ELK介绍、Elasticsearch单节点部署、Elasticsearch集群部署
文章目录
- 一、什么是ELK?
-
- 1.什么是Elasticsearch?
- 2.什么是 Logstash?
- 3.什么是 是 kibana :
-
- 二、ELK 常用架构及使用场景介绍:
-
- 1)简单架构
- 2)以Logstash 作为日志搜集器
- 3)以Beats 作为日志搜集器
- 4)引入消息队列模式
- 三、Elasticsearch 部署
-
- 1.部署
-
- 源码安装:
-
- docker安装
- 安装地址
- 2.rpm包安装
-
- 1)节点规划
- 2)系统优化
- 3)下载安装包
- 4)安装java环境
- 5)安装elasticsearch
- 6)elastcsearch设置内存锁定
- 7)修改elasticsearch锁定内存大小(
- 8)修改es配置文件
- 注意:
- 9)配置图形化管理界面
-
- 十、启动
- 十一、 测试访问
-
- elasticsearch监控
- 多节点部署(部署主从)
-
-
- 1) 集群节点规划
-
- 2) 部署主节点es01
- 3) 部署从节点es-02
-
- 修改配置文件
- 4) 配置图形化管理界面
-
- docker安装,可配置安装集群head插件,主要是有图形化elastic search
- 5) 启动
- 解决方法:
-
- 四、测试集群性能
-
-
-
- 再次添加
- Master 与 Slave 的区别:
-
-
- 五、补充:es集群启动完成后报master_not_discovered_exception 报错503
- 解决es集群启动完成后报master_not_discovered_exception
一、什么是ELK?
通俗来讲,ELK 是由 Elasticsearch、Logstash、Kibana 三个开源软件的组 成的一个组合体,这三个软件当中,每个软件用于完成不同的功能,ELK 又称 为 ELK stack,官方域名为 stactic.co,ELK stack 的主要优点有如下几个:
- 处理方式灵活:
elasticsearch是实时全文索引,具有强大的搜索功能 - 配置相对简单:
elasticsearch全部使用JSON 接口,logstash使用模块配置,kibana的配置文件部分更简单。 - 检索性能高效:基于优秀的设计,虽然每次查询都是实时,但是也可以达到百 亿级数据的查询秒级响应。
- 集群线性扩展:
elasticsearch 和 logstash都可以灵活线性扩展 - 前端操作绚丽:
kibana的前端设计比较绚丽,而且操作简单
1.什么是Elasticsearch?
是一个高度可扩展的开源全文搜索和分析引擎,它可实现数据的实时全文搜索 搜索、支持分布式

2.什么是 Logstash?
可以通过插件实现日志收集和转发,支持日志过滤,支持普通 log、自定义 json格式的日志解析。

3.什么是 是 kibana :
主要是通过接口调用 elasticsearch 的数据,并进行前端数据可视化的展现

二、ELK 常用架构及使用场景介绍:
ELK使用场景:
- 日志平台:利用elasticsearch的快速检索功能,在大量的数据当中可以快速查询需要的日志。
- 订单平台:利用elasticsearch的快速检索功能,在大量的订单当中检索我们所需要的订单。
- 搜索平台:利用elasticsearch的快速检索功能,在大量的数据中检索出我们所需要的数据。
1)简单架构
这种架构非常简单,使用场景也有限。初学者可以搭建这个架构,了解 ELK 如何工作;在这种架构中,只有一个Logstash、Elasticsearch 和Kibana实例。Logstash 通过输入插件从多种数据源(比如日志文件、标准输入 Stdin 等)获取数据,再经过滤插件加工数据,然后经 Elasticsearch 输出插件输出到Elasticsearch,通过 Kibana 展示。现高可用、提供 API 接口,可以处理大规模日志数据,比 如 Nginx、Tomcat、系统日志等功能。
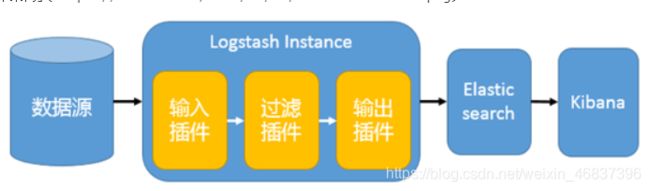
2)以Logstash 作为日志搜集器
