python地铁客流数据分析与可视化
文章目录
-
0 前言+ 1 实现目的+ 2 数据集+
-
2.2 数据集概况+ 2.3 数据字段
-
3 实现效果+
-
3.1 地铁数据整体概况+ 3.2 平均指标+ 3.3 地铁2018年9月开通运营的线路+ 3.4 客流量相关统计+
-
3.4.1 线路客流量排行+ 3.4.2 站点客流量排行+ 3.4.3 入站客流排行+ 3.4.4 整体客流随时间变化趋势+ 3.4.5 不同线路客流随时间变化+ 3.4.6 不同线路的客流组成
-
3.5 收入消费指标统计+
-
3.5.1 线路收入排行+ 3.5.2 各个站点对线路收入的贡献+ 3.5.3 不同消费金额次数占比
-
3.6 完整乘车记录中客流统计+
-
3.6.1 数据过滤+ 3.6.2 不同乘车区间客流量排行+ 3.6.3 不同线路区间客流排行
-
3.7 实时计算+
-
3.7.1 将站点客流数据写入 Hbase 中+ 3.7.2 按照不同的业务场景从Hbase中读取数据
-
4 最后
0 前言
这两年开始,各个学校对毕设的要求越来越高,难度也越来越大… 毕业设计耗费时间,耗费精力,甚至有些题目即使是专业的老师或者硕士生也需要很长时间,所以一旦发现问题,一定要提前准备,避免到后面措手不及,草草了事。
1 实现目的
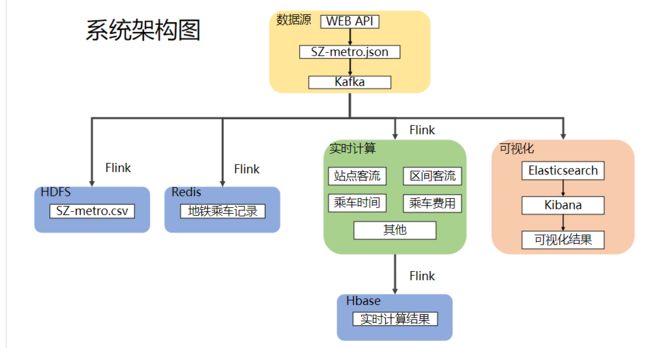
使用 Flink 完成数据清洗和聚合,使用 Elasticsearch + Kibana 的的技术路线,完成了客流信息,地铁收入、乘客车费、乘车区间和乘车时间的查询和可视化。
在此基础上,还使用 Flink 实现了计算各线路、站点和乘车区间的客流信息等实时计算功能,并将实时计算的结果写入到Hbase中,供下游业务查询使用。
2 数据集
2.2 数据集概况
-
数据集共用 1337000 条信息,其中包括 447708 条巴士的乘车信息和 781472 条地铁的出入站信息。巴士数据和地铁数据存在明显的不同:
-
乘坐巴士只需要上车的时候刷卡,因此一条记录就是一次乘车记录+ 而地铁在进出站时均需要刷卡,因此需要同时拥有一张交通卡的进出站记录才能构成一条完整的乘车记录
-
由于巴士的乘车记录比较简单,所有本项目中主要针对地铁的乘车记录进行计算和分析+ 地铁部分数据集的日期是北京时间 2018-09-01 05:00 ~ 2018-09-01-11:35
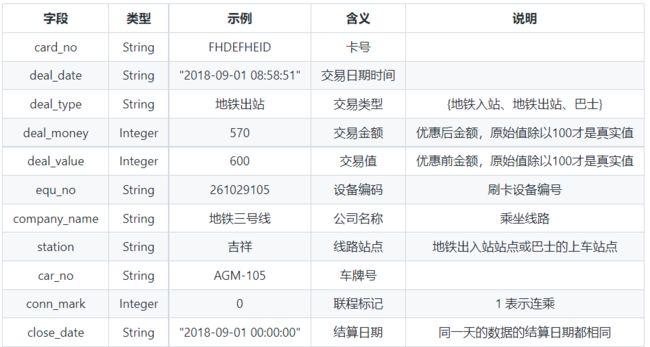
2.3 数据字段
3 实现效果
3.1 地铁数据整体概况
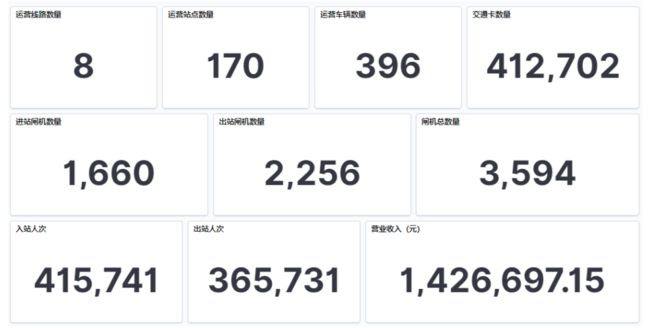
本项目只针对地铁的乘车记录进行分析,下面对数据集的整体概况做介绍,如图 1 所示,当日(2018-09-01 05:00 ~ 2018-09-01-11:35)共计有 8 条线路的 170 个站点完成了 781472 人次的出入站,其中入站 415741 人次、出站 365731 人次,实际营业收入 1426697.15 元。因为不是一个完整的运营日所以出入站乘客人次并不相等。
