Redis(六)
1、Redis的缓存淘汰策略
1.1、内存配置
首先查看Redis最大的占用内存,打开redis配置文件,设置maxmemory参数,maxmemory是bytes字节类型,注意转换。

打开配置文件发现没有配置,那么默认是多少的内存,是这样的,如果不设置最大的内存或者最大的内存为零,在64位的操作系统下不限制内存的大小,在32位操作系统下做多使用3G的内存。
那么想配置的话,给redis配置多少呀,一般推荐Redis设置内存为最大物理内存的四分之三,另外配置方式分为两种,一种是直接在配置文件中修改,另外一个种是在客户端种配置数据。
#配置文件
# maxmemory
maxmemory 参数
#客户端
#设置
config set maxmemory 参数
#查看
config get maxmemory 当然想要查看当前的redis内存的使用情况,可以使用以下的命令
#使用
info memory
或者
config get maxmeory如果reids的内存的使用情况超出了设置的最大的内存数量会怎么样?会报错
(error) 00M command not allowed when used memory >'maxmemory'.所以如果设置了内存的最大的数量的话,然后在使用的过程中存储的数据又没有设置过期时间,那么越积越多就会导致存储的数据沾满maxmemory。
1.2、删除策略
1.2.1、立即删除
Redis不可能时时刻刻遍历所有被设置了生存时间的key,来检测数据是否已经到达过期时间,然后对它进行删除。
立即删除能保证内存中数据的最大新鲜度,因为它保证过期键值会在过期后马上被删除,其所占用的内存也会随之释放。但是立即删除对cpu是最不友好的。因为删除操作会占用cpu的时间,如果刚好碰上了cpu很忙的时候,比如正在做交集或排序等计算的时候,就会给cpu造成额外的压力,让CPU心累,时时需要删除,这会产生大量的性能消耗,同时也会影响数据的读取操作。
1.2.2、惰性删除
数据到达过期时间,不做处理。等下次访问该数据时,如果未过期,返回数据 ;发现已过期,删除,返回不存在。
惰性删除策略的缺点是,它对内存是最不友好的。如果一个键已经过期,而这个键又仍然保留在redis中,那么只要这个过期键不被删除,它所占用的内存就不会释放。
在使用惰性删除策略时,如果数据库中有非常多的过期键,而这些过期键又恰好没有被访问到的话,那么它们也许永远也不会被删除(除非用户手动执行FLUSHDB),我们甚至可以将这种情况看作是一种内存泄漏-----无用的垃圾数据占用了大量的内存,而服务器却不会自己去释放它们,这对于运行状态非常依赖于内存的Redis服务器来说,肯定不是一个好消息。
1.2.3、定时删除
定期删除策略每隔一段时间执行一次删除过期键操作并通过限制删除操作执行时长和频率来减少删除操作对CPU时间的影响。
周期性轮询redis库中的时效性数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频度。
-
特点1:CPU性能占用设置有峰值,检测频度可自定义设置
-
特点2:内存压力不是很大,长期占用内存的冷数据会被持续清理
-
总结:周期性抽查存储空间 (随机抽查,重点抽查)
定期删除策略的难点是确定删除操作执行的时长和频率:如果删除操作执行得太频繁或者执行的时间太长,定期删除策略就会退化成立即删除策略,以至于将CPU时间过多地消耗在删除过期键上面。如果删除操作执行得太少,或者执行的时间太短,定期删除策略又会和惰性删除束略一样,出现浪费内存的情况。因此,如果采用定期删除策略的话,服务器必须根据情况,合理地设置删除操作的执行时长和执行频率。
缺点:
-
定期删除时,从来没有被抽查到
-
惰性删除时,也从来没有被点中使用过
1.3、缓存淘汰策略
# volatile-lru -> Evict using approximated LRU, only keys with an expire set.
# allkeys-lru -> Evict any key using approximated LRU.
# volatile-lfu -> Evict using approximated LFU, only keys with an expire set.
# allkeys-lfu -> Evict any key using approximated LFU.
# volatile-random -> Remove a random key having an expire set.
# allkeys-random -> Remove a random key, any key.
# volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
# noeviction -> Don't evict anything, just return an error on write operations.
#
# LRU means Least Recently Used
# LFU means Least Frequently Used
#
# Both LRU, LFU and volatile-ttl are implemented using approximated
# randomized algorithms.1.3.1、lru和lfu算法
LRU:最近最少使用页面置换算法,淘汰最长时间未被使用的页面,看页面最后一次被使用到发生调度的时间长短,首先淘汰最长时间未被使用的页面。
LFU:最近最不常用页面置换算法,淘汰一定时期内被访问次数最少的页,看一定时间段内页面被使用的频率,淘汰一定时期内被访问次数最少的页。
1.3.2、内存淘汰策略
-
noeviction: 不会驱逐任何key,表示即使内存达到上限也不进行置换,所有能引起内存增加的命令都会返回error。
-
allkeys-lru: 对所有key使用LRU算法进行删除,优先删除掉最近最不经常使用的key,用以保存新数据。
-
volatile-lru: 对所有设置了过期时间的key使用LRU算法进行删除。
-
allkeys-random: 对所有key随机删除。
-
volatile-random: 对所有设置了过期时间的key随机删除。
-
volatile-ttl: 删除马上要过期的key。
-
allkeys-lfu: 对所有key使用LFU算法进行删除。
-
volatile-lfu: 对所有设置了过期时间的key使用LFU算法进行删除。
两个方面是针对过期key或者是所有的key,然后有四种策略随机、立即、时间长,次数少。然后根据不同的需求场景选择不同的策略。
-
在所有的 key 都是最近最经常使用,那么就需要选择 allkeys-lru 进行置换最近最不经常使用的key,如果你不确定使用哪种策略,那么推荐使用 allkeys-lru
-
如果所有的 key 的访问概率都是差不多的,那么可以选用 allkeys-random 策略去置换数据
-
如果对数据有足够的了解,能够为 key 指定 hint (通过expire/ttl指定),那么可以选择 volatile-ttl 进行置换
2、跳表
对于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高O(N)

