数仓治理-数据质量治理
注:文章参考:语数-数据质量治理本期语兴从数据质量治理角度出发,与大家一起探讨数据质量治理最佳实践,之前的数据治理文章在网易有数官方公众号,数据治理课程讲解在B站(搜索:语兴呀) https://mp.weixin.qq.com/s/uoHlA64q1K_WHVYLPRucHQ
https://mp.weixin.qq.com/s/uoHlA64q1K_WHVYLPRucHQ
目录
一、数据质量治理的背景
1.1 BUG工单较多
1.2 DQC(数据质量监控)常触发
1.3 基线/SLA经常破线
二、数据质量治理识别
2.1 数据问题频出
2.2 DQC及任务失败频出
2.3 基线/SLA破线
三、数据质量治理实施流程
3.1 数据开发/校验流程重制定
3.2 DQC整治
3.3 基线告警任务拆解
四、数据质量治理评估
五、数据质量治理思考
一、数据质量治理的背景
一般而言,数仓的数据质量保障措施包括:数据质量监控DQC、数据基线/SLA、数据问题上报平台、数据质量长期监测跟踪体系等。该篇文章阐述的数据质量治理,前提是数仓已经实施过质量方案,只是随着业务迭代,当前的质量保障措施不再适用,逐渐暴露出一些问题(数据质量治理的阶段:业务中后期)。
数仓-数据质量 见: 数仓-数据质量-CSDN博客文章浏览阅读460次,点赞13次,收藏6次。数仓-数据质量https://blog.csdn.net/SHWAITME/article/details/135732154?spm=1001.2014.3001.5501
1.1 BUG工单较多
数仓在快速扩张期时忙于交付需求,从而对数据质量侧并未形成对应流程,同时由于开发者能力较弱或对业务不理解也会出现被投诉的情况。
1.2 DQC(数据质量监控)常触发
实施全链路DQC保障后,无效/敏感DQC触发、数据质量波动触发、或者无效DQC不下线仍触发等一系列问题导致夜间告警频发,夜间值班同学工作量巨增。
1.3 基线/SLA经常破线
由于线上任务告警过多(任务报错、资源告警、任务超时等)导致值班同学高频率起夜看问题,部分任务挂在基线/SLA上导致夜间电话不断。同时对于跨域值班的同学、新人来说处理起来较难,需要去找他人解决,对于跨BU(业务线/产品线)数据使用还需要找到其他业务方去处理。
二、数据质量治理识别
2.1 数据问题频出
可以从数据质量问题出发、找到任务经常出现质量问题对应的数仓负责人,定位触发问题细节。
2.2 DQC及任务失败频出
通过数据质量中心去查看每日/近一周情况,DQC每周破线次数,夜间电话告警次数、起夜次数等判断情况。(数据质量监控报告图)
 、
、
2.3 基线/SLA破线
通过基线运维去查看每日/近一周基线破线情况 ,每条基线的周破线次数、夜间电话告警次数、起夜次数等判断基线情况,SLA破线可以与业务方对接,对数仓产出投诉去查看。(基线运维图)

三、数据质量治理实施流程
3.1 数据开发/校验流程重制定
需求评估:接到需求后进行评估(数仓不能盲目的支撑需求),除了对接口径背景外,可以让业务方阐述需求带来的价值和数据增长,从而判断需求要不要接,从源头减少无效需求的出现。
模型设计:接入需求后按照模型5要素(数据域、事实、粒度、维度、度量)完成数据模型设计,并进行需求模型评审。
(1)模型5要素是否满足结构清晰,例如:数据域有划分、度量值是否合理(例如dwd层存储明细,不做聚合操作)、全量增量是否有做分区。
(2)数据是否有日期及时间字段、是否将code 转化(例如 :将数值code映射成具有实际业务含义的值)、脱敏字段是否已经处理(具体看业务场景,并一定做)等。
(3)表/字段命名/字段属性是否遵循规范、字段comment是否完整等。
(4)任务ower是否标记清楚、模型对应业务过程是否描述清楚、粒度是否有描述、表生命周期/存储格式是否遵循标准规范、核心表是否有重点标注等。
数据校验:平台工具或写sql自测的方式进行数据探查和数据比对。
(1)数据探查: 对表,字段,数据内容等进行全面摸查,表数据量、关键性字段(特指主键)的最大最小值/长度,空值占比;其余字段的最大最小值/长度等。(数据探查图)

