Linux ---- Shell编程之函数与数组
目录
一、函数
1、函数的基本格式
2、查看函数列表
3、删除函数
4、函数的传参数
5、函数返回值
实验:
1.判断输入的ip地址正确与否
2. 判断是否为管理员用户登录
6、函数变量的作用范围
7、函数递归(重要、难点)
实验:
递归遍历目录
编辑一键安装nginx
阶乘
1.用for循环求阶乘
2.用函数求阶乘编辑
附加:sed
二、数组
1、数组介绍
2、引言
3、shell数组的定义
4、定义数组格式
方法一:
方法二:
方法三:
实验:
简单随机点名
方法一:
方法二:
5、数组索引
6、数组定义方法
实验:取最大值
7、冒泡排序法:
举例:
一、函数
- 将命令序列按格式写在一起
- 可以方便重复使用命令序列
- 函数也是一种脚本的别名
使用函数
1、先进性定义
2、再调用
1、函数的基本格式
[function] 函数名(){
命令序列
[return x] #使用return或exit可以显示的结束函数
}
或者
-------------------------------第二种使用较多---------------------------------------------------
#也可以省略掉[function],它表示该函数的功能
函数名() { #函数名后面()是没有内容的
命令序列 #我们执行的命令内容放在{}里面
}
----------------------------------------------------------------------------------
[function] 函数名 {
命令序列
}- 函数定义完之后并不会自动执行,需要调用才行
- 好处在于可以写一段功能代码作为函数,有需要就直接调用定义的时候哪怕出现语法错误也没关系,不调用就不会报错
- 当然我们写函数最终目的还是为了调用,为了实现某个功能块。
举例:
#!/bin/bash
h () {
echo "hello"
}
niao () {
echo `h` `w`
}
w () {
echo "world"
}
nihao 

最简单的例子
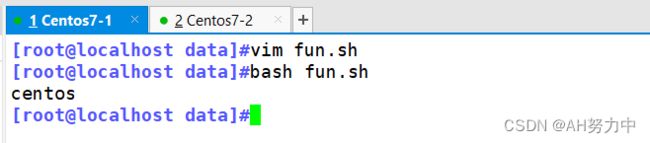
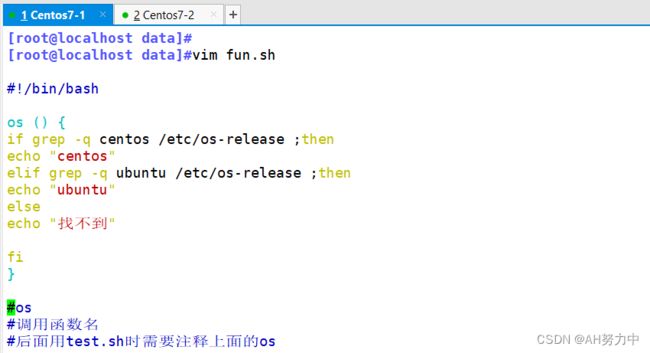
vim func.sh
#!/bin/bash
haha () {
echo "hello"
}
haha
#这个是调用hello
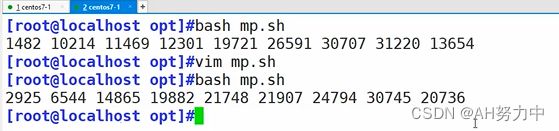
bash func.sh

