谈谈那些实习测试工程师应该掌握的基础知识(一)
全文4218字,为阅读方便,拆分两部分,第二部分内容已放置文末。
一、测试基础篇
测试流程有哪些步骤?
1.需求分析。这个部分主要就是针对需求提出一些不合理的地方,讨论解决之后才进入下一步。
2.测试计划。根据需求文档做对功能进行划分,通过合理的划分人力、物力进行测试安排。
3.测试方案。主要确定测试的方法、测试的环境、测试的对象,是性能测试呢?还是功能测试?
4.测试用例。这个步骤通常可以在开发进行的时候同步进行编写。
(测试用例设计的要素以及用例设计的方法?)
5.用例评审。在这一步里面,通常需要产品、UI、前后端等多个部门的人参与进来,有必要的话也需要邀请甲方一起,完善测试用例。
6.接口测试。这个步骤一般是在前后端完成之后,我们在测试结果的时候,开发进行前后端联调。
7.功能测试。在前后端联调完之后,进行功能测试。
8.bug管理。使用bug管理工具进行bug的管理,一般是禅道。
(bug的生命周期/生命流程是怎样的?)
9.回归测试。需要验证bug是否已经正确解决了,需要注意的是,解决bug的过程中是否产生了新的bug。
10.线上验证。在产品上线后,我们可以使用自动化脚本进行一个监控,一般是只查不改,主要为了实现自动化监控预警。
测试如何分类?
按照阶段来分,可以分为:单元测试,集成测试,系统测试,验收测试。
按照是否运行程序来分,可以分为:静态测试、动态测试。
按照是否需要查看源码来分,可以分为:黑盒测试和白盒测试。黑盒测试又分为了功能测试和性能测试,功能测试一般有逻辑功能测试、界面测试、易用性测试、兼容性测试等;性能测试一般有压力测试、负载测试、稳定性测试,以及一个时间性能和空间性能。
静态测试:是指不实际运行被测试软件,而只是静态的检查程序代码、界面或者文档中可能存在的错误的过程。
动态测试:是指实际运行被测程序,输入相应的测试数据,检查实际输出结果和预期结果是否相符的过程。
单元测试:一般就是指对代码中的最小可测单元进行测试,一般都是开发人员自行测试了。
集成测试:一般指的是把上述的单元测试组装成系统或者子系统,在进行测试,一般也是开发人员完成。
系统测试:一般指的就是开发的差不多了,然后把我们的整个系统看做一个整理,需要对系统的功能、性能、软件能运行的环境等进行一个测试。
验收测试:整个就比较好理解,对上述的一些流程和一些bug进行一个测试,查看是否功能都符合我需求说明书,是否还存在bug没有修复。
逻辑功能测试:就是这个操作是否符合正常人的逻辑,例如我进入一个软件,没有登录,那么应该弹出登录对吧,但是这个软件弹出了注册,这个逻辑可能就不太合理。
界面测试:就例如我注册完之后是否会跳转到登录界面,这就是我个人理解的一个界面测试。
易用性测试:就是测试这个软件是否容易使用,如果不好用,用户操作不了,也算是bug,也是缺陷。
兼容性测试:就是测试不同设备的情况下,软件是否能够正常运行,对PC端来说,可能就涉及到操作系统不同,分辨率不同等,对于移动端来说,就是设备的尺寸不同等问题。
压力测试:就是持续不断的给被测试的系统增加压力,直到被测试的系统压垮为止,用来测试系统所承受的最大压力。
负载测试:就是让系统在其能够接受的压力范围内持续运行,着重关注系统的性能和响应能力。
稳定性测试:也叫作可靠性测试,就是指连续运行被测系统,查看系统运行时的稳定程度,着重测试系统的稳定性和可靠性。
时间性能:就是指软件的响应时间,例如点击一个登陆按钮,系统能给出登陆成功或失败的一个反应时间。
空间性能:指的就是对内存和Cpu的一个消耗情况。
冒烟测试:冒烟这个概念最早就是出现的硬件的,指的是一个电路板被生产出来之后,测试有没有问题的最好方法就是通电,如果通电没有冒烟,就可以初步说明这个电路板是没有问题,那么这个概念放在软件行业来说,就是我们可以在软件发版之前对软件的一些主要功能进行测试,如果没有实现主要功能的话,直接就可以打回重做,就没有必要继续走后面的流程了。
对一个Web端可以怎么测试?