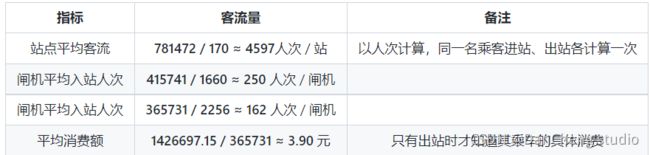
3.2 平均指标
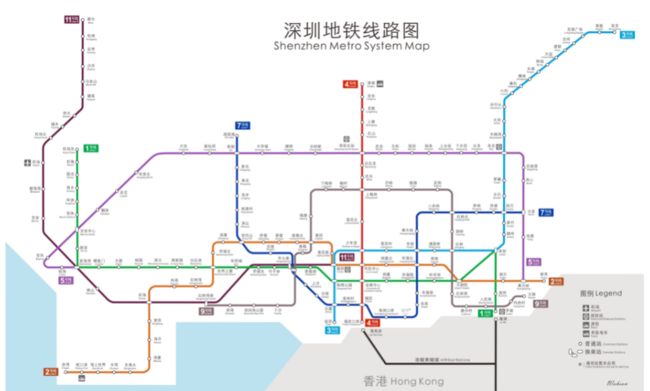
3.3 地铁2018年9月开通运营的线路
2018年9月该地区地铁共计有8条线路投入运行,分别是1号线、2号线、3号线、4号线、5号线、7号线、9号线、11号线,其具体线路图入下所示。
3.4 客流量相关统计
有关使用 Elasticsearch + Kibana实现数据可视化的具体细节。
3.4.1 线路客流量排行
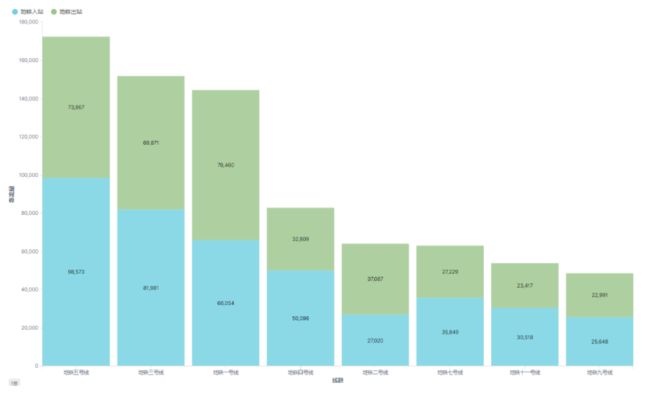
如图所示是线路的客流排行榜,其中蓝色是入站客流,绿色是出站客流,根据图中信息可得到:
- 总客流排名:5 号线、3 号线、1 号线、4 号线、2 号线、7 号线、11 号线、9 号线 + 入站客流排名:5 号线、3 号线、1 号线、4 号线、7 号线、11 号线、9 号线、2 号线 + 出站客流排名:1 号线、5 号线、3 号线、2 号线、4 号线、7 号线、11 号线、9 号线
3.4.2 站点客流量排行
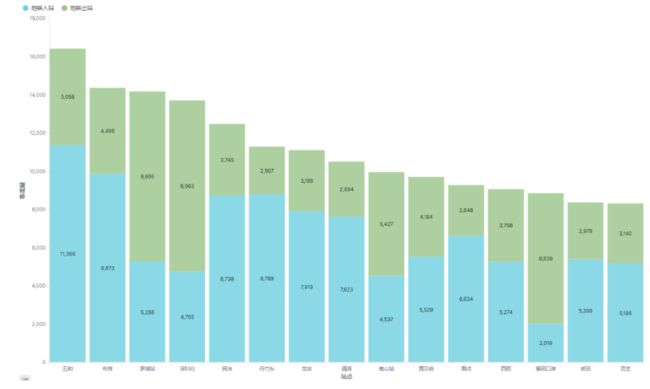
总客流量的排行
从图站点总客流排行可以看出,五和、布吉站(深圳东火车站)、罗湖站(深圳火车站)、深圳北(深圳北高铁站)和民治分列前五,其中五和、布吉和民治入站客流明显多于出站客流,而罗湖站和深圳北则完全相反,这些车站基本都是不同线路的换乘车站。
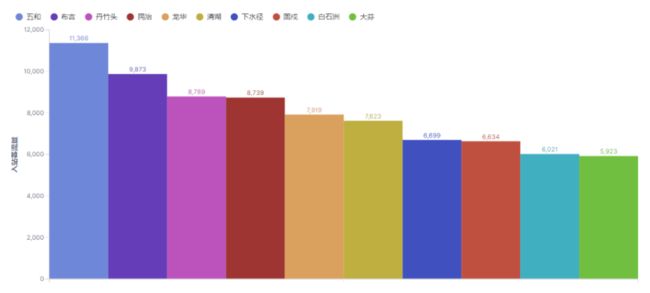
3.4.3 入站客流排行
对于入站客流,五和、布吉(深圳东火车站)、丹竹头、民治和龙华分列前五
3.4.4 整体客流随时间变化趋势
从图 中可以看出,出入站客流随时间变化都出现了明显的高峰,但是具体来说又存在不同:
- 入站客流的高峰在 08:30 附近,早于出站客流高峰的 08:45 附近+ 在 08:37 之前入站的客流都是多于出站客流+ 出站客流在 08:35-08:55 出现了大幅增加,这也与大部分公司固定的 9 点上班相吻合。+ 整体来说入站客流的波动性没有出站客流那么剧烈,因为入站客流相对于地铁到站瞬间大量出站乘客来说相对更平稳没有那么明显的波峰出现。

3.4.5 不同线路客流随时间变化
由于图表篇幅的限制只显示客流量前四的线路。从图 2.8 中可以看出 地铁 5 号线、地铁 3 号线、地铁 1 号线在不同时间段客流量的变化较大,尤其是是 5 号线早高峰十分明显,由此推测人们的工作地点多集中在 5 号线附近,从客流量也可以佐证这个观点。

3.4.6 不同线路的客流组成
以客流量最多的五号线为例,从图 2.9 可以看出五和、深圳北、民治三个站点的客流分别占全线客流的 9.53 9.53% 9.53、 7.96 7.96% 7.96、 7.24 7.24% 7.24,同时这三个站的客流量也排名所以站点客流的第一、第四和第五位,右侧图例从上到下客流量依次减少。
