Deeplab系列语义分割模型
目录
- 一、网络模型
-
- 1.deeplabv1
- 2.deeplabv2
- 3.deeplabv3
- 4.deeplabv3+
- 二、空洞卷积
- 三、代码实现
- 总结
一、网络模型
1.deeplabv1

2.deeplabv2

3.deeplabv3
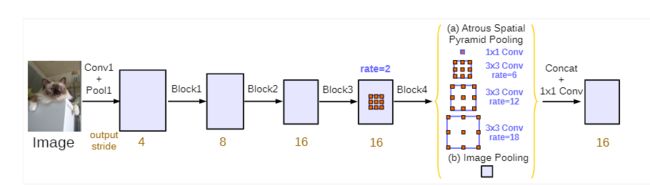
4.deeplabv3+

二、空洞卷积
空洞卷积(Dilatee/Atrous Convolution)是一种特殊的卷积算子,针对卷积神经网络在下采样时图像分辨率降低、部分信息丢失而提出的卷积思路,通过在卷积核中添加空洞以获得更大的感受野。

- 3x3卷积核,dilation rate 分别为1, 2, 4,空洞部分填充零。
- 输入大小为[H,W],卷积核大小为{FH,FW],填充为P,步幅为S,计算输出大小
O H = H + 2 P − F H S + 1 O W = W + 2 P − F W S + 1 \begin{aligned} &O H=\frac{H+2 P-F H}{S}+1 \\ &O W=\frac{W+2 P-F W}{S}+1 \end{aligned} OH=SH+2P−FH+1OW=SW+2P−FW+1 - 3x3卷积核可以等效为5x5,假设卷积核大小k=3,空洞数d=2,则等效卷积核k‘,感受野RF,第一层感受野为3,Si为之前所有层步长的乘积。RFa=3,RFb=5,RFc=8。
k ′ = k + ( k − 1 ) × ( d − 1 ) R F i + 1 = R F i + ( k ′ − 1 ) × S i S i = ∏ i = 1 i Stride i \begin{aligned} &k^{\prime}=k+(k-1) \times(d-1)\\ &R F_{i+1}=R F_{i}+\left(k^{\prime}-1\right) \times S_{i}\\ &S_{i}=\prod_{i=1}^{i} \text { Stride }_{i} \end{aligned} k′=k+(k−1)×(d−1)RFi+1=RFi+(k′−1)×SiSi=i=1∏i Stride i
k ′ = 3 + ( 3 − 1 ) × ( 2 − 1 ) = 5 R F i + 1 = 3 + ( 5 − 1 ) × S i S i = ∏ i = 1 i Stride i = 1 \begin{aligned} &k^{\prime}=3+(3-1) \times(2-1)=5\\ &R F_{i+1}=3+(5-1) \times S_{i}\\ &S_{i}=\prod_{i=1}^{i} \text { Stride }_{i}=1 \end{aligned} k′=3+(3−1)×(2−1)=5RFi+1=3+(5−1)×SiSi=i=1∏i Stride i=1
传统卷积算子只对局部邻域内的数值运算,使得训练的网络模型对局部特征信息异常敏感,在医学领域的细胞图像分割上取得重大进展。庞大的、复杂的的输入图像则更看重全局信息,空洞卷积算子的提出完美地解决了这个问题,越是深层网络的卷积核,同样能够感受到输入层的全局信息,训练参数不变的前提下,视野更开阔。

