JAVA学习笔记(七) 数组和数组列表
这个部分就不如循环和判断那么基础了,但是还是挺重要的,值得一学。
目录
数组
声明和使用数组
数组引用
部分填充的数组
避免并行数组
增强for循环
常用的数组算法
求和与求平均
最值
线性查找
删除一个元素
插入元素
交换元素
复制数组
读取输入
二维数组
声明二维数组
访问元素
数组列表
声明和使用数组列表
复制数组列表
数组列表的算法
数组列表与数组的选择
数组
声明和使用数组
数组嘛,字如其名,就是数的组合。
在各种编程语言里面数组是不可避免的内容,毕竟计算机就是处理数字的。
// 声明一个数组
double[] values;
// 之前只是声明,没有初始化。下面这个就是初始化一个里面包含10个double类型数据的数组
double[] values = new double[10];
// 上面这个初始化是默认里面的数值是0// 如果想要初始化的数组里面是有你指定的数值的,要这样做
double[] moreValues = {32, 54, 67.5, 29, 35, 80, 115, 44.5, 100, 65};既然我们进行了最基础的创建,那么一些调用也要明白:
// 将第五个数字改为32
values[4] = 32;也就是说用[]来调用索引位置下的内容
一个很基础的内容这里强调一下,敲代码的时候检查一下你的索引,是从0开始计的吗?别犯超出索引这样的低级错误!
数组引用
数组的引用不是数组的调用,这里注意审题!
说白了,教材的意思是对于同一个对象,给它开多个链接
// 举个例子
int[] scores = { 10, 9 , 8, 7};
int[] values = scores;
// 这里的values可不是一个复制scores,只是引用;
// 这好比说鲁迅先生说:“绍兴是个好地方!”,我的引用是“绍兴是个好地方!”
// 如果鲁迅先生的遗稿发现写的是“绍兴是个很好的地方!”
// 那么我们的引用就会发生改变部分填充的数组
一个数组是有大小的,就像一个盒子有他的容积,但是我们会不会把这个“盒子”放满就是一个实际应用的问题了。

上图中的currentSize就是一个伴随变量,是用来指示“盒子”里面实际的装填量的。下面的代码就是用来实际解释应用的:
int currentSize = 0;
Scanner in = new Scanner(System.in);
while (in.hasNextDouble()){
if (currentSize < values.length){
values[currentSize]=in.nextDouble();
currentSize++;
}
}
// 循环的最后会使得currentSize值的大小就是实际数据的长度
// 如果需要打印输出实际的数组的内容,那么应当如下
for (int i = 0; i < currentSize; i++){
System.out.println(values[i]);
}避免并行数组
如果两个数组内容是并行处理的,比如银行账户放在一个数组,对应的存款放在另一个数组。这样处理就会比较麻烦,而且有出错的可能性,所以建议将这样的情况整合为一个类,作为一个整体放在同一个数组里面。刚刚提及的例子完全可以用BankAccount类来实现,然后把每一个BankAccount对象作为一个内容放在数组里面
增强for循环
所谓的增强for循环也就是for循环,但是比较省事好写,语法如下:
for (数据类型 形式参数 : 被遍历的对象){
// 进行各人的操作
}
//例子
for (double element : values){
System.out.println(element);
}值得注意的是, 增强for循环和一般循环比较不一样的一点是它不可以修改被遍历对象的内容,只能读取!
常用的数组算法
求和与求平均
double total = 0;
for (double element : values){
total += element;
}
double average = 0;
if (values.length > 0){average = total / values.length}最值
// 最大值
double largest = values[0];
for (double element : values){
if (element > largest){
largest = element;
}
}// 最小值
double smallest = values[0];
for (double element : values){
if (element < smallest){
smallest = element;
}
}线性查找
就是要在一个数组里面得到要查找的内容的位置信息:
// 假设我们要找的那个内容是target
int pos = 0;
boolean found = false;
while (pos < values.length && !found){
if (values[pos] == target){
found = true;
}else{
pos++;
}
}删除一个元素
如果该数组对顺序没有要求,那么用最后一个元素去覆盖该元素,并将长度减一即可:
values[pos] = values[currentSzie-1];
currentSize--;如果顺序很重要,那么就需要牵动其他相关内容的位置了:
for (int i = pos + 1; i < currentSize; i++){
values[i-1] = values[i];
}
currentSize--;插入元素
假设需要插入的元素是newElement。
如果顺序不重要,那么直接在末尾加上即可:
if (currentSize < values.length){
currentSize++;
values[currentSize-1] = newElement;
}如果顺序重要,需要插入到一个特定的位置:
if (currentSize < values.length){
currentSize++;
for (int i = currentSize -1; i > pos; i--){
values[i] = values[i-1];
}
values[pos] = newElement;
}交换元素
Java和其他的一类的语言交换过程不像Python那么无脑,不是说a=b,b=a就可以直接交换的:
double temp = values[i];
values[i] = values[j];
values[j] = temp;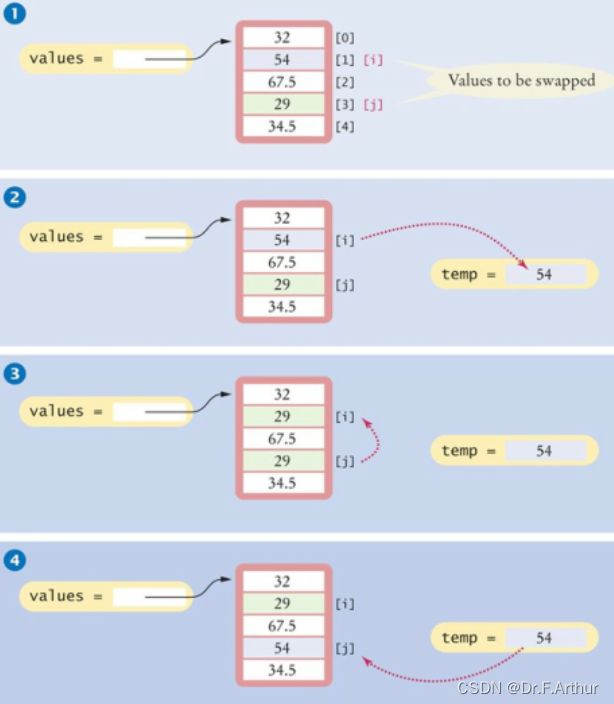
复制数组
这个地方就不同于对数组的引用了,是要实实在在的做一个副本,二者是不相干的!