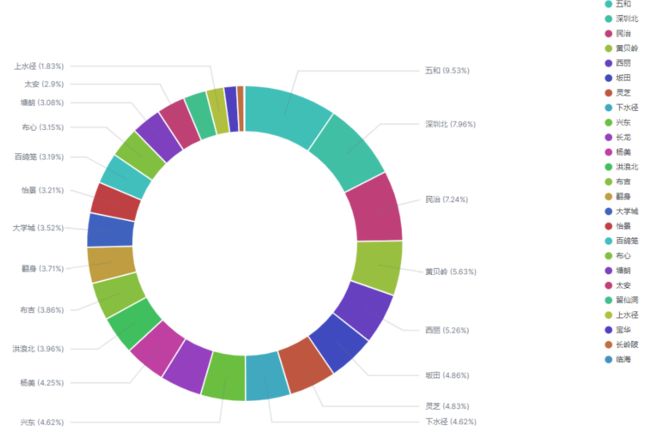
3.5 收入消费指标统计
3.5.1 线路收入排行
从图 可以看出,虽然 1 号线的客流量只能排在 5 号线和 3 号线之后屈居第三,但是其线路的收入却排名第一。而客流量第四的 4 号线其收入只能排在第六位。
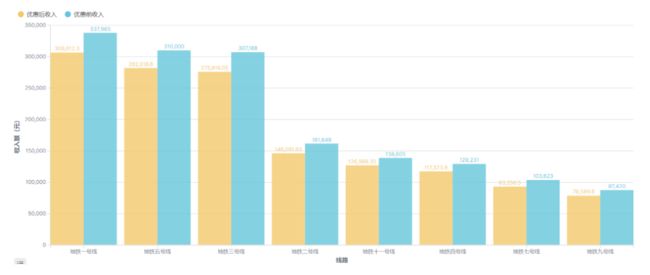
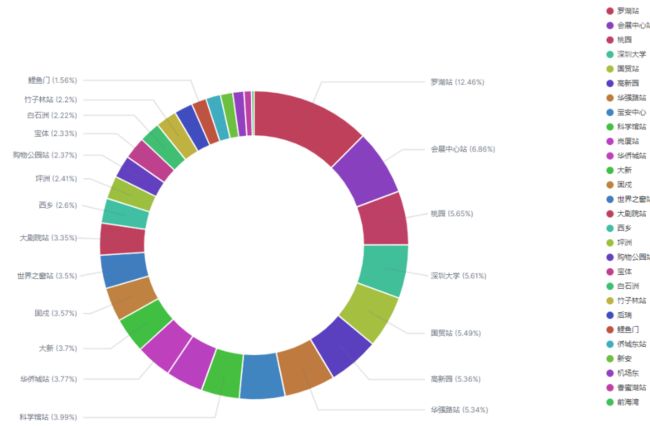
3.5.2 各个站点对线路收入的贡献
以收入最多的地铁 1 号线为例,罗湖站、会展中心站和桃园站对全线的收入贡献分列前三,而前海湾则是全线副班长贡献最少。右侧图例从上到下对线路收入贡献依次减少。
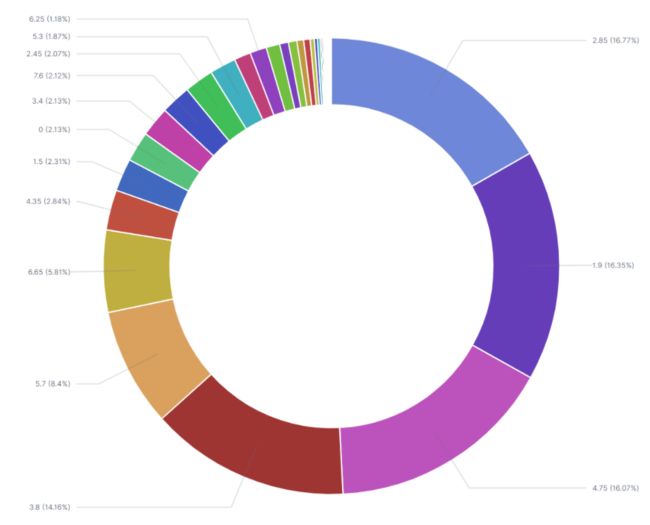
3.5.3 不同消费金额次数占比
从图中可以看出、实际消费金额为 2.85、1.9、4.75、3.8和5.7排名总消费次数的前五。
值得注意的是消费金额为0在总消费次数中的占比为 2.13 2.13% 2.13,这个一方面是深圳地铁确实对部分人群免费乘坐,另外一部分是有内部员工卡产生的。
3.6 完整乘车记录中客流统计
3.6.1 数据过滤
数据中存在大量的数据不能构成完整的情况,如
- 对于一张卡只有入站或车站单条记录的显然不能构成一条完整的行程记录+ 对于入站点和出现点相同的情况显然是不合理的数据,同样不能构成一条合理行程记录+ 对于入站时间在 06:00 之前的记录同样不计算在内,因为深圳地铁的所有线路平均首班车时间在06:20左右,所以猜测可站点对外开放时间不会早于6:00。+ 对于按照时间排序之后同一张卡出现,连续两次均为入站或出站的视为不合法数据
入站时间早于06:00和入站点出站点相同的数据
深圳地铁的运营时间都是 6 点以后,所以之前的数据记录,均有内部工作人员活所产生,视为无效数据
如卡号为 HHJJAFGAH 的用户在同一条线路的同一站点产生的这 6 条数据,从实际消费金额为 0.0 也可以佐证此推论
1535752434000,HHJJAFGAH,0.0,0.0,地铁入站,地铁二号线,0,大剧院,AGM-109,260036109 2018/9/1 5:53:54
1535752629000,HHJJAFGAH,2.0,0.0,地铁出站,地铁二号线,0,大剧院,AGM-117,260036117 2018/9/1 5:57:9
1535754065000,HHJJAFGAH,0.0,0.0,地铁入站,地铁二号线,0,大剧院,AGM-109,260036109 2018/9/1 6:21:5
1535754386000,HHJJAFGAH,2.0,0.0,地铁出站,地铁二号线,0,大剧院,AGM-117,260036117 2018/9/1 6:26:26
