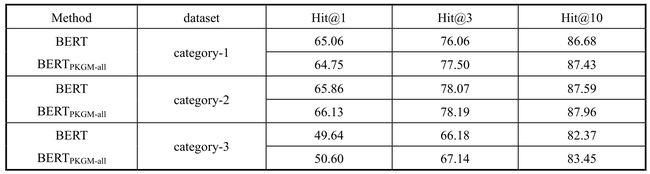
同时,也比较了结合知识图谱预训练模型产生的两种查询服务向量不同组合方式的实体对齐任务的预测准确率,具体如表7-6所示。可以很明显地看出来,BERTPKGM-all模型在三个数据集上都有最好的效果,有效提升了实体对齐任务的预测能力。
表7-6 商品对齐任务的准确率指标结果

7.4.3 基于知识图谱预训练的商品推荐
商品推荐任务的目的是基于用户曾经浏览商品、搜索商品和购买商品等行为作为隐式反馈(Implicit Feedback)数据,向用户正确推荐可能喜欢的商品。与隐式反馈相对的是显式反馈(Explicit Feedback)数据,用户直接反映其对产品的喜好信息,如评分等。用户对商品的各种隐式反馈行为广泛存在于电子商务平台中,能够从侧面反映出用户对商品喜爱偏好,于是可以利用隐式反馈数据作为商品推荐任务的输入数据,并仿照神经协同过滤算法,将商品推荐任务视为排序问题。
商品推荐任务的模型如图7-15所示。
 图7-15 商品推荐任务的模型
图7-15 商品推荐任务的模型
(1)基准模型。使用神经协同过滤算法(Neural Collaborative Filtering,NCF)作为基本模型的一般框架。广义矩阵分解(Generalized Matrix Factorization,GMF)层和多层感知机(Multi-Layer Perceptron,MLP)层能够对用户和商品的交互数据进行建模,其中广义矩阵分解层使用线性核函数模拟潜在的特征交互,而多层感知机层使用非线性核函数从数据中学习交互函数。
神经协同过滤算法框架包括数据输入层、向量表示层、神经网络层和输出层。数据输入层包含描述用户u的特征向量
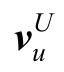
和描述商品i的特征向量,在实际场景中生成的特征向量都是独热(One-Hot)向量。向量表示层用全连接网络将稀疏的输入向量映射为稠密的向量,克服独热向量不利于大规模运算的稀疏性问题,此时用户u和商品i的特征向量分别被转化为向量pu和qi:
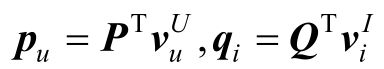
然后将用户向量pu和商品向量qi反馈到神经协同过滤层,将潜在的向量映射为预测得分,最终输出得到最终的得分。因此,神经协同过滤算法模型可以表述为
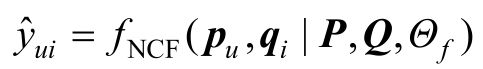
式中,P∈RM×K和Q∈RN×K分别是用户和商品的向量映射矩阵;Θf是函数fNCF的一系列参数。函数fNCF是让两个向量pu和qi充分交互和互相影响的用户—商品交互函数,并能给出给定(用户,商品)对的得分,而矩阵分解模型和多层感知机(Multi-Layer Perceptron,MLP)模型都能够实现用户和商品之间的交互函数。
矩阵分解(Matrix Factorization,MF)模型是最流行的推荐模型,并且在大量文献中被广泛地研究。在该模型中,神经广义矩阵分解(Generalized Matrix Factorization,GMF)层的映射函数可以表示为:
ϕGMF(pu, qi)=pu◦qi
式中,符号◦表示向量的元素级别点积。
在多模态深度学习模型中,使用两条路径对用户和商品进行建模的方法已被广泛使用。因此在多层感知机交互层中,首先对矩阵拼接操作:
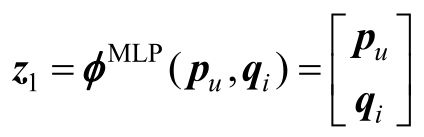
然后在拼接后的向量z上利用标准的多层感知机学习用户和商品潜在特征的交互,而这赋予了模型很大的灵活性和非线性,使之更好地学习pu和qi两者之间的交互信息:
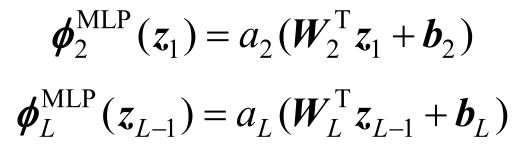
式中,Wx、bx和ax分别第x层感知机中的权重矩阵、偏置矩阵和激活函数。
到目前为止,有两种交互向量,分别是基于广义矩阵分解得到的向量ϕGMF和基于多层感知机得到的向量ϕMLP,将这两者融合如下:
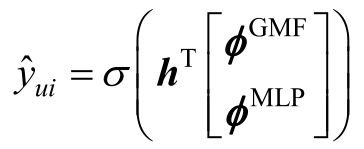
那么神经协同过滤方法中最终的损失函数可以描述为

式中,yui是判断用户u和商品i是否有交互的标签,如果在数据集中存在交互,那么yui=1,否则yui=0;Y是包含正负样本对的训练集,而一开始的原始数据集正样本对通过随机替换(用户,商品)对中的商品来生成负样本,最终将正负样本都囊括到集合Y中。
(2)知识增强模型。因为神经协同过滤算法需要基于商品的向量,因此向其中融入知识增强的服务向量,具体的方法类似于上述的向量序列融合知识信息的方法。具体来说,对于每个(用户,商品)对,知识图谱预训练模型会提供表示为
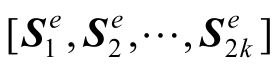
、长度为2k的服务向量序列,并将其对应位置上的三元组查询模块服务向量和关系查询模块服务向量两两融合,并进行平均池化:
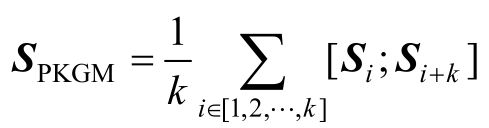
之后,将向量SPKGM融入多层感知机中,于是向量z1便成了三个向量拼接后的结果:
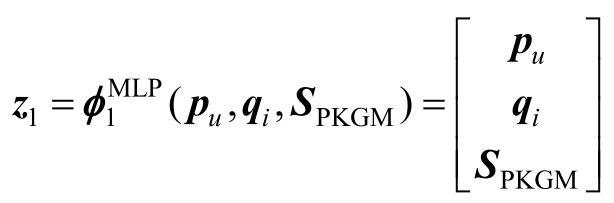
而神经协同过滤算法框架的其他部分不变,具体可以参看图7-13。