double[] prices = Arrays.copyOf(values,n);
// 前一个参数是要复制的内容
// 后一个参数是这个副本的长度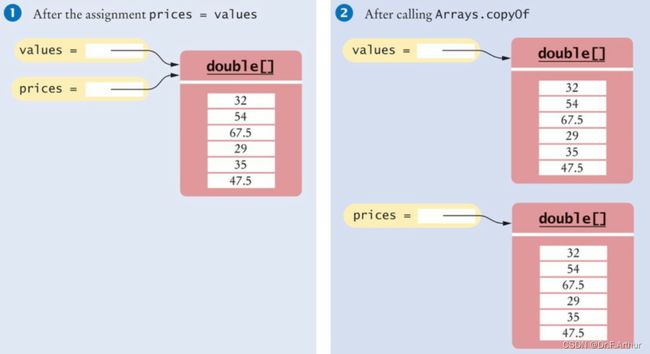
这下就很有趣了,虽然我们不能改变数组的长度,但是可以通过复制形成一个新数组,使其内容一致,长度改变,曲线救国了属于是。这样的具体应用将在下一个小标题里面提及。
读取输入
下面这个挺综合,也比较符合实际:
double[] inputs = new double[10];
int currentSize = 0;
while (in.hasNextDouble()){
if (currentSize >= inputs.length){
inputs = Arrays.copyOf(inputs,currentSize*2);
}
inputs[currentSize] = in.nextDouble();
currentSize++;
}
// 最后为了节省空间,可以这样做
inputs = Arrays.copyOf(inputs,currentSize);二维数组
声明二维数组
int[][] counts = int[7][3];
// 默认是7行3列的内容全为0的数组
// 如果遵从非“魔法数”原则,那么就应当这里给7和3赋值给有实际指示含义的变量
//也可以像下面这样进行最直观的初始化
int[][] counts =
{
{0,3,0},
{0,0,1},
{0,0,1},
{1,0,0},
{0,0,1},
{3,1,1},
{0,1,0}
}同样二维数组和数组一样,一旦确定之后就不能改变大小!
访问元素
可以通过位置进行读取和改动:
counts[2][0] = 1;
// 就是将第3行第1列的元素改成1
通常我们会运用到循环的内容来辅助读取:
for (int i = 0; i < counts.length; i++){
for (int j = 0; j < counts[0].length; j++){
System.out.printf(counts[i][j]);
}
System.out.println();
//尾端强制换行
}数组列表
这个东西就比较接近Python里面的列表了,但是没有那个万能:数组列表不需要事先规定大小,但是要事先规定所装的数据类型。
声明和使用数组列表
首先是声明
// 这个数组列表不同于数组,不是基本数据类型,用它是要专门导库的
import java.util.ArrayList;
ArrayList names = new ArrayList();
ArrayList values = newArrayList(); 注意,基本数据类型是不能直接放入数组列表的,要用特殊的包装器: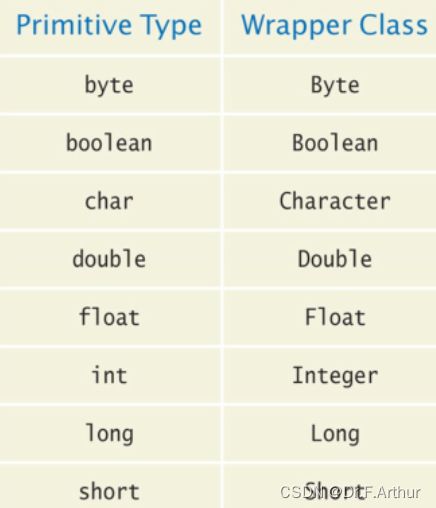
然后是使用
// 添加
names.add("Emily");
names.add("Bob");
names.add("Cindy");
names.add(3,"World")
// 获取元素
names.get(2);
//这个的返回值是第三个元素,即"Cindy"
// 获取数组列表的长度
int len = names.size();
// 设置元素内容
names.set(2,"Hello");
// 结果就是第三个元素变化,即"Cindy"修改为"Hello"
// 删除
names.remove(3);复制数组列表
因为数组列表不是数组,所以复制的方法不一样,而且请牢记,除了基础的数字,一般的东西都是引用的,所以都要考虑复制:
ArrayList newNames = new ArrayList(names); 数组列表的算法
基础的求和、求平均、最值等就改一下语法就行,内核是一样的。不过删除匹配元素这一项就有点差异了。
因为每删除一个,就会不可避免地导致索引发生变化,它不会像数组一样是静态的,是动态灵活的。解决也简单,具体代码我不写,写个伪代码如下,有想要知道的私信我可以给出答案:
if 索引i的元素满足条件
删除该元素
else
将i+1
数组列表与数组的选择
其实也没什么好纠结的 ,具体问题具体分析,结合实际的数据需要与这两种数据结构的特性而定。
好了,水完,收工!