Linux 增加 SWAP 空间
一、需求
通过阿里云启动项目时,使用Vuepress build编译静态页面时内存需要800MB,导致内存不够,因此考虑使用swap方式,置换一些内存资源存放swap磁盘。
[root@xxx myblog]# npm run docs:dev
> myblog@1.0.0 docs:dev
> vuepress dev docs
wait Extracting site metadata...
tip Apply theme @vuepress/theme-default ...
warning Invalid value for "plugin": expected a String, Function or Object but got Array.
warning An error was encountered in plugin "@vuepress/back-to-top"
tip Apply plugin container (i.e. "vuepress-plugin-container") ...
tip Apply plugin @vuepress/register-components (i.e. "@vuepress/plugin-register-components") ...
tip Apply plugin @vuepress/active-header-links (i.e. "@vuepress/plugin-active-header-links") ...
tip Apply plugin @vuepress/search (i.e. "@vuepress/plugin-search") ...
tip Apply plugin @vuepress/nprogress (i.e. "@vuepress/plugin-nprogress") ...
tip Apply plugin copyright (i.e. "vuepress-plugin-copyright") ...
tip Apply plugin sitemap (i.e. "vuepress-plugin-sitemap") ...
tip Apply plugin baidu-autopush (i.e. "vuepress-plugin-baidu-autopush") ...
tip Apply plugin @vuepress/medium-zoom (i.e. "@vuepress/plugin-medium-zoom") ...
tip Apply plugin img-lazy (i.e. "vuepress-plugin-img-lazy") ...
tip Apply plugin @vssue/vssue (i.e. "@vssue/vuepress-plugin-vssue") ...
tip Apply plugin one-click-copy (i.e. "vuepress-plugin-one-click-copy") ...
● Client █████████████████████████ building (68%) 2689/2748 modules 59 active
url-loader › docs/blogs/interview/image/java/link.png
ℹ 「wds」: Project is running at http://0.0.0.0:8080/
ℹ 「wds」: webpack output is served from /
ℹ 「wds」: Content not from webpack is served from /root/project/myblog/docs/.vuepress/public
ℹ 「wds」: 404s will fallback to /index.html
Language does not exist: c++
Language does not exist: c++
Language does not exist: c++
Language does not exist: c++
Killed
swap分区是Linux操作系统中的一种虚拟化内存技术,将硬盘空间作为内存使用。由于内存和磁盘的读写性能差异较大,Linux会在内存充裕时将空闲内存用于缓存磁盘数据,以提高I/O性能。相对的在内存紧张时Linux会将这些缓存回收,将脏页回写到磁盘中。而在进程的地址空间中,如heap,stack等匿名页,在磁盘上并没有对应的文件,但同样有回收到磁盘上以释放出空闲内存的需求。swap机制通过在磁盘上开辟专用的swap分区作为匿名页的backing storage,满足了这一需求。
在Linux上可以使用swapon -s命令查看当前系统上正在使用的交换空间有哪些,以及相关信息:
[root@xxx myblog]# swapon
NAME TYPE SIZE USED PRIO
/etc/swap file 2G 677.9M -2
二、SWAP 创建
Linux支持两种形式的swap分区: 使用分区空间swap disk和使用分区文件swap file。前者是一个专用于做swap的块设备,作为裸设备提供给swap机制操作;后者则是存放在文件系统上的一个特定文件,其实现依赖于不同的文件系统,会有所区别。
分区文件swap file
【1】创建swap文件
[root@xxx myblog]# fallocate -l 2G /etc/swap #指定文件为2G
【2】设置该文件为swap文件
[root@xxx myblog]# mkswap /etc/swap
Setting up swapspace version 1, size = 2097148 KiB
no label, UUID=5b9e4232-dad5-4dbd-9805-f2296452e6f8
【3】启动swap文件
[root@xxx myblog]# swapon /etc/swap
swapon: /etc/swap: insecure permissions 0644, 0600 suggested.
