谷歌发布West-of-N,利用合成数据,显著提升LLM奖励模型质量 | 今日Arxiv最热大模型论文
导语:论文提出了一种新的通过生成合成偏好数据来提升奖励模型质量的方法,引入了一种自我训练策略,通过筛选最优和最差候选来生成偏好对。实验证明,这种方法可以提高任何奖励模型的性能,效果类似于添加同等量的人类偏好数据。这为改善人类反馈强化学习(RLHF)在语言模型对齐上提供了新的研究方向。
引言:人类反馈对语言模型的影响
在人工智能领域,语言模型的发展已经达到了令人瞩目的水平,它们能够生成流畅、连贯且在很多情况下几乎无法与人类写作有所区分的文本。然而,要使这些模型的输出与人类的价值观保持一致,就需要一种方法来引导它们产生更受人类欢迎和认可的结果。这种方法通常是通过人类反馈来实现的,即通过从人类反馈中学习(Reinforcement Learning from Human Feedback, RLHF)的方式,来调整模型的响应结果,使其更符合人类的偏好。
人类反馈在这个过程中扮演了至关重要的角色。它不仅涉及到收集数据的成本和时间,还包括如何准确地建模人类的偏好。这些偏好是主观的、复杂的,并且依赖于文本质量。因此,如何有效地生成和利用这些数据,成为了提升语言模型性能的关键。
在最近的研究中,一种新颖的方法被提出用来增强奖励模型训练,即通过生成高质量的、符合策略的合成偏好数据。这种方法利用了语言模型策略的生成能力,产生了一种半监督训练框架。通过这种方法,研究人员能够在不增加人类标注数据的情况下,显著提高奖励模型的性能。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接!
论文标题:
West-of-N: Synthetic Preference Generation for Improved Reward Modeling
论文链接:
https://arxiv.org/pdf/2401.12086.pdf
人类反馈的重要性与挑战
人类反馈在大型语言模型(LLMs)的发展中扮演着至关重要的角色。通过人类反馈的强化学习(RLHF),模型的行为可以更好地与人类价值观保持一致。这一策略通过定义一个捕捉文本质量的主观、复杂和上下文依赖性的损失函数,引导模型响应偏向于首选输出。因此,准确建模人类偏好成为了这一范式的关键方面,这涉及到收集反馈数据的昂贵和耗时过程。
偏好模型的质量受到多个因素的影响,包括人类反馈数据的数量、评估响应的分布以及偏好标签的准确性。基于这些观察,我们提出了一种新颖的方法,通过生成高质量的、符合策略的合成偏好数据来增强奖励模型训练。这种方法利用语言模型策略的生成能力,产生一个半监督训练框架。
1. West-of-N 采样策略的定义
West-of-N 采样策略是基于最佳N个采样(Best-of-N sampling)的生成策略,它产生N个输出并选择根据奖励模型得分最高的一个。在我们的工作中,West-of-N 采样策略通过从给定未标记提示的N个输出中提取最好和最差的生成来生成合成偏好数据。这种自我训练的形式有效地扩充了任何初始偏好数据集,并且使用高质量的、符合策略的偏好来增强它。
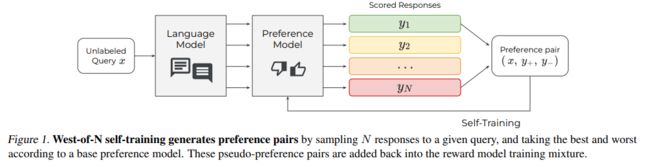
2. 生成合成偏好数据的方法
我们的方法基于自我训练,假设有一些初始偏好数据集,可以包括人类偏好或其他合成生成的数据。我们使用这些数据来训练一个基础偏好模型,该模型参数化为θ,让θ模型化为查询x下响应y+比y−更受偏好的概率。为了给未标记的查询x生成合成偏好数据,可以从生成策略π(x)中采样两个响应y1, y2,并对偏好进行伪标记。这种方法可以用来生成一个伪偏好数据集DL′,并且可以在DL ∪ DL′上优化一个自我训练的学生奖励模型,参数化为θ′。
3. West-of-N 在偏好建模中的理论保证
我们提出了一个理论保证,假设,对于所有的,对于任何,West-of-N偏好对被正确标记的概率ϵ。这个结果强调了West-of-N偏好对有很高的被正确标记的概率。正确标记的概率取决于基础模型在估计真实偏好函数方面的表现。
为了进一步提高生成偏好对的质量,可以根据偏好标签的置信度(换言之,最好和最差响应的可分性)以及它们对相关响应分布的覆盖度来过滤这些偏好对。我们通过预测θ来衡量模型对标记偏好的置信度,并且只保留高于某个分位数的West-of-N对。同样,我们也应用了对正面和负面响应的可能性,π和π的似然阈值,以确保被比较的响应保持在分布内。我们通过验证性能来确定最终的阈值。
实验设计:数据集与方
1. 使用的数据集简介
在我们的研究中,我们使用了两个数据集进行实验验证:Reddit TL;DR摘要数据集和Anthropic Helpful and Harmless问答对话数据集。Reddit TL;DR数据集包含约129,000个Reddit帖子及其人类编写的摘要,以及64,000对由人类评价员评分的模型生成摘要。AnthropicHH数据集则包含170,000对模型生成的对话响应,这些响应也由人类评价员根据其有用性和无害性进行评分,其中大约70%的数据集关注有用性,而30%关注无害性.
