基于Python 爬虫的房地产数据可视化分析与实现
摘要: 过去,不管是翻阅书籍,还是通过手机,电脑等从互联网上手动点击搜索信息,视野受限,信息面太过于狭窄,且数据量大而杂乱,爆炸式信息的更新速度是快速且不定时的。要想手动获取到海量的信息,并进行分析整理,都要耗费巨多的时间,精力,效率低下,但是通过网络爬虫,根据需求获取海量房源数据,进行数据清洗,去重,入库,存表,数据可视化,把分析结果反馈给用户,并把数据结合数据库存储,以直观明了的可视化图表展示数据等功能,提高工作效率,提供令人满意的结果,克服了以往数据使用单一,不利于决策的问题。
关键词: 爬虫;可视化;Python;数据分析
-
引言
-
研究背景与意义 房地产行业在我国属于支柱性产业,在我国社会经济发展中一直扮演着重要角色。房价问题,尤其是大中城市的房价问题,一直是政府、大众和众多研究人员关注的热点。如何科学地预测房价是房价问题的研究方向之一。随着互联网时代的来临,如今越来越多的民众选择通过网络获取房源信息并进行选房购房,如何尽可能多角度的呈现房源信息帮助民众选房成为一个值得深人研究的课题。 为此,本研究使用爬虫技术获取温州二手房的房源信息,然后使用数据处理模块采用去重、分组、填补缺失值等处理方法,并根据处理的结果,找出各个变量之间的线性或者非线性关系,从而找出影响房价的因素。在房价数据抓取阶段使用Python爬虫技术,该方法获取的房价数据与传统从政府信息网站获取的房价数据相比更加丰富并具有时效性。在房价数据处理时使用pandas库和正则表达式对房源信息进行处理,在利用热力图找出各个变量和房价直接的关系,从而找出影响房价的原因。在房价数据展示部分利用pyechart实现房源统计信息可视化展示,包括呈现房价排名、房价区间等等可视化图表,可以帮助消费者更加高效了解房源信息,更快更清晰地选房、购房。
-
主要研究内容 本研究主要实现一个基于Python 爬虫的房地产数据可视化分析系统。此系统实现了beautifulsoup框架进行数据采集、pandas数据处理、MySQL进行数据存储、以及使用pyechart进行数据可视化等部分。主要研究内容分为以下五点: 1、基于beautifulsoup框架的房源信息采集,爬取目标数据包括基本信息、房屋属性、交易属性等 2、伪装请求头和使用ip代理、设置采集频率等方式对抗反爬虫。 3、pandas库和正则表达式对房源数据进行处理。对爬取数据进行查数据一致性,处理无效值和缺失值等操作目的在于删除重复信息、纠正存在的错误,并提供数据一致性。 4、mySQL持久化存储数据。 5、Pyecharts数据可视化展示。可视化模块对数据进行可视化的呈现,使消费者更直观的观察各地区价格户型之间差异。
-
论文结构
-
引言;剖析研究背景和意义,说明研究的内容。
-
开发技术;代码主要使用了python技术,beautifulsoup爬虫框架和myspl数据库,并对此做了介绍。
-
需求分析;囊括需求功能、流程图进行了分析。
-
功能需求设计;包括爬虫功能模块、数据处理模块、可视化模块和数据库进行详细设计。
-
功能需求实现;对需求和功能实现和描述。
-