(3)实验与案例分析。在淘宝真实记录中采样得到的数据集上进行测试,表7-7展示了商品推荐任务的具体细节,其中包括2万多个用户和3万多个商品,以及44万条用户—商品交互记录。数据集中保证每个用户的交互记录至少有10条,防止过于稀疏。
表7-7 商品推荐任务数据集

在上述数据集上进行了实验,实验中采用了“留—法”评估推荐效果。对每个用户,将其最近一次的交互作为测试集,其余作为训练集。在测试过程中,随机采样100个未观测到的负样本,将这些负样本同真正的测试正样本排序。通过这种方式统计排名前k个命中率(Hit Ratio)的指标HR@k以及归一化累计增益(Normalized Discounted Cumulative Gain)的指标NDCG@k作为评估指标,其中k的取值范围是{1,3,5,10,30}。对于每个测试用户,分别计算这两种评价指标,并求其在所有测试用户上的均值作为最终评估指标。
我们为每个用户随机采样一个正样本交互作为验证集,以求得模型的最优超参数。对于广义矩阵分解层,用户向量和商品向量的维度都为8。在多层感知机层中,用户向量和商品向量的维度设置为32。对于基准模型和知识增强模型,三个隐含层的维度依次为32、16和8。对于知识增强模型来讲,增强的特征被输入后与多层感知机层的用户向量和商品向量拼接,模型用最小化公式中的损失函数训练,并且我们为广义矩阵分解层和多层感知机层中的用户向量和商品向量加了L2正则化惩罚,惩罚系数选择为0.001。学习率设置为0.0001,预测层的维度为16,预测层的输入是由两个8维向量拼接而成的,分别是广义矩阵分解层的输出和多层感知机层的输出。在实验中,采用的负采样比例为4,即为每个正样本采样4个负样本。为了简洁性和有效性,对于基线模型和知识增强模型,均采用了非预训练版本的神经协同过滤模型。
如表7-8所示,有NCFPKGM-T标识的神经协同过滤模型表示仅加入了基于知识图谱预训练三元组查询服务向量的知识增强模型,有NCFPKGM-R标识的神经协同过滤模型表示仅加入了关系查询服务向量特征的知识增强模型,有NCFPKGM-all标识的神经协同过滤模型表示融合了以上两种服务向量的知识增强模型。
表7-8 商品推荐任务的实验结果

通过实验结果可以看出:首先,相对于基准模型,所有的知识增强模型在所有的评价指标上效果均有提升。对于NCFPKGM-T模型来说,它在命中率指标上相比基线模型平均提升了0.37%,而在NDCG指标上相比于基线模型平均提升了0.0023。对于NCFPKGM-R模型来说,它在命中率指标上相比于基线模型平均提升了3.66%,而在NDCG指标上相比于基线模型平均提升了0.0343%。对于NCFPKGM-all模型来说,它在命中率指标上相比于基线模型平均提升了3.47%,而在NDCG指标上相比于基线模型平均提升了0.0324%。提升的结果证明了预训练的知识增强模型能够有效地提供从用户—商品交互不能分析出的额外信息,从而提升了电商推荐等下游任务的效果。
其次,NCFPKGM-R模型的效果要好于NCFPKGM-T模型的效果,说明预训练模型提供的不同特征的侧重点不同。因此在商品推荐任务中,NCFPKGM-R模型提供的特征相比于NCFPKGM-T模型提供的特征要更有用,这很有可能是当描绘用户商品交互时,属性关系往往要比属性实体更有效。
7.4.4 基于商品知识预训练的实体识别
随着导购、推荐等业务场景越来越成熟,新制造、C2M作为新方向,在电商场景中得到越来越多的关注,这些业务的核心点之一是发现商品的趋势和热点。商品的趋势和热点的发现,可以归结为商品热门标签挖掘问题。标签是商品知识图谱中的一个实体节点,因此标签挖掘在本质上可以转化成一个实体识别任务。给定标识符集合,s=<a1,a2,...,aN>,实体识别任务输出一个三元组<Is,Ie,t>,列表中的每个三元组都是序列s中的一个实体,此处Is∈[1,N],Ie∈[1,N],分别为命名实体的起始索引及结束索引,t指具体的预定义好的实体类型。为了提高标签挖掘的丰富性,尽量覆盖市场上所有的趋势热点,从数据和算法两个方面都需要着手。在数据方面,使用了能获取的所有站内外与商品相关的数据;在算法方面,采用了新词发现和命名实体识别两条路径同时发现新标签,这两种方法各有优缺点,可以互为补充。由于本章主要介绍知识预训练,因此仅介绍命名实体标签挖掘算法。
基于命名实体识别的标签挖掘链路主要需要解决两个问题。一是没有标注数据,我们只有已有的商品属性词表,但是无法大量获得标注的语料数据。二是需要提升命名实体识别模型的召回率,尤其是OOV实体发现的能力。因为模型需要发现的是市场上出现的新趋势标签,而不是训练数据中见过的标签。
对于第一点,我们采用的是远程监督的方案,即直接使用商品标准类目属性在文本中匹配构造训练语料。在淘宝内数据,通过类目校验,匹配的准确率较高。在外部舆情数据上,由于无法得知一个外部文本描述的是哪个类目,结合使用产品词表和商品属性进行双重匹配校验。
使用远程监督构造命名实体识别训练语料的问题在于,存在漏标和错标两种问题。漏标问题会严重降低模型的召回率,直观的感受是模型仿佛是在“背词典”,对于新实体的发现能力很差。不存在于词典中的实体,会被标注为O。实际中这种情况较多,严重降低了模型的召回率。遇到互相包含的实体时,误标会导致标注的实体边界错误。例如