【4】使swap文件永久生效
vim /etc/fstab
【5】在fstab末尾添加如下内容
/etc/swap swap swap defaults 0 0
【6】更改swap配置
vim /etc/sysctl.conf
【7】添加如下内容:值越大表示越倾向于使用swap空间
vm.swappiness=30
【8】重启生效
init 6
分区空间swap disk
【1】创建分区:并设置为swap格式
fdisk /dev/sdb
| 参数 | 说明 |
|---|---|
| n | 创建分区 |
| p | 创建主分区 |
| 1 | 创建分区1 |
| 两次回车 | 起始扇区和Last扇区选择默认 |
| t | 转换分区格式 |
| 82 | 转换为swap空间 |
| p | 查看已创建的分区结果 |
| w | 保存退出 |
【2】格式化为swap空间 |
mkswap /dev/sdb1
【3】启用swap
swapon /dev/sdb1
【4】编辑配置文件,设为开机自动挂载
vim /etc/fstab
【5】fstab中添加如下内容:
/dev/sdb1 swap swap defaults 0 0
【6】设置自动启用所有swap空间
swapon -a
【7】重启验证
init 6
可通过swapon和swapoff命令开启或关闭对应的swap分区。通过cat /proc/swaps或swapon -s可以查看使用中的swap分区的状态。
[root@xxx myblog]# swapon -s
Filename Type Size Used Priority
/etc/swap file 2097148 678772 -2
移除交换(Swap)文件
通过以下命令来移除交换Swap文件,或者通过命令删除/etc/fstab中的交换文件
[root@xxx]# sudo swapoff -v /swapfile
三、整Swappiness值
Swappiness是Linux内核的一个属性,用于定义交换空间的使用频率。如您所知,RAM比硬盘驱动器快。因此,每次您需要使用交换时,您都会注意到某些进程和应用程序运行速度会变慢。但是,您可以调整系统以使用比交换更多的RAM。这有助于提高整体系统性能。通常,默认的swappiness值为30。此值越小,将使用的RAM越多。
要验证swappiness值,请运行以下命令:
[root@xxxx ~]# cat /proc/sys/vm/swappiness
30
如果想要修改swappiness的值,可以编辑/etc/sysctl.conf文件。并添加以下以下内容。
vm.swappiness=20
为了应用更改,则需要重新启动系统。这样Linux内核将使用更多的RAM和更少的交换,但是当你的RAM内存严重满时它仍然会交换。通常,当您的RAM超过4Gb时,建议使用此设置。
四、页面回收机制
Linux触发页面回收有三种情况:
【1】直接回收:alloc_pages()分配物理页,内存紧缺时,会陷入回收机制,同步触发;
【2】周期性回收:当系统内存触发低水位时,唤醒kswapd线程,异步回收内存;
【3】slab收割机制:当内存紧缺时,直接回收,周期性回收,都会调用slab收割机回收,不过这里是内核的内存分配;
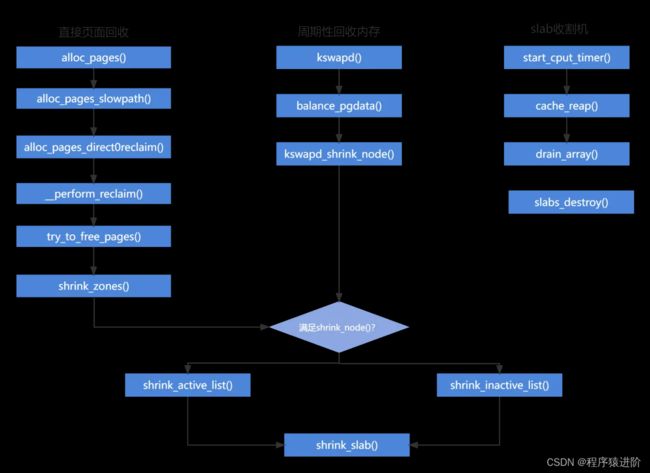
kswapd_wait等待队列: 等待队列用于使进程等待某一事件发生,而无需频繁轮询,进程在等待期间睡眠。在某事件发生时,由内核自动唤醒。
setup_arch()-->
paging_init()-->
bootmem_init()->
zone_sizes_init()-->
free_area_init_node()-->
free_area_init_core()
kswapd_wait等待队列在free_area_init_core中进行初始化,每个内存节点一个。kswapd内核线程在kswapd_wait等待队列上等待TASK_INTERRUPTIBLE事件发生。
static void __paginginit free_area_init_core(struct pglist_data *pgdat,
unsigned long node_start_pfn, unsigned long node_end_pfn,
unsigned long *zones_size, unsigned long *zholes_size)
{
...