这种结构因为需要在各个服务器上部署 Logstash,而它比较消耗 CPU 和内存资源,所以比较适合计算资源丰富的服务器,否则容易造成服务器性能下降,甚至可能导致无法正常工作。

3)以Beats 作为日志搜集器
这种架构引入 Beats 作为日志搜集器。目前 Beats 包括四种:
Packetbeat(搜集网络流量数据);Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据);Filebeat(搜集文件数据);Winlogbeat(搜集 Windows 事件日志数据)。
Beats 将搜集到的数据发送到Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈现给用户。
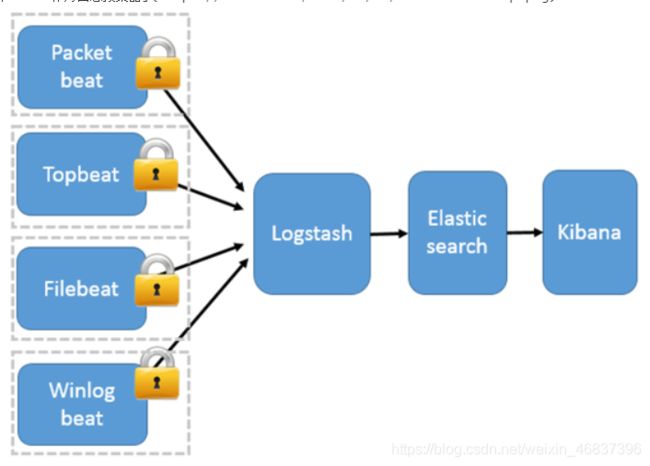

这种架构解决了 Logstash在各服务器节点上占用系统资源高的问题。相比Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。
因此这种架构适合对数据安全性要求较高,同时各服务器性能比较敏感的场景。
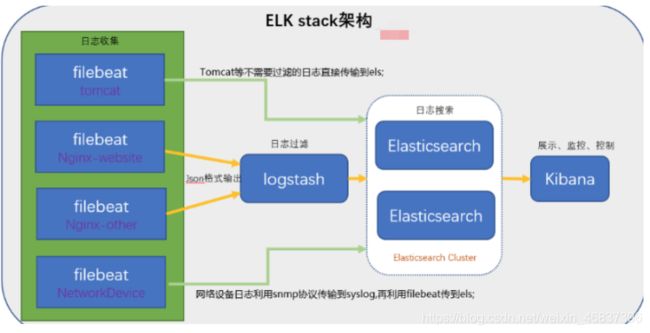
4)引入消息队列模式
Beats 还不支持输出到消息队列(新版本除外:5.0版本及以上),所以在消息队列前后两端只能是 Logstash 实例。logstash从各个数据源搜集数据,不经过任何处理转换仅转发出到消息队列(kafka、redis、rabbitMQ等),后logstash从消息队列取数据进行转换分析过滤,输出到elasticsearch,并在kibana进行图形化展示
三、Elasticsearch 部署
1.部署
一般部署elasticsearch有三种方式:
- rpm包安装
- 源码包安装
- docker安装
源码安装:
# 下载源码包
wget https://github.com/elastic/elasticsearch/archive/refs/tags/elasticsearch-7.12.1-linux-x86_64.tar.gz
# 解压
tar xf elasticsearch-7.12.1-linux-x86_64.tar.gz -C /usr/local/
# elasticsearch是依赖于Java
yum install java-1.8.0* -y
# 验证Java
[root@es-01 ~]# java -version
openjdk version "1.8.0_292"
OpenJDK Runtime Environment (build 1.8.0_292-b10)
OpenJDK 64-Bit Server VM (build 25.292-b10, mixed mode)
查看完整配置文件内容(源码包安装的默认没有)
[root@es-01 ~]# cat /usr/lib/systemd/system/elasticsearch.service
[Unit]
Description=Elasticsearch
Documentation=https://www.elastic.co
Wants=network-online.target
After=network-online.target
[Service]
LimitMEMLOCK=infinity
Type=notify
RuntimeDirectory=elasticsearch
PrivateTmp=true
Environment=ES_HOME=/usr/share/elasticsearch
Environment=ES_PATH_CONF=/etc/elasticsearch
Environment=PID_DIR=/var/run/elasticsearch
Environment=ES_SD_NOTIFY=true
EnvironmentFile=-/etc/sysconfig/elasticsearch
WorkingDirectory=/usr/share/elasticsearch
User=elasticsearch
Group=elasticsearch
ExecStart=/usr/share/elasticsearch/bin/systemd-entrypoint -p ${PID_DIR}/elasticsearch.pid --quiet