1535758541000,HHJJAFGAH,0.0,0.0,地铁入站,地铁二号线,0,大剧院,AGM-113,260036113
1535758687000,HHJJAFGAH,2.0,0.0,地铁出站,地铁二号线,0,大剧院,AGM-105,260036105
随然该持卡人极可能是内部用户,但是下面这条数据将被作为有效数据,因为乘车事件是真实发生的从大剧院 -> 晒布
1535766418000,HHJJAFGAH,0.0,0.0,地铁入站,地铁二号线,0,大剧院,AGM-117,260036117 2018/9/1 9:46:58
1535767398000,HHJJAFGAH,2.0,0.0,地铁出站,地铁三号线,0,晒布,AGM-105,261013105 2018/9/1 10:3:18
连续两次均为入站的数据
1535755820000,CBCGDHCBB,0.0,0.0,地铁入站,地铁五号线,0,太安,AGT-118,263035118
1535759424000,CBCGDHCBB,0.0,0.0,地铁入站,地铁四号线,0,清湖,AGM-105,262011105
1535759862000,CBCGDHCBB,2.0,1.9,地铁出站,地铁四号线,0,清湖,AGM-108,262011108
1535756340000,HHACJJFHE,0.0,0.0,地铁入站,地铁四号线,0,莲花北,AGM-109,262020109
1535756926000,HHACJJFHE,0.0,0.0,地铁入站,地铁四号线,0,上梅林,AGM-110,262019110
1535757664000,HHACJJFHE,2.0,0.0,地铁出站,地铁四号线,0,上梅林,AGM-104,262019104
1535758092000,HHACJJFHE,0.0,0.0,地铁入站,地铁四号线,0,上梅林,AGM-110,262019110
1535758342000,HHACJJFHE,2.0,0.0,地铁出站,地铁四号线,0,莲花北,AGM-107,262020107
经过以上指标过滤之后得到能够构成完整且合理的出入站记录 572156 条,每两条记录组成一条完整的行程记录 ,因此有 286078 条合法行程记录,其中包含了入站和出站的时间、线路、站点、刷卡设备等,还能计算出单次乘车所用时间。
3.6.2 不同乘车区间客流量排行
排名前三的乘车区间是:赤尾 —> 华强北,福民福田 —> 口岸、五和 —> 深圳北
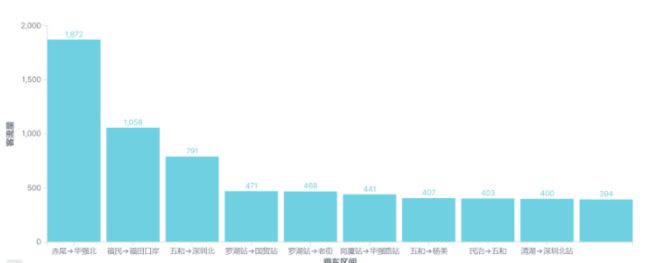
3.6.3 不同线路区间客流排行
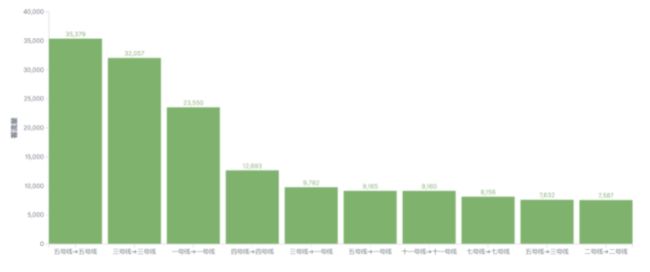
从图可以看出,5 号线直达,3 号线直达和 1 号线直达的客流最多。
3.7 实时计算
通过Flink可以实时计算过去的某个时间段内,个站点的出入站客流量以及总客流量,不同站点区间的客流量,以及不同线路区间的客流量等指标。