功能测试。包括爬虫、和数据处理、数据库等模块进行测试
-
总结心得;在论文最后结束章节总结了开发这个系统和撰写论文时候自己的总结、感想,包括致谢
二、开发技术
(一)Python语言
Python语言的编程风格与C语言非常接近,它继承了C++面向对象技术的核心,它面世之后发展迅速,非常流行,对高级C语言形成了很大的冲击。业内人士称之为“一次编译、到处执行”。当然python也有缺点,在每次执行编译后,字节码都需要消耗一定的时间,在某些程度上降低了性能。但是这并不影响python成为此次设计语言的选择。
表2-1 Python优势
| 序号 |
优势 |
|---|---|
| 1 |
Python面向对象技术,有四个特点:封装、继承、多态、抽象。 |
| 2 |
Python通用性强,在任何平台上,只要有Python虚拟机,Python代码都能运行 |
| 3 |
Python对内存的访问都必须通过对象的实例变量来实现,避免了指针中出现的错误 |
| 4 |
Python提供了多线程功能,利用编程实现同一时间同时工作的功能。 |
(二)MySQL数据库
因为MySQL是源代码对外开放的,所以任何人都可以通过相应的方法下载,并根据个性化需求进行修改。 由于MySQL的速度,可靠性和适应性,MySQL受到重视。
(三)beautifulsoup爬虫框架
是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree)。 它提供简单又常用的导航(navigating),搜索以及修改剖析树的操作。利用它我们不在需要编写正则表达式就可以方便的实现网页信息的提取。
(四)MySQL数据库安装
本系统的数据使用的是MySQL,所以要将MySQL安装到指定目录,如果下载的是非安装的MySQL压缩包,直接解压到指定目录就可以了。然后点击C:\Program Files\MySQL\bin\winMySQLadmin.exe这个文件其中C:\Program Files\MySQL是MySQL安装目录。输入winMySQLadmin的初始用户、密码(注:这不是MySQL里的用户、密码)随便填不必在意,确定之后右下角任务的启动栏会出现一个红绿灯的图标,红灯亮代表服务停止,绿灯亮代表服务正常,左击这个图标->winnt->install the service 安装此服务,再左击这个图标->winnt->start the service 启动MySQL服务。
修改MySQL数据库的root密码。用cmd进入命令行模式输入如下命令:
cd C:\Program Files\MySQL\bin
MySQLadmin -u root -p password root
回车出现Enter password: ,这是要输入原密码. 刚安装时密码为空,所以直接回车,此时MySQL 中账号 root 的密码被改为 root 安装完毕。
(五)系统运行环境
上述目标来分析本系统的硬件如下:
inter的处理器;
内存是 4G;
硬盘是120G;
操作系统是Window 10;
Pycharm社区版
MySQL8.0
Navicat12
三、需求分析
(一)技术可行性分析
本系统开发选择python技术,python技术是一个完全面向对象的语言,为开发者提供了丰富的类库,大大减少了使用windows编程的难度,减少开发人员在设计算法上的难度,作为python技术开发 pycharmo更是一个必不可少的角色,它友好的界面,以及强大的功能,给程序开发人员带来了很多方便,加上环境简单,转移方便,无疑使此系统最佳的选择。
(二)经济可行性分析
Python是一款开源免费的脚本语言,Pycharm开发环境也有免费的社区版,而且MySQL也是一款优秀的免费的数据库。因此开发成本几乎可以忽略不计,因此经济可行性非常高。
(三)操作可行性分析
本系统的开发符合国家法律进行,也不会触犯到任何人,任何集体的法律权益。只要开发过程中遵纪守法就完全符合法律要求,并且使用计算机的用户都会具有一定的计算机基础,并且本系统操作方法简单,分析的均为计算机相关方面的人才,所以用户绝对能够熟练使用该系统,并且普通会使用计算机的人群也能使用。因此社会可行性很高。
(四)需求功能分析
基于Python 爬虫的房地产数据可视化分析,要求实现数据爬取模块,数据清洗模块,数据可视化模块以及数据存储模块。实现对温州链家二手房网站房源数据采集、经过pandas库清洗处理后MySQL数据库中,结合Pyecharts组件,实现数据到可视化图表的转换,帮助消费者更加高效了解房源信息,更快更清晰地选房、购房。本研究的结构设计如图3-3-1所示
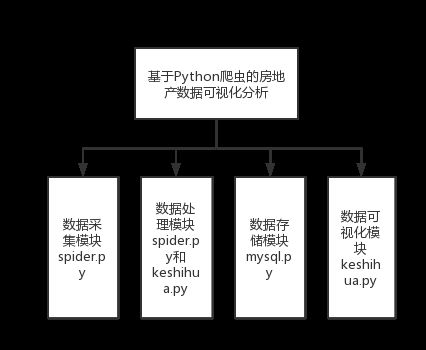
图3-3-1房地产数据可视化分析结构设计图
四、功能需求设计
(一)需求功能模块设计
1.数据爬取模块
程序模拟浏览器访问温州链家二手房网获取响应信息,提取其中所有房源数据,包括房源名称、地址、单价、总价、面积、户型等,下面是数据爬取流程图,如图3-4-1所示。
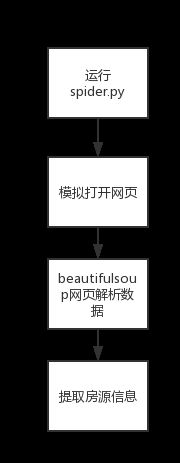
图4-1-1 数据爬虫流程图
2.数据处理模块
爬虫提取其中所有房源数据后,经过正则表达式的清洗,将空格还有一些特殊符号去掉,在存到数据库当中,下面是数据处理流程图,如图3-5-1所示。
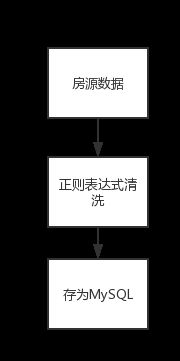
图4-1-1数据处理流程图
3.数据存储模块
在爬虫运行之前,我们先将数据库和数据表建立,其中先通过mysql.py建立一个浙江房地产数据库和一张房地产数据表,爬虫提取清洗其中所有房源数据后,经过pymysql库,存到数据表当中,实现持久性存储。
-
数据可视化模块
要做房地产数据分析就要使用可视化操作,在keshihua.py中先通过pandas库处理数据,经过分组、转换数据类型、去重、求和之后,经过pyechart库和matloplit库的渲染,生成可视化图表,可视化流程图如图4-1-2所示。
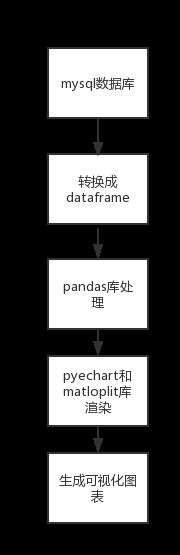
图4-1-2可视化流程图
-
数据库设计
1.数据库概念设计
概念模型是对现实中的问题出现的事物的进行描述,ER图是由实体及其关系构成的图,通过E-R图可以清楚地描述系统涉及到的实体之间的相互关系。实体图如图4-2所示:

图4-2 房地产数据实体图
-
数据库物理模型设计 表4-2:房地产数据表
| 字段名称 |
类型 |
长度 |
字段说明 |
主键 |
默认值 |
|---|---|---|---|---|---|
| 索引 |
int |
主键 |
主键 |
||
| title |
varchar |
标题 |
|||
| pisition |
varchar |
100 |
地址 |
||
| tag |
varchar |
100 |
标签 |
||
| followinfo |
varchar |
100 |
信息 |
||
| vr |
varchar |
200 |
Vr看房 |
||
| info |
varchar |
详细信息 |
|||
| 总价 |
varchar |
总价 |
|||
| 单价(rmp) |
varchar |
单价 |
|||
| 关注人数 |
varchar |
关注人数 |
|||
| 发布时间 |
varchar |
发布时间 |
|||
| 几室 |
varchar |
几室 |
|||
| 几厅 |
varchar |
几厅 |
|||
| 面积 |
varchar |
面积 |
|||
| 楼层 |
varchar |
楼层 |
五、功能需求实现 (一)爬虫功能实现 1.确定url 通过网页发现温州链家二手房网页地址可以用下面的公式来表示:https:// + 城市名称拼音缩写 + .lianjia.com/ershoufang/pg +页码+/,根据此规律,就可以获得温州链家二手房的所有网页的网址。 2.添加伪装浏览器的请求头 获取了url之后,我们需要利用函数requests.get() 来得到该网页下html的内容。但是直接利用requests.get()函数获取html的内容会报错,服务器拒绝访问。大部分网站都有反爬虫的机制,但链家官网的反爬虫机制比较简单,只需要添加网页的headers从而模仿人为使用浏览器访问链家二手房网页。
-
beautifulsoup解析 第二步只是简单获取了文本参数,还需要对html的内容进行解析。这个时候,就可以在程序中导入BeautifulSoup,作为解析html内容的工具。当然过程中发现中间掺杂了大量标签, 而结果只需要文字。就只能通过正则表达式等方式去除标签,去标签提取文本内容的结果,结果如图5-1爬虫结果所示。

图5-1爬虫结果 (二)数据处理功能实现 获取了数据之后,需要首先对数据进行预处理,本论文中的预处理操作比较简单,利用pandas库,直接采用astype()包含对数据类型进行转化、dropna()清除空值、对异常的数据进行筛选和删除、groupy()数据列的拆分(将一列数据拆分为多列数据)等操作。结果如图5-2 数据处理结果。
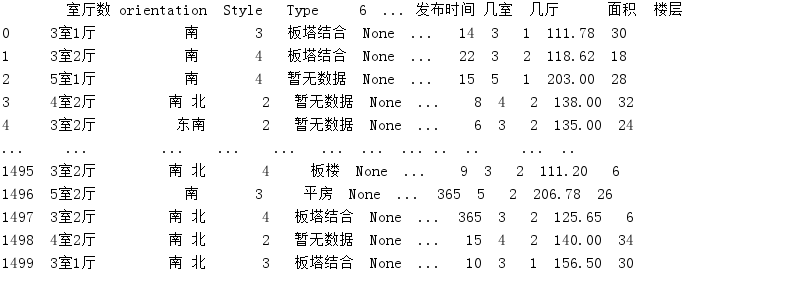
图5-2 数据处理结果 (三)数据存储实现 在爬取数据后,就可以对数据进行存储,这里使用的是pymysql库进行创库建表操作,然后在利用pymysql的connect方法往数据表中实现insert操作,结果如图5-3 数据存储结果。
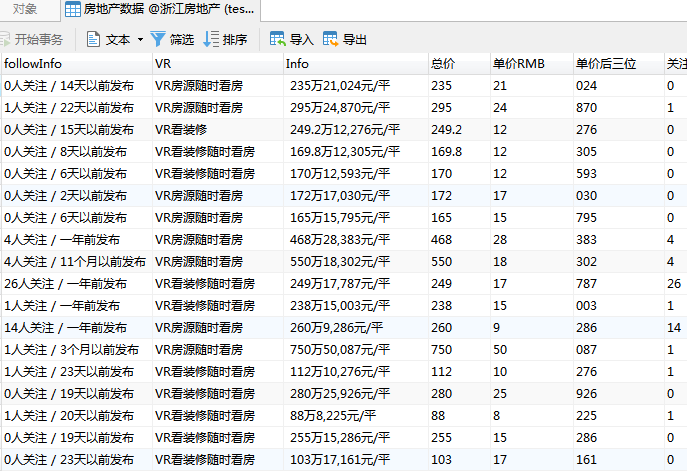
图5-3 数据存储结果 (四)数据可视化实现 1.户型特征分析 户型特征分析,是基于二手房的户型特征,对二手房的数量进行统计分析。通过户型特征分析,可以看到二手房中几室几厅的二手房最受欢迎。这里使用的是pyechart库的pie模块,对筛选的户型数据进行渲染,生成饼图。结果如图5-4-1 户型分析
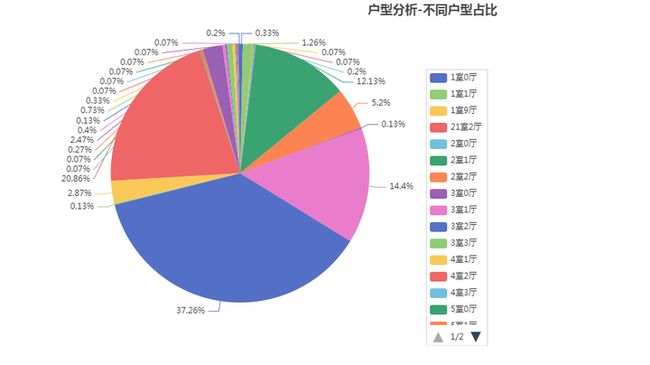
图5-4-1 户型分析 2.区域特征分析 区域特征分析,是基于小区,对二手房进行统计,通过此操作,可以看到,哪个小区的二手房数量最多。这里使用的是pyechart库的bar模块,对筛选的小区数据进行渲染,生成柱形图。结果如图5-4-2 区域特征分析
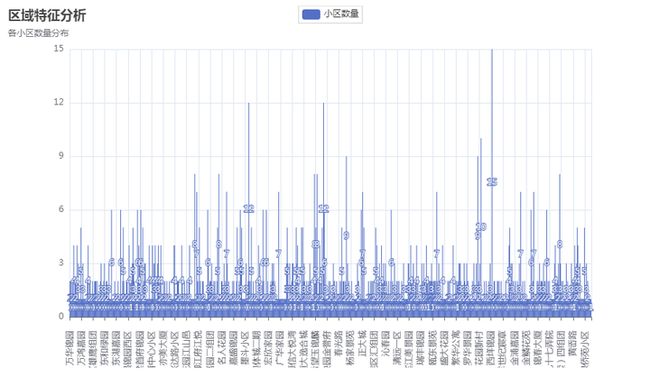
添加图片注释,不超过 140 字(可选)
图5-4-2 区域特征分析 3.面积特征分析 面积特征分析,是基于二手房面积,对二手房进行统计分析。将二手房面积划分不同的区间,同时,结合二手房价格,验证二手房面积越大,价格是否越昂贵。这里使用的是pyechart库的bar和scatter模块,对筛选的面积数据进行渲染,生成面积分布图和面积和总价散点图。结果如图5-4-3 面积分布图和图5-4-4面积总价散点图
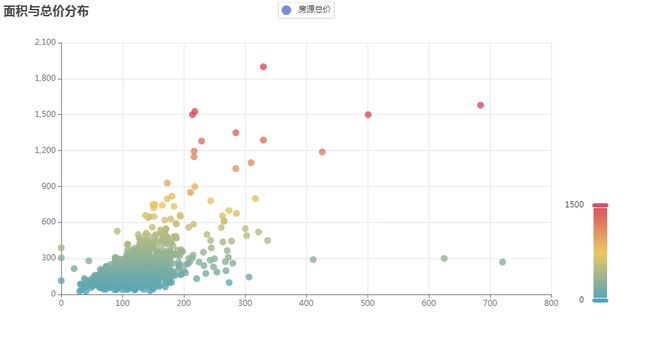
图5-4-4面积总价散点图
-
装修特征分析 装修特征分析,是基于二手房装修类型,结合二手房每平米售价进行分析。这里使用的是pyechart库的line模块,对筛选的装修特征数据进行渲染,生成装修特征分析图。结果如图5-4-5 装修特征分析图
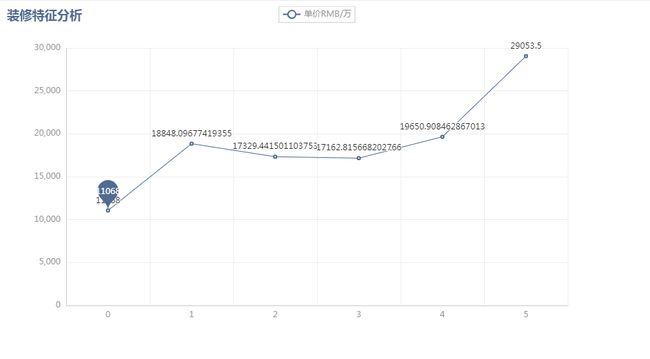
图5-4-5 装修特征分析图
-
楼层分析 楼层分析是基于二手房的所在楼层,对不同楼层的二手房进行统计作图,更能直观的看到不同楼层二手房的数量。这里使用的是pyechart库的bar模块,对筛选的楼层数据进行渲染,生成楼层分析图。结果如图5-4-6楼层分析图
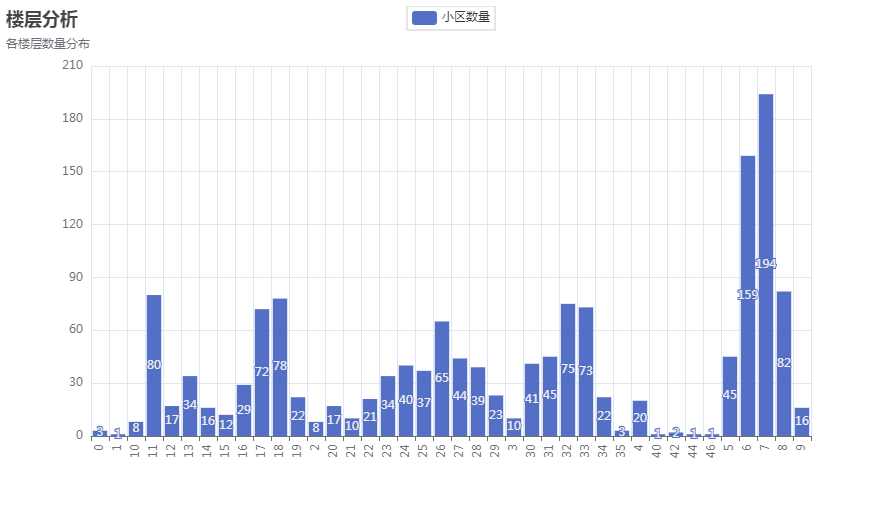
图5-4-6楼层分析图
-
热力图分析
通过前面的分析,要找出影响房价的因素有哪些,就要利用热力图展示各个变量和房价之间的关系,当然先要对可能影响房价的所有变量求相关系数,利用corr()方法求出,再利用seaborn中的heatmap函数绘制热力图。结果如下图5-6-1热力图

图5-6-1热力图
六、功能测试
(一)测试内容
基于Python爬虫的房地产信息可视化分析主要是房地产数据采集和处理,以及持久化存储,对数据进行可视化产生,所以我们主要测试系统是否能采集、数据处理是否成功,存储是否实现,可视化是否正常。所以选择开发人员手工执行测试用例的方式进行。以下是对基于Python爬虫的房地产信息可视化分析系统进行的详细说明。基于Python爬虫的房地产信息可视化分析系统测试用例,如表6-1所示。
表6-1 基于Python爬虫的房地产信息可视化分析系统测试用例
| 测试名称:基于Python爬虫的房地产信息可视化分析系统测试测试目的:看可视化功能是否正确显示可视化图片,爬虫是否能正常爬取,数据库是否能政策存入数据。前置测试:成功连接数据库,并可视化展示房地产可视化信息。主要参与者:用户 |
|||
|---|---|---|---|
| 功能模块 |
测试目的 |
测试步骤 |
预期结果 |
| 爬虫模块 |
尝试爬取前几页,观察是否能正常采集数据 |
输入测试页数6页 |
成功:运行界面出现了采集的房地产信息;错误:没有其他信息 |
| 数据处理 |
点击运行测试采集数据,观察是否能正常处理成我们想要的数据,包括去重、包括去空值等 |
点击运行spider.py和keshihus.py |
成功:运行界面出现处理后的结果。失败:数据不变 |
| 数据存储 |
运行mysql.py,查看是否能成功建表和存储测试数据 |
运行mysql.py |
成功:数据库和数据表建立成功。失败:数据表和数据库不能成功创建 |
| 数据可视化 |
选择测试数据,运行keshihua.py查看是否有可视化图片生成 |
运行keshihua.py |
成功:可视化图表成功创建失败:可视化图表不能显示 |
(二)测试结果
本系统的所有功能经过测试后已经完全满足要求。本系统满足了房地产数据信息爬取,房地产数据处理,房地产数据存储,房地产信息可视化图表展示。
七、结论和总结
本次论文完成了对于基于Python爬虫的房地产信息可视化分析,基本上达到了任务要求,通过网络爬虫,根据需求获取海量房源数据,进行数据清洗,去重,入库,存表,数据可视化,把分析结果反馈给用户,并把数据结合数据库存储,以直观明了的可视化图表展示数据等功能,提高工作效率,提供令人满意的结果。
虽然本次设计已经完成,但是还有很多问题需要在今后的学习过程中解决。
其一,更充分的认识到Python的应用确实是当下较为容易入门和掌握的开发模式。可并没有能完全的掌握这种开发方式的优势,未能发挥其全部能力,甚至只是用的它的冰山一角。需要更深入的学习才能在今后的工作中有更好的发挥。
其二,在Python爬虫编程应用上必须通过进一步的研究来完善这一方面的知识,才能脱离现在只能对其进行浅层次的应用的现状,以实现更多更好的系统功能。
参考文献
[1]崔朝霞,刘宝龙.基于Python的网络数据爬虫设计与实现[J].数字化用户,2018.
[2]王彦雅.基于Python的廊坊市二手房数据爬取及分析[J].电脑知识与技术,2021,017(029) - 168~170.
[3]田雪丽 ,郭志斌 , 刘梦贤.基于Python的网页数据爬取与可视化分析[j].电脑知识与技术:学术交流.2022,018(006) - 24~26.
[4]钱程 ,阳小兰 ,朱福喜,基于Python的网络爬虫技术[j].黑龙江科技信息,2016,000(036) - 273~273.
[5]陈海燕,朱庆华,常莹.基于Python的网页信息爬取技术研究[j].电脑知识与技术.2021,017(008) - 195~196