# StandardOutput is configured to redirect to journalctl since
# some error messages may be logged in standard output before
# elasticsearch logging system is initialized. Elasticsearch
# stores its logs in /var/log/elasticsearch and does not use
# journalctl by default. If you also want to enable journalctl
# logging, you can simply remove the "quiet" option from ExecStart.
StandardOutput=journal
StandardError=inherit
# Specifies the maximum file descriptor number that can be opened by this process
LimitNOFILE=65535
# Specifies the maximum number of processes
LimitNPROC=4096
# Specifies the maximum size of virtual memory
LimitAS=infinity
# Specifies the maximum file size
LimitFSIZE=infinity
# Disable timeout logic and wait until process is stopped
TimeoutStopSec=0
# SIGTERM signal is used to stop the Java process
KillSignal=SIGTERM
# Send the signal only to the JVM rather than its control group
KillMode=process
# Java process is never killed
SendSIGKILL=no
# When a JVM receives a SIGTERM signal it exits with code 143
SuccessExitStatus=143
# Allow a slow startup before the systemd notifier module kicks in to extend the timeout
TimeoutStartSec=75
[Install]
WantedBy=multi-user.target
# Built for packages-7.12.1 (packages)
docker安装
**cluster.name:集群名**
docker run -p 9200:9200 -p 9300:9300 -e "cluster.name=[集群名]" docker.elastic.co/elasticsearch/elasticsearch:7.12.1
安装地址
ElasticSearch官网下载地址:https://www.elastic.co/cn/downloads/elasticsearch
官网其他版本安装包下载地址 :https://www.elastic.co/cn/downloads/past-releases#elasticsearch
官方文档参考:
Filebeat:
https://www.elastic.co/cn/products/beats/filebeat
https://www.elastic.co/guide/en/beats/filebeat/5.6/index.html
Logstash:
https://www.elastic.co/cn/products/logstash
https://www.elastic.co/guide/en/logstash/5.6/index.html
Kibana:
https://www.elastic.co/cn/products/kibana
https://www.elastic.co/guide/en/kibana/5.5/index.html
Elasticsearch:
https://www.elastic.co/cn/products/elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/index.html
elasticsearch中文社区:
https://elasticsearch.cn/
2.rpm包安装
1)节点规划
![]()
2)系统优化
关闭selinux
[root@es01 ~]# setenforce 0
setenforce: SELinux is disabled
[root@es01 ~]# getenforce
Disabled
关闭防火墙
[root@es01 ~]# systemctl stop firewalld
关闭NetworkManager
[root@es01 ~]# systemctl disable --now NetworkManager
设置时区
[root@es01 ~]# timedatectl set-timezone Asia/Shanghai
设置程序可以打开的文件数
[root@es01 ~]# vim /etc/security/limits.conf
[root@es01 ~]# grep -E ^[^#] /etc/security/limits.conf
* soft memlock unlimited
* hard memlock unlimited
* soft nofile 131072
* hard nofile 131072
同步时间
echo "*/5 * * * * ntpdate time1.aliyun.com &> /dev/null
&& hwclock -w" >> /var/spool/cron/root
[root@linux-host1 ~]# systemctl restart crond
重启
[root@es01 ~]# reboot
3)下载安装包
[root@es01 ~]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.12.1-x86_64.rpm
4)安装java环境
方式一
[root@es01 ~]# yum install java-1.8.0-* -y
[root@es01 ~]# java -version
openjdk version "1.8.0_292"
OpenJDK Runtime Environment (build 1.8.0_292-b10)
OpenJDK 64-Bit Server VM (build 25.292-b10, mixed mode)
方式二
本地安装在 oracle 官网下载 rpm 安装包:
yum localinstall jdk-8u92-linux-x64.rpm
方式三:下载二进制包自定义 profile 环境变量:
下 载 地 址 :
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-
2133151.html
tar xvf jdk-8u121-linux-x64.tar.gz -C /usr/local/
ln -sv /usr/local/jdk1.8.0_121 /usr/local/jdk
vim /etc/profile
export JAVA_HOME=/usr/local/jdk
export
CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HO
ME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
java -version
java version "1.8.0_121" #确认可以出现当前的 java 版本号
Java(TM) SE Runtime Environment (build 1.8.0_121-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode)
5)安装elasticsearch
[root@es01 ~]# yum install java-1.8.0-* -y
6)elastcsearch设置内存锁定
=====因为es的数据在内存里,如果不锁定的话,就会造成es数据不稳定
[root@es01 ~]# vim /usr/lib/systemd/system/elasticsearch.service
LimitAS=infinity
LimitMEMLOCK=infinity #在[service]层LimitAS行下边添加此行内容
[root@es01 ~]# systemctl daemon-reload
7)修改elasticsearch锁定内存大小(
[root@es01 ~]# vim /etc/elasticsearch/jvm.options
-Xms1g #最大锁定内存1g
