Impala元数据简介
Impala元数据简介
背景
Impala是一个高性能的OLAP查询引擎,与其它SQL-on-Hadoop的ROLAP解决方案如Presto、SparkSQL 等不同的是,Impala对元数据(Metadata/Catalog)做了缓存,因此在做查询计划生成时不再依赖外部系统(如Hive、HDFS、Kudu),能做到毫秒级别的生成时间。另外缓存元数据也能极大减少对底层系统Master节点(Hive Metastore、HDFS NameNode、Kudu Master)的负载。
然而事情总有两面性,元数据缓存给Impala的系统设计引入了极大的复杂性。一方面在功能上为了维护缓存的正确性,引入了两个Impala特有的SQL语句:Invalidate Metadata 和 Refresh,另外还引入了query option SYNC_DDL。这些都让用户参与了缓存的维护。另一方面在架构设计上,有许多元数据相关的复杂设计,比如元数据的增量传播、缓存一致性的维护等。
在数仓规模较大时,Impala的元数据设计暴露出了许多问题,比如大表的元数据加载和刷新时间特别长、元数据的广播会被DDL阻塞导致广播延迟很大、元数据缓存导致节点Full GC或OOM等。因此Impala元数据设计也一直在演化之中,最新进展主要集中在Fetch-on-demand coordinator(又称local catalog mode、catalog-v2等)的设计,详见IMPALA-7127。
本文旨在介绍Impala元数据设计的基本概念,更多元数据相关的复杂设计将在后续文章中介绍。
Impala Server简介
Impala集群包含一个 Catalog Server (Catalogd)、一个 Statestore Server (Statestored) 和若干个 Impala Daemon (Impalad)。Catalogd 主要负责元数据的获取和DDL的执行,Statestored主要负责消息/元数据的广播,Impalad主要负责查询的接收和执行。

Impalad 又可配置为 coordinator only、 executor only 或 coordinator and executor(默认)三种模式。Coordinator角色的Impalad负责查询的接收、计划生成、查询的调度等,Executor角色的Impalad负责数据的读取和计算。默认配置下每个Impalad既是Coordinator又是Executor。生产环境建议做好角色分离,即每个Impalad要么是Coordinator要么是Executor,且可以以1:50的比例配置。更多细节可参考官方文档[1].
Impala元数据的构成
Impala的元数据缓存在catalogd和各个Coordinator角色的Impalad中。Catalogd中的缓存是最新的,各个Coordinator都缓存的是Catalogd内元数据的一个复本。如下图所示,元数据由Catalogd向外部系统获取,并通过 Statestored 传播给各个 Coordinator

元数据缓存主要由Java代码实现,主体代码在FE中。另有一些C++实现的代码,主要处理FE跟BE的交互,以及元数据的广播。代码中把 Catalogd 和 Coordinator (Impalad) 中相同的元数据管理逻辑抽出来放在了 Catalog.java 中,Catalogd 里的实现是 CatalogServiceCatalog.java,Coordinator 里的实现是 ImpaladCatalog.java.