三、代码实现
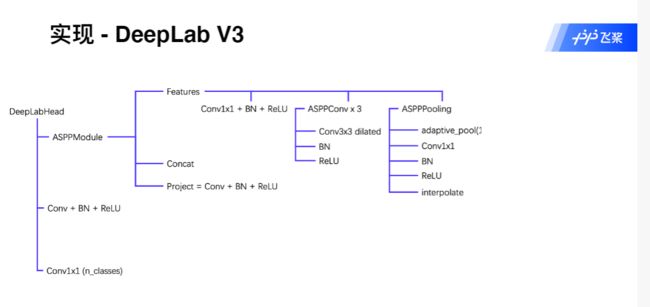
"""
paddlepaddle-gpu==2.2.1
author:CP
Deeplabv3
"""
import paddle
import paddle.nn as nn
class ASPPPooling(nn.Layer):
def __init__(self,num_channels,num_filters):
super(ASPPPooling,self).__init__()
self.adaptive_pool = nn.AdaptiveMaxPool2D(output_size=3)
self.features = nn.Sequential(
nn.Conv2D(num_channels, num_filters,1),
nn.BatchNorm(num_filters, act="relu")
)
def forward(self, inputs):
n1, c1, h1, w1 = inputs.shape
x = self.adaptive_pool(inputs)
x = self.features(x)
x = nn.functional.interpolate(x, (h1, w1), align_corners=False)
return x
class ASPPConv(nn.Layer):
def __init__(self,num_channels,num_filters,dilations):
super(ASPPConv,self).__init__()
self.asppconv = nn.Sequential(
nn.Conv2D(num_channels,num_filters,3,padding=dilations,dilation=dilations),
nn.BatchNorm(num_filters, act="relu")
)
def forward(self,inputs):
x = self.asppconv(inputs)
return x
#ASPP模块最大的特点是使用了空洞卷积来增大感受野
class ASPPModule(nn.Layer):
def __init__(self, num_channels, num_filters, rates):
super(ASPPModule, self).__init__()
self.features = nn.LayerList()
#层一
self.features.append(nn.Sequential(
nn.Conv2D(num_channels, num_filters,1),
nn.BatchNorm(num_filters, act="relu")
)
)
#层二
for r in rates:
self.features.append(ASPPConv(num_channels, num_filters, r))
#层三
self.features.append(ASPPPooling(num_channels, num_filters))
#层四
self.project = nn.Sequential(
nn.Conv2D(num_filters*(2+len(rates)), num_filters, 1),#TODO
nn.BatchNorm(num_filters, act="relu")
)
def forward(self, inputs):
out = []
for op in self.features:
out.append(op(inputs))
x = paddle.concat(x=out,axis=1)
x = self.project(x)
return x
class DeeplabHead(nn.Layer):
def __init__(self, num_channels, num_classes):
super(DeeplabHead, self).__init__()
self.head = nn.Sequential(
ASPPModule(num_channels, 256, [12, 24, 36]),
nn.Conv2D(256, 256, 3, padding=1),
nn.BatchNorm(256, act="relu"),
nn.Conv2D(256, num_classes, 1)
)
def forward(self, inputs):
x = self.head(inputs)
return x
from paddle.vision.models import resnet50
from paddle.vision.models.resnet import BottleneckBlock
class Deeplabv3(nn.Layer):
def __init__(self, num_classes=59, backbone='resnet50'):
super(Deeplabv3, self).__init__()
# resnet50 3->2048
# resnet50 四层layers = [3 4 6 3]
# 调用resnet.py模块,空洞卷积[2 4 8 16]
res = resnet50()
res.inplanes = 64 #初始化输入层
self.layer0 = nn.Sequential(res.conv1, res.bn1, res.relu, res.maxpool)
self.layer1 = res._make_layer(BottleneckBlock, 64,3)
self.layer2 = res._make_layer(BottleneckBlock,128,4)
self.layer3 = res._make_layer(BottleneckBlock,256,6)
self.layer4 = res._make_layer(BottleneckBlock,512,3,stride=2,dilate= 2) #dilation=2
self.layer5 = res._make_layer(BottleneckBlock,512,3,stride=2,dilate= 4) #dilation=4
self.layer6 = res._make_layer(BottleneckBlock,512,3,stride=2,dilate= 8) #dilation=8
self.layer7 = res._make_layer(BottleneckBlock,512,3,stride=2,dilate=16) #dilation=16
feature_dim = 2048 #输出层通道2048
self.deeplabhead = DeeplabHead(feature_dim, num_classes)
def forward(self, inputs):
x = self.layer0(inputs)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.layer6(x)
x = self.layer7(x)
x = self.deeplabhead(x)#ASPP模块进行分类
# 恢复原图尺寸
x = paddle.nn.functional.interpolate(x=x, size=inputs.shape[2::], mode='bilinear', align_corners=True)
return x
paddle.summary(Deeplabv3(), (1, 3, 600, 600))
总结


参考文献
[1]Chen L C, Papandreou G, Kokkinos I, et al. Semantic image segmentation with deep convolutional nets and fully connected crfs[J]. arXiv preprint arXiv:1412.7062, 2014.
[2]Chen L C, Papandreou G, Kokkinos I, et al. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 40(4): 834-848.
[3]Chen L C, Papandreou G, Schroff F, et al. Rethinking atrous convolution for semantic image segmentation[J]. arXiv preprint arXiv:1706.05587, 2017.
[4]Chen L C, Zhu Y, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 801-818.
原文阅读
Deeplabv1:SEMANTICIMAGESEGMENTATION WITHDEEPCON-VOLUTIONALNETS ANDFULLYCONNECTEDCRFS
Deeplabv2:DeepLab: Semantic Image Segmentation withDeep Convolutional Nets, Atrous Convolution,and Fully Connected CRFs
Deeplabv3:Rethinking Atrous Convolution for Semantic Image Segmentation
Deeplabv3+:Encoder-Decoder with Atrous SeparableConvolution for Semantic Image Segmentation