init_waitqueue_head(&pgdat->kswapd_wait);
init_waitqueue_head(&pgdat->pfmemalloc_wait);
pgdat_page_ext_init(pgdat);
...
}
kswapd内核线程: kswapd内核线程负责在内存不足的情况下进行页面回收,为每NUMA内存节点创建一个kswap%d的内核线程。其中kswapd函数是内核线程kswapd的入口。
/*
* 一个pglist_data,对应一个内存节点,是最顶层的内存管理数据结构
* 主要包括三部分:
* 1.描述zone
* 2.描述内存节点的信息;
* 3.和页面回收相关;
*/
typedef struct pglist_data {
int node_id;
wait_queue_head_t kswapd_wait;
struct task_struct *kswapd; /* Protected by
mem_hotplug_begin/end() */
int kswapd_order;
enum zone_type kswapd_highest_zoneidx;
struct lruvec __lruvec; ///lru链表向量(包括所有,5种lru链表)
} pg_data_t;
wakeup_kswapd唤醒kswaped内核线程: 分配内存路径上的唤醒函数wakeup_kswapd把kswapd_order和kswapd_highest_zoneidx作为参数传递给kswaped内核线程;
alloc_page()->
__alloc_pages_nodemask()->
__alloc_pages_slowpth()->
wake_all_kswapds()->
wakeup_kswapd()
void wakeup_kswapd(struct zone *zone, gfp_t gfp_flags, int order,
enum zone_type highest_zoneidx)
{
pg_data_t *pgdat;
enum zone_type curr_idx;
if (!managed_zone(zone))
return;
if (!cpuset_zone_allowed(zone, gfp_flags))
return;
pgdat = zone->zone_pgdat;
///准备本内存节点的kswapd_order和kswapd_highest_zoneidx
curr_idx = READ_ONCE(pgdat->kswapd_highest_zoneidx);
if (curr_idx == MAX_NR_ZONES || curr_idx < highest_zoneidx)
WRITE_ONCE(pgdat->kswapd_highest_zoneidx, highest_zoneidx);
if (READ_ONCE(pgdat->kswapd_order) < order)
WRITE_ONCE(pgdat->kswapd_order, order);
if (!waitqueue_active(&pgdat->kswapd_wait))
return;
/* Hopeless node, leave it to direct reclaim if possible */
if (pgdat->kswapd_failures >= MAX_RECLAIM_RETRIES ||
(pgdat_balanced(pgdat, order, highest_zoneidx) &&
!pgdat_watermark_boosted(pgdat, highest_zoneidx))) {
/*
* There may be plenty of free memory available, but it's too
* fragmented for high-order allocations. Wake up kcompactd
* and rely on compaction_suitable() to determine if it's
* needed. If it fails, it will defer subsequent attempts to
* ratelimit its work.
*/
if (!(gfp_flags & __GFP_DIRECT_RECLAIM))
wakeup_kcompactd(pgdat, order, highest_zoneidx);
return;
}
trace_mm_vmscan_wakeup_kswapd(pgdat->node_id, highest_zoneidx, order,
gfp_flags);
///唤醒kswapd_wait队列
wake_up_interruptible(&pgdat->kswapd_wait);
}
回收函数kswapd
static int kswapd(void *p)
{
...