123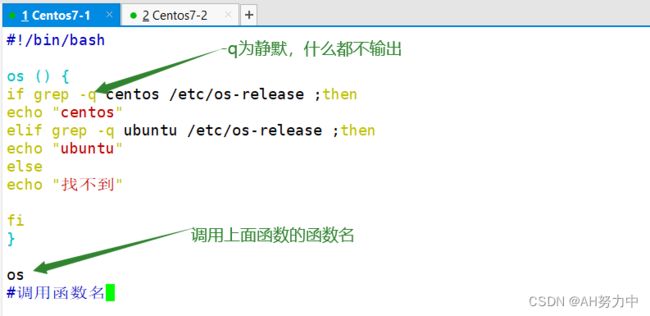
如果在其他文件中调用这个文件


添加颜色
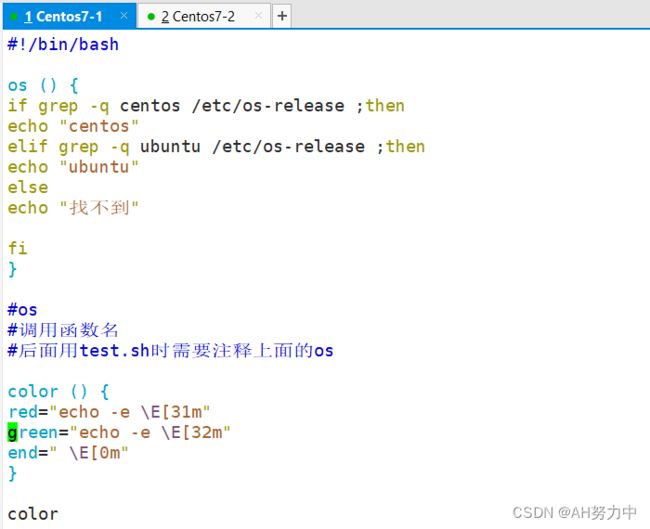
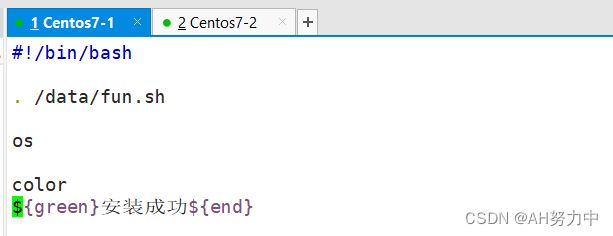

2、查看函数列表
declare -F ##查看当前已定义的函数名
declare -f ##查看当前已定义的函数定义
declare -f func_name ##查看指定当前已定义的函数名
declare -F func_name ##查看当前已定义的函数名定义3、删除函数
删除函数: unset func_name
[root@localhost data]#func1 () { hostname;hostname -I; }
[root@localhost data]#func1
localhost.localdomain
20.0.0.100 192.168.122.1
[root@localhost data]#unset func1
[root@localhost data]#func1
bash: func1: 未找到命令...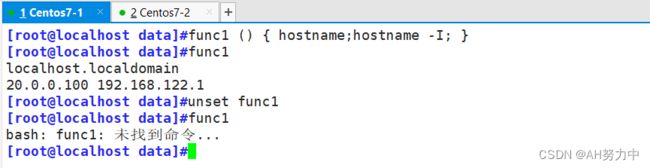
4、函数的传参数
#!/bin/bash
h () {
echo "第一个参数是:$1 $2 $3"
}
h $1 $2 $3 ##调用

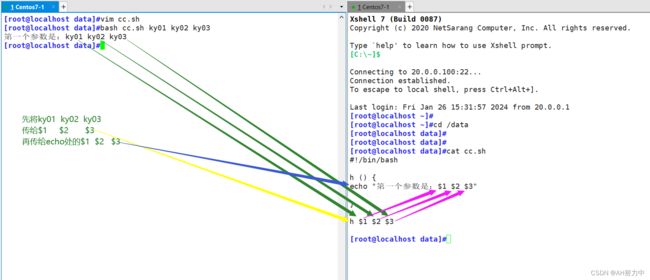
调换位置
#!/bin/bash
h () {
echo "第一个参数是:$1 $2 $3"
}
h $2 $1 $3 ##调用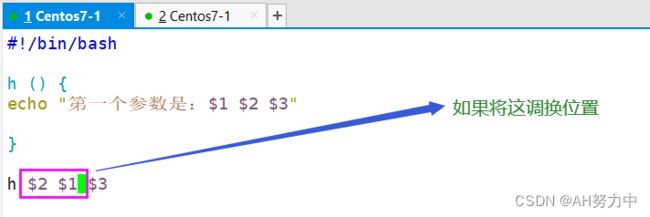

5、函数返回值
实验:
1.判断输入的ip地址正确与否
使用原则:
1、函数一结束就取返回值,因为$?变量只返回执行的最后一条命令的退出状态码
2、退出状态码必须是0~255,超出时值将为除以256取余
return ###只能用在函数中
###return 从函数中返回,用最后状态命令决定返回值
###return 0 无错误返回
###return 1 有错误返回
exit 100 ##exit退出整个脚本
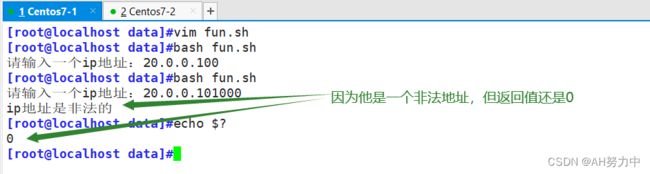