对于实时计算的结果可以使用 Redis 或者 Hbase 来进行存储,对于两者的技术特点对比如下:
- Redis作为纯内存NoSQL虽然读写性能十分优秀,但其支持的数据量通常受内存限制,而HBase没有这个限制,可以存储远超内存大小的数据+ HBase采用WAL,先记录日志再写入数据,理论上不会丢失数据。而Redis采用的是异步复制数据,在failover时可能会丢失数据+ 客流信息作为基本不需要再次变动已经固化, 非常适合使用 HBase 来存储。
综上本项目中使用 Hbase 来存储实时计算的数据结果。
3.7.1 将站点客流数据写入 Hbase 中
- 首先在 Hbase shell 中使用以下命令建立存储表
create 'StationTraffic', {NAME => 'traffic'}
- 执行 com.ngt.traffic.HBaseWriterStationTraffic 将站点的客流信息写入 Hbase 中
# 时间 客流排名
2018-09-01 11:30 001 column=traffic:count, timestamp=1609614078234, value=117
2018-09-01 11:30 001 column=traffic:name, timestamp=1609614078234,value=\xE8\x80\x81\xE8\xA1\x97
代码中统计的是,过去五分钟的客流量信息,每一分钟滚动一次
.timeWindow(Time.minutes(5), Time.minutes(1))
3.7.2 按照不同的业务场景从Hbase中读取数据
执行 com.ngt.traffic.HBaseReaderStationTraffic 实现相关功能
需求1:查询 2018-09-01 08:30 - 2018-09-01 08:45 各站点最近五分钟的客流
case class Traffic(time: String, rank: String, station: String, count: String)
val dataStream1: DataStream[(String, String)] =
// 表名,列族名,起始Rowkey,终止Rowkey(取不到)
env.addSource(new HBaseReader("StationTraffic", "traffic","2018-09-01 08:30", "2018-09-01 08:46"))
dataStream1.map(x => {
val keys: Array[String] = x._1.split(" ")
val values: Array[String] = x._2.split("_")
Traffic("时间:" + keys(1), "站点:" + values(1), "排名:" + keys(2), "客流量:" + values(0))
})
.map(data => {