///PF_MEMALLOC允许使用系统预留内存,即不考虑水位
tsk->flags |= PF_MEMALLOC | PF_SWAPWRITE | PF_KSWAPD;
for ( ; ; ) {
bool ret;
///回收页面数量,2的order次幂
alloc_order = reclaim_order = READ_ONCE(pgdat->kswapd_order);
///classzone_idx内核线程扫描和回收的最高zone
highest_zoneidx = kswapd_highest_zoneidx(pgdat,
highest_zoneidx);
kswapd_try_sleep:
///睡眠,等待wakeup_kswapd唤醒
kswapd_try_to_sleep(pgdat, alloc_order, reclaim_order,
highest_zoneidx);
...
reclaim_order = balance_pgdat(pgdat, alloc_order,
highest_zoneidx);
if (reclaim_order < alloc_order)
goto kswapd_try_sleep;
}
tsk->flags &= ~(PF_MEMALLOC | PF_SWAPWRITE | PF_KSWAPD);
return 0;
}
kswapd内核线程扫描过程: kswapd()->balance_pgdat()
/*****************************************************************************
* 回收页面的主函数:
*
* highmem->normal->dma, 从高端往低端方向,查找处于不平衡状态,
* 即free_pages <= high_wmark_pagesend_zone的zone
*
*
****************************************************************************/
static int balance_pgdat(pg_data_t *pgdat, int order, int highest_zoneidx)
{
///用于内存碎片化
unsigned long nr_boost_reclaim;
...
nr_boost_reclaim = 0;
for (i = 0; i <= highest_zoneidx; i++) {
zone = pgdat->node_zones + i;
if (!managed_zone(zone))
continue;
nr_boost_reclaim += zone->watermark_boost;
zone_boosts[i] = zone->watermark_boost;
}
boosted = nr_boost_reclaim;
restart:
sc.priority = DEF_PRIORITY;
do {
...
///检查这个节点中是否有合格的zone,其水位高于高水位且能分配2的sc.order次幂个连续的物理页面
balanced = pgdat_balanced(pgdat, sc.order, highest_zoneidx);
///若所有zone都不合格,关闭nr_boost_reclaim,重新检查一次
if (!balanced && nr_boost_reclaim) {
nr_boost_reclaim = 0;
goto restart;
}
//若符合条件,不需要回收,直接跳出
if (!nr_boost_reclaim && balanced)
goto out;
...
///老化匿名页面的活跃链表
age_active_anon(pgdat, &sc);
...
///真正扫描和页回收函数,扫描的参数和结果存放在struct scan_control中,
///返回true表明回收了所需要的页面,不需要再提高扫描优先级
if (kswapd_shrink_node(pgdat, &sc))
raise_priority = false;
...
///加大扫描粒度
if (raise_priority || !nr_reclaimed)
sc.priority--;
} while (sc.priority >= 1);
...
out:
/* If reclaim was boosted, account for the reclaim done in this pass */
///若设置了nr_boost_reclaim,唤醒kcompacted线程
if (boosted) {
...
wakeup_kcompactd(pgdat, pageblock_order, highest_zoneidx);
}
...
return sc.order;
}
对活跃链表中页面的老化:kswapd()->balance_pgdat()->age_active_anon()
///老化匿名页面的活跃链表
static void age_active_anon(struct pglist_data *pgdat,
struct scan_control *sc)
{
struct mem_cgroup *memcg;
struct lruvec *lruvec;
if (!total_swap_pages)
return;
lruvec = mem_cgroup_lruvec(NULL, pgdat);
if (!inactive_is_low(lruvec, LRU_INACTIVE_ANON))
return;
memcg = mem_cgroup_iter(NULL, NULL, NULL);
do {
lruvec = mem_cgroup_lruvec(memcg, pgdat);
shrink_active_list(SWAP_CLUSTER_MAX, lruvec,
sc, LRU_ACTIVE_ANON);
memcg = mem_cgroup_iter(NULL, memcg, NULL);
} while (memcg);
}
执行回收:kswapd()->balance_pgdat()->kswapd_shrink_node()->shrink_node()->shrink_node_memcgs()
static void shrink_node_memcgs(pg_data_t *pgdat, struct scan_control *sc)
{
struct mem_cgroup *target_memcg = sc->target_mem_cgroup;
struct mem_cgroup *memcg;
memcg = mem_cgroup_iter(target_memcg, NULL, NULL);
do {
///获取LRU链表的集合
struct lruvec *lruvec = mem_cgroup_lruvec(memcg, pgdat);
unsigned long reclaimed;
unsigned long scanned;
/*
* This loop can become CPU-bound when target memcgs
* aren't eligible for reclaim - either because they
* don't have any reclaimable pages, or because their
* memory is explicitly protected. Avoid soft lockups.