2. 判断是否为管理员用户登录

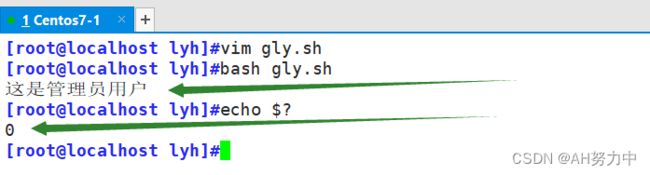
6、函数变量的作用范围
函数在Shell脚本中仅在当前Shell环境中有效
Shell脚本中变量默认全局有效
将变量限定在函数内部使用local命令
7、函数递归(重要、难点)
调用自己本身的函数
可以写病毒
[root@localhost ~]#func () { echo $i;echo "run fast";let i++; func; }
funcfor炸弹
:(){ :|:& };: //:就是一个字符 可以写成单词
bomb() { bomb | bomb & }; bomb执行bomb以后会死机,除非重启,在没有其他办法。
实验:
递归遍历目录

 一键安装nginx
一键安装nginx


阶乘
0和1的阶乘都为1
自然数n的阶乘写作n!
1.用for循环求阶乘

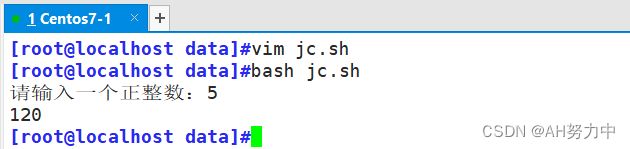
2.用函数求阶乘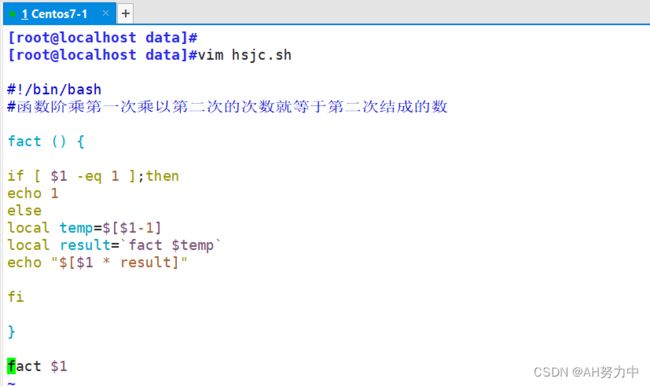

附加:sed
sed -i “s/旧/新/g” 文件名 ### -i 选项是真的改
#sed -i "s/root/admin/g" passwd
#当面文件夹下的passwd里的root改为admin
sed -i.bak "s/admin/root/g" passwd ### -i.bak 是做备份,.bak只是后缀名,可以任意写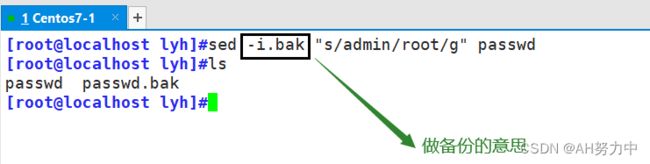
sed "2a/hahahahaha" passwd ### a是插入的意思,2a是在第二行后面插入
sed
- i :在前面插
- a :在后面插
- c :整行替换
二、数组
1、数组介绍
数组和变量:
- 数组:储存多个元素的连续的内存空间,相当于多个变量的集合
- 变量:存储单个元素的内存空间
2、引言
将全班学生定义成一个变量,无法使用普通变量。
-
普通数组
-
关联数组
变量和数组
-
变量:存储单个元素的内存空间
-
数组:存储多个元素的连续的内存空间,相当于多个变量的集合
数组名和索引
-
索引的编号从0开始,属于数值索引
-
索引可支持使用自定义的格式,而不仅是数值格式,即为关联索引,bash 4.0版本之后开始支持
-
bash的数组支持稀疏格式(索引不连续)
3、shell数组的定义
数组中可以存放多个值,Bash Shell 只支持一维数组(不支持多维数组)
数组元素的下标由 0 开始
Shell 数组用括号来表示,元素用"空格"符号分割开
在shell语句中,使用、遍历数组的时候,数组格式要写成 ${arr[@]} 或 ${arr[*]}
4、定义数组格式
方法一:
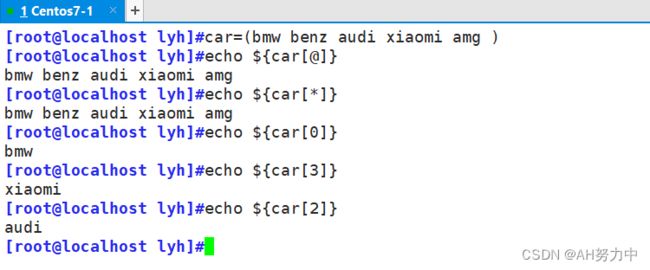
数组名=(value1 value2 ... valuen)
[root@localhost lyh]#a=(1 2 3 4 5)
[root@localhost lyh]#echo ${a[@]}
1 2 3 4 5
[root@localhost lyh]#echo ${a[*]}
1 2 3 4 5
方法二:
数组名=([0]=value0 [1]=value0 [2]=value0 ...)
[root@localhost lyh]#b=([0]=1 [1]=2 [2]=3 [3]=4 [4]=5)
[root@localhost lyh]#echo ${b[@]}
1 2 3 4 5
方法三:
数组名[0]="value"
数组名[1]="value"
数组名[2]="value"
[root@localhost lyh]#c[0]=1
[root@localhost lyh]#c[1]=2
[root@localhost lyh]#c[2]=3
[root@localhost lyh]#c[3]=4
[root@localhost lyh]#echo ${c[@]}
1 2 3 4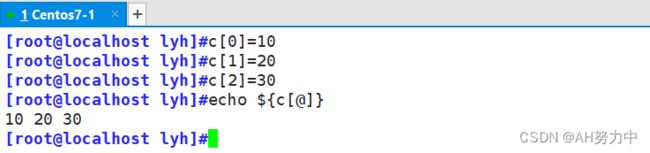
实验:
简单随机点名
方法一:


方法二:

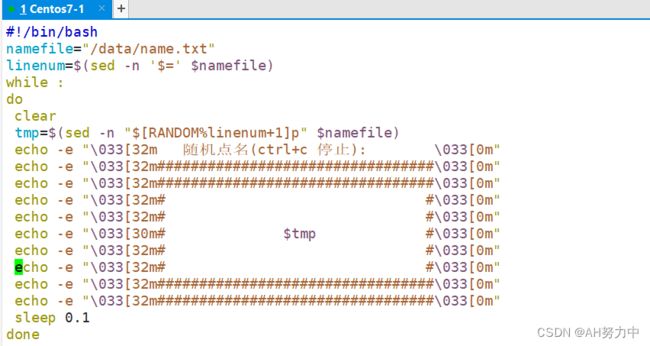

5、数组索引
数组名和索引
- 索引的编号从0开始,属于数值索引
- 索引可支持使用自定义的格式,而不仅是数值格式,即为关联索引,bash 4.0版本之后开始支持
- bash的数组支持稀疏格式(索引不连续)
索引分为两种:普通索引和关联索引
普通索引:上面解释了
关联索引:①下表可以是文字:称为关联索引 键值对的关系
②下表可以不连续,称为稀疏格式
注意:关联数组和普通数组都要先声明,普通可以声明也可以不用声明
但是关联数组必须要先声明
定义关联数组一定要声明,不声明就没有效果
[root@localhost data]#declare -A 数组名 -A 声明关联数组,
[root@localhost data]#declare -a 数组名 -a 声明普通数组,不是变量是数组

只能把这个删了重新声明,不声明就会混乱


6、数组定义方法
方法一(一次赋值全部元素):
数组名=(value0 valuel value2 ...)
a=(10 20 30 40 50)
方法二(只赋值特定元素):
数组名=([0]=value[1]=value[2]=value ··)
b=([0]=10[1]=20[21=30)
方法三:
列表名="value0 valuel value2..."
数组名=(S列表名)
[root@localhost data]#b="12345 6"
[root@localhost data]#c=$b
[root@localhost data]#echo ${c[*]}
123456
方法四(一次只赋值一个元素): 追加 修改
数组名[0]="value"
数组名[1]="value"
数组名[2]="value"
方法五:read-a 交互式
[root@localhost datal#touch{1..10}.txt
[root@localhost datal#file=(*.txt) //当前文件夹下的,所有txt结尾的文件
[root@localhost datal#echo $file
10.txt





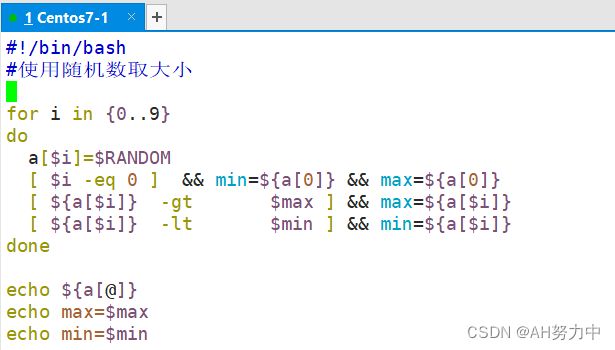
实验:
取最大值


取最小值:

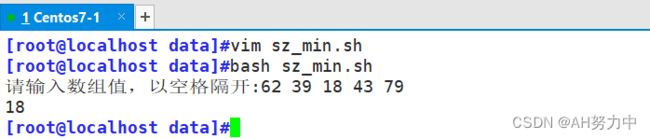
随机数

7、冒泡排序法:
数组排序算法:冒泡排序
类似气泡上涌的动作,会将数据在数组中从小到大或者从大到小不断的向前移动。
基本思想:
冒泡排序的基本思想是对比相邻的两个元素值,如果满足条件就交换元素值,把较小的元素移动到数组前面,把大的元素移动到数组后面(也就是交换两个元素的位置),这样较小的元素就像气泡一样从底部上升到顶部。
算法思路:
冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,一般为要排序的数组长度减1次,因为最后一次循环只剩下一个数组元素,不需要对比,同时数组已经完成排序了。而内部循环主要用于对比数组中每个相邻元素的大小,以确定是否交换位置,对比和交换次数随排序轮数而减少。
score=(77 13 91 56 88)
两两对比,第1个和第2个比,小的值到前面,大的值到后面。
以此类推。第2个和第3个比,第3个和第4个比,第4个和第5个比
------------第一轮------------
77 13 91 56 88 第一次对比 数组长度-1 第一轮比较往后值, 最大值为91
13 77 91 56 88 第二次对比
13 77 91 56 88 第三次对比
13 77 56 91 88 第四次对比
13 77 56 88 91
------------第二轮------------
13 77 56 88 91 第一次对比 数组长度-1第二轮比较往后,第二大的数字88
13 77 56 88 91 第二次对比
13 56 77 88 91 第三次对比
13 56 77 88 91
------------第三轮-----------
13 56 77 88 91 第一次对比 数组长度-1第三轮比较往后,第三大的数字77
13 56 77 88 91 第二次对比
13 56 77 88 91
------------第四轮-----------
13 56 77 88 91 第一次对比 数组长度-1第四轮比较往后,第四大的数字56
13 56 77 88 91
举例:
#!/bin/bash
array=(98 76 24 100 35 3)
echo "old_array:${array[*]}"
lt=${#array[*]}
#定义比较轮数,比较轮数为数组长度-1,从1开始
for ((i=1;i<$lt;i++))
do
#确定比较元素的位置,比较相邻两个元素,较大的数往后放,比较次数随比较轮数而
减少
for ((j=0;j<$lt-i;j++))
do
#定义第一个元素的值
first=${array[$j]}
#定义第二个元素的值
k=$[$j+1]
second=${array[$k]}
#如果第一个元素比第二个元素大,就互换
if [ $first -gt $second ];then
#把第一个元素的值保存到临时变量中
temp=$first
#把第二个元素值赋给第一个元素
array[$j]=$second
#把临时变量赋给第二个元素
array[$k]=$temp
fi
done
done
echo "new_array:${array[@]}"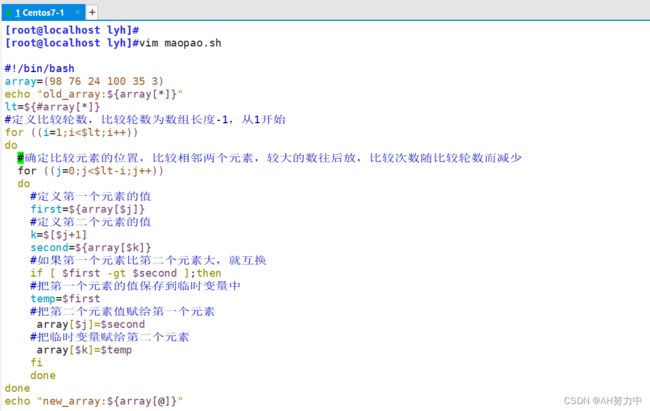

二