【AI Agent系列】【MetaGPT】总结这段时间学习MetaGPT的一些学习方法和感悟
跟着《MetaGPT智能体开发入门》课程学习了近两周,原本是抱着试试看的心态,没想到自己竟然全程跟了下来。期间踩坑颇多,但也收获颇多,特写个总结回顾一下课程内容和沉淀下自己的收获,同时把我的学习方法记下来,希望后来学习的人能从中获得一点点的灵感或方向。
文章目录
-
- 0. 个人背景
- 1. 我的学习方法
-
- 1.1 先跑通demo
- 1.2 搞清数据流
- 1.3 有选择地看源码
- 2. 从一个坑开始,看智能体运行机制
- 3. 本次课程的收获和感悟
-
- 3.1 收获
- 3.2 感悟
- 4. MetaGPT入门系列文章
0. 个人背景
通过标题序号也可能猜出来,下标从0开始,我是一个程序员,不过是C++程序员。
-
Python:能写hello world,零零碎碎的知识,不系统,可以在代码上缝缝补补,但干不了大事。
-
大模型:刚入门,知道里面的概念(Prompt、Function Calling、Agent等),基本没实操,只会调用OpenAI的一个对话接口(问:OpenAI一共有几个接口?)。
-
爬虫:小白
所以对于本课程,我可能比小白好那么一丢丢,但不多。
1. 我的学习方法
下面说下我的学习方法,这可能不适合所有人,但是希望能对大家有点启发或帮助。
1.1 先跑通demo
教程有示例代码,可以不理解代码的意思,先试着跑通demo。作用有二:
- 一是心里有底,路通了。既然路通了,结果好坏是有很多方法去调试的(断点也好、日志也罢),就算一行一行运行,也终究能调出大差不差的结果,毕竟demo一般也就不超过百行有效代码。
- 二是有了成就感。无论懂不懂,我都能看到结果了,这样才有兴趣去深究。
可能有的同学会问demo不通怎么办?
这就考验你的debug问题的能力和运气了。说实话,我也没有很好的办法,只能一点点去debug、搜索、各种试…看过我系列文章的同学都能看出来,我踩得坑真的不少,基本是一步一坑…但是也一步一坑地走了下来。
但无论如何,想尽各种办法跑通示例demo一定是第一步。
1.2 搞清数据流
以我的经验来讲,快速入门了解某段程序最有效的方法,是抓住一个输出,或输入,去捋数据流。你可以看不懂架构的设计,但是一定得知道数据通路。
在看数据流的过程,你就会自然而然的知道整个过程涉及哪些模块,每个模块的作用、依赖是什么,从而对整个程序有个宏观的认知。
可以看下我学习过程中绘制的各种图,很丑,但能凑合看出一些东西。
- 【AI的未来 - AI Agent系列】【MetaGPT】3. 实现一个订阅智能体,订阅消息并打通微信和邮件
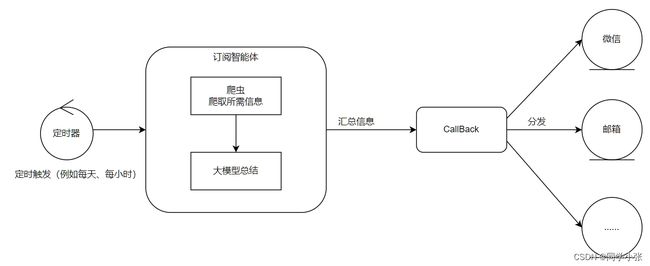
- 【AI的未来 - AI Agent系列】【MetaGPT】4. ActionNode从理论到实战
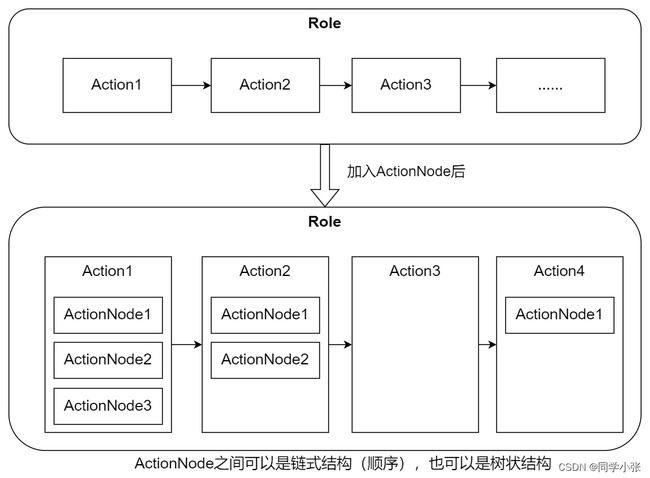
- 【AI的未来 - AI Agent系列】【MetaGPT】6. 用ActionNode重写技术文档助手

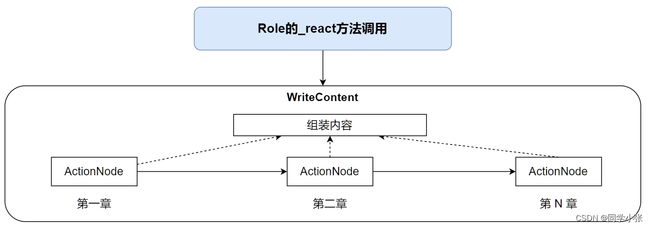
- 【AI Agent系列】【MetaGPT】7. 实战:只用两个字,让MetaGPT写一篇小说

- 【AI Agent系列】【MetaGPT】9. 一句话订阅专属信息 - 订阅智能体进阶,实现一个更通用的订阅智能体(2)
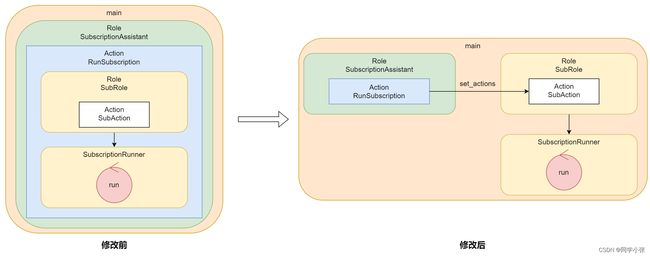