*/
cond_resched();
mem_cgroup_calculate_protection(target_memcg, memcg);
if (mem_cgroup_below_min(memcg)) {
/*
* Hard protection.
* If there is no reclaimable memory, OOM.
*/
continue;
} else if (mem_cgroup_below_low(memcg)) {
/*
* Soft protection.
* Respect the protection only as long as
* there is an unprotected supply
* of reclaimable memory from other cgroups.
*/
if (!sc->memcg_low_reclaim) {
sc->memcg_low_skipped = 1;
continue;
}
memcg_memory_event(memcg, MEMCG_LOW);
}
reclaimed = sc->nr_reclaimed;
scanned = sc->nr_scanned;
///扫描回收lru链表
shrink_lruvec(lruvec, sc);
///扫描回收slab链表
shrink_slab(sc->gfp_mask, pgdat->node_id, memcg,
sc->priority);
/* Record the group's reclaim efficiency */
vmpressure(sc->gfp_mask, memcg, false,
sc->nr_scanned - scanned,
sc->nr_reclaimed - reclaimed);
} while ((memcg = mem_cgroup_iter(target_memcg, memcg, NULL)));
}
回收函数shrink_lruvec()
static void shrink_lruvec(struct lruvec *lruvec, struct scan_control *sc)
{
unsigned long nr[NR_LRU_LISTS];
unsigned long targets[NR_LRU_LISTS];
unsigned long nr_to_scan;
enum lru_list lru;
unsigned long nr_reclaimed = 0;
unsigned long nr_to_reclaim = sc->nr_to_reclaim;
struct blk_plug plug;
bool scan_adjusted;
///计算每个链表应该扫描的页面数量,结果放在nr[]
get_scan_count(lruvec, sc, nr);
///全局回收,优化当内存紧缺时,触发直接回收
scan_adjusted = (!cgroup_reclaim(sc) && !current_is_kswapd() &&
sc->priority == DEF_PRIORITY);
///遍历所有链表,回收页面
///主要处理不活跃匿名页面,活跃文件映射页面和不活跃文件映射页面
while (nr[LRU_INACTIVE_ANON] || nr[LRU_ACTIVE_FILE] ||
nr[LRU_INACTIVE_FILE]) {
unsigned long nr_anon, nr_file, percentage;
unsigned long nr_scanned;
for_each_evictable_lru(lru) {
if (nr[lru]) {
nr_to_scan = min(nr[lru], SWAP_CLUSTER_MAX);
nr[lru] -= nr_to_scan;
//扫描链表,回收页面,返回成功回收的页面数量
nr_reclaimed += shrink_list(lru, nr_to_scan,
lruvec, sc);
}
}
cond_resched();
///没完成回收任务,或设置了scan_adjusted,继续进行页面扫描
if (nr_reclaimed < nr_to_reclaim || scan_adjusted)
continue;
...