-Xmx1g #最小锁定内存1g
8)修改es配置文件
[root@es-01 ~]# vim /etc/elasticsearch/elasticsearch.yml
[root@es-01 ~]# grep -E '^[^#]' /etc/elasticsearch/elasticsearch.yml
# # 设置集群名称
cluster.name: es
# # 设置集群节点名称(节点名称在集群中唯一)
node.name: node-01
# # 设置数据存放目录
path.data: /var/lib/elasticsearch
# # 设置日志存放目录
path.logs: /var/log/elasticsearch
# # 设置内存锁定
bootstrap.memory_lock: true
# # 设置监听的IP,可监听所有
network.host: 0.0.0.0
# # 设置监听的端口
http.port: 9200
# # 开启跨域功能
http.cors.enabled: true
http.cors.allow-origin: "*"
# # 设置主节点(单台可不设置)
cluster.initial_master_nodes: node-01
# # 设置参与选举master的策略
discovery.zen.minimum_master_nodes: 2
# # 设置节点(所有)
discovery.zen.ping.unicast.hosts: ["172.16.1.30","172.16.1.40"]
# # 是否具备参与选举为master节点的资格
node.master: true
注意:
设置集群节点名称(节点名称在集群中唯一)
node.name: node-01
9)配置图形化管理界面
- 此小结仅需主节点执行即可,可通过一个容器来管理多个节点
- 需利用docker配置安装集群head插件,此步骤需在第5步测试访问后执行
- docker安装,可配置安装集群head插件,主要是有图形化elastic search
#1.卸载旧版本
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
#2.安装需要的安装包
sudo yum install -y yum-utils
# 3.设置镜像的仓库
默认是国外的:
sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
华为云:
sudo yum-config-manager \
--add-repo \
https://repo.huaweicloud.com/dockerce/linux/centos/docker-ce.repo
阿里云:
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 4.清空缓存
yum clean all && yum makecache fast
# 5.安装docker
yum install docker-ce docker-ce-cli containerd.io -y
# 6.阿里云加速器
打开阿里云官网 产品 --> 容器与中间件 --> 容器与镜像服务ACR --> 管理控制台 --> 镜像加速器 --> CentOS
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://vf52ltmx.mirror.aliyuncs.com"]
}
EOF
#7.启动
sudo systemctl daemon-reload
sudo systemctl restart docker
拉取运行图形化管理界面镜像
docker run -d -p 9100:9100 alvinos/elasticsearch-head
可通过图形界面访问了,添加主从后,可通过它来管理
http://10.0.0.30:9100 # 图形化管理界面
十、启动
# 启动
systemctl start elasticsearch.service
# 可监控启动日志
[root@es-01 ~]# tailf /var/log/elasticsearch/Peng-by-es.log
# 检测启动端口
[root@es-01 ~]# netstat -lntp | grep java
tcp6 0 0 :::9200 :::* LISTEN 2865/java
tcp6 0 0 :::9300 :::* LISTEN 2865/java
十一、 测试访问
- **测试是否能够正常对外提供服务,通过IP+9200端口访问