println(data.time, data.rank, data.station, data.count)
})
---------------------------------------
(时间:08:30,排名:001,站点:五和,客流量:548)
(时间:08:30,排名:002,站点:民治,客流量:386)
(时间:08:30,排名:003,站点:布吉,客流量:369)
(时间:08:30,排名:004,站点:丹竹头,客流量:343)
(时间:08:30,排名:005,站点:南山站,客流量:340)
(时间:08:30,排名:006,站点:深圳北,客流量:313)
(时间:08:30,排名:007,站点:罗湖站,客流量:306)
......
需求2:查询 2018-09-01 06:30 - 2018-09-01 11:30 客流量排名前 3 的站点
val dataStream2: DataStream[(String, String)] =
env.addSource(new HBaseReader("StationTraffic", "traffic","2018-09-01 06:30", "2018-09-01 11:31"))
dataStream2.map(x => {
val keys: Array[String] = x._1.split(" ")
val values: Array[String] = x._2.split("_")
Traffic("时间:" + keys(1), "排名:" + keys(2), "站点:" + values(1), "客流量:" + values(0))
})
.filter(_.rank.substring(3).toInt <= 3)
.map(data => {
println(data.time, data.rank, data.station, data.count)
})
---------------------------------------
(时间:08:30,排名:001,站点:五和,客流量:548)
(时间:08:30,排名:002,站点:民治,客流量:386)
(时间:08:30,排名:003,站点:布吉,客流量:369)
(时间:08:31,排名:001,站点:五和,客流量:577)
(时间:08:31,排名:002,站点:南山站,客流量:436)
(时间:08:31,排名:003,站点:布吉,客流量:405)
(时间:08:32,排名:001,站点:五和,客流量:602)
(时间:08:32,排名:002,站点:南山站,客流量:439)
(时间:08:32,排名:003,站点:布吉,客流量:413)
(时间:08:33,排名:001,站点:五和,客流量:594)
(时间:08:33,排名:002,站点:南山站,客流量:451)
(时间:08:33,排名:003,站点:布吉,客流量:393)
......
不同乘车区间是同样的道理,更多的业务场景不在列举。