阿里推出AnyText: 解决AI绘图不会写字的问题,可以任意指定文字位置,且支持多国语言!
目录
前言
相关链接
模型介绍
模型使用
环境配置
示例代码
结果展示
训练数据介绍
模型评测指标
模型局限性

前言
近年来,随着AIGC的爆火,图片生成技术得到飞速发展,当前AI生成的图片已达到真假难辨的高保真度。不过,当合成图片中出现文字内容时,仍能够使AI露出马脚,因为当前主流方法尚无法在图片中生成准确可读的字符。最近半年来已有学者开始研究文本生成的问题,但这些方法大多以英文为主,无法解决中文这种字形繁杂、字符数以万计的文字生成。AnyText通过创新性的算法设计,可以支持中文、英语、日语、韩语等多语言的文字生成,还支持对输入图片中的文字内容进行编辑。模型所涉及的文字生成技术为电商海报、Logo设计、创意涂鸦、表情包等新型AIGC应用提供了新的可能性。

相关链接
代码链接:https://github.com/tyxsspa/AnyText
论文链接:https://arxiv.org/abs/2311.03054
在线Demo:AnyText图文融合, Huggingface-AnyText
模型介绍
AnyText主要基于扩散(Diffusion)模型,包含两个核心模块:隐空间辅助模块(Auxiliary Latent Module)和文本嵌入模块(Text Embedding Module)。其中,隐空间辅助模块对三类辅助信息(字形、文字位置和掩码图像)进行编码并构建隐空间特征图像,用来辅助视觉文字的生成;文本嵌入模块则将描述词中的语义部分与待生成文本的字形部分解耦,使用图像编码模块单独提取字形信息后再与语义信息做融合,既有助于文字的书写精度,也有利于提升文字与背景的一致性。训练阶段,除了使用扩散模型常用的噪声预测损失,还增加了文本感知损失,在图像空间对每个生成文本区域进行像素级的监督,以进一步提升文字书写精度。

模型使用
AnyText使用范围较广,能基于输入的提示词以及指定的位置生成包含多语言字符的图像,或对输入图像中的文本进行编辑或修复。
环境配置
# 安装git(如有请跳过)
conda install -c anaconda git
# 克隆anytext仓库
git clone https://github.com/tyxsspa/AnyText.git
cd AnyText
# 准备字库文件(推荐Arial Unicode MS,需自行下载)
mv your/path/to/arialuni.ttf ./font/Arial_Unicode.ttf
# 方式一:如果使用modelscope notebook最新镜像(ubuntu22.04-cuda11.8.0-py310-torch2.1.0-tf2.14.0-1.10.0),直接安装如下包即可
pip install Pillow==9.5.0
pip install gradio==3.50.0
# 方式二:重新创建一个独立虚拟环境(耗时较长)
conda env create -f environment.yaml
conda activate anytext示例代码
参照如下示例代码,使用anytext进行文字生成或文字编辑
(首次运行时,会下载模型文件至:~/.cache/modelscope/hub中,请耐心等待;如果需要修改下载目录,可以手动指定环境变量:MODELSCOPE_CACHE)
from modelscope.pipelines import pipeline
from util import save_images
pipe = pipeline('my-anytext-task', model='damo/cv_anytext_text_generation_editing', model_revision='v1.1.1', use_fp16=True, use_translator=False)
img_save_folder = "SaveImages"
params = {
"show_debug": True,
"image_count": 2,
"ddim_steps": 20,
}
# 1. text generation
mode = 'text-generation'
input_data = {
"prompt": 'photo of caramel macchiato coffee on the table, top-down perspective, with "Any" "Text" written on it using cream',
"seed": 66273235,
"draw_pos": 'example_images/gen9.png'
}
results, rtn_code, rtn_warning, debug_info = pipe(input_data, mode=mode, **params)
if rtn_code >= 0:
save_images(results, img_save_folder)
# 2. text editing
mode = 'text-editing'
input_data = {
"prompt": 'A cake with colorful characters that reads "EVERYDAY"',
"seed": 8943410,
"draw_pos": 'example_images/edit7.png',
"ori_image": 'example_images/ref7.jpg'
}
results, rtn_code, rtn_warning, debug_info = pipe(input_data, mode=mode, **params)
if rtn_code >= 0:
save_images(results, img_save_folder)
print(f'Done, result images are saved in: {img_save_folder}')结果展示
训练数据介绍
模型的训练数据集为AnyWord-3M(即将开源),主要来源于互联网开源数据集,包括LAION-400M, Noah-Wukong以及部分OCR数据集,按照一定规则从中筛选出包含文字的图片,并使用OCR模型和BLIP-2模型进行全自动打标,总计得到300万高质量的图文对,涵盖自然图像、电影海报、书籍封面等各类场景。
模型评测指标
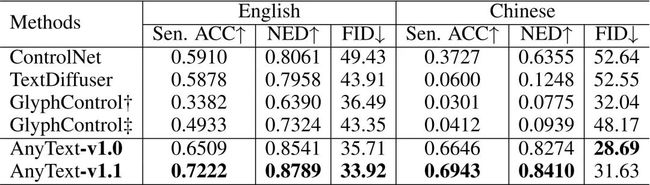
使用全句准确率(Sen. ACC)和归一化编辑距离(NED)评价生成文字的准确度,使用FID指标评价图像的生成质量。与现有方法相比,AnyText在中英文的文字生成方面均具备显著优势,达到SOTA水平。
模型局限性
-
由于训练数据的原因,当前模型对中文和英文的书写精度要好于其他语种;
-
有一定概率会产生文本模糊、扭曲、拼写错误等现象;
-
有一定概率在背景中生成不可读的伪文字或水印;
-
基于互联网公开数据的训练,生成结果与训练数据分布存在较大关联;
相关链接
代码链接:https://github.com/tyxsspa/AnyText
论文链接:https://arxiv.org/abs/2311.03054
在线Demo:创空间, HuggingFace
感兴趣的小伙伴可以点击下面链接体验一下,感谢你看到这里,要不就顺便左下角再点个关注吧!一个有趣有AI的AIGC公众号:关注AI、深度学习、计算机视觉、AIGC、Stable Diffusion等相关技术。