http://10.0.0.30:9200
http://10.0.0.30:9100 # 图形化管理界面
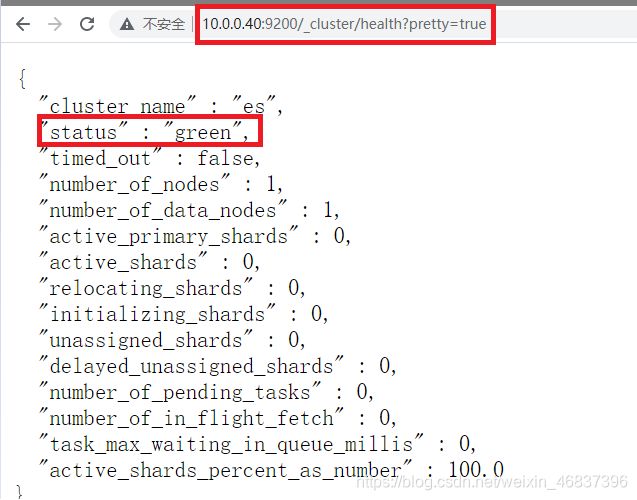
elasticsearch监控
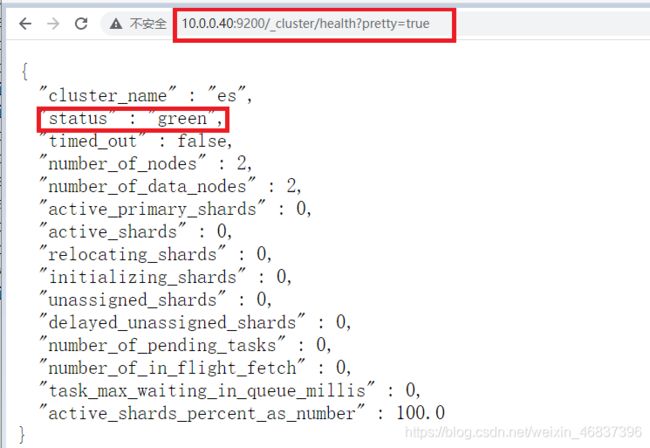
通过浏览器访问:http://10.0.0.40:9200/_cluster/health?pretty=true, 例如对 status 进行分析,如果等于green(绿色)就是运行在正常,等于yellow(黄色)表示副本分片丢失,red(红色)表示主分片丢失。

多节点部署(部署主从)
elasticsearch是主从数据节点分离的,按照节点还可以分为
热数据节点和冷数据节点。
-
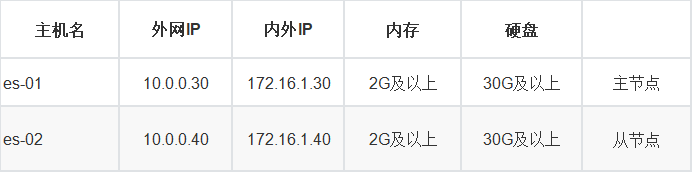
1) 集群节点规划
2) 部署主节点es01
- 参考上述单节点部署(包括优化),略 ~
3) 部署从节点es-02
- 参考上述单节点部署(包括优化),略 ~
-
修改配置文件
1.把主节点的拉过来,进行以下修改(主节点也也要修改部分内容)
scp 10.0.0.30:/etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/
# # 设置集群名称
cluster.name: es
# # 设置集群节点名称(节点名称在集群中唯一)
node.name: node-01
# # 设置数据存放目录
path.data: /var/lib/elasticsearch
# # 设置日志存放目录
path.logs: /var/log/elasticsearch
# # 设置内存锁定
bootstrap.memory_lock: true
# # 设置监听的IP,可监听所有
network.host: 0.0.0.0
# # 设置监听的端口
http.port: 9200
# # 开启跨域功能
http.cors.enabled: true
http.cors.allow-origin: "*"
# # 设置主节点(单台可不设置)
cluster.initial_master_nodes: node-01
# # 设置参与选举master的策略
discovery.zen.minimum_master_nodes: 2
# # 设置节点(所有)
discovery.zen.ping.unicast.hosts: ["172.16.1.30","172.16.1.40"]
# # 是否具备参与选举为master节点的资格
node.master: true
2.设置集群节点名称(节点名称在集群中唯一)
node.name: node-02
# # 设置集群名称
cluster.name: es
# # 设置集群节点名称(节点名称在集群中唯一)
node.name: node-02
# # 设置数据存放目录
path.data: /var/lib/elasticsearch
# # 设置日志存放目录
path.logs: /var/log/elasticsearch
# # 设置内存锁定
bootstrap.memory_lock: true
# # 设置监听的IP,可监听所有
network.host: 0.0.0.0
# # 设置监听的端口
http.port: 9200
# # 开启跨域功能
http.cors.enabled: true
http.cors.allow-origin: "*"
# # 设置主节点(单台可不设置)
cluster.initial_master_nodes: node-01
# # 设置参与选举master的策略
discovery.zen.minimum_master_nodes: 2
# # 设置节点(所有)
discovery.zen.ping.unicast.hosts: ["172.16.1.30","172.16.1.40"]
# # 是否具备参与选举为master节点的资格
node.master: false
================================================================================
解释:
node.name: es-01 # 不参与选举为master节点
node.data: true # 允许存储数据
建议:主节点nodes设置成主节点的名称,不建议ip
cluster.initial_master_nodes: node-01
生产中环境中参考配置:
默认情况下,每个节点都有成为主节点的资格,也会存储数据,还会处理客户端的请求;
