【微服务】springboot集成ELK使用详解
目录
一、前言
二、为什么需要ELK
三、ELK介绍
3.1 什么是elk
3.2 elk工作原理
四、ELK环境搭建
4.1 搭建es环境
4.1.1 获取es镜像
4.1.2 启动es容器
2.1.3 配置es参数
2.1.4 重启es容器并访问
4.2 搭建kibana
4.2.1 拉取kibana镜像
4.2.2 启动kibana容器
4.2.3 修改配置文件
4.2.4 重启容器并访问
4.3 搭建logstash
4.3.1 下载安装包
4.3.2 解压安装包
4.3.3 新增配置logstash文件
五、SpringBoot集成ELK
5.1 集成过程
5.1.1 创建springboot工程
5.1.2 导入依赖
5.1.3 配置logback日志
5.1.4 增加测试接口
5.2 效果演示
5.2.1 启动服务工程
5.2.2 配置索引模式
5.2.3 调用接口验证效果
5.3 ELK使用补充
六、写在文末
一、前言
对于一个运行中的应用来说,线上排查问题是一件很头疼的问题。不管是springboot单应用,还是springcloud微服务应用,一旦在生产环境出了问题,大多数人第一反应就是赶紧去看日志查问题。如何查呢?如果是管理不那么严格的项目,允许你登录生产服务器通过命令去查,或者将生产的日志down下来去查。但为了服务器安全,一般来说是不允许研发人员随便接触服务器,会有运维人员去操作日志,这样以来就极大的影响了排查的效率,这时候会有人说,如果有可视化的操作,能可视化检索日志的界面就好了。
二、为什么需要ELK
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。一个完整的集中式日志系统,需要包含以下几个主要特点:
- 收集-能够采集多种来源的;
- 传输-能够稳定的把日志数据传输到中央系统;
- 存储-如何存储日志数据;
- 分析-可以支持 UI 分析;
- 警告-能够提供错误报告,监控机制;
基于上述的需求,业界很多公司在不断探索过程中,经过多年实践经验,最终形成了以ELK为主流的一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用,是目前主流的一种日志系统。
三、ELK介绍
3.1 什么是elk
ELK其实并不是某一款软件,而是一套完整的解决方案,是三个产品的首字母缩写,即:
- Elasticsearch;
- Logstash ;
- Kibana;
这三个软件都是开源软件,通常配合使用,而且又先后归于 Elastic.co 公司名下,故被简称为ELK协议栈,具体来说:
Elasticsearch
是一个分布式的搜索和分析引擎,可以用于全文检索、结构化检索和分析,并能将这三者结合起来。Elasticsearch 基于 Lucene 开发,现在是使用最广的开源搜索引擎之一。
Logstash
简单来说就是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端,与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供了很多功能强大的滤网以满足你的各种应用场景。
Kibana
是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看、交互存放在Elasticsearch索引里的数据,使用各种不同的图标、表格、地图等,kibana能够很轻易的展示高级数据分析与可视化。
3.2 elk工作原理
如下是elk实际工作时的原理图,还是很容易理解的
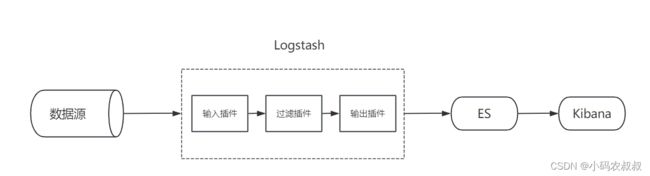
Logstash的存在,让数据可视化的展示成为很多需要做日志类数据展示不可或缺的组件,比如数据源可以是静态的日志文件,也可以是mysql,或来自于kafka的topic消息数据等。
四、ELK环境搭建
下面演示如何搭建elk,网上的参考资料比较丰富,本文采用docker快速搭建起elk的演示环境,参考下面的步骤。
4.1 搭建es环境
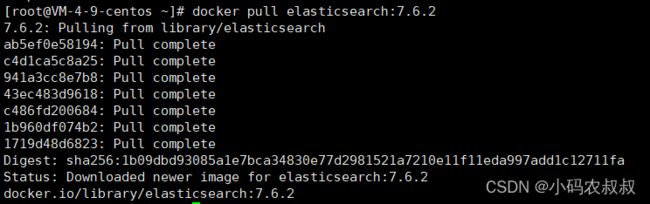
4.1.1 获取es镜像
版本可以根据自身的情况选择,我这里使用的是7.6的版本
docker pull elasticsearch:7.6.2
4.1.2 启动es容器
使用下面的命令启动es容器,注意这个配置,ES_JAVA_OPTS="-Xms512m -Xmx512m",这个配置参数值根据你的服务器配置决定,一般最好不要低于512m即可;
docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms512m -Xmx512m" --name es76 -d elasticsearch:7.6.2
2.1.3 配置es参数
进入到es容器内部,然后找到下面的这个文件
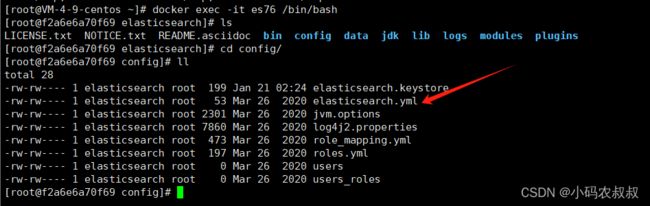
然后将下面的配置参数配置进去
cluster.name: "docker-cluster"
http.cors.enabled: true
network.host: 0.0.0.0
http.port: 9200
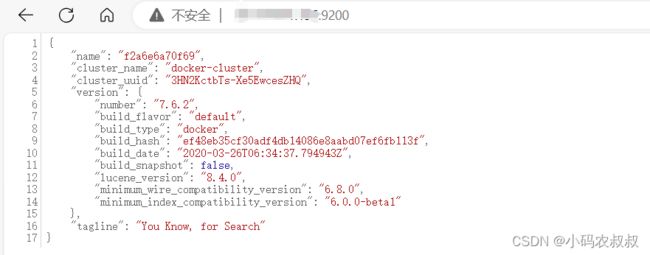
http.cors.allow-origin: "*"2.1.4 重启es容器并访问
配置完成后重启docker容器,重启成功后,开放9200端口,然后浏览器访问,IP:9200,看到如下信息,说明es可以正常使用。
4.2 搭建kibana
4.2.1 拉取kibana镜像
为了减少后面的配置麻烦和一些问题,建议kibana版本与es版本一致
docker pull kibana:7.6.2
4.2.2 启动kibana容器
这里的IP地址,如果是云服务器,注意使用内网的IP地址
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://es服务IP:9200 -p 5601:5601 -d kibana:7.6.2
4.2.3 修改配置文件
进入到kibana容器中,进入到下面的目录中
cd /usr/share/kibana/config
vi kibana.yml 
将如下的配置信息配置进去(es的IP地址如果是云服务器建议使用内网IP)
server.name: kibana
server.host: "0"
elasticsearch.hosts: [ "http://es服务IP:9200" ]
xpack.monitoring.ui.container.elasticsearch.enabled: true
i18n.locale: zh-CN
4.2.4 重启容器并访问
上述配置信息配置完成后,重启容器,开放5601端口,浏览器就可以直接访问,IP:5601,看到下面的效果说明kibana可以正常使用了

4.3 搭建logstash
4.3.1 下载安装包
logstash的版本建议不要与es版本差别太多即可
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.1.0.tar.gz
4.3.2 解压安装包
tar -zxvf logstash-7.1.0.tar.gz
4.3.3 新增配置logstash文件
进入logstash-7.1.0目录下,创建一个目录,用于保存自定义的配置文件,注意提前开发4560端口
cd cd logstash-7.1.0/
mkdir log-conf
vi logstash.conf
然后添加下面的配置信息
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 4560
codec => json
}
}
output {
elasticsearch {
hosts => "es公网地址:9200"
index => "springboot-logstash-%{+YYYY.MM.dd}"
},
stdout { codec => rubydebug }
}在主目录下,使用下面的命令进行启动
./bin/logstash -f ./log-conf/logstash.conf看到下面的输出日志,说明当前logstash服务已经开始工作,准备接收输入日志了
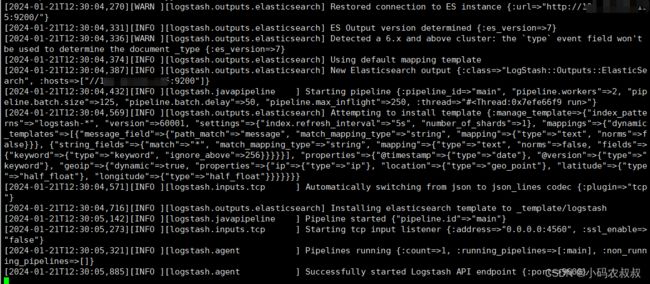
五、SpringBoot集成ELK
5.1 集成过程
参考下面的过程在springboot中快速集成elk,如果是dubbo或者springcloud项目,集成步骤也差不多
5.1.1 创建springboot工程
项目目录下

5.1.2 导入依赖
根据需要引入依赖,如果是集成elk,还需要引入下面这个
net.logstash.logback
logstash-logback-encoder
5.3
5.1.3 配置logback日志
springboot集成elk最关键的就是配置logback日志文件,需要按照一定的格式规范进行配置,才能将运行过程中产生的日志上报到logstash,然后经过转换输送到es,最后展现在kibana中,参考下面的配置信息,以下两种配置方式都可以;
方式一:
%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n
INFO
logstash地址:4560
Asia/Shanghai
{
"project": "elk",
"level": "%level",
"service": "${springApplicationName:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger",
"message": "%message",
"stack_trace": "%exception"
}
方式二:
%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n
logstash地址:4560
{"appname": "${springApplicationName}"}
5.1.4 增加测试接口
为了后续方便观察效果,增加两个测试接口,一个模拟正常的调用,另一个模拟异常调用
@RestController
@RequestMapping("/user")
@Slf4j
public class UserController {
@Autowired
private UserService userService;
//http://localhost:8088/user/get?userId=001
@GetMapping("/get")
public Object getUserInfo(String userId){
log.info("getUserInfo userId:【{}】",userId);
Map userInfo = userService.getUserInfo(userId);
return userInfo;
}
//http://localhost:8088/user/error?userId=001
@GetMapping("/error")
public Object error(String userId){
log.info("error userId:【{}】",userId);
Map userInfo = userService.getUserInfo(userId);
int e = 1/0;
return userInfo;
}
}5.2 效果演示
5.2.1 启动服务工程
启动之后,通过下面的在logstash终端的输出日志信息中,可以发现logstash已经接收到程序中上报过来的日志了,并且内部已经按照预定的格式进行了转换;
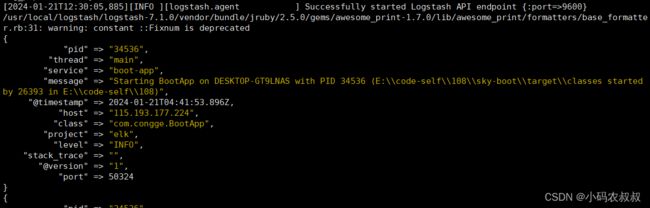
5.2.2 配置索引模式
为了让程序中的日志能够正常展现到es中,由于es是通过接收logstash传输过来的数据,存储到索引中才能通过kibana展现,所以索引的存储格式就很重要,需要提前在kibana上面配置一下索引的展现格式,按照下面的操作步骤配置即可。
在kibana中找到下图模式配置入口

自定义索引的模式,比如这里选择的就是在上面logstash中配置的名称前缀
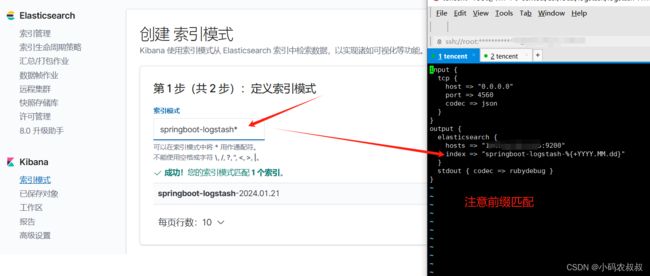
使用时间戳

刷新配置

最后进入到索引查看的栏目就可以看到展示的索引中的日志信息了

5.2.3 调用接口验证效果
依次调用上面的两个测试接口,然后查看kibana中日志的变化
调用正常响应的接口

接口能够正常响应,由于我们在接口方法中添加了一行输出日志信息,通过上面的搜索框,能够在es的日志信息中搜索出来;

调用异常响应接口

接口调用异常后,也能通过kibana快速发现异常信息输出

通过上面的实验和操作体验,可以感受到在springboot中集成elk之后带来的便利,有了可视化的日志展现,提升问题排查效率的同时,也能更好的统一管理日志,并充分发挥日志的作用。
5.3 ELK使用补充
上面完整演示了如何在springboot中快速接入ELK进行日志的可视化展示,如果使用的是springloud或dubbo等技术栈,集成步骤类似,这里结合实际经验,补充下面几点以供参考。
日志切分与清理
展示的日志毕竟是要存储到ES索引中,随着时间的推移,日志文件将会越来越大,索引也将会占用较大的存储空间,如何管理这些源源不断的日志索引呢,给出下面两点建议:
- 原始的日志文件,即logback文件建议按天切分(需要在配置文件中配置策略),这样产生的es索引文件也是按天存储;
- 有了第一步之后,可以通过脚本或者手动的方式定期清理索引;
控制日志输出级别
不建议使用debug级别的日志级别,这样es中存储的日志索引文件会增长的非常快
设置kibana访问密码
生产环境中,日志也是非常重要的数据,在很多公司甚至不会对外开放,而是需要通过授权后才能查看,因此如果是在你的生产环境集成ELK,建议设置kibana的访问账户信息。
六、写在文末
本文详细介绍了如何在springboot中快速接入ELK的过程,ELK可以说在实际项目中具有很好的适用价值,不管是小项目,还是中大型项目,都具备普适参考性,值得深入了解和学习。本篇到此结束,感谢观看。