Ribbon 体系架构解析
前面已经介绍了服务治理相关组件,接下来趁热打铁,快速通关Ribbon!前面我们了解了负载均衡的含义,以及客户端和服务端负载均衡模型,接下来我们就来看下SpringCloud 下的客户端负载均衡组件Ribbon 的特点以及工作模型。
负载均衡工具箱

《圣斗士星矢》是一部贯穿我童年的动画片,它讲述了五个怎么也打不死的人,把其他人全部都打死的过程(突然发现童年好无聊)。在这片子中,最厉害的装备叫做黄金圣衣,总共有 12 件,分别对应十二座。这十二件中最传奇,最特殊的当属天秤座黄金圣衣,和其他圣衣相比他有以下几个特点:
- 丰富的组件库 整套圣衣由 12 件兵器组成,不管你是煎炸烹炒,都有合适的
组件供你选择 - 给谁都能用 适配性好,跟谁都能搭配,片子里的五小强,谁拿都能用
在 SpringCloud 的世界观中,如果也要打造一件一模一样的天秤座圣衣,那一定是非Ribbon 莫属了,它也有一模一样的特点:
- 丰富的组件库 整套负载均衡由 7 个具体策略组成,不管你是什么特殊需求,都有合适的策略供你选择
- 给谁都能用 适配性好,跟谁都能搭配,SpringCloud 里的五小强(eureka,feign,gateway,zuul,hystrix),谁拿都能用。
- 更牛的是 Ribbon 可以脱离 SpringCloud 应用在一般项目中。
走近 Ribbon
刚才说到 Ribbon 给谁都能用,要不先让带头大哥 Eureka 试试?同学们注意了,红框白底
的是 Ribbon 自己的组件。

一个 HttpRequest 发过来,先被转发到 Eureka 上。此时 Eureka 仍然通过服务发现获取了
所有服务节点的物理地址,但问题是他不知道该调用哪一个,只好把请求转到了 Ribbon
手里。
IPingIPing 是 Ribbon 的一套healthcheck机制,故名思议,就是要Ping一下目标机器看是否还在线,一般情况下 IPing 并不会主动向服务节点发起healthcheck请求,Ribbon 后台通过静默处理返回 true 默认表示所有服务节点都处于存活状态(和 Eureka 集成的时候会检查服节点 UP 状态)。IRule这就是Ribbon的组件库了,各种负载均衡策略都继承自IRule接口。所有经过Ribbon的请求都会先请示IRule一把,找到负载均衡策略选定的目标机器,然后再把请求转发过去。
负载均衡策略-七种策略
RandomRule - 随性而为
从名字就能看出,这是个很随性的策略,随性到什么程度呢?它会从当前可用的服务节点中,随机挑选一个节点访问。这分明是乱拳打死老师傅的路子吗,哪有负载均衡的智慧?别急,这里为了打死老师傅还真用了两个小花招,使用了 yield+自旋的方式做重试,还采用了严格的防御性编程。
RoundRobinRule - 按部就班
这个 rule 是 RandomRule 的亲兄弟,RandomRule 是随性而为挑选节点,RobinRule 却按部就班从一个节点一步一步地向后选取节点,既不会跳过一个,也不会原地踏步,每一次只向后移动一步。

小伙伴也许会问了,假如在多线程环境下,两个请求同时访问这个 Rule 是否会读取到相同节点呢?不会,这靠的是 RandomRobinRule 底层的自旋锁+CAS 的同步操作。CAS 的全称是 compare and swap,是一种借助操作系统函数来实现的同步操作。前面我们讲到过Eureka 为了防止服务下线被重复调用,就使用 AtomicBoolean 的 CAS 方法做同步控制,CAS+自旋锁这套组合技是高并发下最廉价的线程安全手段,因为这套操作不需要锁定系统资源。当然了,有优点必然也有缺点,自旋锁如果迟迟不能释放,将会带来 CPU 资源的浪费,因为自旋本身并不会执行任何业务逻辑,而是单纯的使 CPU“ ”空转 。所以通常情况下会对自旋锁的旋转次数做一个限制,比如 JDK 中 synchronize 底层的锁升级策略,就对自旋次数做了动态调整。
// CAS+自旋锁获取系统资源的打开方式,真实应用中还要注意防止无休止自旋:
// 或者 for (; 做自旋
while (true) {
// cas 操作
if (cas(expected, update)) {
// 业务逻辑代码
// break 或退出 return
}
}
Netflix 真是特别喜欢用自旋 CAS,毕竟作为中间件来说性能还是非常重要的。不过我实在没明白为什么名字里带个 Robin,我猜想写代码的人或者他的宠物可能叫 Robin?就像Oracle 数据库有一个默认账号叫 scott 一样。
RetryRule - 卷土重来
RetryRule 是一个类似装饰器模式的 Rule,我们前面学习服务注册的时候了解过,装饰器相当于一层套一层的俄罗斯娃娃,每一层都会加上一层独特 BUFF,我们这里复习一下装饰器的结构.