生产中建议集群中设置3台以上的节点作为master节点【node.master: true node.data: false】;
这些节点只负责成为主节点,维护整个集群的状态;
再根据数据量设置一批data节点【node.master: false node.data: true】。
4) 配置图形化管理界面
- 此小结仅需主节点执行即可,可通过一个容器来管理多个节点
- 需利用docker配置安装集群head插件,此步骤需在第5步测试访问后执行
-
docker安装,可配置安装集群head插件,主要是有图形化elastic search
5) 启动
systemctl start elasticsearch.service
PS:
做到这一步极其容易出现数据不一致的问题,反应到登录网页上就上明明好像能正常访问,其实它的的UUTD是错误的,中间若启动错误,并检查配置文件是否配置错误,进行重启。
解决方法:
rm -rf /var/lib/elasticsearch/*
systemctl restart elasticsearch.service
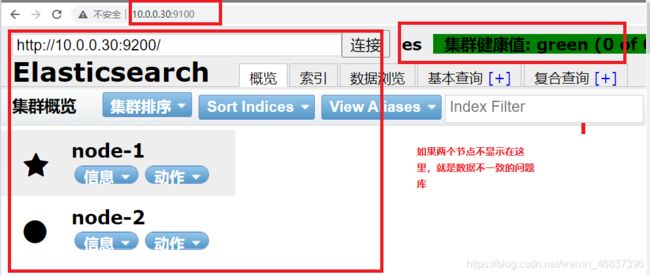
测试访问
http://10.0.0.30:9200
http://10.0.0.40:9200
http://10.0.0.30:9100 # 图形化管理界面
jyh-node-01 # 主节点
jyh-node-02 # 从节点
9200作为Http协议,主要用于外部通讯
9300作为Tcp协议,jar之间就是通过tcp协议通讯
ES集群之间是通过9300进行通讯
解决方法:
#故障报错解决:
做到这一步极其容易出现数据不一致的问题,反应到登录网页上就上明明好像能正常访问,其实它的的UUID是错误的。为此可以先删除/var/lib/elasticsearch/*下面的东西,然后再重启elasticsearch。这样就可以了。
[root@es-02 ~]# systemctl stop elasticsearch.service
[root@es-02 ~]# rm -rf /var/lib/elasticsearch/*
[root@es-02 ~]# tail -f /var/log/elasticsearch/elaina-es.log #实时监控集群日志发现问题
[root@es-02 ~]# systemctl start elasticsearch.service #新窗口执行启动命令
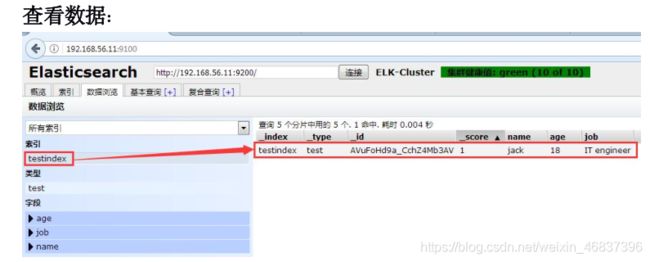
四、测试集群性能
-
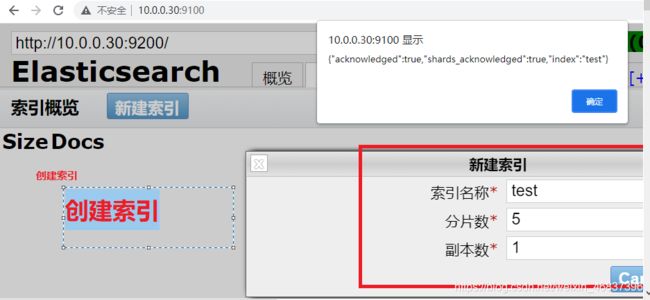
新建索引
-
点击概述查看
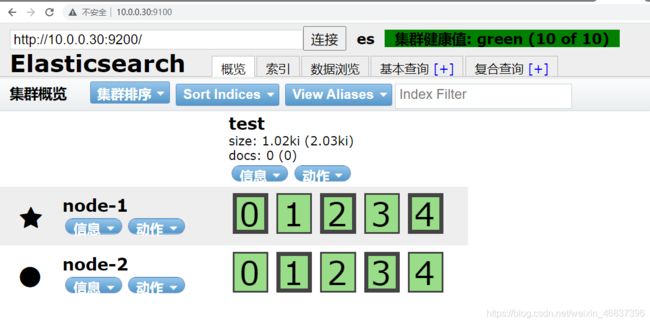
-
点击复合查询

-
点击基础查询
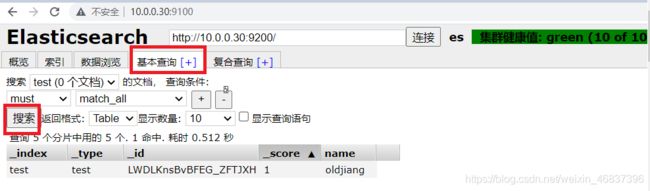
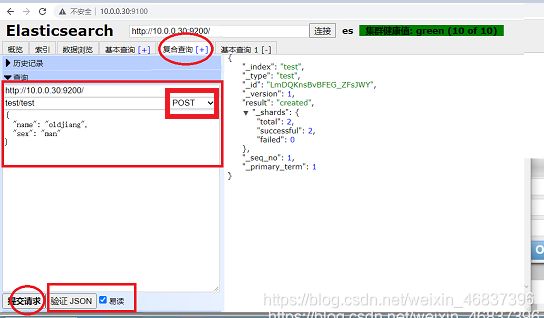
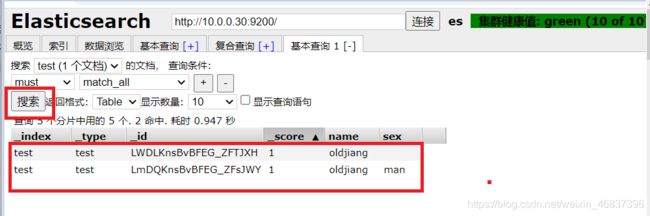
再次添加

Master 与 Slave 的区别:
Master 的职责:
统计各 node 节点状态信息、集群状态信息统计、索引的创建和删除、索引分配
的管理、关闭 node 节点等
Slave 的职责:
同步数据、等待机会成为 Master
五、补充:es集群启动完成后报master_not_discovered_exception 报错503
解决es集群启动完成后报master_not_discovered_exception
es集群启动后,在浏览器输入:http://es ip地址:端口/_cat/nodes?pretty,会提示如下错误:
{ “error” : { “root_cause” : [ { “type” : “master_not_discovered_exception”, “reason” : null } ], “type” : “master_not_discovered_exception”, “reason” : null }, “status” : 503 }
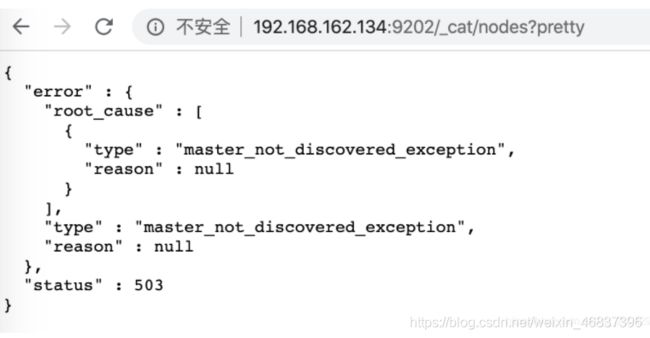 解决方案:
解决方案:
在每个配置文件指定初始节点:
cluster.initial_master_nodes: node-1

重启ES集群,浏览器再次输入http://es ip地址:端口/_cat/nodes?pretty,就可以看到集群启动成功了: