Android MediaCodec解析
Android MediaCodec解析
1 引言
MediaCodec是Android平台提供的一个底层的音视频编解码框架,它是安卓底层多媒体基础框架的重要组成部分。它经常和 MediaExtractor, MediaSync, MediaMuxer, MediaCrypto, MediaDrm, Image, Surface, AudioTrack一起使用。解码的作用,就是将视频/音频压缩编码数据,解码成为非压缩的视频/音频原始数据。反之,编码的作用,就是将非压缩的视频/音频原始数据转为视频/音频压缩编码数据。
1.1编写目的
本文档编制旨在说明和总结Android 音视频编解码相关知识,供开发人员查阅与参考。
1.2术语定义及说明
编码:编码就是将原始音频数据也就是PCM压缩的一个过程;或者是将原始的视频数据RGB或YUV压缩的一个过程。
解码:解码就是编码一个逆过程,比如将编码后的数据AAC解码成PCM给播放器播放;或者将编码后的H264数据解码成YUV或RGB给播放器渲染的过程
编解码又分为硬件编解码和软件编解码:
软编软解码:使用CPU进行编码,一般是执行代码运行算法指令编码。
硬编硬解码:使用非CPU进行编码,如显卡GPU、专用的DSP、FPGA、ASIC芯片等,一般是算法已经固化在芯片中。
一般来说,软编码会使CPU负载更重,所以性能相对比硬编要低,不过兼容性一般比硬编好,低码率下质量通常比硬编码要好一点。而硬编码一般性能比软编码好一些,但是兼容性就差一些,低码率下通常质量低于软编码的。
视频帧:视频的每一张静态图片就叫一帧
视频帧又分为I帧、B帧和P帧:
I帧:帧内编码帧,大多数情况下I帧就是关键帧,就是一个完整帧,无需任何辅助就能独立完整显示的画面。
B帧:帧是双向预测帧。参考前后图像帧编码生成。需要前面的 I/P 帧或者后面的 P 帧来协助形成一个画面。
P帧:前向预测编码帧。是一个非完整帧,通过参考前面的I帧或P帧生成画面。
所以 I 帧是很关键的存在,压缩 I 帧就可以很容易压制掉空间的大小,而压缩P帧和B帧可以压缩掉时间上的冗余信息 。
GOP:group of picture,就是两个 I 帧之间的距离,一般 GOP 设置得越大,画面的效果就会越好,到那时需要解码的时间就会越长。所以如果码率固定而 GOP 值越大,P/B帧 数量会越多,画面质量就会越高
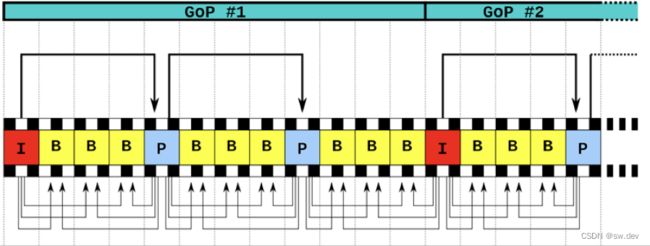
所以在视频 seek 的时候,I 帧很关键,如果视频 seek 之后发生往前的跳动,有可能就是你要seek到的位置没用关键帧,这就需要处理了。好像Android自带的播放器就会有这个问题,有时候无法精确地seek到某个位置。
封装格式:封装格式业界也有人称音视频容器,比如我们经常看到的视频后缀名:mp4、rmvb、avi、mkv、mov等就是音视频的容器,它们将音频和视频甚至是字幕一起打包进去,封装成一个文件。
2.MediaCodec工作流程
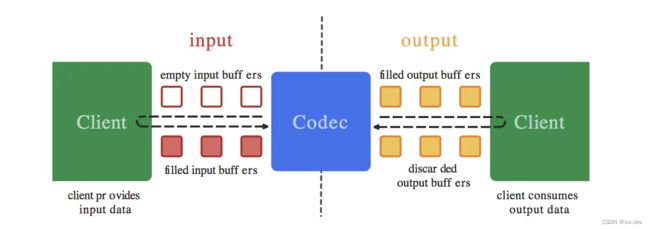
左边是输入端,右边是输出端。其中有输入和输出端各有若干个buffer,输入端不断拿到一个空buffer,装上数据,再传入MediaCodec直到所有数据输入为止。输出端不断从MediaCodec获取到buffer,每次得到处理好的数据后,再将buffer交还给MediaCodec。
mediacodec接受三种数据格式:压缩数据、原始音频数据和原始视频数据。压缩数据一般是解码端的输入和编码端的输出,反之原始音频数据和原始视频数据一般是编码的输入和解码端的输出。
3.MediaCodec工作生命周期

MediaCodec就是一个状态机,在工作期间会经历多个状态阶段。具体来说是总共有三个大状态:Stopped, Executing ,Released,其中Stopped包含Uninitialized, Configured and Error三个小状态,Executing包含Flushed, Running and End-of-Stream三个小状态。
当MediaCodec对象实例刚创建好的时候,处于Stopped状态中的Uninitialized状态,此时需要调用configure方法,就能进入Configured状态,一个start方法的调用,此时进入Executing状态了,目前暂时处于Flushed状态,dequeueInputBuffer方法的调用返回值为bufferIndex。这也能看出api设计不人性化的地方,不是直接返回对应buffer,还要使用bufferIndex再获取一次buffer。再通过queueInputBuffer正式进入Running状态。MediaCodec工作阶段大部分时间都处于Running状态中,在Running状态不断的由input端queueInputBuffer,output端dequeueOutputBuffer,形成一个循环,直到input端加上BUFFER_FLAG_END_OF_STREAM标签,MediaCodec拿到此状态后不再接受任何新的数据输入,即进入End-of-Stream状态。调用stop此时又回到了Stopped状态中的Uninitialized状态。调用release方法来释放所有的资源进入Released状态。
中间过程可能会出现一些意外,就会进入Stopped中的Error状态,这时候有2个选择,一个是直接关门(release)进入Released状态,一个从Stopped状态中的Uninitialized状态重新开始。
4.MediaCodec代码实例
前面已经叙述了MediaCodec工作流程和工作周期状态机,下面从代码角度详细解析MediaCodec。
4.1解复用代码
复用,也可以叫做封装,即将已经压缩编码的视频数据和音频数据按照一定的格式打包到一起,比如我们都很熟悉的MP4,MKV,RMVB,TS,FLV,AVI,就是复用格式。比如FLV格式的数据,是由H.264编码的视频码流和AAC编码的音频码流打包一起。
通过MediaExtractor来获取视频的宽高:
//解复用
MediaExtractor extractor = null;
try {
extractor = new MediaExtractor();
//传入视频文件的路径
extractor.setDataSource(sourceFile.toString());
int trackIndex = selectTrack(extractor);
if (trackIndex < 0) {
throw new RuntimeException("No video track found in " + mSourceFile);
}
//选中得到的轨道(视频轨道),即后面都是对此轨道的处理
extractor.selectTrack(trackIndex);
//通过该轨道的MediaFormat得到对视频对应的宽高
MediaFormat format = extractor.getTrackFormat(trackIndex);
Log.d(TAG, "extractor.getTrackFormat format" + format);
//视频对应的宽高
mVideoWidth = format.getInteger(MediaFormat.KEY_WIDTH);
mVideoHeight = format.getInteger(MediaFormat.KEY_HEIGHT);
if (VERBOSE) {
Log.d(TAG, "Video size is " + mVideoWidth + "x" + mVideoHeight);
}
} finally {
if (extractor != null) {
extractor.release();
}
}
通过获取到的mime类型来创建一个MediaCodec解码器:
MediaFormat format = extractor.getTrackFormat(trackIndex);
Log.d(TAG, "EgetTrackFormat format:" + format);
// Create a MediaCodec decoder, and configure it with the MediaFormat from the
// extractor. It's very important to use the format from the extractor because
// it contains a copy of the CSD-0/CSD-1 codec-specific data chunks.
String mime = format.getString(MediaFormat.KEY_MIME);
Log.d(TAG, "createDecoderByType mime:" + mime);
//通过视频mime类型初始化解码器
MediaCodec decoder = MediaCodec.createDecoderByType(mime);
此时MediaCodec处于Stopped状态中的Uninitialized状态,接下来开始启动MediaCodec
//配置解码器,指定MediaFormat以及视频输出的Surface,解码器进入configure状态
decoder.configure(format, mOutputSurface, null, 0);
//启动解码器,开始进入Executing状态
// Immediately after start() the codec is in the Flushed sub-state, where it holds all the buffers
decoder.start();
//具体的解码流程
doExtract(extractor, trackIndex, decoder, mFrameCallback);
此时MediaCodec已经启动,此时已经进入input端和output端的大循环阶段
/**
* 循环工作。直到视频用完或被告知停止。
*/
private void doExtract(MediaExtractor extractor, int trackIndex, MediaCodec decoder,
FrameCallback frameCallback) {
//获取解码输出数据的超时时间
final int TIMEOUT_USEC = 0;
//输入ByteBuffer数组(较高版本的MediaCodec已经用getInputBuffer取代了,可直接获取buffer)
ByteBuffer[] decoderInputBuffers = decoder.getInputBuffers();
//记录传入了第几块数据
int inputChunk = 0;
//用于log每帧解码时间
long firstInputTimeNsec = -1;
boolean outputDone = false;
boolean inputDone = false;
while (!outputDone) {
if (VERBOSE) Log.d(TAG, "loop");
if (mIsStopRequested) {
Log.d(TAG, "Stop requested");
return;
}
// 将更多数据馈送到解码器.
if (!inputDone) {
//拿到可用的ByteBuffer的index
int inputBufIndex = decoder.dequeueInputBuffer(TIMEOUT_USEC);
if (inputBufIndex >= 0) {
if (firstInputTimeNsec == -1) {
firstInputTimeNsec = System.nanoTime();
}
//根据index得到对应的输入ByteBuffer
ByteBuffer inputBuf = decoderInputBuffers[inputBufIndex];
Log.d(TAG, "decoderInputBuffers inputBuf:" + inputBuf + ",inputBufIndex:" + inputBufIndex);
//从媒体文件中读取的一个sample数据大小
int chunkSize = extractor.readSampleData(inputBuf, 0);
if (chunkSize < 0) {
//文件读到末尾,设置标志位,发送一个空帧,给后面解码知道具体结束位置
decoder.queueInputBuffer(inputBufIndex, 0, 0, 0L,
MediaCodec.BUFFER_FLAG_END_OF_STREAM);
Log.d(TAG, "queueInputBuffer");
inputDone = true;
if (VERBOSE) Log.d(TAG, "sent input EOS");
} else {
if (extractor.getSampleTrackIndex() != trackIndex) {
Log.w(TAG, "WEIRD: got sample from track " +
extractor.getSampleTrackIndex() + ", expected " + trackIndex);
}
//得到当前数据的播放时间点
long presentationTimeUs = extractor.getSampleTime();
//把inputBufIndex对应的数据传入MediaCodec
decoder.queueInputBuffer(inputBufIndex, 0, chunkSize,
presentationTimeUs, 0 /*flags*/);
Log.d(TAG, "queueInputBuffer inputBufIndex:" + inputBufIndex);
if (VERBOSE) {
Log.d(TAG, "submitted frame " + inputChunk + " to dec, size=" +
chunkSize);
}
//记录传入了第几块数据
inputChunk++;
//extractor读取游标往前挪动
extractor.advance();
}
} else {
if (VERBOSE) Log.d(TAG, "input buffer not available");
}
}
if (!outputDone) {
//如果解码成功,则得到解码出来的数据的buffer在输出buffer中的index。并将解码得到的buffer的相关信息放在mBufferInfo中。
// 如果不成功,则得到的是解码的一些状态
int outputBufferIndex = decoder.dequeueOutputBuffer(mBufferInfo, TIMEOUT_USEC);
Log.d(TAG, "dequeueOutputBuffer decoderBufferIndex:" + outputBufferIndex + ",mBufferInfo:" + mBufferInfo);
if (outputBufferIndex == MediaCodec.INFO_TRY_AGAIN_LATER) {
if (VERBOSE) Log.d(TAG, "no output from decoder available");
} else if (outputBufferIndex == MediaCodec.INFO_OUTPUT_BUFFERS_CHANGED) {
if (VERBOSE) Log.d(TAG, "decoder output buffers changed");
} else if (outputBufferIndex == MediaCodec.INFO_OUTPUT_FORMAT_CHANGED) {
MediaFormat newFormat = decoder.getOutputFormat();
if (VERBOSE) Log.d(TAG, "decoder output format changed: " + newFormat);
} else if (outputBufferIndex < 0) {
throw new RuntimeException(
"unexpected result from decoder.dequeueOutputBuffer: " +
outputBufferIndex);
} else { // decoderStatus >= 0
if (firstInputTimeNsec != 0) {
// Log the delay from the first buffer of input to the first buffer
// of output.
