NoSQL基本常识
NoSQL基本常识
NoSQL(最初指“非SQL(non SQL)”、“非关系(non relational)”或“不仅是SQL(Not Only SQL)”)
NoSQL是一个通用术语,用于指不遵循传统RDBMS模型的任何数据存储——具体来说,数据是非关系型的,它不使用SQL作为主要查询语言。它是用于指试图解决可伸缩性和可用性问题而不是原子性或一致性问题的数据库。
NoSQL可以用描述任何一种数据文件,不具备传统关系型数据库的范式,NoSQL是非关系型设计的Database,主要针对当前互联网时代的复杂数据
NoSQL的必要性:
数以百万计的用户
低成本的存储
增加处理能力
捕获(和需要)数百万个事件的能力。缓存在一定程度上解决了这个问题,但也带来了其他复杂性
实时响应
需要向外扩展,而不是向上扩展(增加无限数量的低成本机器 VS 用更强大的机器代替)
花费:
企业数据库的互联网规模可能会变得昂贵
开源数据库可以解决许可证成本问题,但不要忽略运营成本
关系型数据库 VS NoSQL:
关系型数据库:
分为表,关联到外键,DB约束,规范化数据,接口是SQL
NoSQL:
以无模式格式存储,鼓励冗余,应用程序访问决定存储格式(您的查询)。接口的变化和优化的实现,没有强制的数据库约束。
Schema:定义数据库表里的数据结构,就是列的定义的意思
NoSQL的权衡:
Eventual consistency——最终一致性,当从数据库里读取数据时,并不会马上读取出来,但是最终是读出来的
应用程序增加了维护一致性和处理事务等职责
Store redundant data——冗余数据存储,关系型数据库要遵守5大范式保证数据库不冗余
NoSQL不是大数据:
NoSQL != Big Data
创建NoSQL产品是为了帮助解决大数据问题。
大数据是一个比存储更大的问题(NoSQL只是大数据生态圈里的一小部分)
Hadoop
Kafka
Spark等等
NoSQL只是在数据存储的角度,类似于Database的语句
NoSQL的概念:
三个重要性——CAP,BASE,Consistency(一致性)
Indexing(索引),Queries(查询)
MapReduce
Sharding(分区)
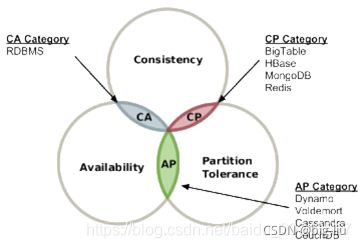
CAP理论(Consistency,Availability,Partition Tolerance):
数据库只能满足3个条件中的2个
NoSQL不提供“ACID”保证
ACID是数据库事务正确执行的四个基本要素的缩写,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
相反,它提供了“最终一致性”
BASE理论:
根据上限定理,基本可用性表明系统确实保证了可用性。
软状态表示即使没有输入,系统的状态也可能随时间而变化。这是因为最终一致性模型。
最终的一致性表明,随着时间的推移,系统将变得一致,前提是系统在此期间不接收输入。
最终一致性:
比如库存,账户余额应该是一致的
像目录信息这样的东西不必是必须的,至少不必立即是
如果在目录中输入了一个新条目,一些客户甚至在其他客户的服务器知道它之前就可以看到它
但是目录信息必须很快出现
因此,在等待更新另一个位置时,不要将数据锁定在一个位置
因此,在某些情况下,为了速度牺牲一致性是可以的
索引:
大多数NoSQL数据库都是按键索引的
一些允许所谓的“二级”索引
主键索引通常是集群的
HBase使用HDFS(Hadoop分布式文件),这是只附加的
写记录
日志写入被批处理
文件被重新创建和排序
查询:
通常没有查询语言
相反,创建过程程序
有时支持SQL
有时使用MapReduce代码…
MapReduce:
这不是Hadoop的MapReduce,但它在概念上是相关的
映射步骤:预处理数据
简化步骤:汇总/聚合数据
分区:
一种分区模式,其中单独的服务器存储分区
扇-输出查询支持
分区可能是重复的,因此也提供了复制
有利于灾难恢复
由于“切分”可以在地理上分布,所以切分可以充当CDN
有利于保持数据接近处理
减少MapReduce分割发生时的网络流量
NoSQL类别:

Key-Value存储:
最常见的;不一定是最受欢迎的
有行,每个行都有一个大的字典/关联数组
模式可能因行而异
云平台上常见的
例如:Amazon SimpleDB,Azure Table Storage
MemcacheDB,Voldemort,Couchbase,DynamoDB(AWS),Dynomite,Redis和Riak
Key-Value存储结构:

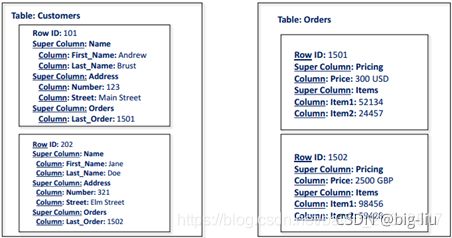
宽列存储:
表是否具有已声明的列族
每个列族都有“列”,它们是KV对,行与行之间可以不同
这些是大型站点最基础的
Google big table
HBase
Cassandra(Facebook)
将列族称为“超级列”和表“超级列家庭”
它们是最“大数据”的,尤其是HBase + Hadoop
宽列存储结构:
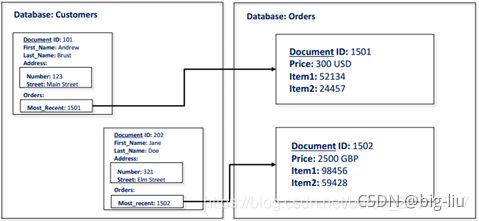
文件存储:
文档通常是JSON对象
每个文档都有属性和值
值可以是标量、数组、到其他数据库或子文档(即包含JSON对象的文档)中的文档的链接
允许分层存储)
保留旧版本
因此,文档存储对于内容管理非常有效
有些观点认为文档存储是专门的KV存储
最受开发者,创业公司,风投公司欢迎
CouchDB,MongoDB,CouchBase
文档存储模式:
图形数据库:
非常适合社交网络应用程序和其他关系很重要的应用程序
Nodes(节点)和edges(边)
Edge就像join
Nodes类似于表中的行
节点还可以具有属性和值
Neo4j是一种流行的图形数据库
Titan
图形数据库结构(描述数据库的关系):
NoSQL和BI(数据智能):
NoSQL数据库不适合特殊查询和数据仓库
BI应用涉及模型;模型依赖于模式
提取Extract、转换Transform和加载load(ETL)可能是您的朋友
然而,宽栏存储对于“大数据”是有好处的
宽列存储和面向列的数据库在技术上是类似的
NoSQL和大数据:
大数据和NoSQL是相关的
通常,大数据场景中使用的是宽列存储
最好的例子:HBase and Hadoop
缺少索引不是问题
一致性不是问题
快速阅读非常重要
分布式文件系统也很重要
商品硬件和磁盘的假设也很重要
不是web的规模,而是大规模的扩展,类似的问题
NoSQL妥协
最终一致性
写缓冲,把写的东西写到一个log里,在数据恢复的时候能保证写的东西不会丢失
只能索引主键
查询必须作为程序编写
工具和支持
Productivity (= money)
NoSQL中常见的DBA任务
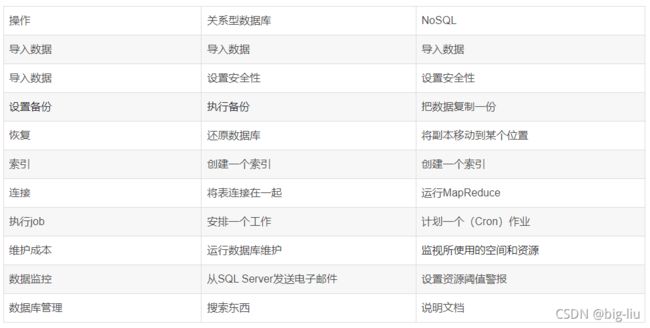
关系型数据库 VS NoSQL
业务线数据分析使用关系型数据库
大型、面向公共(消费者)的网站站点点使用 NoSQL
复杂的数据结构使用关系型数据库
大数据使用NoSQL
Transactional事务处理型数据库使用关系型数据库
Content Management内容管理型数据库使用NoSQL
企业级使用关系型数据库
消费者级网络使用NoSQL
喜欢的同学欢迎关注公众号,每天都有新的java内容分享