2. 政策模型和奖励模型的构建
政策模型和奖励模型均采用T5-XXL(11B)模型。
-
首先,我们对政策模型进行监督式微调,使用人类摘要(TL;DR数据集)或偏好对中的积极响应(AnthropicHH数据集)。
-
然后,我们使用人类偏好数据的50%作为基础偏好数据(HF50%),以便比较West-of-N提升效果与增加人类反馈数据量(HF100%)的效果。除非另有说明,West-of-N采样使用从SFT模型中采样的N=64个生成响应,使用剩余50%的HF数据中的查询。
基础模型以成对方式进行训练,通过比赛来确定最佳和最差的生成。自训练的奖励模型以点对点方式进行训练,训练数据中包含基础偏好和West-of-N偏好的1:1混合。
West-of-N 的性能提升
1. 与人类反馈数据的比较
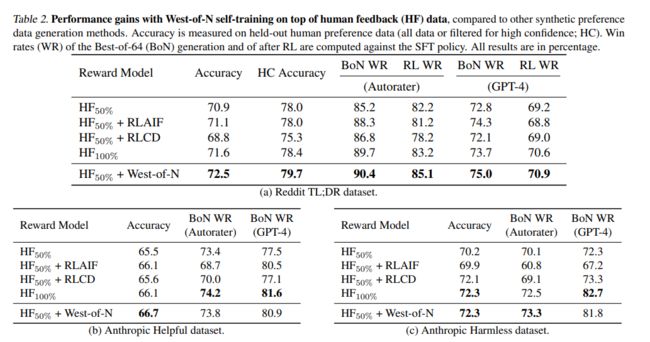
我们的实验结果表明,West-of-N自训练在人类反馈数据之上取得了显著的性能提升。这些提升不仅在保留的人类偏好数据的准确性上得到了体现,更重要的是,也转化为了在Best-of-N采样或强化学习微调后更高的模型质量。当基础奖励模型的质量更高时,自训练的收益更大,因为伪标签的噪声更少。我们甚至发现,West-of-N提供的性能提升与增加相同数量的人类标记偏好数据(HF100%)相当或更大。
2. 与其他合成偏好数据生成方法的比较
我们将我们的方法与两种其他合成偏好数据生成技术进行了比较。这两种方法都是通过将人类反馈和合成数据混合在RM训练中实现的,与我们的方法相比,这显著提高了它们的性能。我们确保在AnthropicHH数据集上也验证了我们的方法,这使我们能够使用原始RLCD和RLAIF论文中提出的偏好生成的确切设置。West-of-N自训练始终在所有数据集上提高了性能,尽管当基础奖励模型的准确性较低时,收益较小——这会影响伪偏好标签的质量。
深入分析 West-of-N 的优
1. 偏好标签的质量提升
West-of-N 是一种生成策略,它通过从 N 个输出中选择最佳和最差的生成来创建合成偏好数据。这种方法的核心优势在于其能够提升偏好标签的质量。通过这种自训练方法,可以有效地扩充初始偏好数据集,生成高质量的、符合策略的偏好数据。这种方法不仅提高了奖励模型的性能,而且与增加相同数量的人类偏好数据相比,效果相当或更好。

在实际应用中,West-of-N 通过最大化基础偏好模型正确标记一对策略响应的概率,来生成合成偏好数据。通过这种方法,生成的偏好对有很高的概率被正确标记,这取决于基础模型在估计真实偏好函数方面的性能.