skiplist是一种以空间换取时间的结构。由于链表,无法进行二分查找,因此借鉴数据库索引的思想,提取出链表中关键节点(索引),先在关键节点上查找,再进入下层链表查找,提取多层关键节点,就形成了跳跃表,but由于索引也要占据一定空间的,所以,索引添加的越多,空间占用的越多。
2.1、时间复杂度
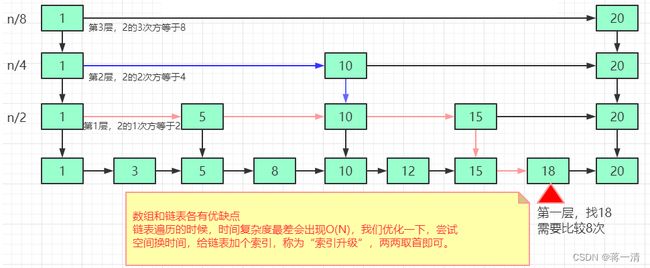
跳表查询的时间复杂度分析,如果链表里有N个结点,会有多少级索引呢?按照我们前面讲的,两两取首。每两个结点会抽出一个结点作为上一级索引的结点,以此估算:
第一级索引的结点个数大约就是n/2,
第二级索引的结点个数大约就是n/4,
第三级索引的结点个数大约就是n/8,依次类推......
也就是说,第k级索引的结点个数是第k-1级索引的结点个数的1/2,那第k级索引结点的个数就是n/(2^k)。时间复杂度就是时间复杂度是O(logN)
2.2、空间复杂度
比起单纯的单链表,跳表需要存储多级索引,肯定要消耗更多的存储空间。那到底需要消耗多少额外的存储空间呢?我们来分析一下跳表的空间复杂度。
第一步:首先原始链表长度为n,
第二步:两两取首,每层索引的结点数:n/2, n/4, n/8 ... , 8, 4, 2 每上升一级就减少一半,直到剩下2个结点,以此类推;如果我们把每层索引的结点数写出来,就是一个等比数列。

这几级索引的结点总和就是n/2+n/4+n/8…+8+4+2=n-2。所以,跳表的空间复杂度是O(n) 。也就是说,如果将包含n个结点的单链表构造成跳表,我们需要额外再用接近n个结点的存储空间。
第三步:思考三三取首,每层索引的结点数:n/3, n/9, n/27 ... , 9, 3, 1 以此类推;
第一级索引需要大约n/3个结点,第二级索引需要大约n/9个结点。每往上一级,索引结点个数都除以3。为了方便计算,我们假设最高一级的索,引结点个数是1。我们把每级索引的结点个数都写下来,也是一个等比数列。

通过等比数列求和公式,总的索引结点大约就是n/3+n/9+n/27+…+9+3+1=n/2。尽管空间复杂度还是O(n) ,但比上面的每两个结点抽一个结点的索引构建方法,要减少了一半的索引结点存储空间。所以空间复杂度是O(n);
2.3、总结
优点:
跳表是一个最典型的空间换时间解决方案,而且只有在数据量较大的情况下才能体现出来优势。而且应该是读多写少的情况下才能使用,所以它的适用范围应该还是比较有限的。
缺点:
维护成本相对要高,在单链表中,一旦定位好要插入的位置,插入结点的时间复杂度是很低的,就是O(1),但是新增或者删除时需要把所有索引都更新一遍,为了保证原始链表中数据的有序性,我们需要先找到要动作的位置,这个查找操作就会比较耗时最后在新增和删除的过程中的更新,时间复杂度也是O(log n)。