- 【AI Agent系列】【MetaGPT】【深入源码】智能体的运行周期以及多智能体间如何协作

找到自己的画图风格,即使你画的不标准,不适合给别人看,但你能画出来,对程序的理解也是有帮助的。
1.3 有选择地看源码
源码太多,肯定看不过来,也不知道从哪开始看。根据数据流,或者过程中踩得坑,带着问题去看源码最有效。
例如:
- 【AI的未来 - AI Agent系列】【MetaGPT】4.1 细说我在ActionNode实战中踩的那些坑
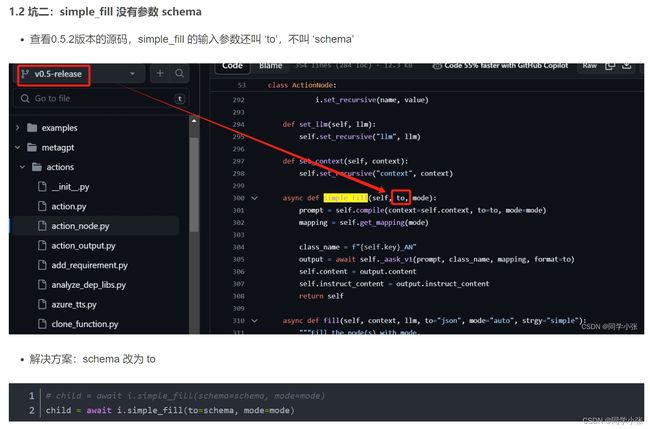
再比如,下面我要与大家探讨的智能体运行机制,其实就是带着问题去看的。
2. 从一个坑开始,看智能体运行机制
- 【AI的未来 - AI Agent系列】【MetaGPT】2. 实现自己的第一个Agent

我看这部分的源码的起因,源自第三章作业,打印数字的一个坑。智能体run的时候,必须传入一个字符串,否则不运行,这是当时调试时浪费了我很久时间的一个坑。当时留了个TODO。后面详细了解了下智能体的运行机制,可以看下这篇文章,在这里也简单与大家交流下。
- 【AI Agent系列】【MetaGPT】【深入源码】智能体的运行周期以及多智能体间如何协作
这是官方的智能体运行周期图,从_observe开始,经过思考、行动,最后将结果发送出去。

这是我根据Role的run函数画出来的一个智能体的运行的数据流(欢迎批评指正)。
跟着图,看下源码:
@role_raise_decorator
async def run(self, with_message=None) -> Message | None:
"""Observe, and think and act based on the results of the observation"""
if with_message:
msg = None
if isinstance(with_message, str):
msg = Message(content=with_message)
elif isinstance(with_message, Message):
msg = with_message
elif isinstance(with_message, list):
msg = Message(content="\n".join(with_message))
if not msg.cause_by:
msg.cause_by = UserRequirement
self.put_message(msg)
if not await self._observe():
# If there is no new information, suspend and wait
logger.info(f"{self._setting}: no news. waiting.")
return
rsp = await self.react()
# Reset the next action to be taken.
self.rc.todo = None
# Send the response message to the Environment object to have it relay the message to the subscribers.
self.publish_message(rsp)
return rsp
(1) 首先是对 with_message参数的处理,如果with_message参数不是None,会执行下面指令:
self.put_message(msg)
- self.put_message(msg)干了什么?