2. 生成在策略偏好数据的重要性
West-of-N 方法的另一个优势在于它强调了生成在策略偏好数据的重要性。这种方法生成的数据与策略模型的响应分布一致,即所谓的“在策略”数据。这种一致性对于奖励模型的优化至关重要,因为它确保了在训练过程中使用的数据与模型在实际应用中遇到的数据分布相匹配。
在实验中,West-of-N 生成的数据与人类反馈数据相比,更有可能是“在策略”的,这解释了为什么自训练可以提高奖励模型的性能。此外,通过迭代使用 West-of-N,可以在强化学习微调后生成新的在策略合成偏好数据,从而进一步提高奖励模型的性能。
迭代 West-of-N:一种新的自训练方法
迭代 West-of-N 是一种新的自训练方法,它通过在每次迭代中使用前一次迭代的奖励模型作为基础偏好模型,来生成新的在策略合成偏好数据。这种方法可以在不断改进的奖励模型和策略模型之间形成一个正反馈循环,从而逐步提高模型的性能。
在实验中,迭代 West-of-N 方法在减少对人类反馈数据准确性的依赖的同时,显著提高了最佳生成候选的质量。这表明,即使在持有的人类偏好数据上的准确性可能有所下降,迭代 West-of-N 仍能改善奖励模型在识别高奖励生成方面的性能,这与奖励模型的推理分布完全匹配。

总之,West-of-N 和其迭代方法提供了一种有效的策略,通过生成高质量的在策略偏好对来提升奖励模型的性能,这一点在多个数据集和不同类型的初始偏好数据上都得到了验证。
##结论与未来展望
1. West-of-N 在奖励建模中的潜力
本研究提出了一种新颖的方法,即通过West-of-N采样技术生成高质量的合成偏好数据,以增强奖励模型训练。这种方法利用了语言模型策略的生成能力,通过从N个输出中选择最佳和最差的生成来产生半监督训练框架。实验结果表明,West-of-N自训练不仅提高了奖励模型的性能,而且其效果可与增加相同数量的人类偏好数据相媲美,甚至更好。
未来,West-of-N的应用潜力巨大。首先,它为奖励模型提供了一种有效的训练方法,能够在不增加人工反馈数据成本的情况下,显著提升模型性能。其次,由于生成的偏好数据是高质量的,在策略模型中,这些数据能够更好地反映真实的用户偏好。此外,West-of-N生成的数据是基于当前策略的(on-policy),这意味着它们更贴近于模型在实际应用中可能遇到的数据分布,从而使得奖励模型在实际应用中的表现更加准确和鲁棒。
2. 自训练文献中的潜在方法对未来研究的启示
自训练作为一种半监督学习范式,已经在计算机视觉、机器翻译和视觉-语言模型等领域取得了显著的性能提升。在本研究中,自训练的应用通过West-of-N采样技术进一步扩展到了奖励模型训练的背景下。通过这种方法,我们不仅能够利用现有的偏好数据集,还能够生成新的高质量的合成偏好数据,从而提升奖励模型的性能。
未来的研究可以从以下几个方面受到启发:
-
首先,可以探索更多自训练文献中的方法,如噪声学生训练,以进一步提高West-of-N训练的奖励模型的性能。
-
其次,可以研究如何更有效地过滤和选择合成偏好数据,以确保数据的质量和对模型训练的贡献。
-
此外,迭代式的West-of-N自训练方法也展示了在模型训练过程中逐步改进奖励模型的潜力,这为未来的研究提供了新的思路。
总之,West-of-N采样和半监督学习策略在奖励建模中展现出了巨大的潜力,未来的研究可以在这一基础上进一步探索,以实现更高效、更准确的语言模型对齐。
声明:本期论文解读非人类撰写,全文由 赛博马良「AI论文解读达人」 智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接!