解决上述第二个问题的主要方案是局部监督学习或半监督学习。
局部监督学习的思路是通过词典匹配文本标注了B、I等标记后,剩下的词不直接标记为O,而是标记为unkown,即未知。相对应地,模型优化的目标也更改命名实体识别模型的CRF损失函数,从最大化最优的一条标记路径的概率,到最大化所有unkwon位置可以是B、I、O中任意一种的多种路径的概率之和,如图7-16[158]所示。
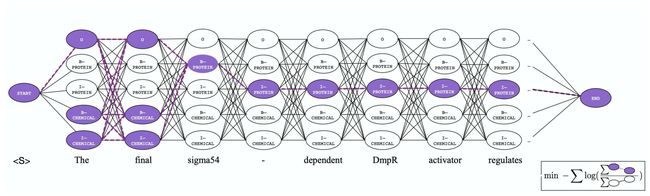 图7-16 局部监督学习方法
图7-16 局部监督学习方法
在通常情况下,使用词典初步匹配文本标注后,B、I的位置占少数,而unknown位置占多数。这会导致局部监督的损失函数分子路径过多,影响模型学习的速度和效果。通常在使用词典初步标注之后,还要想一些办法减少unknown位置的数量,例如使用停用词词表,把一部分unknown变为O,或者使用交叉验证方法把一部分unknown变成BIO。
半监督学习是机器学习中的一类问题,即假定训练集中只有正样本(postive)和未标注样本(unlabelled),而没有负样本(negative),需要学习出良好的分界面。对应远程监督命名实体识别中,被词典标注了BI的位置是正样本,而不能被词典匹配的位置不能确定是O(负样本)还是漏标了的正样本,所以是未标注样本,通过这种训练数据可以学习出命名实体识别模型。这种方式的优点在于,由于避免了把漏标的位置直接当成O的错误惩罚,模型的召回率可以提升。参考论文Distantly Supervised Named Entity Recognition using Positive-Unlabeled Learning,这里使用的是bnPU(bounded non-negative Positive-Unlabelled Learning),即相比BERT-CRF的模型,替换了损失函数,使用Bert-bnPU的模型。
如图7-17所示为部分输出结果。可以看到,相比于CRF Loss,对于同样的文本使用bnPU Loss模型召回的实体数目大大增加(D列是CRF-Loss输出结果,E列是bn-PU-Loss输出结果)。当然,模型发现的新标签会有一些错误案例,需要使用一定的后处理机制,如组合词拆分、边界判断等。目前该模型已经在业务场景中应用。

图7-17 部分输出结果
一般的CRFLoss为L(w)=-∑ilog pw(y(i)|x(i)),局部标注的CRF Loss的分子包含所有的可能路径为

。
7.4.5 基于商品知识预训练的关系抽取与属性补齐
知识图谱主要包含实体和实体之间的边,关系抽取主要用来丰富知识图谱的边。商品知识图谱已经沉淀了商品类目、属性和属性值,以及商品同款和产品等标准化的数据,为了扩展和细化现有的商品知识图谱,让商品知识图谱更丰富,更有空间,我们提出概念图谱,真正进入认知智能。概念图的技术架构主要包含三大技术板块:概念发现、概念关系识别和概念挂载。概念发现主要是发现概念,概念关系识别主要挖掘概念之间的关系,概念挂载主要将挖掘出的概念挂载到商品或者门店上。本节将详细讲解概念关系抽取相关的技术和实践。
关系抽取作为知识图谱的关键技术之一,在很多自然语言处理任务中发挥着重要的作用。相比于复杂的开放式关系抽取,在概念图谱的构建中,关系抽取定义为:已知头尾实体和关系种类,判断头尾实体是否存在关系。当前的关系比较简单,就是概念之间是否存在边,概念主要是产品词、场景和人群,例如连衣裙和约会,戒指和结婚等。形式化描述为F(C,h,r,t)∈ {0,1},基于给定的上下文C,函数F判断给定的概念h和t之间是否存在r关系。其中,1表示存在r关系,0则表示不存在r关系。h和t∈{产品词,场景,人群},r表示是否存在关系。传统的关系三元组为头尾实体和关系,我们基于此也尝试了多元关系抽取,挖掘细分市场(属性值+品类词,如性感连衣裙)和标签之间的关系。概念关系抽取一般分为两步,第一步将包含头尾实体的句子抽取出来,第二步根据句子的特征判断该头尾实体是否存在关系。此类方法大概归结为两类:sequence-based(基于序列)和dependency-based(基于依存)。
基于序列的方法仅仅依赖于句子的词语序列特征和词法语法特征,目前主要基于深度学习和预训练方法,下面分别介绍。
1.基于序列的关系抽取方法:ReBERT
随着预训练的发展,基于BERT的下游任务越来越多,2019年研究者提出将BERT应用于关系抽取的任务中,提出增加标志位来建模头尾实体的类型,如图7-18所示为BERT模型结构。
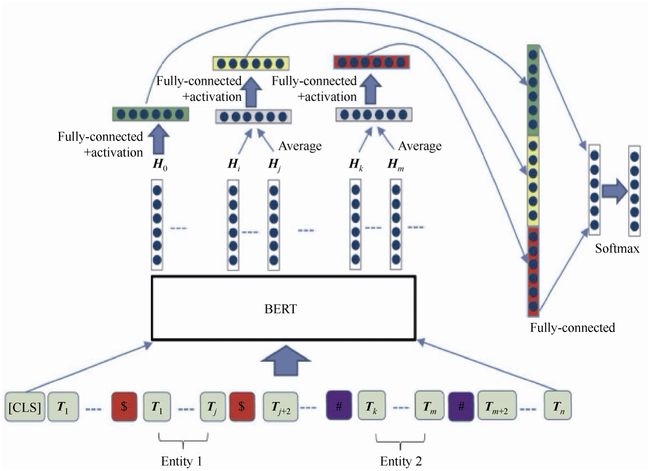
图7-18 BERT模型结构
传统的关系抽取模型仅仅把头尾实体加到模型表示中,ReBERT的创新点主要是两点,第一是引入了最新的预训练模型BERT,第二是不仅仅添加句子Token的序列语义信息,同时在头尾实体添加对应的特殊标记位,通过特殊标记位得到头尾实体对应的表示,最后拼接句子的表示应用到分类任务。
2.基于依存的关系抽取方法
基于依存的关系抽取方法除了利用文本序列信息,同时还会考虑依存关系,下面主要介绍GCN和AGGCN两种方法。
(1)GCN。GCN主要将依存关系建模到模型中,每个词语的向量根据其邻居节点更新,邻接矩阵根据其依存句法树建立,GCN模型结构如图7-19所示。
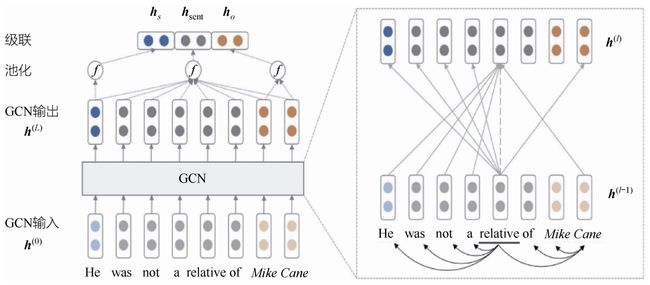
图7-19 GCN模型结构
GCN的输入向量失去了上下文和位置信息,可以连接一个RNN或者BERT进行联合训练,这样可以间接地将位置信息建模到神经网络中;传统的全连接神经网络是基于序列所有的节点更新权重,而GCN是基于和自己相邻的节点更新权重的。具体的更新公式如下,其中Aij为邻接矩阵,hj为对应节点的向量,每一层所有节点会根据其邻居节点向量更新,总的层数为L,最后把对应三元组的向量连接一个多层感知机应用到对应的分类任务中。
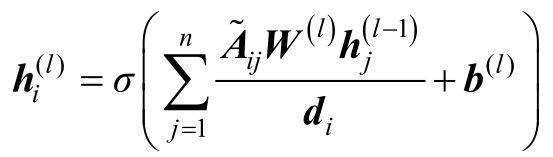
(2)AGGCN。可以看到GCN对于当前节点的权重处理采用二元形式,即邻接的取1,非邻接的取0。后续有学者又提出了AGGCN,该模型的核心是对邻接矩阵权重进行注意力机制计算,将权重学出来,而不是简单地分配0或1,如图7-20所示为AGGCN模型结构。
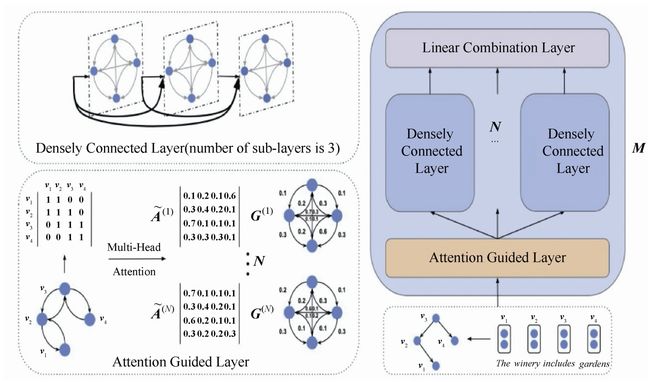
图7-20 AGGCN模型结构
(3)实验与案例分析。我们实现了闭合域的三大关系抽取算法——ReBERT、GCN和AGGCN,同时基于外包标注的数据训练模型,给予主动学习的思想进行后续标注实验,相关实验数据如表7-9所示。
表7-9 相关实验数据

基于此可以抽取到的数据如图7-21所示。
宝宝早教场景需要积木、益智拼板和早教教具等商品。二元关系有一定的局限性,因此在产品词上加上属性值,进一步地增加关系抽取的场景,实现多元关系抽取,如“材质:竹炭 牙刷 适合 去口臭”,如图7-22所示。
同时尝试了基于依存句法和ReVerb的开放关系抽取,抽取更加丰富的三元组数据,如图7-23所示。

图7-21 抽取到的数据
图7-22 多元关系抽取
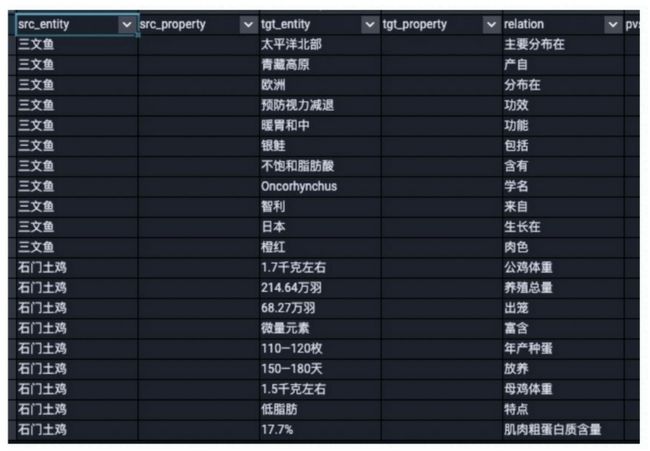
图7-23 抽取更加丰富的三元组数据
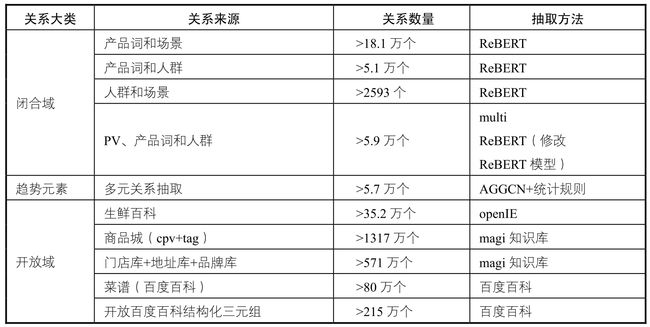
概念知识图谱主要由概念和概念之间的关系组成,概念关系识别是发现已有的概念间是否存在某种关系。本文总结和实践了两类关系抽取方法——sequence-based(基于序列)和dependency-based(基于依存),并分别研究最新的关系抽取方法进行了实验,总结了规模的二元和多元三元组知识,同时也总结了一部分开放式三元组知识,具体数据规模如表7-10所示。
图7-10 开放式三元组知识数据规模
7.4.6 基于商品知识预训练的标题生成
商品标题是卖家和买家在电商平台沟通的重要媒介。在电商情境下,卖家为了吸引买家兴趣,也为了提高商品被搜索引擎检索命中的概率,通常趋于写过于冗长的商品标题。但是商品原始标题往往过长(平均长度为30字左右),在结果页中无法完整显示,只能点击进入商品详情页才能看到商品的完整标题,会影响消费者的体验。如何从过于冗长的标题中抽取关键信息作为短标题展示在手机端,引起用户的点击和浏览,提高转化率,是研究的核心。运用算法的手段构建深度学习模型,并在阿里巴巴的业务场景里尝试并落地了短标题生成的技术,丰富了场景的营销内容,在场景中取得了不错的效果。生成短标题的常用方法有生成方式和抽取方式。业务场景的目标是从原有标题中抽取特定的词组成新的标题,因此采用抽取方式生成短标题。
每一个商品标题是有序的单词序列,即t=[w1,w2,w3,…,wn]。基于阿里巴巴集团内部的分词工具进行分词,当得到分词结果时,工具同时还能返回每个词的类别。对标题进行分词,得到词序列
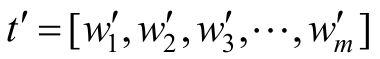
,然后针对t′中的每个词都进行二分类,确定是否保留当前词,如图7-24所示。在标题抽取任务中,有一个硬性要求是短标题里不能出现品牌词,所以在设计模型时,引入了词的类型作为特征。
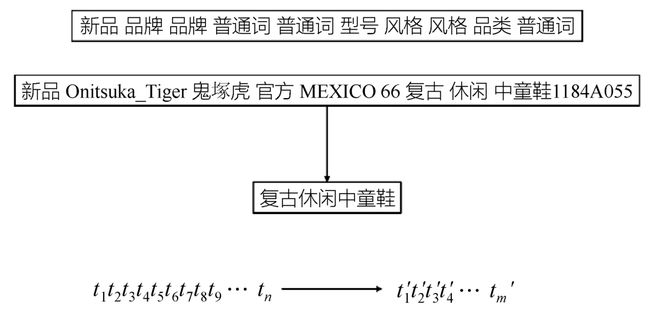 图7-24 标题分词示例
图7-24 标题分词示例
(1)模型结构。如图7-25所示,模型底层是训练的知识增强的预训练语言模型。考虑到短标题中不能包含品牌词,同时在分词工具接口返回时又能获取当前词类别信息。所以在设计模型时,输入层除了Token向量、Segment向量、Position向量输入,还额外引入了一个词类别特征,用于建模当前词的类别信息。词类别也是初始化为向量表示,直接和Token向量、Segment向量、Position向量加在一起,输入Transformer编码器中建模。最后基于顶层输出的向量,对每个词做二分类任务,预测标签为1则保留当前词,否则不保留,最后输出得到目标的短标题。

图7-25 模型结构
(2)实验与案例分析。如何定义一个短标题是否合理,其实是一个主观且相对困难的问题。如图7-26所示为部分输出结果,可以看到模型可以有效过滤掉品牌等不关键的信息,同时生成得到的短标题在语序表达上也相对通顺。目前该模型已经在业务场景中上线。
图7-26 部分输出结果
7.5 总结与展望
本章主要介绍了知识预训练相关内容,并围绕阿里巴巴电商场景的商品知识图谱展开了一系列实践和论证。
参考文献
[1] 袁鼎荣,钟宁,张师超.文本信息处理研究述评[J].计算机科学,2011(2):15-19.