scan_adjusted = true;
}
blk_finish_plug(&plug);
sc->nr_reclaimed += nr_reclaimed;
///老化活跃链表
///如果不活跃链表页面数量太少,从活跃链表迁移一部分页面到不活跃链表
if (total_swap_pages && inactive_is_low(lruvec, LRU_INACTIVE_ANON))
shrink_active_list(SWAP_CLUSTER_MAX, lruvec,
sc, LRU_ACTIVE_ANON);
}
shrink_lruvec()->shrink_list()
static unsigned long shrink_list(enum lru_list lru, unsigned long nr_to_scan,
struct lruvec *lruvec, struct scan_control *sc)
{
if (is_active_lru(lru)) {
///扫描活跃的文件映射链表
if (sc->may_deactivate & (1 << is_file_lru(lru)))
shrink_active_list(nr_to_scan, lruvec, sc, lru);
else
sc->skipped_deactivate = 1;
return 0;
}
///扫描不活跃链表
return shrink_inactive_list(nr_to_scan, lruvec, sc, lru);
}
扫描活跃链表函数shrink_active_list()实现:
/*************************************************************************************
* func:扫描活跃链表,包括匿名页或文件映射页面,
* 把最近没访问的页面,从活跃链表尾部移到不活跃链表头部
* nr_to_scan: 待扫描页面的数量
* lruvec:LRU链表集合
* sc:页面扫描控制参数
* lru: 待扫描的LRU链表类型
*************************************************************************************/
static void shrink_active_list(unsigned long nr_to_scan,
struct lruvec *lruvec,
struct scan_control *sc,
enum lru_list lru)
{
unsigned long nr_taken;
unsigned long nr_scanned;
unsigned long vm_flags;
///定义三个临时链表
LIST_HEAD(l_hold); /* The pages which were snipped off */
LIST_HEAD(l_active);
LIST_HEAD(l_inactive);
struct page *page;
unsigned nr_deactivate, nr_activate;
unsigned nr_rotated = 0;
///判断是否为文件映射链表
int file = is_file_lru(lru);
///获取内存节点
struct pglist_data *pgdat = lruvec_pgdat(lruvec);
lru_add_drain();
spin_lock_irq(&lruvec->lru_lock);
///将页面批量迁移到临时链表l_hold中
nr_taken = isolate_lru_pages(nr_to_scan, lruvec, &l_hold,
&nr_scanned, sc, lru);
///增加内存节点NR_ISOLATED_ANON计数
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, nr_taken);
if (!cgroup_reclaim(sc))
__count_vm_events(PGREFILL, nr_scanned);
__count_memcg_events(lruvec_memcg(lruvec), PGREFILL, nr_scanned);
spin_unlock_irq(&lruvec->lru_lock);
///扫描临时链表l_hold,有些页面放到不活跃链表,有些会放回到活跃链表
while (!list_empty(&l_hold)) {
cond_resched();
page = lru_to_page(&l_hold);
list_del(&page->lru);
///如果不能回收,放入不能回收链表
if (unlikely(!page_evictable(page))) {
putback_lru_page(page);
continue;
}
if (unlikely(buffer_heads_over_limit)) {
if (page_has_private(page) && trylock_page(page)) {
if (page_has_private(page))
try_to_release_page(page, 0);
unlock_page(page);
}
}
///page_referenced()返回该页面最近访问,应用pte个数,若返回0,表示最近没访问
if (page_referenced(page, 0, sc->target_mem_cgroup,
&vm_flags)) {
/*
* Identify referenced, file-backed active pages and
* give them one more trip around the active list. So
* that executable code get better chances to stay in
* memory under moderate memory pressure. Anon pages
* are not likely to be evicted by use-once streaming
* IO, plus JVM can create lots of anon VM_EXEC pages,
* so we ignore them here.
*/
if ((vm_flags & VM_EXEC) && page_is_file_lru(page)) {
nr_rotated += thp_nr_pages(page);
///放回活跃链表
list_add(&page->lru, &l_active);
continue;
}
}
ClearPageActive(page); /* we are de-activating */
SetPageWorkingset(page);
///加入不活跃链表
list_add(&page->lru, &l_inactive);
}
/*
* Move pages back to the lru list.
*/
spin_lock_irq(&lruvec->lru_lock);
///将l_active,l_inactive分别加入到相应的链表
nr_activate = move_pages_to_lru(lruvec, &l_active);
nr_deactivate = move_pages_to_lru(lruvec, &l_inactive);
/* Keep all free pages in l_active list */
list_splice(&l_inactive, &l_active);
__count_vm_events(PGDEACTIVATE, nr_deactivate);
__count_memcg_events(lruvec_memcg(lruvec), PGDEACTIVATE, nr_deactivate);
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, -nr_taken);
spin_unlock_irq(&lruvec->lru_lock);
mem_cgroup_uncharge_list(&l_active);
free_unref_page_list(&l_active);
trace_mm_vmscan_lru_shrink_active(pgdat->node_id, nr_taken, nr_activate,
nr_deactivate, nr_rotated, sc->priority, file);
}
扫描不活跃链表shrink_inactive_list()实现:
///扫描不活跃LRU链表,尝试回收页面,返回已经回收的页面数量
static noinline_for_stack unsigned long
shrink_inactive_list(unsigned long nr_to_scan, struct lruvec *lruvec,
struct scan_control *sc, enum lru_list lru)
{
LIST_HEAD(page_list);
unsigned long nr_scanned;
unsigned int nr_reclaimed = 0;
unsigned long nr_taken;
struct reclaim_stat stat;
bool file = is_file_lru(lru);
enum vm_event_item item;
struct pglist_data *pgdat = lruvec_pgdat(lruvec);
bool stalled = false;
while (unlikely(too_many_isolated(pgdat, file, sc))) {
if (stalled)
return 0;
/* wait a bit for the reclaimer. */
///太多进程在直接回收页面,睡眠,避免内存抖动
msleep(100);
stalled = true;
/* We are about to die and free our memory. Return now. */
if (fatal_signal_pending(current))
return SWAP_CLUSTER_MAX;
}
lru_add_drain();
spin_lock_irq(&lruvec->lru_lock);
///分离页面到临时页表
nr_taken = isolate_lru_pages(nr_to_scan, lruvec, &page_list,
&nr_scanned, sc, lru);
///增加内存节点NR_ISOLATED_ANON计数
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, nr_taken);
item = current_is_kswapd() ? PGSCAN_KSWAPD : PGSCAN_DIRECT;
if (!cgroup_reclaim(sc))
__count_vm_events(item, nr_scanned);
__count_memcg_events(lruvec_memcg(lruvec), item, nr_scanned);
__count_vm_events(PGSCAN_ANON + file, nr_scanned);
spin_unlock_irq(&lruvec->lru_lock);
if (nr_taken == 0)
return 0;
///执行回收页面,返回nr_reclaimed个
nr_reclaimed = shrink_page_list(&page_list, pgdat, sc, &stat, false);
spin_lock_irq(&lruvec->lru_lock);
///page_list链表剩余页面迁回不活跃链表
move_pages_to_lru(lruvec, &page_list);
///减少NR_ISOLATED_ANON计数
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, -nr_taken);
item = current_is_kswapd() ? PGSTEAL_KSWAPD : PGSTEAL_DIRECT;
if (!cgroup_reclaim(sc))
__count_vm_events(item, nr_reclaimed);
__count_memcg_events(lruvec_memcg(lruvec), item, nr_reclaimed);
__count_vm_events(PGSTEAL_ANON + file, nr_reclaimed);
spin_unlock_irq(&lruvec->lru_lock);
lru_note_cost(lruvec, file, stat.nr_pageout);
mem_cgroup_uncharge_list(&page_list);
free_unref_page_list(&page_list);
/*
* If dirty pages are scanned that are not queued for IO, it
* implies that flushers are not doing their job. This can
* happen when memory pressure pushes dirty pages to the end of
* the LRU before the dirty limits are breached and the dirty
* data has expired. It can also happen when the proportion of
* dirty pages grows not through writes but through memory
* pressure reclaiming all the clean cache. And in some cases,
* the flushers simply cannot keep up with the allocation
* rate. Nudge the flusher threads in case they are asleep.
*/
if (stat.nr_unqueued_dirty == nr_taken)
wakeup_flusher_threads(WB_REASON_VMSCAN);
sc->nr.dirty += stat.nr_dirty;
sc->nr.congested += stat.nr_congested;
sc->nr.unqueued_dirty += stat.nr_unqueued_dirty;
sc->nr.writeback += stat.nr_writeback;
sc->nr.immediate += stat.nr_immediate;
sc->nr.taken += nr_taken;
if (file)
sc->nr.file_taken += nr_taken;
trace_mm_vmscan_lru_shrink_inactive(pgdat->node_id,
nr_scanned, nr_reclaimed, &stat, sc->priority, file);
return nr_reclaimed;
}