long nowNsec = System.nanoTime();
Log.d(TAG, "startup lag " + ((nowNsec - firstInputTimeNsec) / 1000000.0) + " ms");
firstInputTimeNsec = 0;
}
boolean doLoop = false;
if (VERBOSE) Log.d(TAG, "surface decoder given buffer " + outputBufferIndex +
" (output mBufferInfo size=" + mBufferInfo.size + ")");
//判断是否到了文件结束,上面设置MediaCodec.BUFFER_FLAG_END_OF_STREAM标志位在这里判断
if ((mBufferInfo.flags & MediaCodec.BUFFER_FLAG_END_OF_STREAM) != 0) {
if (VERBOSE) Log.d(TAG, "output EOS");
if (mLoop) {
doLoop = true;
} else {
outputDone = true;
}
}
//如果解码得到的buffer大小大于0,则需要渲染
boolean doRender = (mBufferInfo.size != 0);
if (doRender && frameCallback != null) {
//渲染前的回调,这里具体实现是通过一定时长的休眠来尽量确保稳定的帧率
frameCallback.preRender(mBufferInfo.presentationTimeUs);
}
//得到输出Buffer数组,较高版本已经被getOutputBuffer代替
ByteBuffer[] decoderOutputBuffers = decoder.getOutputBuffers();
Log.d(TAG, "ecoderOutputBuffers.length:" + decoderOutputBuffers.length);
//将输出buffer数组的第outputBufferIndex个buffer绘制到surface。doRender为true绘制到配置的surface
decoder.releaseOutputBuffer(outputBufferIndex, doRender);
if (doRender && frameCallback != null) {
//渲染后的回调
frameCallback.postRender();
}
if (doLoop) {
Log.d(TAG, "Reached EOS, looping");
//需要循环的话,重置extractor的游标到初始位置。
extractor.seekTo(0, MediaExtractor.SEEK_TO_CLOSEST_SYNC);
inputDone = false;
//重置decoder到Flushed状态,不然就没法开始新一轮播放
decoder.flush(); // reset decoder state
frameCallback.loopReset();
}
}
}
}
}
4.2方法解释
- 询问Mediacodec当前有没有可以input的Buffer可以使用:
int inputBufIndex = decoder.dequeueInputBuffer(TIMEOUT_USEC);
TIMEOUT_USEC为等待超时时间。当返回的inputBufIndex大于等于0,则说明当前有可用的Buffer,此时inputBufIndex表示可用Buffer在Mediacodec中的序号。如果等待了TIMEOUT_USEC时间还没找到可用的Buffer,则返回inputBufIndex小于0,等下次循环再来取Buffer。
-
每次从MediaExtractor中的readSampleData方法读出视频一段数据放在ByteBuffer中,然后通过Mediacodec的queueInputBuffer将ByteBuffer传给Mediacodec内部处理。
//从媒体文件中读取的一个sample数据大小到inputBuf中 int chunkSize = extractor.readSampleData(inputBuf, 0);readSampleData方法是读取一帧的数据。返回值为读取到数据大小,所以如果返回值大于0,则说明是有读取到数据的,则将数据传入MediaCodec中:
//得到当前数据的播放时间点
long presentationTimeUs = extractor.getSampleTime();
//把inputBufIndex对应的数据传入MediaCodec
decoder.queueInputBuffer(inputBufIndex, 0, chunkSize,
presentationTimeUs, 0 /*flags*/);
如果readSampleData方法返回值,即读到的数据大小为负数,则说明已经读到视频文件尾部了,则还是调用queueInputBuffer方法,但是需要特殊处理:
decoder.queueInputBuffer(inputBufIndex, 0, 0, 0L,
MediaCodec.BUFFER_FLAG_END_OF_STREAM);
发送一个空帧,标志位传BUFFER_FLAG_END_OF_STREAM,告诉MediaCodec,已经到文件尾部了,这个文件没有剩下需要传的数据了。
input端的代码就到这,然后立刻到ouptut端去尝试获取一下output的buffer。
int outputBufferIndex = decoder.dequeueOutputBuffer(mBufferInfo, TIMEOUT_USEC);
如果不成功,则得到的是解码的一些状态,以下几种常见 的状态:
1.MediaCodec.INFO_TRY_AGAIN_LATER:表示等了TIMEOUT_USEC时间长,也暂时还没有解码出成功的数据。一般来说,一个是等待时间还不够,另一个就是输入端是B帧,需要后面一帧P帧来作为参考帧才可以解码。
2.MediaCodec.INFO_OUTPUT_BUFFERS_CHANGED:输出Buffer数组已经过时,需要及时更换,由于较新版本已经用getOutputBuffer获取输出Buffer了,所以该标志位也过时了。
3.MediaCodec.INFO_OUTPUT_FORMAT_CHANGED:输出数据的MediaFormat发生了变化。
如果解码成功,则得到解码出来的数据的buffer在输出buffer中的index。并将解码得到的buffer的相关信息放在mBufferInfo中。然后执行非常关键的一段代码:
decoder.releaseOutputBuffer(outputBufferIndex, doRender);
将输出buffer数组的第outputBufferIndex个buffer绘制到surface(还记得configure方法传了的Surface对象么)。doRender为true,绘制到配置的surface。可以理解这行代码就类似Android中Canvas的draw方法,调用就绘制一帧,并将Buffer回收。