可以从兼容性入手,测试不同的操作系统、不同的浏览器是否都能够正常的运行这个系统。
可以从安全性入手,例如常见的安全性测试:
第一个就是用户验证,例如用户登录的token超时了,是否需要重新登录;
第二个就是用户权限方面的验证,例如验证低级别用户是否具有了高级别用户的权限,各级别用户权限都得到了实现。
第三个就是对一些系统数据的保护,例如一些程序可能能够修改系统文件或者访问系统文件,那么就需要考虑到保护敏感数据,例如用户密码等文件。
第四个就是可能防止sql注入吧,当然现在大部分的后端框架都是mybaits-plus,使用了参数化预编译,基本不会出现sql注入的情况,但是我们还是可以进行测试,例如在接口的url请求里面加上一个sql的关键字,例如select之类的,或者在最后加上or 1=1,看一下是否能够获取到全部参数。
可以从页面入手:
第一,页面是否显示完整,正确,美观;
第二,页面的一些特殊效果是否展示出来了;
第三,页面的一个兼容性,是否能够自适应。
第四,页面的一些错误提示是否完善,包括成功、失败、危险操作、重要操作提示。
二、测试用例篇
测试用例设计的要素以及测试用例设计的方法?
测试用例设计八要素:
用例编号、用例标题、所属模块、测试数据、测试步骤、预期输出、实际输出、测试人员。
测试用例设计的方法:
黑盒测试用例设计方法包括等价类划分法、边界值分析法、错误推测法、因果图法、判定表驱动法、正交试验设计法、功能图法等。
等价类划分法:
等价类划分法是把程序的输入域划分成若干部分(子集),然后从每个部分中选取少数代表性数据作为测试用例。每一类的代表性数据在测试中的作用等价于这一类中的其他值。
例如:输入值是学生成绩,范围是0~100:
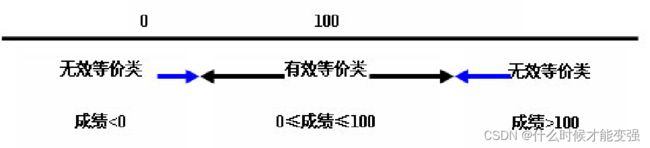
边界值分析法:
边界值分析法就是对输入或输出的边界值进行测试的一种黑盒测试方法。是作为对等价类划分法的补充,其测试用例来自等价类的边界。
很多错误是发生在输入或输出范围的边界上,而不是中间区域。因此针对各种边界情况设计测试用例,可以查出更多的错误。
例: 假设一个文本输入区域允许输入1个到255个字符,则:
输入1个和255个字符作为有效等价类;
输入0个和256个字符作为无效等价类,
这几个数值都属于边界条件值。
错误推断法:
基于经验和直觉推测程序中所有可能存在的各种错误, 从而有针对性的设计测试用例的方法。
例:
输入数据和输出数据为0的情况;
输入表格为空格或输入表格只有一行。 这些都是容易发生错误的情况。
可选择这些情况下的例子作为测试用例。
因果图法:
顾名思义,就是根据画出因果图,来识别软件系统中的潜在问题并找出其根本原因,可以帮助我们快速定位Bug。
判定表驱动法:
它通过创建一个表格来描述测试条件和所需的操作,以辅助测试用例的编写和执行,最好能描述预期结果。
例:我们正在测试一个登录系统,其登录逻辑取决于用户的角色和输入的用户名和密码。
那么判定表就可以如下:
| 角色 | 用户名/密码 有效性 | 期望结果 |
|---|---|---|
| 管理员 | 有效 | 成功 |
| 普通用户 | 无效 | 失败 |
| 普通用户 | 有效 | 成功 |
正交试验设计法:
一般用于在有限的试验次数内尽可能全面地测试系统的不同因素和参数组合情况。
例:我们正在测试一款电子产品的显示屏参数。我们想要测试不同的因素,如亮度、对比度和色彩饱和度。则:
对于亮度、对比度和色彩饱和度这三个因素,我们可以通过正交试验设计法生成以下试验表:
试验1:亮度高、对比度低、色彩饱和度低
试验2:亮度低、对比度高、色彩饱和度低
试验3:亮度低、对比度低、色彩饱和度高
功能图法:
通过创建功能图来描述被测系统的不同功能和它们之间的关系,以帮助测试人员设计测试用例和评估测试覆盖。
例:我们正在测试一个在线购物网站的功能。
通过功能图法,我们可以创建一个功能图来描述网站的不同功能和它们之间的关系。我们可以标识出注册功能、登录功能、浏览商品功能、添加商品到购物车功能以及结算功能等。
通过功能图,我们可以识别出各个功能之间的依赖关系和交互流程。例如,注册功能可能依赖于输入正确的用户名和密码,并且成功注册后用户才能登录。登录后,用户可以浏览商品,选择并添加商品到购物车,最后进行结算。这些关系可以在功能图中清楚地呈现出来。
测试用例有哪些类型?
功能测试用例、性能测试用例、接口测试用例。
这些类型都分别包含了哪些内容?
功能测试用例一般就包含了上文提到的八大要素,即:用例编号、用例标题、所属模块、测试数据、测试步骤、预期输出、实际输出、测试人员。
性能测试用例可能还会有:需要测试的接口、以及一些性能方面的参数,如并发量、迭代次数、压测时间、响应时间等,还需要预期结果,如吞吐量如何,响应时间如何,错误率如何。
接口测试用例可能还会加入:url地址,请求参数,请求头这些内容。
三、bug的生命周期/生命流程是怎样的?
发现bug -> 确认bug -> 提交bug -> 指派bug -> 开发确认bug(如果开发确认这是重复bug、不是缺陷、无法复现的bug,经我们确认后同意开发观点,则关闭bug) -> 开发解决bug -> 验证bug并回归测试 -> 是否通过验证(如果通过则关闭bug,如果没通过则重新激活这个bug)-> 关闭bug
四、http和https的区别?
1.从安全性来说,http是一种明文传输协议,传输的数据容易被拦截,存在安全风险;
https对数据进行了加密和认证,保证了数据传输的安全性。
2.从网站证书来说,http协议不需要网站使用证书,任何人都可以创建一个http网站;
https网站有数字证书,证书会验证网站的身份和可信性,只有合法网站才能使用https。
3.从端口号来说,http使用的是80端口,https使用的是443端口。
4.从连接速度来说,https由于要对数据进行加密和认证,相比http,速度会慢一些。
5.从缓存的角度来说,http协议可能会被浏览器进行缓存;https协议不会被缓存,因为每次请求都是加密的内容,无法通过缓存提速。
6.从使用场景来说,http协议主要用于传输一些非敏感的数据,比如一些普通网页,文件下载等;
https协议主要用于传输敏感数据,例如在线支付、网上银行、电子邮件等。
五、在抓包后如何准确的定位前后端的问题?
1.可以查看请求和响应中的http状态码,如果是5开头的错误码,可能是后端的问题。
2.检查返回值中的信息是否与自己的预期相符,如果不符合则为后端问题,如果返回值符合但是是页面展示问题,则是后端问题。
3.还有一种情况就是抓包后,但是没找到这个包,可能就是前端的,因为前端根本没有发送请求。
六、MySql篇
如果我现在有一张学生表,如何查询成绩前十的学生?
使用order by进行排序,然后limit 10 就可以了
如果我现在查询名字带“李”的,怎么实现?
使用like关键字 "%李%"
左连接、右链接、内连接的区别?