[2] 赵琦,刘建华,刘建华.从ACE会议看信息抽取技术的发展趋势[J].现代图书情报技术,2008(3):18-23.
[3] RABINER L R. A tutorial on hidden Markov models and selected applications in speech recognition[J]. Proceedings of the IEEE, 1989, 77(2): 257-286.
[4] LAFFERTY J, MCCALLUM A, PEREIRA F C N. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[J]. 2001.
[5] MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[C]//Advances in neural information processing systems, 2013: 3111-3119.
[6] HUANG Z, XU W, YU K. Bidirectional LSTM-CRF models for sequence tagging[J]. arXiv preprint arXiv:1508.01991, 2015.
[7] LAMPLE G, BALLESTEROS M, SUBRAMANLAN S, et al. Neural Architectures for Named Entity Recognition[C]//Proceedings of NAACL-HLT, 2016: 260-270.
[8] MA X, HOVY E. End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers), 2016: 1064-1074.
[9] PENNINGTON J, SOCHER R, MANNING C D.Glove: Global vectors for word representation[C]//Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), 2014: 1532-1543.
[10] PETERS M E,NEUMANN M, LYYER M, et al. Deep contextualized word representations[C]//Proceedings of NAACL-HLT, 2018: 2227-2237.
[11] HOWARD J, RUDER S. Universal Language Model Fine-tuning for Text Classification[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers), 2018: 328-339.
[12] DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2019: 4171-4186.
[13] KOLITSAS N, GANEA O E, HOFMANN T. End-to-end neural entity linking[J]. arXiv preprint arXiv:1808.07699, 2018.
[14] RATINOV L, ROTH D, DOWNEY D, et al. Local and global algorithms for disambiguation to wikipedia[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1. Association for Computational Linguistics, 2011: 1375-1384.
[15] TANEVA B, CHENG T, CHAKRABARTI K, et al. Mining acronym expansions and their meanings using query click log[C]//Proceedings of the 22nd international conference on World Wide Web, 2013: 1261-1272.
[16] YAMADA I, SHINDO H, TAKEDA H, et al. Learning distributed representations of texts and entities from knowledge base[J]. Transactions of the Association for Computational Linguistics, 2017, 5: 397-411.
[17] LE P, TITOV I. Boosting entity linking performance by leveraging unlabeled documents[J]. arXiv preprint arXiv:1906.01250, 2019.
[18] LOGESWARAN L, CHANG M W, LEE K, et al. Zero-Shot Entity Linking by Reading Entity Descriptions[J]. arXiv preprint arXiv:1906.07348, 2019.
[19] LE P, TITOV I. Distant Learning for Entity Linking with Automatic Noise Detection[J]. arXiv preprint arXiv:1905.07189, 2019.
[20] CUCERZAN S. Large-scale named entity disambiguation based on Wikipedia data[C]//Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), 2007: 708-716.
[21] CHEN Z, TAMANG S, LEE A, et al. CUNY-BLENDER TAC-KBP2010 Entity Linking and Slot Filling System Description[C]//TAC, 2010.
[22] IKUYA Y, HIROYUK S, HIDEAKI T, et al. Learning distributed representations of texts and entities from knowledge base. TACL, 2017, 5: 397-411.
[23] BROSCHEIT S. Investigating Entity Knowledge in BERT with Simple Neural End-To-End Entity Linking[C]//Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), 2019: 677-685.
[24] GOTTIPATI S, JIANG J. Linking entities to a knowledge base with query expansion. In EMNLP, 2011:804-813.
[25] RAIMAN J R, RAIMAN O M. Deeptype:multilingual entity linking by neural type system evolution[C]//Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
[26] SHEN L, JOSHI A K. Ranking and reranking with perceptron[J]. Machine Learning, 2005, 60(1-3): 73-96.
[27] CAO Z, QIN T, LIU T Y, et al. Learning to rank:from pairwise approach to listwise approach[C]//Proceedings of the 24th international conference on Machine learning, 2007: 129-136.
[28] HOFFART J, SEUFERT S,NGUYEN D B, et al. KORE:keyphrase overlap relatedness for entity disambiguation[C]//Proceedings of the 21st ACM international conference on Information and knowledge management, 2012: 545-554.
[29] FRANCIS-LANDAU M, DURRETTT G, KLEIN D. Capturing semantic similarity for entity linking with convolutional neural networks[J]. arXiv preprint arXiv:1604.00734, 2016.
[30] CAO Y, HUANG L, JI H, et al. Bridge Text and Knowledge by Learning Multi-Prototype Entity Mention Embedding[C]//Meeting of the Association for Computational Linguistics, 2017: 1623-1633.
[31] GANEA O E, HOFMANN T. Deep joint entity disambiguation with local neural attention[J]. arXiv preprint arXiv:1704.04920, 2017.
[32] HE Z, LIU S, LI M, et al. Learning entity representation for entity disambiguation[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2:Short Papers), 2013: 30-34.
[33] LE P, TITOV I. Improving entity linking by modeling latent relations between mentions[J]. arXiv preprint arXiv:1804.10637, 2018.
[34] MULANG I O, SINGH K,VYAS A, et al. Context-aware Entity Linking with Attentive Neural Networks on Wikidata Knowledge Graph[J]. arXiv preprint arXiv:1912.06214, 2019.
[35] DURRETT G, KLEIN D. A joint model for entity analysis: Coreference, typing, and linking[J]. Transactions of the association for computational linguistics, 2014, 2: 477-490.
[36] KOLITSAS N, GANEA O E, HOFMANN T. End-to-end neural entity linking[J]. arXiv preprint arXiv:1808.07699, 2018.
[37] MARTINS P H, MARINHO Z, MARTINS A F T.Joint learning of named entity recognition and entity linking[J]. arXiv preprint arXiv:1907.08243, 2019.
[38] KAMBHATLA N.[Association for Computational Linguistics the ACL 2004-Barcelona, Spain (2004.07.21-2004.07.26)] Proceedings of the ACL 2004 on Interactive poster and demonstration sessions, Combining lexical, syntactic, and semantic features with maximum entropy models for extracting relations[J]. 2004: 22.
[39] ZHOU G, SU J, ZHANG J, et al. Exploring Various Knowledge in Relation Extraction[C]//ACL 2005, 43rd Annual Meeting of the Association for Computational Linguistics, 2005.
[40] ZELENKO D, AONE C, RICHARDELLA A. Kernel Methods for Relation Extraction[J].Journal of Machine Learning Research, 2003, 3(3): 1083-1106.
[41] CULOTTA A, SORENSEN J S. Dependency Tree Kernels for Relation Extraction[C]//Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics, 2004.
[42] BUNESCU R, MOONEY R. A shortest path dependency kernel for relation extraction[C]//Conference on Human Language Technology&Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2005.
[43] ZHANG M, ZHANG J, SU J, et al. A Composite Kernel to Extract Relations between Entities with Both Flat and Structured Features[C]//ACL 2006, 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, 2006.
[44] ZHOU G D, ZHANG M, JI D H, et al. Tree kernel-based relation extraction with context-sensitive structured parse tree information. EMNLP-CoNLL'2007, 2007: 728-736.
[45] ZENG D J, LIU K, LAI S W, et al. Relation classification via convolutional deep neural network. The 25th International Conference on Computational Linguistics: Technical Papers. 2335-2344.
[46] CICERO NOGUEIRA DOS S, XIANG B, ZHOU B W. Classifying relations by ranking with convolutional neural networks. ACL, 2015.
[47] ZHOU P, SHI W, TIAN J, et al. Attention-based bidirectional long short-term memory networks for relation classification. In: The 54th Annual Meeting of the Association for Computational Linguistics, 2016: 207.
[48] ZHENG S, HAO Y, LU D, et al. Joint entity and relation extraction based on a hybrid neural network[J]. Neurocomputing, 2017, 257: 1-8.
[49] MIWA M, BANSAL M. End-to-end Relation Extraction using LSTMs on Sequences and Tree Structures[J]. 2016.
[50] ZHENG S, WANG F, BAO H, et al. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme[J]. 2017.
[51] MIKE M, STEVEN B, RION S, et al. Distant supervision for relation extraction without labeled data[C]//ACL 2009, Proceedings of the 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing of the AFNLP, 2009.
[52] DIETTERICH T G, LATHROP R H, LOZANO-PÉREZ T.Solving the multiple instance problem with axis-parallel rectangles[J]. Artificial intelligence, 1997, 89(1-2): 31-71.
[53] ZENG D, LIU K, CHEN Y, et al. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks[C]//Empirical methods in natural language processing, 2015: 1753-1762.
[54] LIN Y, SHEN S, LIU Z, et al. Neural Relation Extraction with Selective Attention over Instances[C]. Meeting of the association for computational linguistics, 2016: 2124-2133.
[55] FENG J, HUANG M, ZHAO L, et al. Reinforcement Learning for Relation Classification from Noisy Data[C]. National conference on artificial intelligence, 2018: 5779-5786.
[56] BRIN S. Extracting Patterns and relations fromthe World Wide Web[J]. Lecture notes in computerScience, 1998,1590: 172-183.
[57] 漆桂林,高桓,吴天星.知识图谱研究进展[J].情报工程,2017,3(1):004-025.
[58] AGICHTEIN E, GRAVANO L. Snowball: Extractingrelations from large Plain-text collections[C]//acMConference on Digital Libraries. ACM, 2000:85-94.
[59] CARLSON A, BETTERIDGE J, KISIEL B, et al. Toward anarchitecture for never-Ending language learning.[C]//AAAI 2010, 2010: 529-573.
[60] MITCHELL T,FREDKIN E. Never-ending Languagelearning[M]//Never-Ending language learning. Alphascript Publishing, 2014.
[61] BOLLEGALA D T, MATSUO Y,ISHIZUKA M. Measuringthe similarity between implicit semantic relationsfrom the Web[J]. Www Madrid!track semantic/dataWeb, 2009: 651-660.
[62] BOLLEGALA D T, MATSUO Y,ISHIZUKA M. RelationalDuality:Unsupervised Extraction of semantic relations between Entities on the Web[C]//International Conference on World Wide Web, WWW 2010, 2010: 151-160.
[63] BANKO M, CAFARELLA M, SODERLAND S, et al. Open information extraction from the web[C]. International joint conference on artificial intelligence, 2007: 2670-2676.
[64] NIKLAUS C, CETTO M,FREITAS A, et al. A Survey on Open Information Extraction[C]. International conference on computational linguistics, 2018: 3866-3878.
[65] WU F, WELD D S. Open Information Extraction Using Wikipedia[C]. Meeting of the association for computational linguistics, 2010: 118-127.
[66] SCHMITZ M, SODERLAND S, BART R, et al. Open Language Learning for Information Extraction[C]. Empirical methods in natural language processing, 2012: 523-534.
[67] YAHYA M, WHANG S E, GUPTA R, et al. ReNoun: Fact Extraction for Nominal Attributes[C]. empirical methods in natural language processing, 2014: 325-335.
[68] FADER A, SODERLAND S,ETZIONI O, et al. Identifying Relations for Open Information Extraction[C]. empirical methods in natural language processing, 2011: 1535-1545.
[69] ALAN A, ALEXANDER L. Chapter KrakeN:N-ary Facts in Open Infor-mation Extraction, Proceedings of the Joint Workshop on Automatic Knowledge Base Construction and Web-scale Knowledge Extraction (AKBC-WEKEX) Association for Computational Linguistics, 2012: 52-56.
[70] MESQUITA F, SCHMIDEK J, BARBOSA D, et al. Effectiveness and Efficiency of Open Relation Extraction[C]. empirical methods in natural language processing, 2013: 447-457.
[71] STANOVSKY G, DAGAN I. Creating a Large Benchmark for Open Information Extraction[C]. empirical methods in natural language processing, 2016: 2300-2305.
[72] WHITE A S, REISINGER D, SAKAGUCHI K, et al. Universal Decompositional Semantics on Universal Dependencies.[C]. Empirical methods in natural language processing, 2016: 1713-1723.
[73] CORRO L D, GEMULLA R. ClausIE: clause-based open information extraction[J]. the web conference, 2013: 355-366.
[74] ANGELI G, PREMKUMAR M J, MANNING C D, et al. Leveraging Linguistic Structure For Open Domain Information Extraction[C].international joint conference on natural language processing, 2015: 344-354.
[75] MAUSAM M. Open information extraction systems and downstream applications[C].international joint conference on artificial intelligence, 2016: 4074-4077.
[76] SAHA S, PAL H.Bootstrapping for Numerical Open IE[C]. Meeting of the association for computational linguistics, 2017: 317-323.
[77] BAST H, HAUSSMANN E. Open Information Extraction via Contextual Sentence Decomposition[C].ieee international conference semantic computing, 2013: 154-159.
[78] GASHTEOVSKI K, GEMULLA R, Corro L D, et al. MinIE: Minimizing Facts in Open Information Extraction[C]. Empirical methods in natural language processing, 2017: 2620-2630.
[79] DIAN Y, HENG J.Unsupervised Person Slot Filling based on Graph Mining[C]. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016: 44-53.
[80] JR Q. Logic Definitions from Relations[J]. Machine Learning, 1990, 5(3): 239-266.
[81] LUIS A G, CHRISTINA T, KATJA H, et. al. Association Rule Mining Under Incomplte Evidence in Ontological Knowledge Base. Proceedings of the 22nd International Conference on World Wide Web, 2013: 413-422.
[82] LUIS G, CHRISTINA T, KATJA H, et al. Fast Rule Mining in Ontological Knowledge Bases with Amie+. The VLDB Journal, 2015: 1-24.
[83] NI L, TOM M, WILLIAM W C. Random Walk Inference and Learning in A Large Scale Knowledge Base. Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2011: 529-539.
[84] NI L, WILLIAM W C. Relational Retrieval Using a Combination of Path-Constrained Random Walks. Machining Learing, 2010,81(1): 53-67.
[85] ARVIND N, BENJAMIN R, ANDREW M. Compositional Vector Space Models for Knowledge Base Completion. Meeting of the association for computational linguistics, 2015.
[86] MATT G, TOM M. Efficient and Expressive Knowledge Base Completion Using Subgraph Feature Extraction. Meeting of the association for computational linguistics, 2015.
[87] MATT G, PARTHA T, JAYANT K, et al. Incorporating Vector Space Similarity in Random Walk Inference over Knowledge Bases. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014: 397-406.
[88] WANG Q, LIU J, LUO Y F, et al. Knowledge Base Completion via Coupled Path Ranking. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016: 1308-1318.
[89] SAHISNU M, BING L. Context-aware Path Ranking for Knowledge Base Completion. Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, 2017.
[90] YANG B SH, YIH W, HE X D, et al. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. Proceedings of ICLR, 2015.
[91] ZHANG W, PAUDEL B, WANG L, et al. Iteratively learning embeddings and rules for knowledge graph reasoning. In The World Wide Web Conference, 2019b, 2366-2377. ACM.
[92] ZHANG N, DENG S, SUN Z, et al. Long-tail relation extraction via knowledge graph embeddings and graph convolution networks[J]. NAACL, 2019.
[93] ZHANG N, DENG S, SUN Z, et al. Relation Adversarial Network for Low Resource Knowledge Graph Completion[C]//Proceedings of The Web Conference 2020. 2020: 1-12.
[94] GAO T, HAN X, LIU Z, et al. Hybrid attention-based prototypical networks for noisy few-shot relation classification[C]//Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33: 6407-6414.
[95] YU H, ZHANG N, DENG S, et al. Bridging Text and Knowledge with Multi-Prototype Embedding for Few-Shot Relational Triple Extraction[J]. COLING, 2020.
[96] DENG S, ZhANG N, KANG J, et al. Meta-Learning with Dynamic-Memory-Based Prototypical Network for Few-Shot Event Detection[C]//Proceedings of the 13th International Conference on Web Search and Data Mining, 2020: 151-159.
[97] SOARES L B,FITZGERALD N, LING J, et al. Matching the blanks: Distributional similarity for relation learning[J]. ACL, 2019.
[98] YANG S,FENG D, QIAO L, et al. Exploring pre-trained language models for event extraction and generation[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019: 5284-5294.
[99] LU Y, LIN H, HAN X, et al. Distilling Discrimination and Generalization Knowledge for Event Detection via Delta-Representation Learning[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019: 4366-4376.
[100] TONG M, XU B, WANG S, et al. Improving event detection via open-domain trigger knowledge[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020: 5887-5897.
[101] LI J, WANG R, ZHANG N, et al. Logic-guided Semantic Representation Learning for Zero-Shot Relation Classification[J]. COLING, 2020.
[102] DU X, CARDIE C. Event Extraction by Answering (Almost) Natural Questions[J]. EMNLP, 2020.
[103] LIU J, CHEN Y, LIU K, et al. Event Extraction as Machine Reading Comprehension[C]//Proceed-ings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020: 1641-1651.
[104] LI M, ZENG Q, LIN Y, et al. Connecting the dots: Event graph schema induction with path language modeling[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020: 684-695.
[105] WANG L, CAO Z, DE MELO G, et al. Relation Classification via Multi-Level Attention CNNs[C].meeting of the association for computational linguistics, 2016: 1298-1307.
[106] YANG Y, CHEN W, LI Z, et al. Distantly Supervised NER with Partial Annotation Learning and Reinforcement Learning[C].international conference on computational linguistics, 2018: 2159-2169.
[107] YANG Y, ZHANG M, CHEN W, et al. Adversarial Learning for Chinese NER from Crowd Annotations[J]. arXiv: Computation and Language, 2018.
[108] JR Q. Logic Definitions from Relations. Machine Learning, 1990, 5(3): 239-266.
[109] LUIS ANTONID G, CHRISTINA T, KATJA H, et. al. Association Rule Mining Under Incomplte Evidence in Ontological Knowledge Base. Proceedings of the 22nd International Conference on World Wide Web, 2013: 413-422.
[110] LUIS G, CHRISTINA T, KATJA H, et al. Fast Rule Mining in Ontological Knowledge Bases with Amie+. The VLDB Journal, 2015: 1-24.
[111] NI L, TOM M, WILLIAM W C. Random Walk Inference and Learning in A Large Scale Knowledge Base. Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2011: 529-539.
[112] NI L, WILLIAM W C. Relational Retrieval Using a Combination of Path-Constrained Random Walks. Machining Learing, 2010,81(1): 53-67.
[113] ARVIND N, BENJAMIN R, ANDREW M. Compositional Vector Space Models for Knowledge Base Completion. Meeting of the association for computational linguistics, 2015.
[114] MATT G, TOM M. Efficient and Expressive Knowledge Base Completion Using Subgraph Feature Extraction.meeting of the association for computational linguistics, 2015.
[115] MATT G, PARTHA T, JAYANT K, et al. Incorporating Vector Space Similarity in Random Walk Inference over Knowledge Bases. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014: 397-406.
[116] WANG Q, LIU J, LUO Y F, et al. Knowledge Base Completion via Coupled Path Ranking. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016: 1308-1318.
[117] SAHISNU M, BING L. Context-aware Path Ranking for Knowledge Base Completion. Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, 2017.
[118] BORDES A, USUNIER N, GARCIA-DURAN A, et al. Translating embeddings for modeling multi-relational data[C]. In: Proc. of the Advances in Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2013: 2787-2795.
[119] MIKOLOY T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[C]. ICLR Workshop, 2013.
[120] WANG Z, ZHANG J,FENG J, et al. Knowledge graph embedding by translating on hyperplanes[C]. In: Proc. of the 28th AAAI Conf.on Artificial Intelligence. Menlo Park: AAAI, 2014: 1112-1119.
[121] LIN Y, LIU Z, SUN M, et al. Learning entity and relation embeddings for knowledge graph completion. In: Proc. of the 29th AAAI Conf.on Artificial Intelligence. Menlo Park: AAAI, 2015: 2181-2187.
[122] JI G, HE S, XU L, et al. Knowledge graph embedding via dynamic mapping matrix[C]. In: Proc. of the 53rd Annual Meeting of the Association for Computational Linguistics, 2015: 687-696.
[123] JI G, LIU K, HE S, et al. Knowledge graph completion with adaptive sparse transfer matrix[C]. In: Proc. of the 30th AAAI Conf.on Artificial Intelligence. Menlo Park: AAAI, 2016:985-991.
[124] FAN M, ZHOU Q, CHANG E, et al. Transition-Based knowledge graph embedding with relational mapping properties[C]. In: Proc. of the 28th Pacific Asia Conf.on Language, Information and Computation.Stroudsburg: ACL, 2014: 328-337.
[125] JIA Y, WANG Y, LIN H, et al. Locally adaptive translation for knowledge graph embedding[C]. In: Proc. of the 30th AAAI Conf.on Artificial Intelligence. Menlo Park: AAAI, 2016:992-998.
[126] GUO S, WANG Q, WANG B, et al. Semantically smooth knowledge graph embedding[C]. In: Proc. of the 53rd Annual Meeting of the Association for Computational Linguistics, 2015: 84-94.
[127] WANG Z, LI J. Text-enhanced representation learning for knowledge graph[C]. International Joint Conference on Artificial Intelligence. AAAI Press, 2016.
[128] XIAO H, HUANG M, ZHU X.From one point to a manifold:Knowledge graph embedding for precise link prediction[C]. In: Proc. of the 25th Int'l Joint Conf.on Artificial Intelligence. AAAI, 2016: 1315-1321.
[129] HE S, LIU K, JI G, et al. Learning to represent knowledge graphs with gaussian embedding[C]. In: Proc. of the 24th ACM Int'l Conf.on Information and Knowledge Management. New York: ACM Press, 2015: 623-632.
[130] XIAO H, HUANG M, ZHU X. TransG: A generative model for knowledge graph embedding[C]. ACL, 2016.
[131] NICKEL M, TRESP V, KRIEGEL H P. A three-way model for collective learning on multi-relational data[C]. In: Proc. of the 28th Int'l Conf.on Machine Learning. New York: ACM Press, 2011:809-816.
[132] YANG B SH, YIH W, HE X D, et al. Embedding entities and relations for learning and inference in knowledge bases[C]. In International Conference on Learning Representations, 2015.
[133] NICKEL M, ROSASCO L, POGGIO T.Holographic embeddings of knowledge graphs[C]. Thirtieth Aaai conference on artificial intelligence, 2016.
[134] TROUILLON T, WELBL J, RIEDEL S, et al. Complex embeddings for simple link prediction[C]. In: Proc. of the 33rd Int'l Conf.on Machine Learning. New York: ACM Press, 2016: 2071-2080.
[135] YANG B SH, YIH W, HE X D, et al. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. Proceedings of ICLR, 2015.
[136] ZHANG W, PAUDEL B, WANG L, et al. Iteratively learning embeddings and rules for knowledge graph reasoning. In The World Wide Web Conference, 2019: 2366-2377.
[137] BRUNA J, ZAREMBA W, SZLAM A, et al. Spectral networks and locally connected networks on graphs. In ICLR, 2014.
[138] DUVENAUD D K, MACLAURIN D,IPARRAGUIRRE J, et al. Convolutional networks on graphs for learning molecular fingerprints. In NIPS, 2015.
[139] DEFFERRARD M, BRESSON X,VANDERGHEYNST P. Convolutional neural networks on graphs with fast localized spectral filtering. In NIPS, 2016.
[140] KIPF T N, WELLING M.Semi-supervised classification with graph convolutional networks. In ICLR, 2017.
[141] YANG B, YIH W, HE X, et al. Embedding entities and relations for learning and inference in knowledge bases. arXiv preprint arXiv:1412.6575, 2014.
[142] ABU-EL-HAIJA S, KAPOOR A, PEROZZI B, et al. N-gcn: Multi-scale graph convolution for semi-supervised node classi-fication. In MLG KDD Workshop, 2018.
[143] RAJARSHI D, ARVIND N, DAVID B, et al. Chains of reasoning over entities, relations, and text using recurrent neural networks. EACL, 2017.
[144] KIPF W.Semi-Supervised Classification with Graph Convolutional Networks. ICIR, 2017.
[145] DEFFERRARD M, XAVIER B, PIERRE V. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering. NIPS, 2016.
[146] MIKOLOV T, CHEN K, CORRADO G. Efficient estimation of word representations in vector space[J]. 2013: 1301.3781.
[147] BLEI D,NG A, JORDAN M. Latent Dirichlet Allocation[J].Journal of Machine Learning Research, 2003.
[148] YU X, XIANG R, SUN Y Z, et al. Personalized entity recommendation: A heterogeneous information network approach.[C]. International Conference on Web Search and Data Mining, 2014.
[149] ZHAO H, YAO Q M, LI J D, et al. Meta-graph based recommendation fusion over heterogeneous information networks.[C]. Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2017.
[150] WANG Q, MAO Z D, WANG B, et al. Knowledge Graph Embedding: A Survey of Approaches and Applications.[J]. Transactions on Knowledge and Data Engineering, 2017.
[151] BORDES A, USUNIER N, WESTON J. Translating embeddings for modeling multirelational data.[C]. Advances in Neural Information Processing Systems, 2013.
[152] WANG Z, ZHANG J,FENG J, et al. Knowledge graph embedding by translating on hyperplanes[C]. the Association for the Advance of Artificial Intelligence, 2014.
[153] LIN Y, LIU Z, SUN M, et al. Learning entity and relation embeddings for knowledge graph completion[C]. the Association for the Advance of Artificial Intelligence, 2015.
[154] JI G, HE S, XU L, et al. Knowledge graph embedding via dynamic mapping matrix[C]. Proceed-ings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, 2015.
[155] WANG H W, ZHANG F Z, XIE X, et al. DKN: Deep Knowledge-Aware Network for News Recommendation[C]. Proceedings of the 18th World Wide Web Conference, 2018.
[156] WANG H W, ZHANG F Z, WANG J L, et al. RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems[C]. Proceedings of the 27th ACM International Conference on Information and Knowledge Management, 2018.
[157] WANG H W, ZHANG F Z, ZHAO M, et al. Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation[C]. Proceedings of the 19th World Wide Web Conference, 2019.
[158] ZHI S, LIU L Y, ZHANG Y, et al. Partially-Typed NER Datasets Integration: Connecting Practice to Theory, 2020. arXiv:2005.00502v1.