(2)数据比对: 代码上线前,对开发环境dev数据表与线上环境pro表进行比对,包括表数据量、表去重后数据量、字段总体/个别一致率等。(数据比对图)
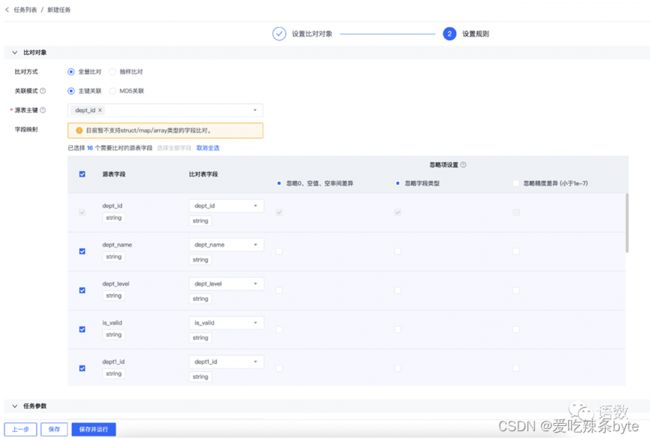
(3)指标验证:数据抽样,从ODS层取数写SQL去关联清洗,与ADS呈现的指标数据进行比对,两者保障80%的匹配度,剩余20%跟数据分析、数据产品等搭建BI看板后再进行统一联调。
Code Review: 除了代码合理性,还需要检查依赖,数据校验报告、开发环境中任务运行是否超时。
3.2 DQC整治
可能是DQC太过敏感或无效DQC影响整体数据质量(尤其是强规则,并非是数据问题),导致DQC经常夜间触发,值班人员被吵醒。
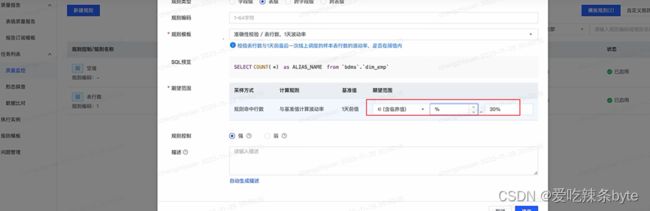
基础DQC治理:通过算法对DQC波动率进行监测,动态评估阈值(阈值可以理解为有一定的 数据容错率)。具体操作可以是:从原来的 表行数波动/主键唯一/主键不为空/表数据不为空 做出裁剪优化,尤其是增量表的表行数波动变化较大,经常会遇到多出1%-5%的情况,从业务及数据实际情况来看,这类情况也是合理的。但是因为最初的DQC阈值设置不合理导致任务失败。阿里的DataWorks具备算法识别功能,支持基于任务最近执行情况计算阈值。(线性回归15日)
业务DQC治理:对长期未被引用且在线上空跑的任务及DQC下线处理,对于指标波动异常的DQC而言,如果是非核心指标监控,可直接降为弱规则,如果是核心指标,可以通过数据血缘溯源,从上游数据查找原因。此外,还可以建设核心指标运营群,当有特殊情况出现(例如:双11大促等)需要提前通知相关负责人,准备应对方案。
3.3 基线告警任务拆解
数据血缘链路长,基线治理的时候,问题错综复杂不知道如何定位。可以从以下几个方面进行问题拆解。
(1)产出延迟任务:确定破线/预警基线,可以通过任务元数据找到告警基线任务中 【实际结束时间-开始运行】差值最大的(可能发生了数据倾斜),排查是依赖了部分晚产出(1-3小时运行时长)的数据导致基线破线(通过数据血缘查看表的依赖链路),解决方式可以将任务切换为t-2数据(将 t-2的数据回填到t-1)使得数据能够交付给下游。
(2)链路过长导致产出延迟:梳理表的上下游依赖关系。从ADS回溯到DWD(明细层)或者从ODS向下游逐层定位问题。这期间可能存在指标重复加工或者数据表反复依赖的问题(DWS依赖DWS依赖DWS,同层级的代码耦合性过高)。通常情况下,是ADS指标被反复依赖导致加工链路过长,需要将公共逻辑的ADS指标下沉到DWS层(下沉的前提,指标的数据粒度是一样的),提高指标的复用性。也可以建设ADS核心指标/标签宽表,减少重复依赖问题,缩短数据加工的流转链路。
(3)高优先级基线调度时间重叠:通过任务元数据梳理同时间运行的节点任务,根据当前资源消耗波动,把重叠基线调度时间提前,进行削峰填谷,充分使用其他闲置时间资源。例如下图资源使用趋势,发现核心任务集中在4点附近,可以将任务调整至0-2点,提高资源利用率。
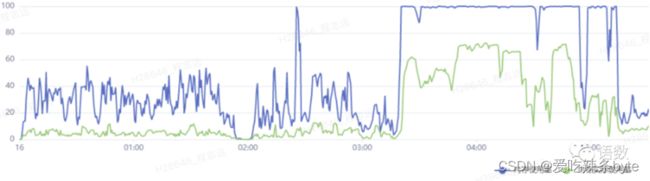
除了观察资源使用趋势图,也可以线下执行节点任务(不要在基线或者任务流上跑),一般是任务资源的抢夺或者基线的分配不合理,导致任务无法按时产出,此时需要对此任务进行重调度。
(4) 任务失败导致告警:通常是代码提交未审核就上线(多半问题是没配依赖,表元数据字段数与逻辑代码中的字段数不一致等情况),需要设置代码审核流程及模型评审机制,降低基础问题的发生。此外针对OOM任务(内存溢出),需要重新分配资源(core核数、memory内存、并行度等)。
(5) 通过wiki维护值班进度,找出常出现的问题,形成解决步骤,例如看到基线告警可以快速定位到预警原因,方便夜间值班同学能在夜间犯困情况下及时翻阅手册通过夜间值班培训处理好基线问题,降低出错频率。(夜间值班运维记录图)

四、数据质量治理评估
主要评估质量治理对于数仓内部价值,对下游而言,完善的质量治理措施可以保障数据问题更少,任务产出更稳定、取数更及时。一般可量化的指标如下:
(1)对业务方提来的BUG进行归纳梳理,提炼共通性高频问题,重构数仓开发及代码审核流程。加强数仓团队数据质量理念,制定奖惩措施,数仓侧原有bug从每月xx个,降低至每月xx内个。
(2)对DQC及任务治理系统化治理,实现自动化DQC识别,夜间值班同学起夜率降低至xx%。
(3)通过对基线/SLA治理,以及制定夜间值班培训及手册,可以保障核心任务按时产出,原每周 x天不能准时产出的任务可以降低至 <= x天。
五、数据质量治理思考
数据质量治理核心在于数据交付下游更稳定、及时、准确,降低组内运维(基线/SLA破线)发生的频率。除了如上保障手段,后续可借助AI对线上任务运行进行全面诊断、基线诊断,辅助数仓同学快速定位当前错综复杂问题。
待补充~