左连接会返回左表中的所有记录,同时返回与右表中匹配的记录,如果右表中没有匹配的记录,则返回空值。
反之,则为右链接。
内连接会返回左表和右表都匹配的记录。
七、Linux篇
新建文件夹的命令?
mkdir
新建文件的命令?
touch
文件重命名的命令?
mv
查看日志的命令?
tail -f 文件名 (能够滚动显示文件的最后10行信息)
在vi模式下怎么查找一个字符串?
使用/或者? (区别就是/查找光标之下的内容,?查找光标之上的内容)
在vi模式下如何显示行号?
使用:set nu
对tar包解压缩的命令是什么?zip呢?
对tar包的命令:tar -zxvf
zip:unzip
查看服务器的进程信息?
ps -ef | grep 进程名称
如何关闭进程?
kill 。kill-9强制关闭
修改文件权限?
chmod
八、接口请求篇
post请求和get请求的区别?
1.get请求把参数附加在url的末尾,导致数据是可见的,容易被截取;
post请求把数据放在请求的消息体中,相对get请求来说更加安全。
2.get请求一般是用于获取数据的,post请求一般用于提交数据。
3.get请求对数据长度进行了限制,一般在2048个字符内,不同的浏览器有不同的限制,而post请求则没有数据长度的限制。
4.get请求刷新或者回退对服务器没有影响,但是post请求刷新或者回退时会重新提交数据请求。
5.get请求可以被浏览器缓存,可以被收藏为书签,可以作为历史记录保存,post请求则都不会。
接口请求的常见方式有哪些?
一般来说,一共有六种,分别是:
1、Get 向特定资源发出请求(请求指定页面信息,并返回实体主体)
2、Post 向指定资源提交数据进行处理请求(提交表单、上传文件),又可能导致新的资源的建立或原有资源的修改
3、Put 向指定资源位置上上传其最新内容(从客户端向服务器传送的数据取代指定文档的内容)
4、Head 与服务器索与get请求一致的相应,响应体不会返回,获取包含在小消息头中的原信息(与get请求类似,返回的响应中没有具体内容,用于获取报头)
5、Delete 请求服务器删除request-URL所标示的资源*(请求服务器删除页面)
6、opions 返回服务器针对特定资源所支持的HTML请求方法 或web服务器发送*测试服务器功能(允许客户端查看服务器性能)
九、cookie和session的区别?
1.Cookie存在客户端浏览器中,Session存在服务器上面,所以导致了他们的安全性不同,Cookie存在浏览器中,容易使用浏览器开发工具或者其他方式篡改,而Session存在服务器上就安全许多。
2.Cookie只能存储简单的字符串类型的数据,而Session可以存储复杂的数据类型,例如对象、数组等。
3.存储的数据量不同。因为Session存在服务器上面,所以存的数据量相对Cookie来说要大许多
4.生命周期不同。Session通常会在用户关闭浏览器后过一段时间就失效,而Cookie存在服务器中,可以关闭浏览器之后仍然有效。
十、Jmeter篇
如何实现接口之间的参数调用?
使用json提取器。(使用$.data 来获取返回体内的data)
使用正则表达式提取器。括号里面代表了要提取的部分,点代表匹配任意字符,星号代表出现一次或多次,问号代表在找到第一个匹配项后就停止
如何实现Jmeter的参数化?
1.使用csv提取器。在里面设置文件存放路径以及一些配置即可。在使用参数化变量的时候,用${}即可。
2.使用用户定义的变量。
3.使用数据库提取数据。
接口测试的关注点有哪些?
1.接口的url知否符合规范
2.接口的调用方式是否正确
3.接口的参数格式(包括参数名称、参数类型、是否必填等)
4.接口对异常的处理情况(接口的代码的健壮性)
5.接口的性能如何?
谈谈那些实习测试工程师应该掌握的基础知识(二)_什么时候才能变强的博客-CSDN博客 https://blog.csdn.net/qq_17496235/article/details/131850980
https://blog.csdn.net/qq_17496235/article/details/131850980