RetryRule 也是同样的道理,他的 BUFF “ ”就是给其他负载均衡策略加上 重试 功能。而在RetryRule 里还藏着一个 subRule,这才是隐藏在下面的真正被执行的负载均衡策略,RetryRule 正是要为它添加重试功能(如果初始化时没指定 subRule,将默认使用RoundRibinRule)。
WeightedResponseTimeRule - 能者多
这个 Rule 继承自 RoundRibbonRule,他会根据服务节点的响应时间计算权重,响应时间越长权重就越低,响应越快则权重越高,权重的高低决定了机器被选中概率的高低。也就是说,响应时间越小的机器,被选中的概率越大。

由于服务器刚启动的时候,对各个服务节点采样不足,因此会采用轮询策略,当积累到一定的样本时候,会切换到 WeightedResponseTimeRule 模式。关于权重的计算方式,感兴趣的小伙伴可以看看Ribbon的源码实现。
BestAvailableRule - 让最闲的人来
应该说这个 Rule 有点智能的味道了,在过滤掉故障服务以后,它会基于过去 30 分钟的统计结果选取当前并发量最小的服务节点,也就是最 “闲” 的节点作为目标地址。如果统计结果尚未生成,则采用轮询的方式选定节点。
关键字
- 过滤故障服务
- 选取并发量最小的节点
AvailabilityFilteringRule - 我是有底线的
这个规则底层依赖 RandomRobinRule 来选取节点,但并非来者不拒,它也是有一些底线的,必须要满足它的最低要求的节点才会被选中。如果节点满足了要求,无论其响应时间或者当前并发量是什么,都会被选中。
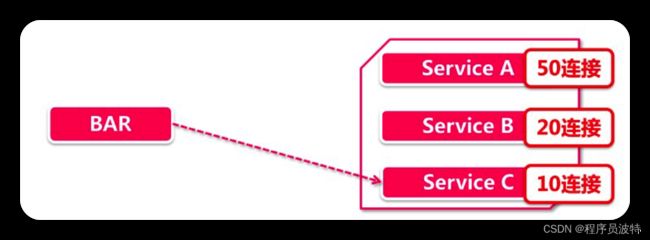
每次 AvailabilityFilteringRule(简称 AFR)都会请求 RobinRule 挑选一个节点,然后对这个节点做以下两步检查:
- 是否处于熔断状态(熔断是 Hystrix 中的知识点,后面章节会讲到,这里大家可以把熔断当做服务不可用)
- 节点当前的 active 请求连接数超过阈值,超过了则表示节点目前太忙,不适合接客,如果被选中的 server 不幸挂掉了检查,那么 AFR 会自动重试(次数最多 10 次),让RobinRule 重新选择一个服务节点。
ZoneAvoidanceRule - 我的地盘我做主
这个过滤器包含了组合过滤条件,分别是 Zone 级别和可用性级别。

Zone Filter: 在 Eureka 注册中一个服务节点有 Zone, Region 和 URL 三个身
份信息,其中 Zone 可以理解为机房大区(未指定则由 Eureka 给定默认值),
而这里会对这个 Zone 的健康情况过滤其下面所有服务节点。- 可用性过滤:这里和
AvailabilityFilteringRule的验证非常像,会过滤掉当
前并发量较大,或者处于熔断状态的服务节点。
本文已收录至我的个人网站:程序员波特,主要记录Java相关技术系列教程,共享电子书、Java学习路线、视频教程、简历模板和面试题等学习资源,让想要学习的你,不再迷茫。