- 将msg放到自身的msg_buffer中
def put_message(self, message):
"""Place the message into the Role object's private message buffer."""
if not message:
return
self.rc.msg_buffer.push(message)
(2)执行 self._observe()函数,如果返回0或false,会进入if not await self._observe()的条件内,直接return,不触发后续动作的执行。
源码如下:
async def _observe(self, ignore_memory=False) -> int:
"""Prepare new messages for processing from the message buffer and other sources."""
# Read unprocessed messages from the msg buffer.
news = []
if self.recovered:
news = [self.latest_observed_msg] if self.latest_observed_msg else []
if not news:
news = self.rc.msg_buffer.pop_all()
# Store the read messages in your own memory to prevent duplicate processing.
old_messages = [] if ignore_memory else self.rc.memory.get()
self.rc.memory.add_batch(news)
# Filter out messages of interest.
self.rc.news = [
n for n in news if (n.cause_by in self.rc.watch or self.name in n.send_to) and n not in old_messages
]
self.latest_observed_msg = self.rc.news[-1] if self.rc.news else None # record the latest observed msg
# Design Rules:
# If you need to further categorize Message objects, you can do so using the Message.set_meta function.
# msg_buffer is a receiving buffer, avoid adding message data and operations to msg_buffer.
news_text = [f"{i.role}: {i.content[:20]}..." for i in self.rc.news]
if news_text:
logger.debug(f"{self._setting} observed: {news_text}")
return len(self.rc.news)
news = self.rc.msg_buffer.pop_all()取出msg_buffer中的所有消息。- 重点在这一句代码,从news中筛选出本role关注的消息
self.rc.news = [
n for n in news if (n.cause_by in self.rc.watch or self.name in n.send_to) and n not in old_messages
]
- 关注的消息:
self.rc.watch或者n.send_to- watch的内容,可以通过_watch函数设置
def _watch(self, actions: Iterable[Type[Action]] | Iterable[Action]):
"""Watch Actions of interest. Role will select Messages caused by these Actions from its personal message
buffer during _observe.
"""
self.rc.watch = {any_to_str(t) for t in actions}
看到这,是不是对刚开始那个必须设置一个msg才能run的坑有了点想法?
- 没有msg输入,就没有publish_message,_observe函数观察不到信息,就直接return了。
(3)_observe到信息之后,就是思考+动作的react函数了,简单看下,这块还没仔细看,就不讲了,怕误人子弟。
async def react(self) -> Message:
"""Entry to one of three strategies by which Role reacts to the observed Message"""
if self.rc.react_mode == RoleReactMode.REACT:
rsp = await self._react()
elif self.rc.react_mode == RoleReactMode.BY_ORDER:
rsp = await self._act_by_order()
elif self.rc.react_mode == RoleReactMode.PLAN_AND_ACT:
rsp = await self._plan_and_act()
self._set_state(state=-1) # current reaction is complete, reset state to -1 and todo back to None
return rsp
理解了单智能体的运行周期后,很容易理解多智能体间的协作。
看下图(图片来自:https://docs.deepwisdom.ai/main/zh/guide/tutorials/multi_agent_101.html):
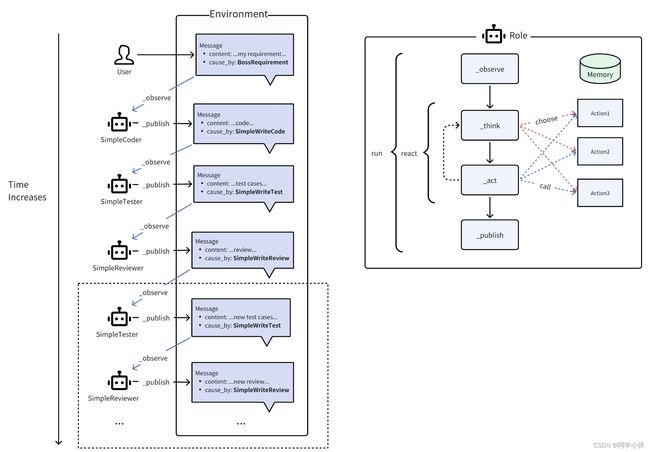
其实就是:
(1)每一个Role都在不断观察环境中的信息(_observe函数)
(2)当观察到自己想要的信息后,就会触发后续相应的动作
(3)如果没有观察到想要的信息,则会一直循环观察等待
(4)执行完动作后,会将产生的msg放到环境中(publish_message),供其它Role智能体来使用。
拿我们实现过的例子来看(【AI Agent系列】【MetaGPT】7. 一句话订阅专属信息 - 订阅智能体进阶,实现一个更通用的订阅智能体):
class SubscriptionAssistant(Role):
"""Analyze user subscription requirements."""
name: str = "同学小张的订阅助手"
profile: str = "Subscription Assistant"
goal: str = "analyze user subscription requirements to provide personalized subscription services."
constraints: str = "utilize the same language as the User Requirement"
def __init__(self, **kwargs) -> None:
super().__init__(**kwargs)
self._init_actions([ParseSubRequirement, RunSubscription]) ## 2. 先解析用户需求,然后运行订阅
self._watch([UserRequirement, WriteCrawlerCode]) ## 触发
我们实现了一个SubscriptionAssistant的智能体,它_watch了UserRequirement用户消息和WriteCrawlerCode消息。
运行后,它就会_observe环境:
- 当用户输入信息时,环境中存在了UserRequirement消息,它_observe到了,就会触发后续相应动作。从而实现了与用户的协作。
- 当其它智能体的WriteCrawlerCode执行完毕,会向环境中写入执行结果的msg,来源(cause_by标记为WriteCrawlerCode),然后SubscriptionAssistant的_observe观察到了,就会触发后续相应动作。从而实现了与其它智能体的协作,也就是多智能体间的协作。
3. 本次课程的收获和感悟
3.1 收获
- 第一个肯定是 MetaGPT 入门了,对Agent算是有了一个初步的系统的认知。
- 其次,Python的一些零零散散的知识和用法。比如:
- 直接在Python中调用系统命令来自动执行程序
subprocess(第三章) - Python推送微信消息(第四章)
- Python推送邮箱消息(第四章)
- GPT写小说的步骤(第五章)
- 最简单的爬虫程序怎么写(第四章、第五章)
- …
- 直接在Python中调用系统命令来自动执行程序
3.2 感悟
-
MetaGPT目前是一个Agent实现框架,是一个个角色和动作的抽象。要想实现Agent,感觉最重要的还是SOP(标准作业程序),只有有了SOP,才知道怎么定义一个个角色和动作,才知道需要怎么串联每个角色和每个动作。
-
目前只是入门,没有具体的需求,所以认识很有限,所以我上面讲的大家选择性的听听即可,希望能给大家一点启发。
-
希望后面有需求可以一起讨论学习。
-
我也会持续学习MetaGPT教程和源码(官方例子可以开始尝试研究了)。
本文就到这,能力有限,希望大家批评指正。
弱弱地说:欢迎 点赞 + 关注 ,促使我持续学习,持续干货输出。
+v: jasper_8017 一起交流,一起进步。微信公众号也可搜【同学小张】
4. MetaGPT入门系列文章
- 【AI的未来 - AI Agent系列】【MetaGPT】0. 你的第一个MetaGPT程序
- 【AI的未来 - AI Agent系列】【MetaGPT】1. AI Agent如何重构世界
- 【AI的未来 - AI Agent系列】【MetaGPT】2. 实现自己的第一个Agent
- 【AI的未来 - AI Agent系列】【MetaGPT】3. 实现一个订阅智能体,订阅消息并打通微信和邮件
- 【AI的未来 - AI Agent系列】【MetaGPT】4. ActionNode从理论到实战
- 【AI的未来 - AI Agent系列】【MetaGPT】4.1 细说我在ActionNode实战中踩的那些坑
- 【AI的未来 - AI Agent系列】【MetaGPT】5. 更复杂的Agent实战 - 实现技术文档助手
- 【AI的未来 - AI Agent系列】【MetaGPT】6. 用ActionNode重写技术文档助手
- 【AI Agent系列】【MetaGPT】7. 实战:只用两个字,让MetaGPT写一篇小说
- 【AI Agent系列】【MetaGPT】8. 一句话订阅专属信息 - 订阅智能体进阶,实现一个更通用的订阅智能体
- 【AI Agent系列】【MetaGPT】9. 一句话订阅专属信息 - 订阅智能体进阶,实现一个更通用的订阅智能体(2)
- 【AI Agent系列】【MetaGPT】【深入源码】智能体的运行周期以及多智能体间如何协作