Catalog是一个层级结构,第一层是 db name 到 db 的映射,每二层是每个db下的 function map和 table map:
Catalog
|-- dbCache_ = Map
|-- functions_ = Map>
|-- tableCache_ = CatalogObjectCache
functions_ Map 里的 value 是 Function 列表,主要表示同名函数的不同重载。tableCache_ 由 CatalogObjectCache 来维护。CatalogObjectCache 封装了一个 ConcurrentHashMap,另加了版本管理的逻辑,比如避免低版本的更新覆盖高版本的缓存、追踪所有缓存的版本号等。这些版本管理逻辑在Impalad中尤其重要。我们在后续的文章中会详细介绍。
Table 在代码里有五个具体的子类:HdfsTable、KuduTable、HBaseTable、View、IncompleteTable、DataSourceTable。前4个都比较直白,解释下最后两个:
- IncompleteTable 表示未加载元数据的表或视图(View)。Catalogd 启动时,为了减少启动时间,只加载了所有表的表名,每个表用IncompleteTable来表示。如果执行了INVALIDATE METADATA,则表的元数据也会被清空,其表现就是回置成了IncompleteTable。IncompleteTable可能代表一个视图,但这在元数据未加载时是无法确定的。因此在HUE等可视化界面中使用Impala时,常常会看到一个View是用Table的图标表示的,但一旦有被使用过,就又变回成了View的图标。
- DataSourceTable 属于external data source的实现,这块没有任何文档提及,因为一直处于实验状态。其初衷是提供一个Java接口来自定义外部数据源,只需要实现 prepare、open、getNext、close 这几个接口。具体可参考代码里的 EchoDataSource 和 AllTypesDataSource。
接下来我们重点介绍下前三个的元数据构成。
HdfsTable
HdfsTable 代表一张底层存储为 HDFS 的 Hive 表。无分区表的元数据比较简单,少了各个分区对应的元数据。这里以分区表为例,其元数据如图所示:
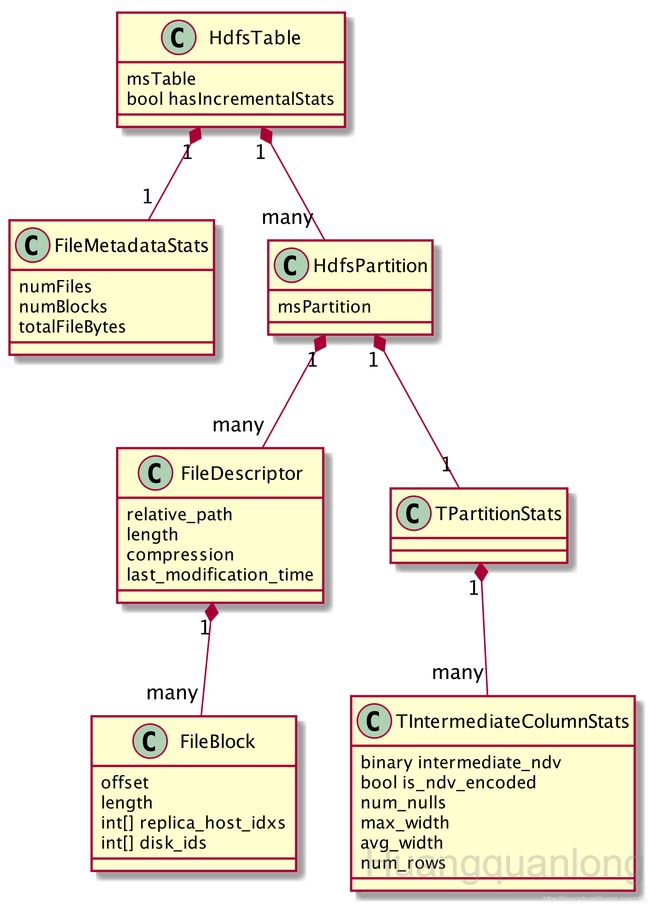
其中 msTable 和 msPartition 表示 HMS API 里返回的对象:
org.apache.hadoop.hive.metastore.api.Table
org.apache.hadoop.hive.metastore.api.Partition
HdfsPartition 代表一个分区的元数据,其一大部分内容是 HDFS 文件和块的信息。图中的 FileDescriptor 和 BlockDescriptor,就是从 HDFS API 里返回的 FileStatus 和 BlockLocation 对象抽取数据后生成的。为了节省空间,实际缓存的并不是上图展示的 FileDescriptor 和 FileBlock。IMPALA-4029 引入了 FlatBuffer 来压缩 FileDescriptor 和 FileBlock。FlatBuffer 的好处是不需要像 protobuf 或 thrift 一样做序列化和反序列化,但却可以直接访问对象里的内容,同时带来了一定的压缩比。更多关于 FlatBuffer 参见文末文档 [2].
HdfsPartition 的另一大部分内容是统计信息,缓存的是deflate算法压缩后的数据,具体详见:PartitionStatsUtil#partStatsFromCompressedBytes()。解压之后是一个 TPartitionStats 对象,主要包含了各列在该partition里的统计信息,每列的统计信息用一个 TIntermediateColumnStats 表示:
struct TIntermediateColumnStats {
1: optional binary intermediate_ndv // NDV HLL 计算的中间结果
2: optional bool is_ndv_encoded // HLL中间结果是否有用 RLE 压缩
3: optional i64 num_nulls // 该列在该分区的 NULL 数目
4: optional i32 max_width // 该列在该分区的最大长度
5: optional double avg_width // 该列在该分区的平均长度
6: optional i64 num_rows // 该分区行数,用于聚集HLL中间结果
}
关于 Impala 里 ndv() 的实现,可参考 be/src/exprs/aggregate-functions-ir.cc 中的 HllInit()、HllUpdate()、HllMerge()、HllFinalEstimate() 的逻辑。ndv 的中间结果用一个string表示,长度为 1024。在传输时一般会用 RLE (Run Length Encoding) 压缩。
Impala的统计信息受限于Hive(因为要保存在Hive Metastore中),目前并没有统计数值类型列的最大最小、平均值等信息。这块有个古老的 JIRA: IMPALA-2416,目前还没有进展。
一个HDFS分区表的元数据在各种压缩后,在内存中的大小约为
分区数*2048 + 分区数*列数*400 + 文件数*500 + 块数目*150
实际应用中要降低大表的元数据大小,就需要在分区数、列数、文件数、块数目上寻求优化的空间。其中 2048、400、500、150 这些数都是各对象压缩大小的估计值,“分区数 * 列数 * 200” 指的是增量统计信息的大小,如果表的统计信息是非增量的,即一直用 Compute Stats 来统计,则不需要这部分。实际应用中很少直接对大表做 Compute Stats,因为执行时间可能很长,一般都是使用 Compute Incremental Stats,因此这部分的内存占用不可忽略。
KuduTable
HdfsTable 代表一张底层存储为 Kudu 的 Hive 表。Impala 缓存的 Kudu 元数据特别有限:
- msTable: HMS API 返回的 Table 对象,主要是 Hive 中的元数据
- TableStats: HMS 中存的统计信息,主要是各列统计信息和整张表的行数等
- kuduTableName: Kudu 存储中的实际表名,该名字可以跟 Hive 中的表名不同。
- kuduMasters: Kudu 集群的 master 列表
- primaryKeyColumnNames: Kudu 表的主键列
- partitions: Kudu 表的分区信息
- kuduSchema: Kudu API 返回的 Schema 信息
关于分区信息,只缓存了分区的列是哪些,以及 hash 分区的分区数,并没有缓存 Range 分区的各个 Range 是什么,因此在用 SHOW CREATE TABLE 语句时,看到的 range partition 信息只包含了列名。比如下面这个例子,“Partition by range(id)” 部分的各个 range 被省略了:
Query: show create table functional_kudu.dimtbl
+-------------------------------------------------------------------------------------------------------------------------------------------+
| result |
+-------------------------------------------------------------------------------------------------------------------------------------------+
| CREATE TABLE functional_kudu.dimtbl ( |
| id BIGINT NOT NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION, |
| name STRING NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION, |
| zip INT NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION, |
| PRIMARY KEY (id) |
| ) |
| PARTITION BY RANGE (id) (...) |
| STORED AS KUDU |
| TBLPROPERTIES ('STATS_GENERATED'='TASK', 'impala.lastComputeStatsTime'='1573922577', 'kudu.master_addresses'='localhost', 'numRows'='10') |
+-------------------------------------------------------------------------------------------------------------------------------------------+
如果需要查看具体有哪些 range 分区,还是需要用 SHOW RANGE PARTITIONS 语句,Impala 会从 Kudu 中获取结果来返回,然而还是不会缓存这些 range 信息。
Query: show range partitions functional_kudu.dimtbl
+-----------------------+
| RANGE (id) |
+-----------------------+
| VALUES < 1004 |
| 1004 <= VALUES < 1008 |
| VALUES >= 1008 |
+-----------------------+
Fetched 3 row(s) in 0.07s
这块个人觉得还有很多工作可做,比如把 range 分区的分界点缓存下来后,可以用来优化 Insert 语句,提升批量导入 Kudu 的性能(IMPALA-7751)。另外关于更细节的信息如每个 kudu tablet 的复本位置,kudu tserver 地址等都是没有缓存的,利用这些信息实际也能做很多优化,欢迎大家一起来参与开发!
HBaseTable
Impala 对 HBase 的支持始于对 Hive 的兼容(Hive 可以读 HBase 的数据),但目前已经处于维护状态,社区不再在这方面投入精力。一方面是 Kudu 更适合替代 HBase 来做 OLAP,另一方面是 Impala 也不适合太高并发的 DML 操作。
HBaseTable 代表底层存储为 HBase 的 Hive 表,缓存了 HMS 中的 Table 定义和表的大小(行数)这些基本的统计信息,另外也缓存了底层 HBase 表的所有列族名。
总结
Impala 缓存了外部系统(Hive、HDFS、Kudu等)的元数据,主要目的是让查询计划生成阶段不再需要跟外部系统交互。生成查询计划需要哪些元数据,哪些元数据就会被缓存下来:
- Table: Schema(表名、字段名、字段类型、分区字段等)、各列统计信息
- HdfsTable: 分区目录、文件路径、文件分块及复本位置、各分区的增量统计信息等
- KuduTable: 分区列及分区类型(Hash、Range)
- HBaseTable: 各列族名
- View: 具体的查询语句
参考文档
- https://impala.apache.org/docs/build/html/topics/impala_dedicated_coordinator.html
- https://google.github.io/flatbuffers/index.html
你可能感兴趣的:(Impala)